原创面试官:JVM内存区域你了解吗?
Posted 程序员的成长之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了原创面试官:JVM内存区域你了解吗?相关的知识,希望对你有一定的参考价值。
阅读本文大概需要 8 分钟。
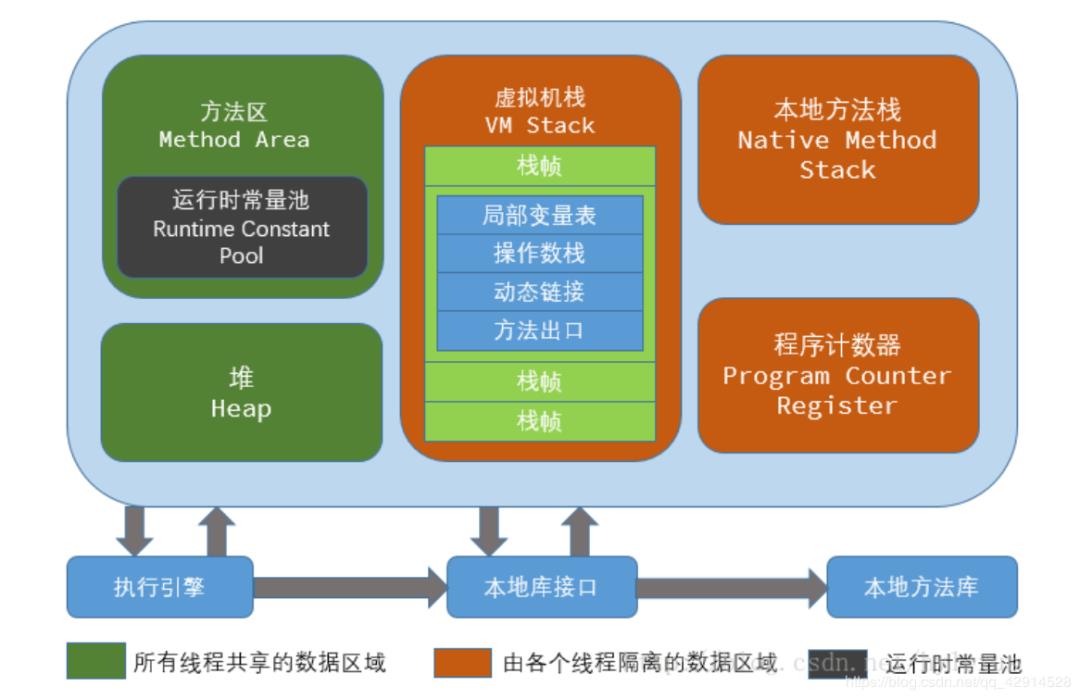
1.JVM 内存区域
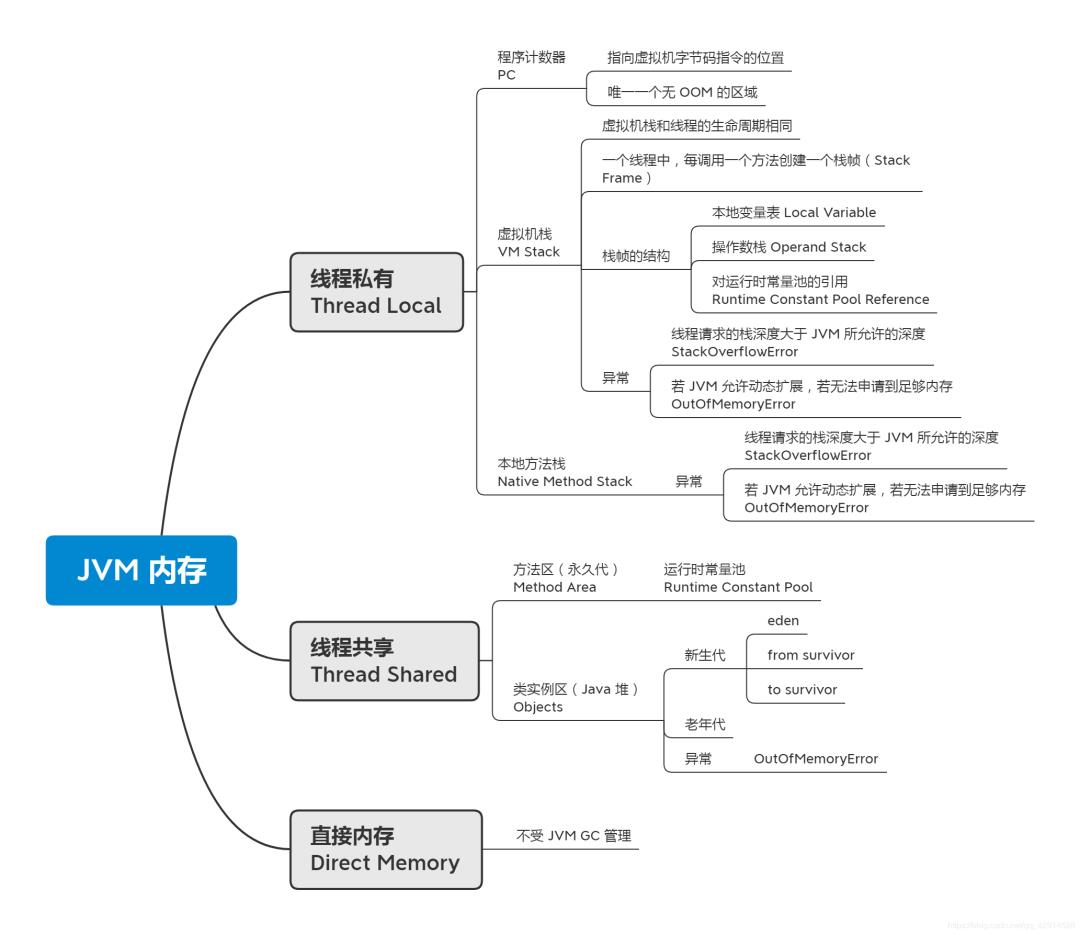
2.内存区域思维导图
3.程序计数器(线程私有)
画外音:假设程序永远只有一个线程,我们就不需要程序计数器。 JVM 的多线程是通过 CPU 时间片轮转(即线程轮流切换并分配处理器执行时间)算法来实现的。 也就是说,某个线程在执行过程中可能会因为时间片耗尽而被挂起,而另一个线程获取到时间片开始执行。 当被挂起的线程重新获取到时间片的时候,它要想从被挂起的地方继续执行,就必须知道它上次执行到哪个位置,在JVM中,通过程序计数器来记录某个线程的字节码执行位置。
4.虚拟机栈(线程私有)
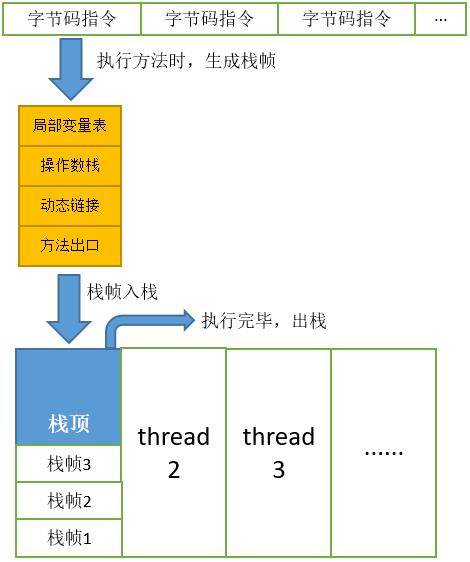
画外音:栈帧随着方法调用而创建,随着方法结束而销毁——无论方法是正常完成还是异常完成(抛出了在方法内未捕获的异常)都算作方法结束。
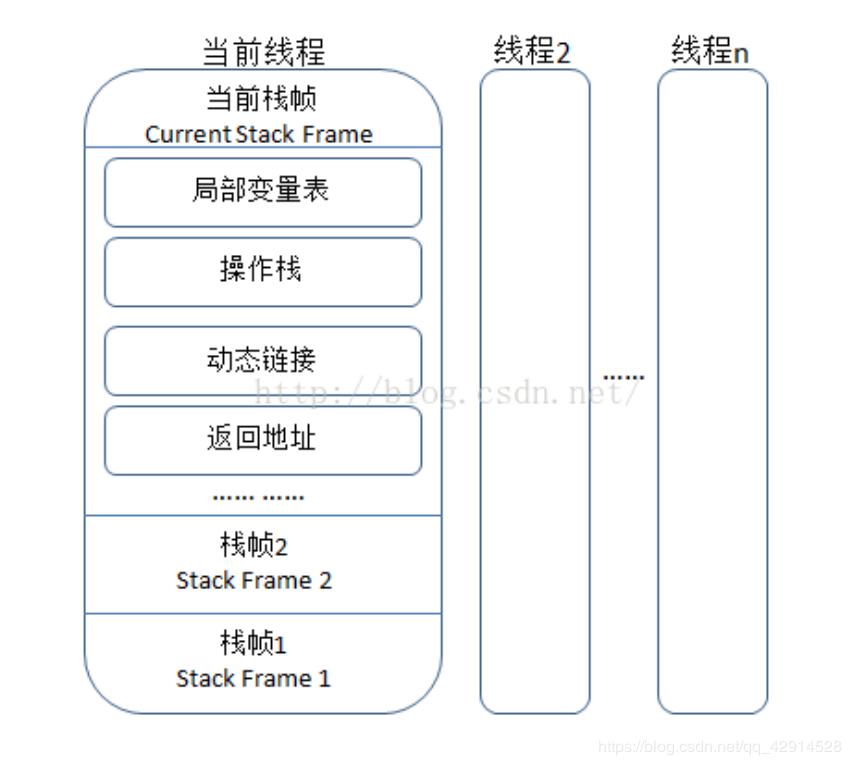
5.本地方法栈(线程私有)
画外音:在HotSpot 虚拟机中未对本地方法栈和虚拟机栈作区分,统称为栈。
6. 堆(Heap-线程共享)-运行时数据区
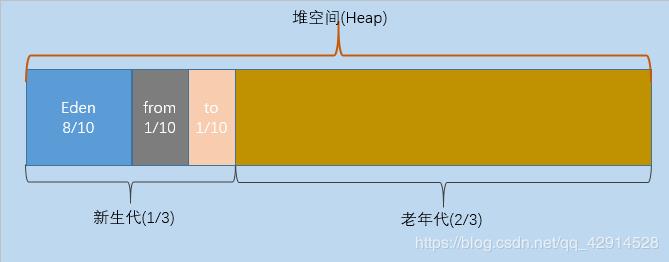
画外音:新生代划分也有这样的叫法:伊甸园(Eden space),幸存者0区(Survivor 0 space)和幸存者1区(Survivor 1 space)
7.方法区(线程共享)
画外音:对于方法区,很多人更愿意称为:“永久代(Permanent Generation)”,不过本质上两者并不等价,仅仅是因为习惯使用 HotSpot 虚拟机的设计团队选择把 GC 分代收集扩展至方法区,或者说使用永久代来实现方法区而已,这样HotSpot的垃圾收集器就可以像管理Java堆一样管理这部分内存,能够省去专门为方法区变编写内存管理代码的工作。 不过对于其他虚拟机(如BEA JRockit、IBM J9等)来说并不存在永久代的概念。
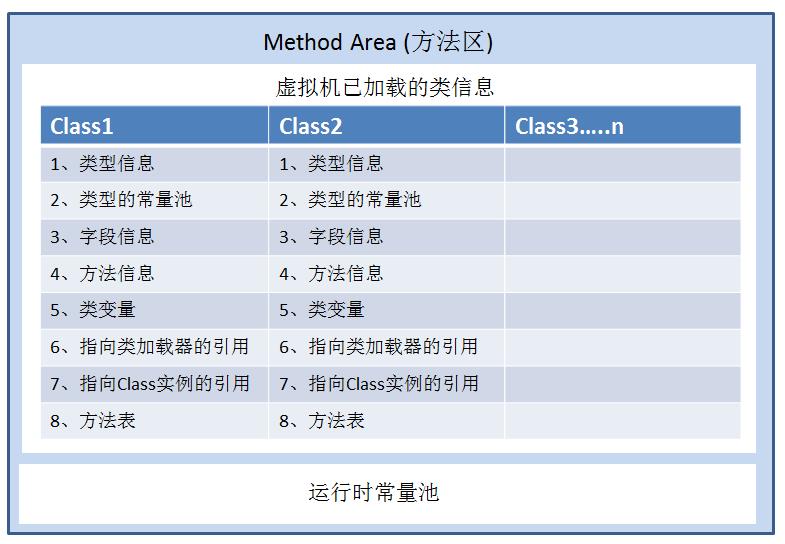
画外音:类型的常量池,也叫运行时常量池,每一个Class文件中,都维护着一个常量池(这个保存在类文件里面,不要与方法区的运行时常量池搞混),里面存放着编译时期生成的各种字面值和符号引用; 这个常量池的内容,在类加载的时候,被复制到方法区的运行时常量池 。
//使用StringBuilder在堆上创建字符串abc,再使用intern将其放入运行时常量池String str = new StringBuilder("abc");str.intern();
//直接使用字符串字面量xyz,其被放入运行时常量池String str2 = "xyz";
-
节省内存空间:常量池中所有相同的字符串常量被合并,只占用一个空间。 -
节省运行时间:比较字符串时,==比equals()快。对于两个引用变量,只用==判断引用是否相等,也就可以判断实际值是否相等。
画外音:什么是字符串常量池? 在 JAVA 语言中有8中基本类型和一种比较特殊的类型String。这些类型为了使他们在运行过程中速度更快,更节省内存,都提供了一种常量池的概念。常量池就类似一个JAVA系统级别提供的缓存。 8种基本类型的常量池都是系统协调的,String类型的常量池比较特殊。它的主要使用方法有两种:
直接使用双引号声明出来的String对象会直接存储在常量池中。 如果不是用双引号声明的String对象,可以使用String提供的intern方法。intern 方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中。
画外音:什么是类的元数据? 元数据是指用来描述数据的数据,更通俗一点,就是描述代码间关系,或者代码与其他资源(例如数据库表)之间内在联系的数据。 在一些技术框架,如struts、EJB、hibernate就不知不觉用到了元数据。 对struts来说,元数据指的是struts-config.xml;对EJB来说,就是ejb-jar.xml和厂商自定义的xml文件;对hibernate来说就是hbm文件。
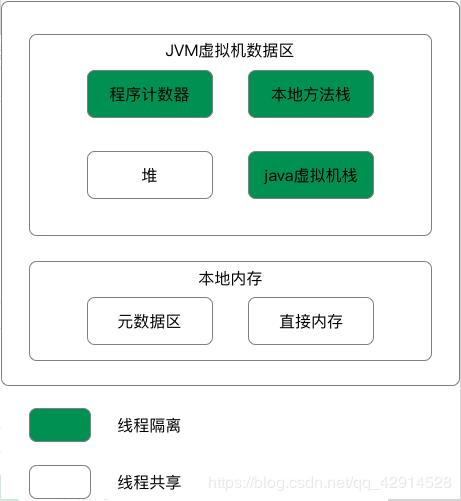
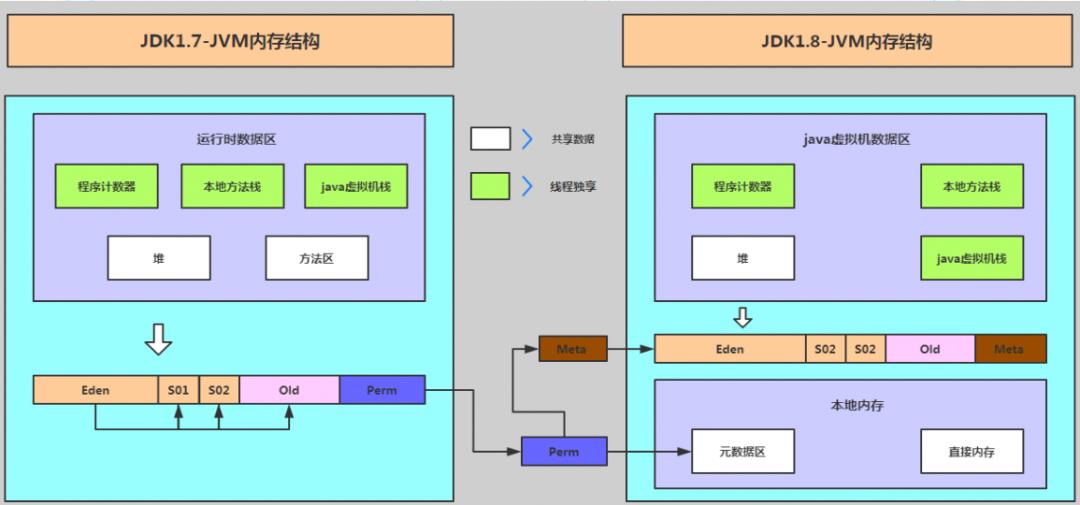
-
从数据流的角度,非直接内存是下面这样的作用链:本地 IO --> 直接内存 --> 非直接内存 --> 直接内存 --> 本地 IO。 -
而直接内存是:本地 IO --> 直接内存 --> 本地 IO。
-
可以使用 -XX:MaxMetaspaceSize 标志设置最大元空间大小,默认值为 unlimited,这意味着它只受系统内存的限制。 -
-XX:MetaspaceSize 调整标志定义元空间的初始大小如果未指定此标志,则 Metaspace 将根据运行时的应用程序需求动态地重新调整大小。
画外音:而且应该为 PermGen 分配多大的空间很难确定,因为 PermSize 的大小依赖于很多因素,比如 JVM 加载的 class 总数,常量池的大小,方法的大小等。
<END>
今天建了个专门更新Java面试题相关的知识星球,介绍下它的用途:
1.每周更新至少三篇JAVA面试题,硬核长篇!
2.向我提问,包括但不限:职场,技术,理财。
3.检查润色面试和简历。
价格:50/年(付费的,两顿饭钱服务一年,一天只要2毛钱)
前三十名加入有优惠,最低10元加入,后台回复【优惠卷】领取!

推荐阅读:
朕已阅
以上是关于原创面试官:JVM内存区域你了解吗?的主要内容,如果未能解决你的问题,请参考以下文章