Perl 脚本自动提取《人民日报》全文数据库中的动态词频数据
Posted 九州语言网
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Perl 脚本自动提取《人民日报》全文数据库中的动态词频数据相关的知识,希望对你有一定的参考价值。
基于动态词频数据可以获得一些与词语使用情况相关的信息。北语 BCC 语料库可提供人民日报词频的历时检索功能(http://bcc.blcu.edu.cn/hc),但目前只收录了2015年之前的语料。网络版《人民日报》本身也提供了一个比较强大的高级检索功能,容许用户按照指定时间段对1946年以来的全部文章进行内容检索,并会给出相应的词频数据。下图1给出了一个检索结果页面:
图1:人民日报检索结果示例
从上图1蓝色框线位置可以看出,“四个全面”这个词语自2012年11月1日至2017年6月29日在《人民日报》中一共出现了2025次。
为了批量提取网页文件中的这些词频信息,笔者在做未登录词研究时曾编写了一个 Perl 脚本程序,用于下载并解析相应的网页内容,输出动态词频数据以便于确定哪些未登录词属于新词。脚本程序源码如下所示,需要的读者可拷贝粘贴至记事本程序中,并另存成一个 *.pl 文件以备用,亦可根据需要修改使用。
#############################
#功能:基于人民日报网数据,统计词语在一定时期内出现的频数(按月统计)
#By XIONG Zi
use Encode;
use Encode::CN;
use Encoding utf8;
use LWP::Simple;
use File::Basename;
use File::Spec;
if ($#ARGV ne 2) {
print " 脚本参数配置如下:start_year end_year word ";
print " start_year: 起始年份 ";
print " end_year: 结束年份 ";
print " word: 要检索的词条 ";
print " 注意:词条中不可含有空格 ";
exit;
}
$start_year = $ARGV[0];
$end_year = $ARGV[1];
$word = $ARGV[2];
my $path_curf = File::Spec->rel2abs(__FILE__);
my($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime(time);
$cm = $mon+1;
$cy = $year+1900;
$dir = dirname($path_curf)."\";
$sfn = $dir.$word;
%words = ();
if ((-e "$sfn.txt") ne 1) {
open (iBFILE, ">$sfn.txt") || die "$sfn.txt can not open! ";
$newtxt=encode(utf8,"x{feff}");
print iBFILE "$newtxt ";
close(iBFILE);
} else {
open (iBFILE, "<$sfn.txt") || die "$sfn.txt can not open! ";
@linelist=<iBFILE>;
foreach $eachline(@linelist){
@fields = split(/ /, $eachline);
$words{$fields[0]}=$fields[1];
}
close(iBFILE);
}
for ($y=$start_year; $y<=$end_year; $y++) {
$tm=12;
if ($y eq $cy) {$tm=$cm-1;}
for ($m=1; $m<=$tm; $m++) {
$mon=$m;
if ($m<10) {$mon = "0".$mon;}
$ym=$y."_".$mon;
if (!exists $words{$ym}) {
my $url = "http://58.68.146.102/rmrb/s?type=2&qs={"cds":[{"fld":"dataTime.start","cdr":"AND","hlt":"false","vlr":"OR","qtp":"DEF","val":"".$y."-".$mon."-01"},{"fld":"dataTime.end","cdr":"AND","hlt":"false","vlr":"OR","qtp":"DEF","val":"".$y."-".$mon."-31"},{"fld":"contentText","cdr":"AND","hlt":"true","vlr":"OR","qtp":"DEF","val":"".$word.""}],"obs":[{"fld":"dataTime","drt":"DESC"}]}";
$url=decode("gbk",$url);
$content=get($url);
$cpos=index($content,"allDataCount");
if($cpos>0) {
$content=substr($content,$cpos+14,20);
$content=substr($content,0,index($content,"<"));
print $y."_".$mon.": ".$content." ";
open (iBFILE, ">>$sfn.txt") || die "$sfn.txt can not open! ";
printf iBFILE "%s %s ", $y."_".$mon, $content;
close(iBFILE);
}
}
}
}
print " 操作已完成!结果保存至: $sfn.txt ";
#############################
要使用这一 Perl 脚本程序,用户需事先安装好 ActivePerl 程序,并配置好相应的运行环境变量。然后在 Dos 命令行窗口中调用该脚本程序,并设定好相应的运行参数,如下图所示:

图2:调用脚本程序的命令行及其参数
上一命令行包含三个控制参数:起始年份,如上图的“2010”;结束年份,如上图的“2017”;关键词,如上图的“中国梦”。运行上一命令,脚本程序将逐月从《人民日报》网站上提取2010年至2017年之间出现“中国梦”一词的次数,得到并输出类似于以下格式的数据文件:
表1:“中国梦”的动态词频

在 Excel 程序中将上表1中的词频数据做成折线图,结果大致如下图3所示,从中我们可以较为清晰地观察出词频的动态变化。
下面给出了几个词语的词频数据检索结果:
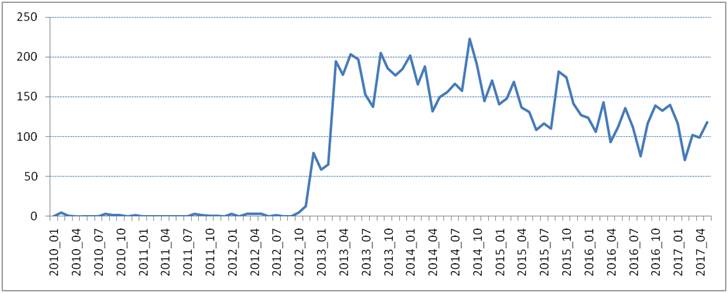
图3:“中国梦”的动态词频(2010-2017)
图4:“奥运会”的动态词频(2000-2017)
图5:“改革开放”的动态词频(1978-2017)
以上是关于Perl 脚本自动提取《人民日报》全文数据库中的动态词频数据的主要内容,如果未能解决你的问题,请参考以下文章