perl提取新浪博客博文地址
Posted 潇湘蘑菇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了perl提取新浪博客博文地址相关的知识,希望对你有一定的参考价值。
贴一张大牛博客首页图片(樊老师),表示敬仰与感谢。
首先,进入“博文目录”列表,发现樊老师的博文共有7页:
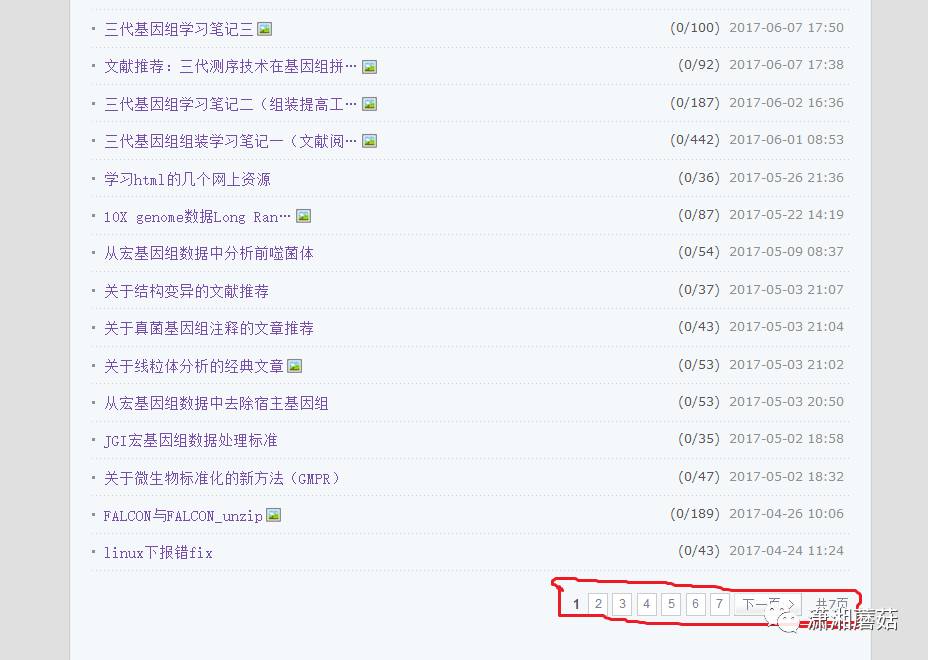
我们点进每页,查看网址:
第一页:http://blog.sina.com.cn/s/articlelist_2214034580_0_1.html
第二页:http://blog.sina.com.cn/s/articlelist_2214034580_0_2.html
。。。。。。。
第七页:http://blog.sina.com.cn/s/articlelist_2214034580_0_7.html
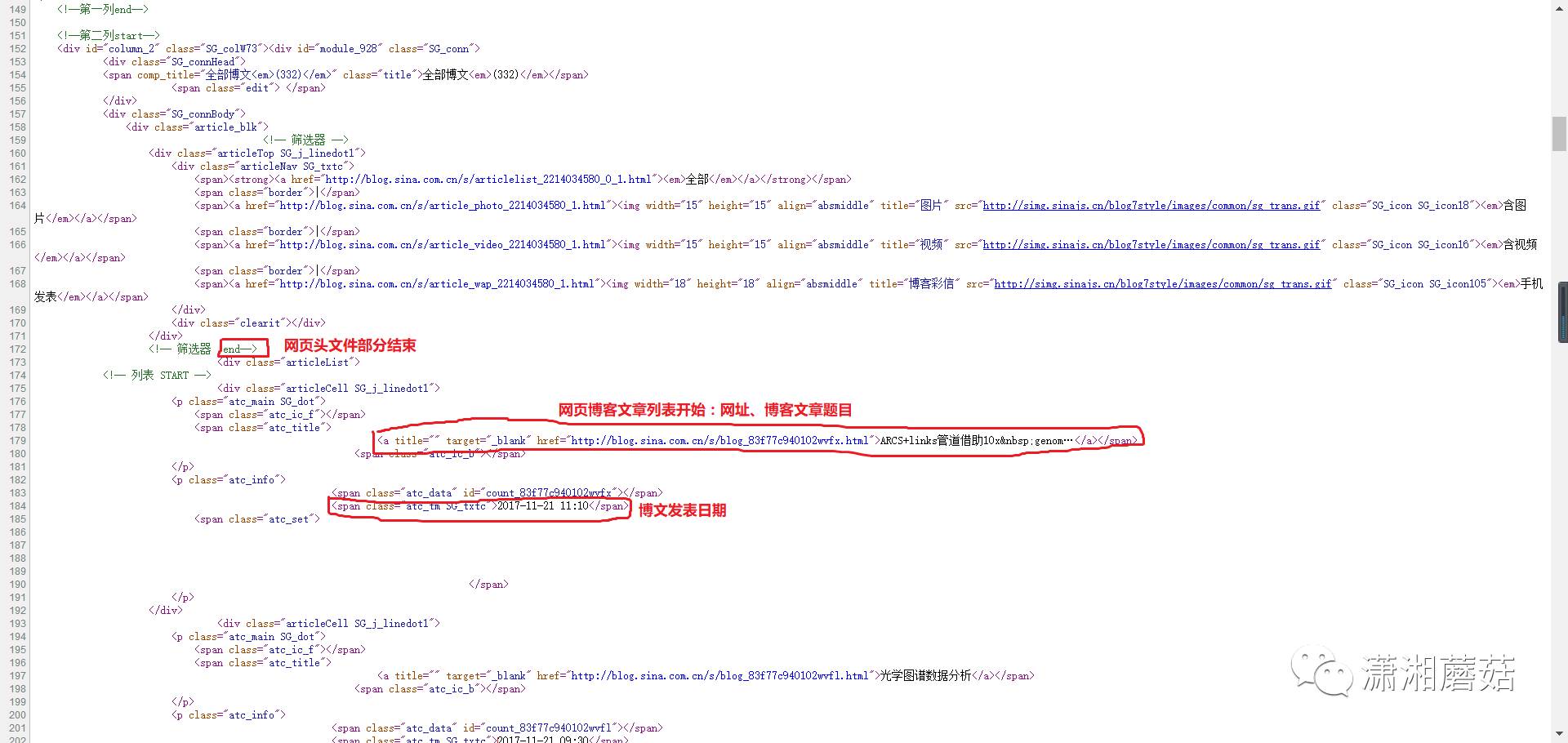
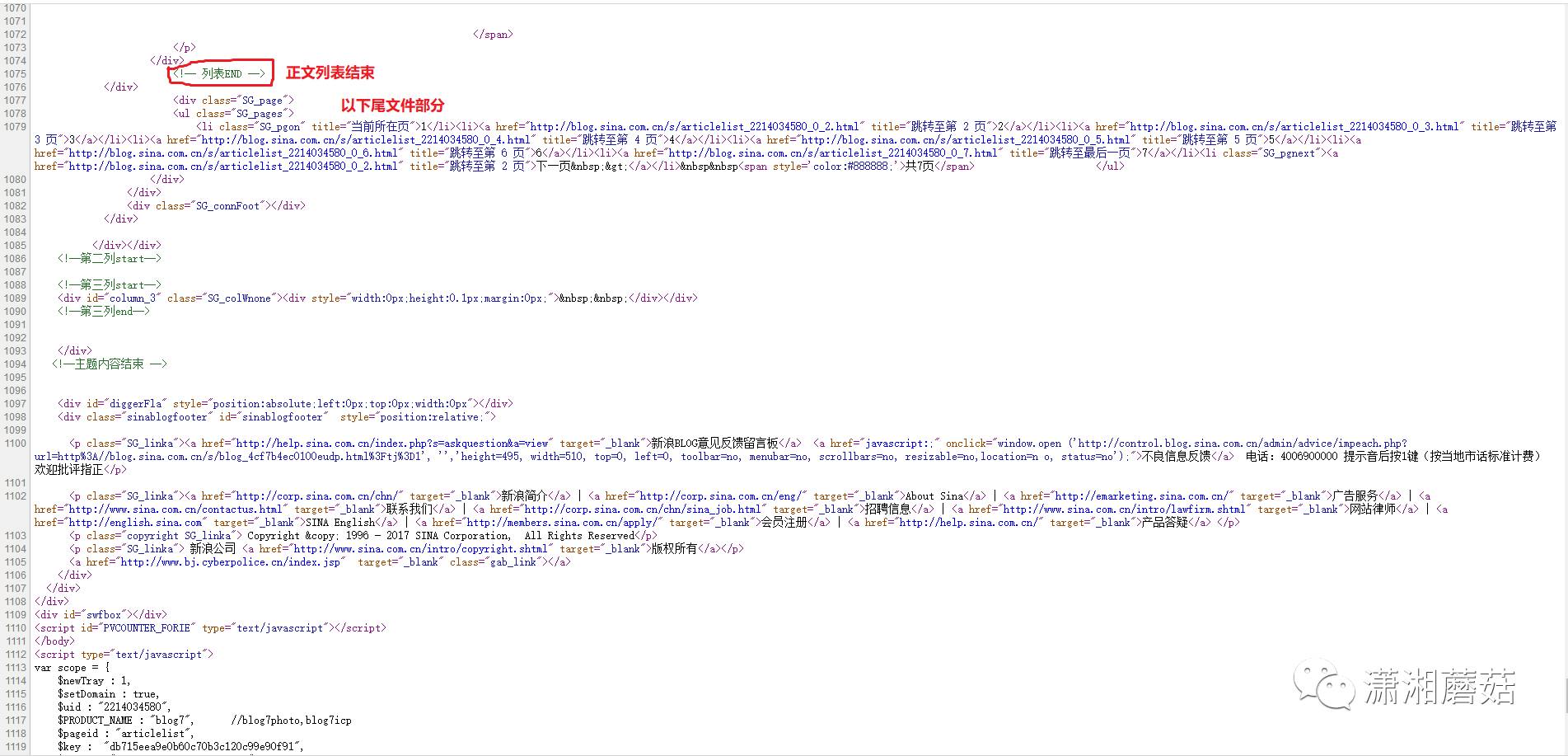
我们发现源代码页主要分为三个部分:
1.页面头文件部分,不含正文列表
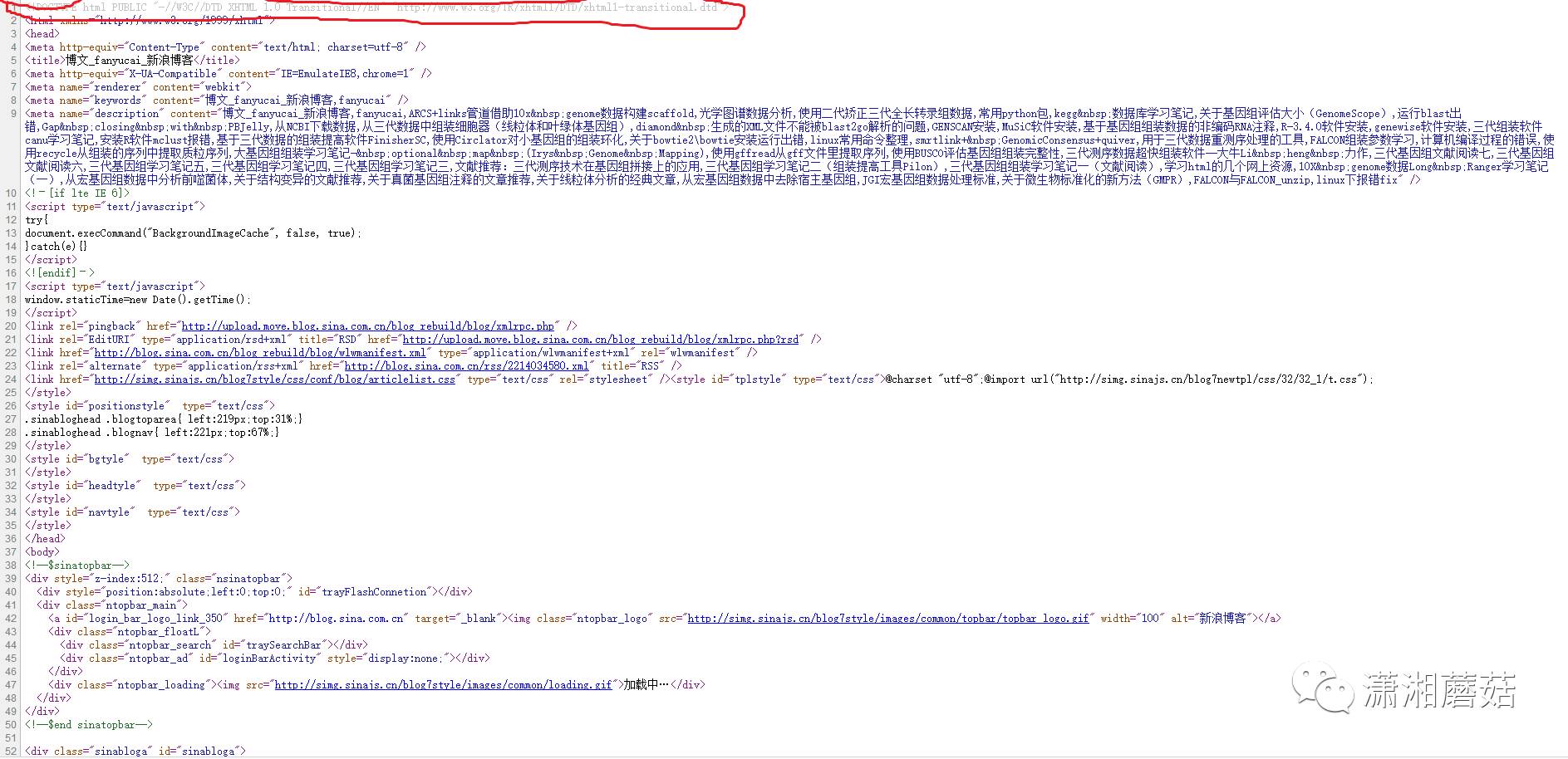
2.正文列表部分
3.页面尾文件部分
#!/usr/bin/perl
use strict;
use LWP::UserAgent;#申明使用LWP::UserAgent模块
open OUTPUT,'>>','fanyucai_blog.txt' or die 'Open fanyucai_blog.txterror!';#追加方式打开文件句柄,用于存放获得的博客信息
my $get_page = LWP::UserAgent -> new;#调用LWP::UserAgent的”new“方法创建$get_page对象
$get_page -> timeout(10);#timeout:10s
my $page_addr;#申明一系列私有变量
my $response;
my $content;
my $blog_title;
my $blog_addr;
my $blog_date;
&print_list();#调用perl子函数,sub以下定义子函数
sub print_list{
foreach (1..7){
print OUTPUT"page.$_ ";#打印page到输出文件并换行
$page_addr ='http://blog.sina.com.cn/s/articlelist_2214034580_0_'.$_.'.html';#每页的网址,变量$_读取foreach循环每次读入的数字,点号为连接符;
$response = $get_page -> get($page_addr);
$content = $response ->content;#获得网页源代码内容并赋值给content
print $_."done ";#打印页面处理进度
$content =~ s/DOCTYPE.+?START/s/xs;#除去源代码中的页面头文件内容
$content =~ s/ENDs-->.*/s/xs;#除去源代码中的页面尾文件内容
while ($content =~ s/target=.+?blank.+?href="(.+?)">(.+?)<.+?(d{4}-d{2}-d{2}.+?)<//xs){#while循环获取正文列表中博文题目、网址、发表日期并输出到文件
$blog_title = $2;
$blog_addr = $1;
$blog_date = $3;
print OUTPUT "$blog_title $blog_addr $blog_date ";
}}}
将以上代码存为blog_sites_parse.pl。在cmd命令行或shell中输入perl blog_sites_parse.pl运行,即得到名字为fanyucai_blog.txt的文件:
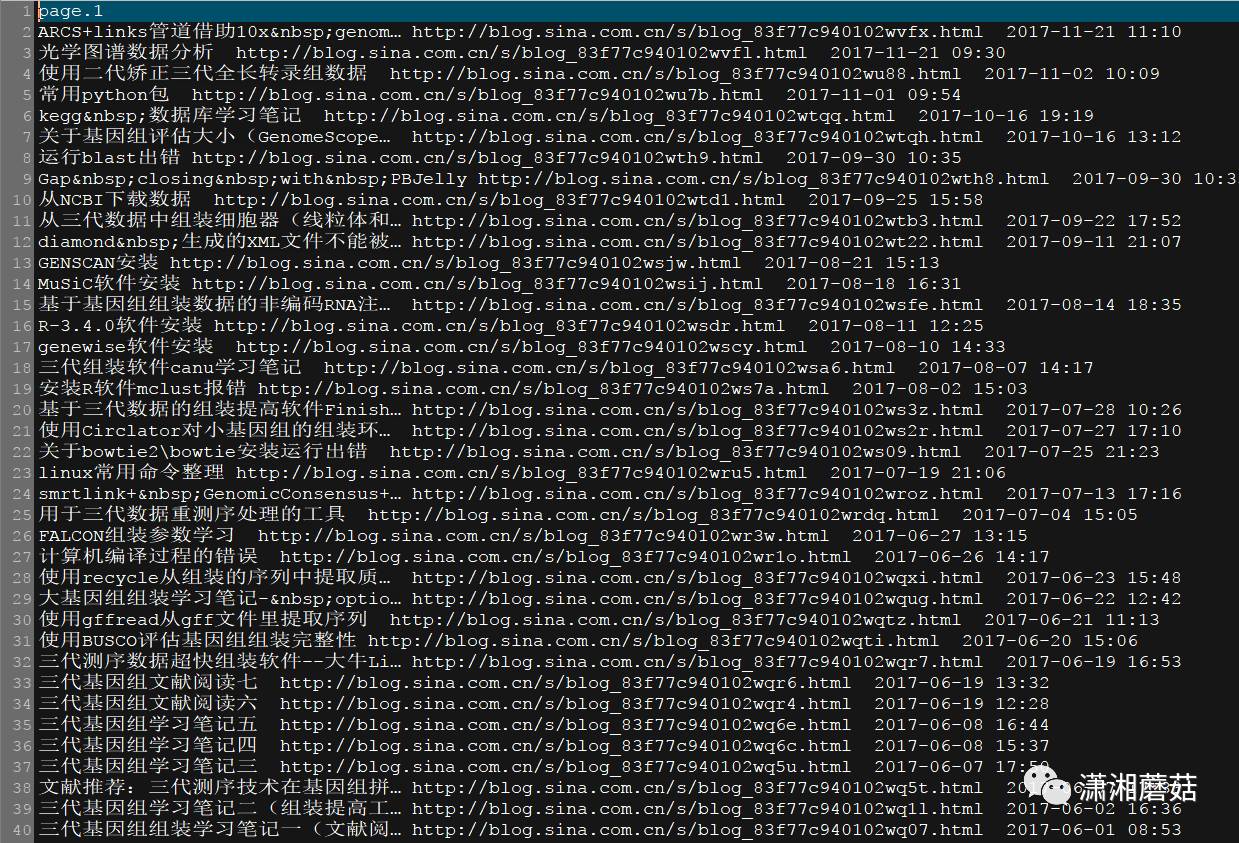
接下来三周目测很忙,更新困难。接下来想利用网址列表获取正文内容,等忙完这阵再说吧。顺利勾搭一个程序员跟我一起学shell脚本了
P.S.新手入门,有错误欢迎后台联系。
以上是关于perl提取新浪博客博文地址的主要内容,如果未能解决你的问题,请参考以下文章