用Perl处理语言信息问题之一
Posted 小试机
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Perl处理语言信息问题之一相关的知识,希望对你有一定的参考价值。
上一篇中整理了Perl的基本语法知识,详见:https://mp.weixin.qq.com/s/p4lOc98OKeYSJRTFfbN6nw 本篇列举几个Perl在语言信息处理方面的使用,例子代码全部来自于《实战Perl——语言信息处理利器》一书,代码稍作了些改动(挺好的一本书,有需要的可以买来看看),本篇是Perl的简单应用。废话不多说,直接上例子。
统计文件词频
任务:词表文件ci_biao.txt文件中存储了很多词语,并且一行仅有一个词语,内容如下图所示,要求从此文件中读取词语数据,统计每个词语出现的次数和频率。
期望结果:
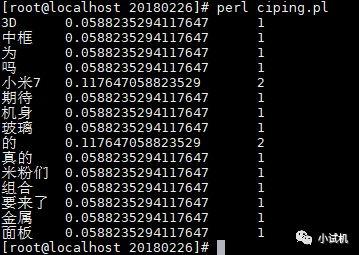
代码实现:
#实现思想:读取文件每一行,然后建立一个key是词语,value是次数的散列(或者叫哈希)。同时记录总的词语数,最后遍历输出key和value,得到每个词语出现的频率和频次。
#!/usr/bin/perl -w
use strict;
use warnings;
my %hash;
#打开进行词表文件
open(In, "ci_biao.txt") or die "Can't not open this file: $!";
#统计词表中总的词数,以便计算词出现的频率
my $i = 0;
while (my $line = <In>) {
#去掉换行符
chomp($line);
#查找当前的词是否在散列中,如果在,频次加1,否则频次设置为1
if (defined $hash{$line}) {
$hash{$line}++;
}else{
$hash{$line}=1;
}
$i++;
}
close(In);
#遍历输出结果
foreach my $element (sort keys %hash) {
my $tf = $hash{$element}/$i;
print "$element $tf $hash{$element} ";
}
合并两个词表
任务:有两个词表,将两个词表合并, 保证合并后的词表中没有重复的词语 两个词表如下所示:

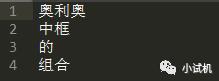
期望结果:
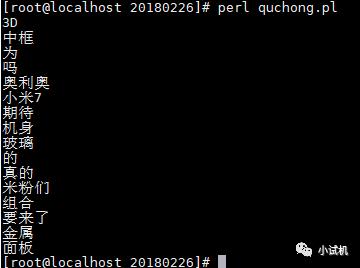
代码实现:
#实现思想:利用哈希key唯一的特性,以词语作为key,key相同的情况下会相互覆盖,最后输出所有的key,就是去重后的词表
#!/usr/bin/perl -w
use strict;
use warnings;
#打开一个词表文件
my %hash;
open(In1, "ci_biao1.txt") or die "Can't not open this file: $!";
while (<In1>) {
chomp;
$hash{$_} = 1;
}
close(In1);
#打开另一个词表,并进行去重的操作
open(In2, "ci_biao2.txt") or die "Can't not open this file: $!";
while (<In2>) {
chomp;
$hash{$_} = 1;
}
close(In2);
#输出去重后的词表
foreach my $element (sort keys %hash) {
print $element." ";
}
求两个词表的交集
任务:打印出两个词表中相同的词语,词表仍然使用 cibiao1.txt 和 cibiao2.txt. 期望结果:
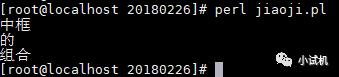
代码实现:
#实现思路:先将一个词表的信息读入哈希变量中,然后读取另一个词表的词语,在哈希变量中查找,如果找到则认为是共同的词语,并打印出来
#!/usr/bin/perl -w
use strict;
use warnings;
#打开一个词表文件
my %hash;
open(In1, "ci_biao1.txt") or die "Can't not open this file: $!";
while (<In1>) {
chomp;
$hash{$_} = 1;
}
close(In1);
#打开另一个词表,并进行去重的操作
open(In2, "ci_biao2.txt") or die "Can't not open this file: $!";
while (<In2>) {
chomp;
if (defined $hash{$_}) {
print "$_ ";
}
}
close(In2);
查词表
任务:给定一个带有译文的词表文件,具体内容见图4,编写Perl程序,实现用户输入一个单词,程序输出该单词的译文,如果找不到,则输出 no found.
词表文件:
代码实现:
#实现思想:以词表文件中的单词为key,单词的译文为value,存入哈希中。查询就是以输入的单词为key,查到结果并打印出来。
#!/usr/bin/perl -w
use strict;
use warnings;
#读取词典文件
my %hash;
open(In1, "dict.txt") or die "Can't not open this file: $!";
while (<In1>) {
chomp;
#以 => 进行切割成单词和译文
my @array = split("=>");
#去除单词前后的空格
$array[0] =~ s/(^s+|s+$)//g;
$array[1] =~ s/(^s+|s+$)//g;
$hash{$array[0]} = $array[1];
}
close(In1);
#while循环接收用户多次输入,直到用户输入 q 时退出
while (1) {
print "please input a word ('q' for exit): ";
my $input = <>;
chomp($input);
if ($input eq 'q') {
print "exit! ";
exit(0);
}
#查找单词
if (defined $hash{$input}) {
print "translation: $hash{$input} ";
}else{
print "no found! ";
}
}
汉语分词
任务:分词是将一句话划分成一个个独立的单词。例如:爱是恒久忍耐,又有恩慈。分词之后为:爱/是/恒久/忍耐,又/有/恩慈。(书中的原话,这句话出自圣经·新约)本例采用最大正向分词法进行分词。 例如:读入 '爱是持久忍耐',检索词表,并没有发现 '爱是持久忍耐'一词,则删除末尾一个字,变成'爱是持久忍',继续检索词表,直到找到一个完整的词,然后检索除这个词以外的部分,递归执行。
输入:爱是恒久忍耐,又有恩慈。 期望输出:爱/是/恒久/忍耐,又/有/恩慈。
代码实现:
#实现思想:把词表读入哈希变量中,并记录词表词语的最大长度。
#读入用户输入后,通过不断的删除最右边的一个字后,检索词表,找到命中的词语,加上 / ,然后递归检索剩下的部分。
#!/usr/bin/perl -w
use strict;
use warnings;
#读取词表文件的内容
my $maxLen = 0;
my %mapDict;
ReadDict("word.txt");
print "please input a sentence:('q' for exit): =>";
while (1) {
my $sentence = <>;
chomp($sentence);
if ($sentence eq 'q') {
exit;
}
#调用额分词函数进行分词
my $result = Segment($sentence);
print $result;
}
#读取词表信息,同时记录最大的长度
sub ReadDict {
my ($Dict) = @_;
open(In, $Dict) or die "Can't not open this file:$!";
#记录词表中最长的词语的长度
while (my $line = <In>) {
chomp($line);
$mapDict{$line} = length($line);
if (length($line) > $maxLen) {
$maxLen = length($line);
}
}
close(In);
}
#分词
sub Segment {
my ($aSentence) = @_;
#$segm为分词后结果,$remain为还需要分词的部分
my $segm = "";
my $remain = $aSentence;
while (length($remain) > 0) {
my $flag = 0; #代表是否从词表中找到该词
#如果没有匹配,则将当前的字符强制判断为一个词语
for (my $i = $maxLen; $i > 1; $i--) {
my $matchStr = substr($remain, 0, $i);
if (defined $mapDict{$matchStr}) {
$segm .= $matchStr."/";
$remain = substr($remain, $i, length($remain) - $i);
$flag = 1;
last;
}
}
if ($flag == 0) {
$segm .= substr($remain, 0, 1)."/";
$remain = substr($remain, 1, length($remain) - 1);
}
}
return $segm;
}
参考文献
[1]荀恩东,黄志娥,饶高琦,谢佳丽.实战Perl——语言信息处理利器[M].北京:清华大学出版社,2013.
关于小试机
以上是关于用Perl处理语言信息问题之一的主要内容,如果未能解决你的问题,请参考以下文章