HyperLogLog函数在Spark中的高级应用
Posted 浪尖聊大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HyperLogLog函数在Spark中的高级应用相关的知识,希望对你有一定的参考价值。
预聚合是高性能分析中的常用技术,例如,每小时100亿条的网站访问数据可以通过对常用的查询纬度进行聚合,被降低到1000万条访问统计,这样就能降低1000倍的数据处理量,从而在查询时大幅减少计算量,提升响应速度。更高层的聚合可以带来进一步的性能提升,例如,在时间维按天聚合,或者通过站点而不是URL聚合。
本文,我们将介绍 spark-alchemy这个开源库中的 HyperLogLog 这一个高级功能,并且探讨它是如何解决大数据中数据聚合的问题。首先,我们先讨论一下这其中面临的挑战。
再聚合(Reaggregation)的挑战
预聚合是数据分析领域的一个强大的技术手段,前提就是所要计算的指标是可重聚合的。聚合操作,顾名思义,是满足结合律的,所以很容易引入再聚合操作,因为聚合操作可以再被进一步聚合。Counts 可以在通过 SUM 再聚合,最小值可以通过 MIN 再聚合,最大值也可以通过 MAX 再聚合。而 distinct counts 是特例,无法做再聚合,例如,不同网站访问者的 distinct count 的总和并不等于所有网站访问者的 distinct count 值,原因很简单,同一个用户可能访问了不同的网站,直接求和就存在了重复统计的问题。
Distinct count 的不可再聚合的特性造成了很大的影响,计算 distinct count 必须要访问到最细粒度的数据,更进一步来说,就是计算 distinct count 的查询必须读取每一行数据。
2~8倍的性能提升是相当可观的,不过它牺牲的精确性,大于等于 1% 的最大偏差率在某些场合可能是无法被接受的。 另外,2~8倍的性能提升在预聚合所带来的上千倍的性能提升面前也是微不足道的,那我们能做什么?
HyperLogLog 算法回顾
Map (每个 partition)
初始化 HLL 数据结构,称作 HLL sketch
将每个输入添加到 sketch 中
发送 sketch
Reduce
聚合所有 sketch 到一个 aggregate sketch 中
Finalize
计算 aggregate sketch 中的 distinct count 近似值
另外这个算法还能带来另一个同样重要的好处: 我们不再限于性能问题向估算精度妥协(大于等于1%的估算偏差)。 由于预聚合能够带来上千倍的性能提升,我们可以创建估算偏差非常低的 HLL sketch,因为在上千倍的查询性能提升面前,我们完全能够接受预聚合阶段2~5倍的计算耗时。 这在大数据业务中基本相当于是免费的午餐: 带来巨大性能提升的同时,又不会对大部分业务端的用户造成负面影响。
Spark-Alchemy 简介:HLL Native 函数
下图所示为 spark-alchemy 处理 initial aggregation (通过
hll_init_agg
), reaggregation (通过
hll_merge
) 和 presentation (通过
hll_cardinality
)。
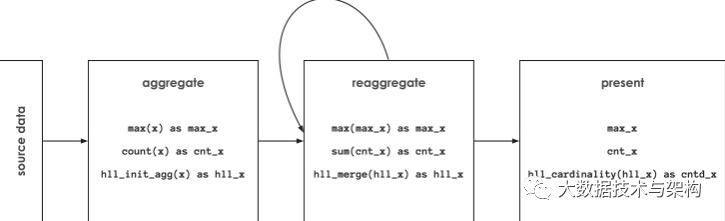
HyperLogLog 互通性
交互式分析系统的一个关键要求是快速的查询响应。而这并不是很多诸如 Spark 和 BigQuery 的大数据系统的设计核心,所以很多场景下,交互式分析查询通过关系型或者 NoSQL 数据库来实现。如果 HLL sketch 不能实现数据层面的互通性,那我们又将回到原点。
为了解决这个问题,在 spark-alchemy 项目里,使用了公开的 存储标准,内置支持 Postgres 兼容的数据库,以及 javascript。这样使得 Spark 能够成为全局的数据预处理平台,能够满足快速查询响应的需求,例如 portal 和 dashboard 的场景。这样的架构可以带来巨大的受益:
99+%的数据仅通过 Spark 进行管理,没有重复
在预聚合阶段,99+%的数据通过 Spark 处理
交互式查询响应时间大幅缩短,处理的数据量也大幅较少
总结
以上是关于HyperLogLog函数在Spark中的高级应用的主要内容,如果未能解决你的问题,请参考以下文章