教程 | face-api.js:在浏览器中进行人脸识别的JavaScript接口
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了教程 | face-api.js:在浏览器中进行人脸识别的JavaScript接口相关的知识,希望对你有一定的参考价值。
选自IT Next
机器之心编译
参与:Geek AI、张倩
本文将为大家介绍一个建立在「tensorflow.js」内核上的 javascript API——「face-api.js」,它实现了三种卷积神经网络架构,用于完成人脸检测、识别和特征点检测任务,可以在浏览器中进行人脸识别。
号外!号外!现在人们终于可以在浏览器中进行人脸识别了!本文将为大家介绍「face-api.js」,这是一个建立在「tensorflow.js」内核上的 javascript 模块,它实现了三种卷积神经网络(CNN)架构,用于完成人脸检测、识别和特征点检测任务。
face-api.js:https://github.com/justadudewhohacks/face-api.js
TensorFlow.js:https://github.com/tensorflow/tfjs-core
像往常一样,我们将查看一个简单的代码示例,这将使你能立即通过短短几行代码中的程序包开始了解这个 API。让我们开始吧!
我们已经有了「face-recognition.js」,现在又来了另一个同样的程序包?
如果你阅读过本文作者另一篇关于「node.js」环境下进行人脸识别的文章《Node.js + face-recognition.js : Simple and Robust Face Recognition using Deep Learning》(Node.js + face-recognition.js:通过深度学习实现简单而鲁棒的人脸识别)(https://medium.com/@muehler.v/node-js-face-recognition-js-simple-and-robust-face-recognition-using-deep-learning-ea5ba8e852),你就会知道他在之前组装过一个类似的程序包,例如「face-recgnition.js」,从而为「node.js」引入了人脸识别功能。
起初,作者并没有预见到 JavaScript 社区对与人脸识别程序包的需求程度如此之高。对许多人而言,「face-recognition.js」似乎是一个不错的、能够免费试用的开源选项,它可以替代由微软或亚马逊等公司提供的付费人脸识别服务。但是作者曾多次被问道:是否有可能在浏览器中运行完整的人脸识别的工作流水线?
多亏了「tensorflow.js」,这种设想最终变为了现实!作者设法使用「tf.js
」内核实现了部分类似的工具,它们能得到和「face-recognition.js」几乎相同的结果,但是作者是在浏览器中完成的这项工作!而且最棒的是,这套工具不需要建立任何的外部依赖,使用它非常方便。并且这套工具还能通过 GPU 进行加速,相关操作可以使用 WebGL 运行。
这足以让我相信,JavaScript 社区需要这样的一个为浏览器环境而编写的程序包!可以设想一下你能通过它构建何种应用程序。
如何利用深度学习解决人脸识别问题
如果想要尽快开始实战部分,那么你可以跳过这一章,直接跳到代码分析部分去。但是为了更好地理解「face-api.js」中为了实现人脸识别所使用的方法,我强烈建议你顺着这个章节阅读下去,因为我常常被人们问到这个问题。
为简单起见,我们实际想要实现的目标是在给定一张人脸的图像时,识别出图像中的人。为了实现这个目标,我们需要为每一个我们想要识别的人提供一张(或更多)他们的人脸图像,并且给这些图像打上人脸主人姓名的标签作为参考数据。现在,我们将输入图像和参考数据进行对比,找到与输入图像最相似的参考图像。如果有两张图像都与输入足够相似,那么我们输出人名,否则输出「unknown」(未知)。
听起来确实是个好主意!然而,这个方案仍然存在两个问题。首先,如果我们有一张显示了多人的图像,并且我们需要识别出其中所有的人,将会怎样呢?其次,我们需要建立一种相似度度量手段,用来比较两张人脸图像。
人脸检测
我们可以从人脸检测技术中找到第一个问题的答案。简单地说,我们将首先定位输入图像中的所有人脸。「face-api.js」针对人脸检测工作实现了一个 SSD(Single Shot Multibox Detector)算法,它本质上是一个基于 MobileNetV1 的卷积神经网络(CNN),在网络的顶层加入了一些人脸边框预测层。
该网络将返回每张人脸的边界框,并返回每个边框相应的分数,即每个边界框表示一张人脸的概率。这些分数被用于过滤边界框,因为可能存在一张图片并不包含任何一张人脸的情况。请注意,为了对边界框进行检索,即使图像中仅仅只有一个人,也应该执行人脸检测过程。

人脸特征点检测及人脸对齐
在上文中,我们已经解决了第一个问题!然而,我想要指出的是,我们需要对齐边界框,从而抽取出每个边界框中的人脸居中的图像,接着将其作为输入传给人脸识别网络,因为这样可以使人脸识别更加准确!
为了实现这个目标,「face-api.js」实现了一个简单的卷积神经网络(CNN),它将返回给定图像的 68 个人脸特征点:

从特征点位置上看,边界框可以将人脸居中。你可以从下图中看到人脸检测结果(左图)与对齐后的人脸图像(右图)的对比:

人脸识别
现在,我们可以将提取出的对齐后的人脸图像输入到人脸识别网络中,该网络基于一个类似于 ResNet-34 的架构,基本上与 dlib(https://github.com/davisking/dlib/blob/master/examples/dnn_face_recognition_ex.cpp)中实现的架构一致。该网络已经被训练去学习出人脸特征到人脸描述符的映射(一个包含 128 个值的特征向量),这个过程通常也被称为人脸嵌入。
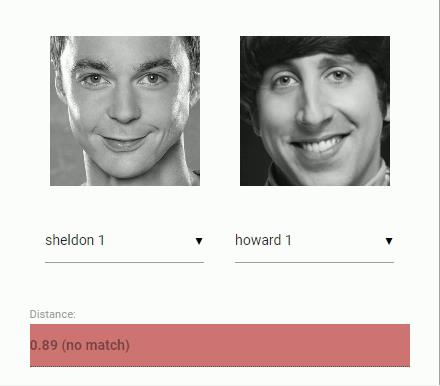
现在让我们回到最初对比两张人脸图像的问题:我们将使用每张抽取出的人脸图像的人脸描述符,并且将它们与参考数据的人脸描述符进行对比。更确切地说,我们可以计算两个人脸描述符之间的欧氏距离,并根据阈值判断两张人脸图像是否相似(对于 150*150 的图像来说,0.6 是一个很好的阈值)。使用欧氏距离的效果惊人的好,当然,你也可以选用任何一种分类器。下面的 gif 动图可视化了通过欧氏距离比较两张人脸图像的过程:
至此,我们已经对人脸识别的理论有所了解。接下来让我们开始编写一个代码示例。
是时候开始编程了!
在这个简短的示例中,我们将看到如何一步步地运行人脸识别程序,识别出如下所示的输入图像中的多个人物:

导入脚本
首先,从 dist/face-api.js 获得最新的版本(https://github.com/justadudewhohacks/face-api.js/tree/master/dist),或者从 dist/face-api.min.js 获得缩减版,并且导入脚本:
<script src="face-api.js"></script>
如果你使用 npm 包管理工具,可以输入如下指令:
npm i face-api.js
加载模型数据
你可以根据应用程序的要求加载你需要的特定模型。但是如果要运行一个完整的端到端的示例,我们还需要加载人脸检测、人脸特征点检测和人脸识别模型。相关的模型文件可以在代码仓库中找到,链接如下:https://github.com/justadudewhohacks/face-api.js/tree/master/weights。
其中,模型的权重已经被量化,文件大小相对于初始模型减小了 75%,使你的客户端仅仅需要加载所需的最少的数据。此外,模型的权重被分到了最大为 4 MB 的数据块中,使浏览器能够缓存这些文件,这样它们就只需要被加载一次。
模型文件可以直接作为你的 web 应用中的静态资源被使用,或者你可以将它们存放在另外的主机上,通过指定的路径或文件的 url 链接来加载。假如你将它们与你在 public/models 文件夹下的资产共同存放在一个 models 目录中:
const MODEL_URL = '/models'
await faceapi.loadModels(MODEL_URL)
或者,如果你仅仅想要加载特定的模型:
const MODEL_URL = '/models'
await faceapi.loadFaceDetectionModel(MODEL_URL)
await faceapi.loadFaceLandmarkModel(MODEL_URL)
await faceapi.loadFaceRecognitionModel(MODEL_URL)
从输入图像中得到对所有人脸的完整描述
该神经网络可以接收 html 图像、画布、视频元素或张量(tensor)作为输入。为了检测出输入图像中分数(score)大于最小阈值(minScore)的人脸边界框,我们可以使用下面的简单操作:
const minConfidence = 0.8
const fullFaceDescriptions = await faceapi.allFaces(input, minConfidence)
一个完整的人脸描述符包含了检测结果(边界框+分数),人脸特征点以及计算出的描述符。正如你所看到的,「faceapi.allFaces」在底层完成了本文前面的章节所讨论的所有工作。然而,你也可以手动地获取人脸定位和特征点。如果这是你的目的,你可以参考 github repo 中的几个示例。
请注意,边界框和特征点的位置与原始图像/媒体文件的尺寸有关。当显示出的图像尺寸与原始图像的尺寸不相符时,你可以简单地通过下面的方法重新调整它们的大小:
const resized = fullFaceDescriptions.map(fd => fd.forSize(width, height))
我们可以通过将边界框在画布上绘制出来对检测结果进行可视化:
fullFaceDescription.forEach((fd, i) => {
faceapi.drawDetection(canvas, fd.detection, { withScore: true })
})

可以通过下面的方法将人脸特征点显示出来:
fullFaceDescription.forEach((fd, i) => {
faceapi.drawLandmarks(canvas, fd.landmarks, { drawLines: true })
})

通常,我会在 img 元素的顶层覆盖一个具有相同宽度和高度的绝对定位的画布(想获取更多信息,请参阅 github 上的示例)。
人脸识别
当我们知道了如何得到给定的图像中所有人脸的位置和描述符后,我们将得到一些每张图片显示一个人的图像,并且计算出它们的人脸描述符。这些描述符将作为我们的参考数据。
假设我们有一些可以用的示例图片,我们首先从一个 url 链接处获取图片,然后使用「faceapi.bufferToImage」从它们的数据缓存中创建 HTML 图像元素:
// fetch images from url as blobs
const blobs = await Promise.all(
['sheldon.png' 'raj.png', 'leonard.png', 'howard.png'].map(
uri => (await fetch(uri)).blob()
)
)
// convert blobs (buffers) to HTMLImage elements
const images = await Promise.all(blobs.map(
blob => await faceapi.bufferToImage(blob)
))
接下来,在每张图像中,正如我们之前对输入图像所做的那样,我们对人脸进行定位、计算人脸描述符:
const refDescriptions = await Promsie.all(images.map(
img => (await faceapi.allFaces(img))[0]
))
const refDescriptors = refDescriptions.map(fd => fd.descriptor)
现在,我们还需要做的就是遍历我们输入图像的人脸描述符,并且找到参考数据中与输入图像距离最小的描述符:
const sortAsc = (a, b) => a - b
const labels = ['sheldon', 'raj', 'leonard', 'howard']
const results = fullFaceDescription.map((fd, i) => {
const bestMatch = refDescriptors.map(
refDesc => ({
label: labels[i],
distance: faceapi.euclideanDistance(fd.descriptor, refDesc)
})
).sort(sortAsc)[0]
return {
detection: fd.detection,
label: bestMatch.label,
distance: bestMatch.distance
}
})
正如前面提到的,我们在这里使用欧氏距离作为一种相似度度量,这样做的效果非常好。我们在输入图像中检测出的每一张人脸都是匹配程度最高的。
最后,我们可以将边界框和它们的标签一起绘制在画布上,显示检测结果:
// 0.6 is a good distance threshold value to judge
// whether the descriptors match or not
const maxDistance = 0.6
results.forEach(result => {
faceapi.drawDetection(canvas, result.detection, { withScore: false })
const text = `${result.distance < maxDistance ? result.className : 'unkown'} (${result.distance})`
const { x, y, height: boxHeight } = detection.getBox()
faceapi.drawText(
canvas.getContext('2d'),
x,
y + boxHeight,
text
)
})
至此,我希望你对如何使用这个 API 有了一个初步的认识。同时,我也建议你看看文中给出的代码仓库中的其它示例。好好地把这个程序包玩个痛快吧!
原文链接:https://itnext.io/face-api-js-javascript-api-for-face-recognition-in-the-browser-with-tensorflow-js-bcc2a6c4cf07
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
以上是关于教程 | face-api.js:在浏览器中进行人脸识别的JavaScript接口的主要内容,如果未能解决你的问题,请参考以下文章
使用 face-api.js 进行人脸检测后,有啥方法可以自动裁剪人脸?