美丽的邂逅:当UML遇上Xgboost
Posted 66号学苑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了美丽的邂逅:当UML遇上Xgboost相关的知识,希望对你有一定的参考价值。
学习过机器学习的同学都知道,从大的概念讲,机器学习分为有监督、无监督、半监督和强化学习。其中,无监督在风控领域应用最为广泛的要数Clustering(聚类)和Anomaly Detection(异常值检测)两大派系。很长时间以来,Clustering都很不受待见,究其原因,主要有二:一是没有找到合适的应用场景,二是对于不那么合适的应用场景,没有进行多种方法的融合。
对于前者,各位同学可以想象一下,哪个行业,团伙欺诈最为猖獗和明显?毫无疑问,是互联网!举个最简单的例子:薅羊毛。单个人的薅羊毛行为,对一个平台的损失可以忽略不计,只有成团伙性质的薅羊毛才会带来巨额的损失。所以,从一个互联网平台的风控来看,可以毫不夸张地说,其只会在乎团伙欺诈(从欺诈分子的角度讲也是一样,只薅一根羊毛实在无意义,只有“一薅一大把”才叫爽)。这也是为什么,Clustering最开始在风控领域崭露头角时,选中了互联网行业。
对于后者,也就是不那么合适的应用场景,如何以Clustering为基础,做多种方法的融合,将是本文论述的重点。
Clustering最不合适的场景,要数那种单笔损失金额大,欺诈难度大的场景,以保险和金融最为典型。在这种场景下,团伙规模一般不大,通常为几人到几十人,上百人的就可以称为是重大案件了(相比之下,互联网的团伙大小通常为几百人/账号到几十万人/账号)。对于这种小型团伙,单靠Clustering已经很难看出异常了,这时,必须要靠多种方法的融合。说到多种方法的融合,黄姐姐最为欣赏的有两大算法:一是GMM(高斯混合模型),二是Xgboost,两大算法有异曲同工之妙:都是抱着开放的态度,不因一个feature而给出结论,告诉你yes or no。而是将其融合,从上帝视角和全局观来审视和定夺。如果算法也具有人格,那么这两大算法可谓是担负得起“海纳百川,有容乃大”这一夸赞了。
为了学习前辈们“有容乃大”的精神,Clustering在应用于金融反欺诈时,也必然需要两大“容”:一是同门“容”,二是跨门“容”。
一、同门“容”
举个例子,假设一个电商场景,绝大多数人都是在早晨9:00-凌晨1:00之间购物,这时,有个人在凌晨4点购物,单看时间,这个用户绝对可以说是异常值(上图中的UserA或者UserB),但实际上,这个人可能是好人(只是今晚失眠,为了打发时间购物),也可能是坏人,实在很难定夺。
但是,假设有一个这样的space,所有的用户就如上图所分布的那样。我们先通过Clustering把一些“长得像”的人聚在一起(称为cluster),再利用异常值检测的思路来判断其欺诈可能性,其欺诈信心指数就会高得多。这里,为了以示区分,我们不称其为“异常值检测”,而是称其为“异常群检测”。或者可以用一种更容易理解的说法来解释:一个人异常,我们不认为坏,一群“长得像”的人一起异常,我们才认为坏。这便是同门“容”最核心的理论基础。
如何定位异常群的中心值,想必算法大牛们各有各的方法,黄姐姐在此就不班门弄斧了。找到异常群的中心值后,就需要计算这个异常群的离群程度,进而判断其欺诈指数。这一离群程度的判定,应用最为广泛的当属Isolation forest(孤独森林,基于节点Level)和Auto-encoder(自编码,基于用户level)了。这里,要特别说明一下,在应用Isolation forest时,超平面不断地划分,最终不是把我们的目标打散成孤立个体(异常值),而是划分到我们Clustering的结果——cluster(异常群)。同样,对于Auto-encoder也是一样,可以利用异常群的中心值来作为计算,以判断这个cluster的异常情况(分享一个经验值,坏账率<2%的场景下,用auto-encoder效果较好)。
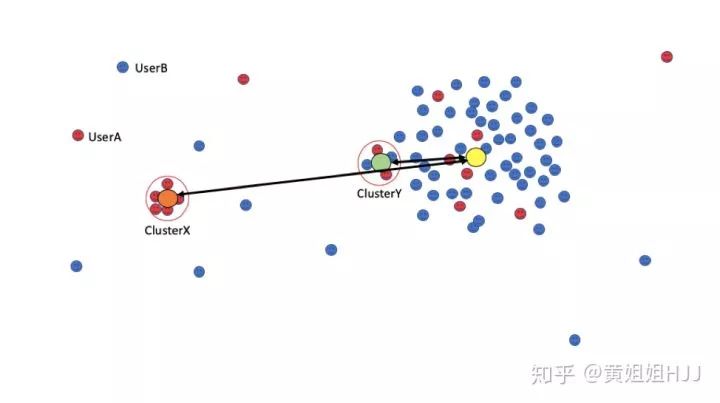
离群程度可以作为这个cluster是否有欺诈嫌疑的有效指标。例如,下图中的ClusterX和ClusterY。为了方便没有算法基础的人理解,我们可以简单地以重心的距离作为离群程度的指标。我们大概知道,这个space的重心在黄色圆点处,ClusterX的重心在橙色圆点处,ClusterY的重心在绿色圆点处。可以看到,ClusterX的重心与整个Space的重心距离更远,那么,往往这个Cluster坏的可能性就更大。
可能会有做策略的同学跳出来说,这样的话,是不是只能抓到那种包装拙劣的欺诈分子,包装精致的欺诈分子,往往“长得更像”正常人,或者说,他们更愿意往正常人靠拢。
其实不然,长得像不像,其实主要看feature选得好不好。就像黄姐姐在文章《如何通俗易懂地解释无监督学习》中所述,如果我们用体重来区分兔子和猫,通常是徒劳的。而如果我们选择用耳朵的形状来区分,才更有意义。其实,这也是信用风险和欺诈风险一个主要区别之一,即建模所用feature的选择和衍生方式不同。
二、跨门“容”
讲完同门“容”,我们再来看看跨门“容”。
跨门“容”,这里是指无监督和有监督的融合。有监督机器学习一直备受风控青睐,虽然有些有监督算法的可解释性极差,但奈何它准啊(比如回归算法)!
可以说,同门“容”解决了Clustering的先天弱势——只知道是不是团伙,不知道坏不坏的问题;那么,跨门“容”,其实解决了Clustering的另一个问题:到底有多坏。
在同门“容”篇末,我们遗留了一个问题,如何选择有效的feature。我们之所以知道要用耳朵形状来判断是猫还是兔子,而不应该选择体重,是因为我们太熟悉兔子和猫,这必然有“事后诸葛亮”之嫌。如果想做到能够选择有效的feature,我们要么靠深入虎穴,了解黑产攻击手法(卧底黑产,亲眼看到兔子和猫);要么靠历史逾期标签来学习(案件分析,看图书认识兔子和猫)。
如果能够做到以上两点中的任何一点,通常按照离群程度做一个排序,就可以回答“到底有多坏”这个问题了。
但事实往往不尽如人意。我们或者没有人力去卧底黑产,或者因为历史标签积累过少,我们选择的那些看起来有效的feature/feature组合,往往稳定性较差。这也很容易理解,毕竟人眼所目及的范围太有限——我们能挑出来的feature/feature组合太有限。
为了解决这一问题,现在,有请我们今天的另一嘉宾登场——Xgboost(掌声在哪里!)
Xgboost近年来风靡算法届,主要原因就是方法简单粗暴,效果稳准狠快。关于Xgboost的原理,大家可参考文末推荐阅读[1]。
Xgboost可以有效解决上面讲到的“人眼所目及的范围太有限”这一问题。我们一是不需要过分苛责建模工程师一定要选择特别有效的feature,打通领域知识壁垒;二是可以给“到底有多坏”一个更为稳定可靠的评判;三是除了团伙欺诈,也可以包罗部分个体欺诈,实现总体评分,用于计算某些业务要求的硬性指标,如KS(懂得无监督原理的人知道,无监督算法不适用于用KS来评判,因为并非是对全量用户评分)。
我们可以这么理解,我们建立了一个两级评分卡:第一级采用了同门“容”,也就是UML体系内的Clustering和Anomaly detection融合,找到哪些人可能坏;第二级采用了跨门“容”,也就是将第一级的结果作为输入,用Xgboost进行有监督学习,判断这些人“到底有多坏”,同时还能顺便检测一些个体欺诈,以及第一级由于feature选择限制遗漏的其他团伙欺诈。
最后,黄姐姐还是要再次跟大家分享一次小平爷爷的话:不管黑猫白猫,抓到老鼠就是好猫。
算法那么多,有的简而美,比如UML,可谓是大道至简。有的稳准狠,比如Xgboost,可谓是有容乃大。如果算法也有人格,那么UML和Xgboost的相遇,必然是世界上最美丽的灵魂邂逅~
作者|黄姐姐HJJ
来源|知乎
更多精彩,戳这里:
以上是关于美丽的邂逅:当UML遇上Xgboost的主要内容,如果未能解决你的问题,请参考以下文章