python从含有汉字和数字的字符串中提取数字部分
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python从含有汉字和数字的字符串中提取数字部分相关的知识,希望对你有一定的参考价值。
参考技术A 方法一、优点是通用,不需要知道字符串中具体的组成部分方法二、优点是简单易理解,但是需要知道字符串中的组成部分,具体以什么来分割
python中如何从字符串中提取数字?
比如:字符串如下:A1.45,b5,6.45,8.82
提取成:[1.45,5,6.45,8.82]
很着急!万分感谢!
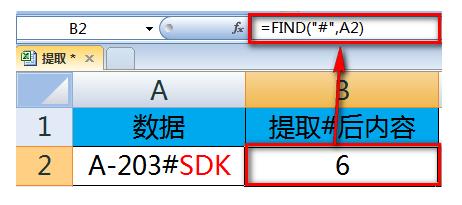
1、如下图,要提取#后面的字符,也即红色的“SDK”到B列。

2、首先,在B2中输入公式:
=FIND("#",A2)
返回#在字符串中的位置,#在A2单元格文本中是第6个字符。
3、知识点说明:
FIND()函数查找第一参数在第二参数中的位置。如下图,查找“B”在“ABCD”中是第几个字符。第一参数是要查找的字符“B”,第二参数是被查找的字符串。最终返回“B”在“ABCD”中是第2个字符。
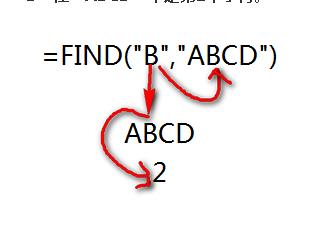
=MID(A2,FIND("#",A2)+1,99)
这样,就提取出了#后的字符。

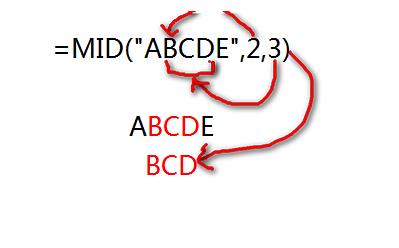
MID()函数返回从字符串中制定字符开始若干个字符的字符串。如下图,MID()函数返回“ABCDE”字符串中从第2个字符开始的连续3个字符,也就是返回“BCD”。
使用正则表达式,用法如下:
## 总结## ^ 匹配字符串的开始。
## $ 匹配字符串的结尾。
## \\b 匹配一个单词的边界。
## \\d 匹配任意数字。
## \\D 匹配任意非数字字符。
## x? 匹配一个可选的 x 字符 (换言之,它匹配 1 次或者 0 次 x 字符)。
## x* 匹配0次或者多次 x 字符。
## x+ 匹配1次或者多次 x 字符。
## xn,m 匹配 x 字符,至少 n 次,至多 m 次。
## (a|b|c) 要么匹配 a,要么匹配 b,要么匹配 c。
## (x) 一般情况下表示一个记忆组 (remembered group)。你可以利用 re.search 函数返回对象的 groups() 函数获取它的值。
## 正则表达式中的点号通常意味着 “匹配任意单字符”
解题思路:
2.1 既然是提取数字,那么数字的形式一般是:整数,小数,整数加小数;
2.2 所以一般是形如:----.-----;
2.3 根据上述正则表达式的含义,可写出如下的表达式:"\\d+\\.?\\d*";
2.4 \\d+匹配1次或者多次数字,注意这里不要写成*,因为即便是小数,小数点之前也得有一个数字;\\.?这个是匹配小数点的,可能有,也可能没有;\\d*这个是匹配小数点之后的数字的,所以是0个或者多个;
代码如下:
# -*- coding: cp936 -*-import re
string="A1.45,b5,6.45,8.82"
print re.findall(r"\\d+\\.?\\d*",string)
# ['1.45', '5', '6.45', '8.82']
string="A1.45,b5,6.45,8.82"
print(re.findall(r"\\d+\\.?\\d*",string))本回答被提问者采纳
以上是关于python从含有汉字和数字的字符串中提取数字部分的主要内容,如果未能解决你的问题,请参考以下文章