从UML到观察者模式
Posted 奔波儿灞取经
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从UML到观察者模式相关的知识,希望对你有一定的参考价值。
对象的基本关系
❝在面向对象思想中,对象的基本关系可以分为: 泛化、实现、依赖、关联、组合、聚合。
❞
泛化
泛化的标志为 实线三角形,如下:
表现在代码层面就是「继承(extends)」,三角形指向的是父类,简单记忆就是: 「指向父类」,上图就表示B继承A。
实现
实线的标志为 虚线三角形,如下:
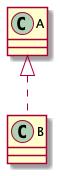
表示在代码层面就是「实现(implements)」,三角形指向的是接口,简单记忆就是: 「指向接口」,上图就表示B实现A。
❝泛化和实现的区别
❞
泛化表示的是一种本能,表示"是什么",是与生俱来的,比如A extends B,那么A就是B,也就是「is」关系;实现表示的是一种扩展关系,表示"可以干什么",是后天的,比如A implements B,表示A拥有B的本事,也就是A可以做B的事,也就是「has」关系,但是A却不是B,它只是拥有B的本领,这是一种扩展关系。泛化和实现都表示类之间的一种纵向关系,这是一种单向的上下级关系,A extends/implements B,B就不可能extends/implements A。正是这种严格的上下级关系,保证了进行面向对象设计时边界是正确的、清晰的。
关联
关联的标志为 实线箭头,如下:
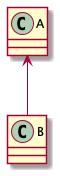
表示在代码层面就是「成员变量」,箭头指向的是被关联类,简单记忆就是: 「指向被关联」,上图表示B关联A,也就是A是B的成员变量。
依赖
依赖的标志为 虚线箭头,如下:

表示在代码层面就是「局部变量(包括局部变量、函数参数以及返回值)」,箭头指向的是被依赖类,简单记忆就是: 「指向被依赖」,上图表示B依赖A,也就是A是B的局部变量。
❝依赖和关联的区别
❞
关联表示的是一种强依赖关系,这种关系是「长期」的,表示在代码层面就是成员变量,我们知道: 成员变量的生命周期和一般和持有它的对象是相同的。而依赖表示的是一种「临时」的关系,表示在代码层面就是局部变量,我们知道: 局部变量的生命周期都是跟随方法的,从方法入栈开始到方法出栈为止。所以关联的生命周期要大于依赖的生命周期,换句话说,关联是一种"强"依赖,或者说是一种"长"依赖。关联和依赖的相同点就是: "他们都表示类之间的一种横向的平等关系",依赖和被依赖、关联和被关联 的两个类之间不存在上下级关系,可以是A依赖B,也可以是B依赖A,这是一种平等的关系。
组合
组合的标志为: 实心菱形,如下:

表示在代码层面跟关联是一样的,也是「局部变量」,但是关联表示的是平等关系,而组合表示的是一种「整体-局部」关系,菱形指向的是整体,简单记忆就是: 「指向整体」,上图表示A持有B,也就是B是A的一部分,这是一种强关联,B不能脱离A而存在。
聚合
聚合的标志为: 空心菱形,如下:
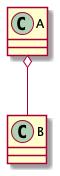
表示在代码层面和组合是一样的,只能从语义层级来区分,聚合跟组合的唯一区别就是: 「聚合对象可以独立存在,组合对象不能独立存在」,比如上图,B是A的一部分,并且B可以脱离A而存在。简单记忆也是: 「指向整体」。
❝组合/聚合 依赖/关联的区别
❞
组合跟聚合都是一种"强关联",表示一种"整体-局部"的关系,被组合的类不能独立存在,比如数据库和数据表,没有数据库肯定没有数据表;而被聚合的类则可以独立存在,比如汽车和轮子,轮子可以脱离汽车而存在,它们两个的区别只能从语义方面划分,换句话说: 组合是一种强聚合。再来看聚合和关联,聚合一定是关联关系,而关联是一种强依赖,所以聚合也是依赖,而组合是一种强聚合,所以组合也是依赖,所以: 组合是聚合,聚合是关联,关联是依赖。只不过它们的耦合强度不同,整体来说就是: 「组合>聚合>关联>依赖」。从设计层面来说,依赖和关联表示的是两个类之间的一种 "横向平等"的关系,而组合和聚合表示的是两个类之间的一种"整体-局部"的关系,它们描述的纬度不同,这个需要在设计的时候从语义层面来区分进而决策。
❝泛化/实现 表示的是一种纵向的上下级关系;依赖/关联 表示的是一种横向的平等关系;组合/聚合 表示的是一种"整体-局部"的关系。
❞

观察者模式
观察者模式的定义很简单: A观察了B,B改变了 就会 通知A,A就可以收到B的通知。因为B要通知A,所以B肯定持有A,也就是说: 被观察者持有观察者,这听着有点儿不对劲,我们可以理解为:订阅/发布模式,A是订阅者,订阅了B,B肯定要有A的联系方式,等到B改变了,就通过A的联系方式通知A,这里A的联系方式就是 A对象的引用,B持有A的引用,等到自己发生改变了,就通过A的引用来调用A的方法 从而 通知A,我们称订阅者A为Observer,被订阅者B为Subject。
理解了类的基本关系之后,我们来看观察者模式的类图,说实话,设计模式的精髓就在于类图,而不是代码。直接上图:
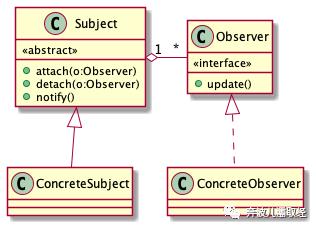
图很简单,我们一点一点来看:
-
1 看Subject,有abstract标记,说明是个抽象类,里面有3个"+"修饰的方法,说明有3个public的方法,我们可以直接写出代码:
public abstract class Subject {
public void attach(Observer o);
public void detach(Observer o);
public void notify();
}
-
2 同样看Observer,他是个interface,可以写出如下代码:
public interface Observer {
public void update();
}
-
3 再来看两个具体类,我们看到了"泛化"和"实现"的标记,分别表示继承和实现,于是可以写出:
public class ConcreteSubject extends Subject {
}
public class ConcreteObserver implements Observer {
}
-
4 最后,我们看到了那个"聚合"的标记,他表示Observer是Subject的一部分,也就是说,Observer是Subject的成员变量,并且是1:n(n>=0)的,既然是n个,说明是个集合,那么Subject内部持有一个Observer集合,于是我们修改Subject的代码:
public abstract class Subject {
private List<Observer> observers;
public void attach(Observer o);
public void detach(Observer o);
public void notify();
}
-
5 再进一步,我们根据观察者模式的定义,知道核心功能为: 注册、移除、通知,于是我们可以写出最终代码:
public abstract class Subject {
// 观察者集合,根据类图的"聚合"推出
private List<Observer> observers = new ArrayList<>();
// 添加观察者,根据观察者模式的定义推出
public void attach(Observer o) {
if(o == null) return;
observers.add(o);
}
// 移除观察者,根据观察者模式的定义推出
public void detach(Observer o) {
observers.remove(o);
}
// 通知更新,根据观察者模式的定义推出
public void notify() {
for(Observer o: observers) o.update();
}
}
于是我们就得到了最终的顶层代码的实现,至于具体的逻辑,就要视具体的业务逻辑来实现了。
我们有如下问题:
-
1 为什么是聚合而不是组合?
因为Observer可以脱离Subject而存在,组合的前提是: B不能脱离A而存在,换句话说:要想有B,必须先有A。而我们要创建Observer,显然不需要有Subject,所以不需要组合。
-
2 那么为什么是聚合而不是关联?
可以是关联!因为聚合本来就是强关联,但是不准确,我们知道,关联表示的是一种平等关系,如果A关联B,B也能关联A,而在观察者模式中,显然是被观察者通知观察者,而不是观察者通知被观察者,所以显然应该是: 被观察者持有观察者,反之则不行(因为没法notify了),所以用聚合更准确!
-
3 为什么Subject定义为抽象类,而Observer定义为接口?
我们知道,抽象类使用的是泛化,而泛化表示一种本能,是天性,我们的Subject本来就是用来被观察的,而不是"可以被观察的",因为如果"可以被观察的",那么也就"可以不被观察",这样的话,如果某个地方真的"不被观察"了,也就是不实现notify()方法了,那么他就失去了最基本的功能,失去了本能,那么它就没有存在的意义(不能更新要它何用),这是不对的;所以我们用更加"强硬"的泛化来明确表示出"它的本能",必须实现!而Observer定义为接口,表示"拥有"这个能力,也就是说: 可以观察,也可以不观察,当需要的时候,就实现这个接口来表示拥有观察的能力,否则就不实现这个接口,这不是强制的,而是可选择的,所以我们定义为比较"弱势"的接口来表示它的这种后天的扩展的能力!
-
4 观察者模式的缺点?
很明显,被观察者采用了聚合的方式持有了观察者,notify的时候通过遍历的方式向下分发结果,那么如果遍历过程中一个observer出现了异常,就会导致后续observer接收不到通知!怎么解决呢?我们可以将每一个notify的调用添加保护,比如:
public void notify() {
for(Observer o: observers){
try {
o.update();
}catch {Exception e} {
// 处理异常
}
}
}
这样可以解决,但是还有问题,比如后续的observer2的依赖于前面的observer1的结果,而observer1没处理完就抛出了异常,那么observer2得到的结果就是错的,这样可能导致连缀问题!所以,需要在设计的时候充分考虑,采取合理的方案。
观察者模式与内存泄漏
我们知道,观察者模式中,被观察者通过聚合的方式"持有"了观察者,那么既然是持有关系,就有可能发生内存泄漏,我们知道,内存泄漏发生的唯一条件是: "长生命周期的对象持有了短生命周期的对象",它的两个必要条件: 一是A持有B;而是A生命周期长于B,二者缺一不可。现在我们假设A是被观察者,B是观察者,那么A持有B,满足了一个条件,那么是否会内存泄漏就看"A的生命周期是否大于B"了。如果A的生命周期小于B,肯定不会内存泄漏,如果A的生命周期大于B,则有可能内存泄漏。如图所示:图中橘色的为被观察者的生命周期,红色为观察者的生命周期,我们attach(observer2),在observer2的生命周期结束时,不进行detach()操作,可以看到,红色结束后,橘色Subject里面还有observer2。
我们知道,对象会回收的时候,会通过"可达性分析"来检测要被回收的对象是否到GCRoot有路径,被观察者 中的 观察者集合observers就是一个GCRoot,而它持有要被回收的observer对象,也就是两者是连通的,是可达的,那么observer就无法回收,怎么办呢,我们断开这个引用链即可,Subject里面的 detach方法就是干这个的,如下图,断开后:detach后,Subject里面没有observer2了,也就是引用链断了。
大多数情况下,观察者的生命周期都小于被观察者的生命周期,所以我们要记得在观察者生命周期结束时,主动移除观察者,比如LiveData(源码自己已经干了),EventBus,Handler等。
以上是关于从UML到观察者模式的主要内容,如果未能解决你的问题,请参考以下文章