(转)带你一步步走入Paxos的世界
Posted 证心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(转)带你一步步走入Paxos的世界相关的知识,希望对你有一定的参考价值。
一个基本的并发问题
先看一个最最基本的并发问题:假设我有一个KV存储集群,3个客户端,并发的向这个集群发送3个请求。请问,最后我去get(x)的时候,x应该等于几?
答案是:x = 1,或者 x = 3, 或者 x = 5 都是对的! 但 x = 4 ,就是错的!
因为从客户端角度来看,3个请求是并发的,但3个请求到达服务器的顺序是不确定的,所以最终3个结果都有可能。
这里有一个很关键的点:把上面的答案换一种说法,即如果最终集群的结果是x = 1。那么当client1发送x = 1的时候,服务器返回x = 1;当client2发送x = 5的时候,返回x=1;当client3发送x=7的时候,返回x=1。相当于client1的请求被接受了,client2/client3的请求被拒绝了!! 如果集群最终结果是x=3,或者x=5,是同样的道理!!
而这正是Paxos协议的一个特点。现在讲这个还是晦涩,后面我们再来提这个问题。
啥叫“时序”
把上面的问题进一步细化:假设这个KV集群,有3台机器,3台机器之间互相通信,把自己的值传播给其他机器,3个客户端分别向3台机器发送3个请求。
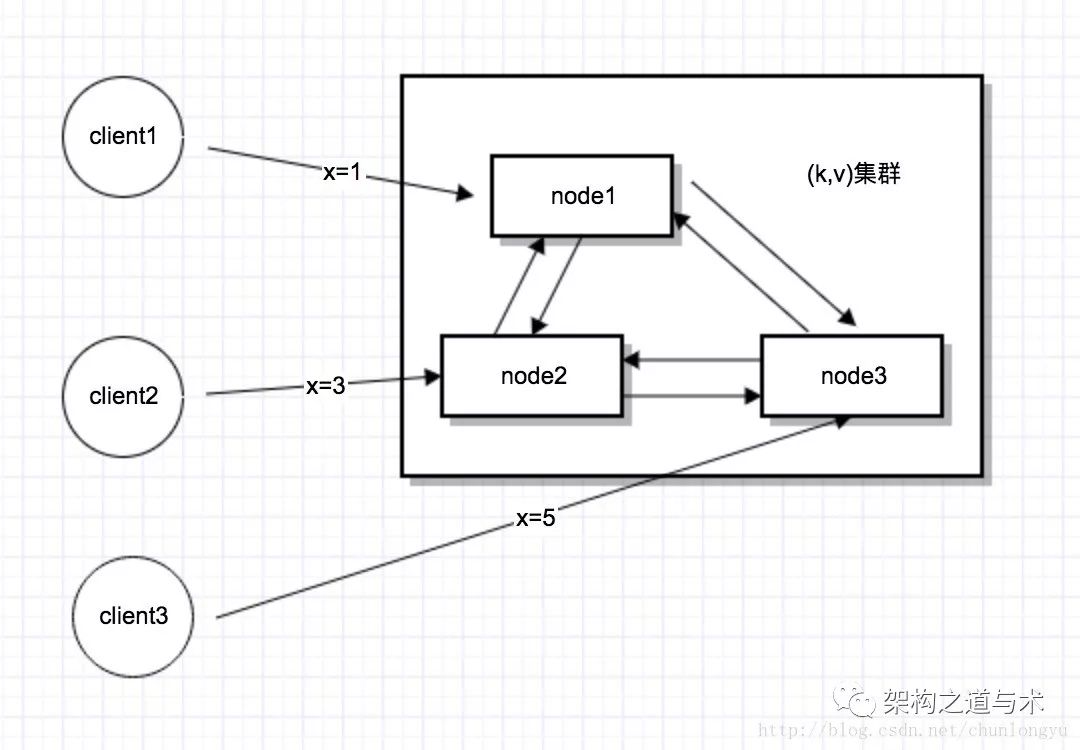
假设每个机器都把自己收到的请求,按日志存下来(包括从客户端来的请求和从其他node来的请求)。那请问:当这3个请求执行完之后,3台机器上面的日志,分别应该是什么顺序?
下面是正确的结果:不管顺序如何,只要3个机器上面的日志顺序是一样的,那结果就是正确的。比如第1种情况,3个机器上面,存储的日志顺序都是x=1/x=3/x=5,那么最终集群里面,x的值肯定等于5。其他情况类似。
很显然,总共有3的全排列,共6种情况。 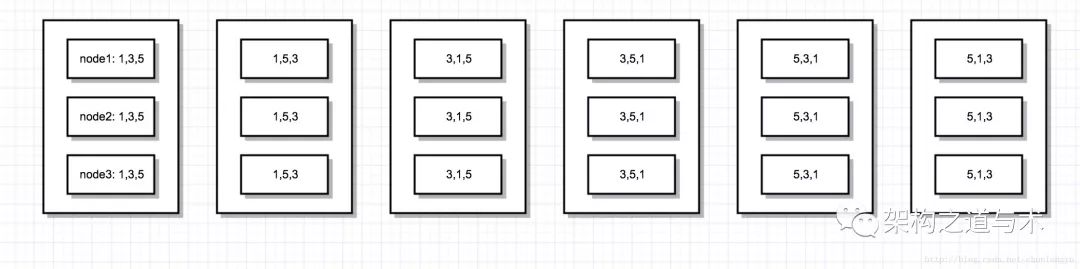
而下面的情况就是错误的:机器1上面日志顺序是1,3,5,因此最终的值就是x=5;机器2是3,5,1,最终值是x=1;机器3是1,5,3,最终值是x=3。 3台机器上面关于x的值不一致。 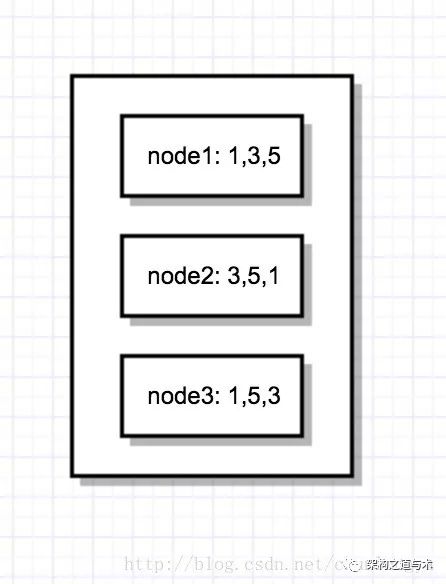
通过这个简单的例子,我们就能对“时序”有一个直观的了解:虽然3个客户端是并发的,没有先后顺序,但到了服务器的集群里面,必须得保证3个机器上面,日志顺序是一样的,这就是所谓的“分布式一致性”。
Paxos解决什么问题
在上面的例子中,node1收到了x=1之后,复制给node2/node3;
node2收到x=3之后,复制给node1/node3;
node3收到x=5之后,复制给node1/node2。
客户端是并发的,3个node之间的复制也是并发的,那如何保证3个node最终的日志顺序是一样的呢?也就是上面说的那6种正确情况中的1种。
比如node1先收到客户端的x=1,之后收到node3的x=5,最后收到node2的x=3;
node2先收到客户端的x=3,之后收到node1的x=1,最后收到node3的x=5;
。。。
如何保证3个node上面存储的日志顺序一样呢???
而这正是Paxos要解决的问题!在接下来的序列中,我们将一步步讨论Paxos是如何解决这问题的!
最后
不同于很多Paxos的文章,本文并没有讲Paxos是什么,而是介绍了我们可以通俗理解的、一个并发问题的场景。如果你明白了这个场景,接下来在看Paxos,就会简单很多了。
-------------------------------
在上一篇我们谈到了复制日志的问题,每个node上面存储日志序列,node之间保证日志完全一样。
可能有人会疑问:为啥我要存储日志,直接存储最终的数据不就行了吗?
复制状态机
日志与状态机
我们可以把一个变量x,或者复杂一点,一个对象,看成是一个状态机。每1次写请求,就是一次导致这个状态机发生变化的事件,也就是日志。
以上篇最简单的一个变量x为例,只有1个node,3个客户端发送了3个修改x的指令,最终结果就是如下形式: 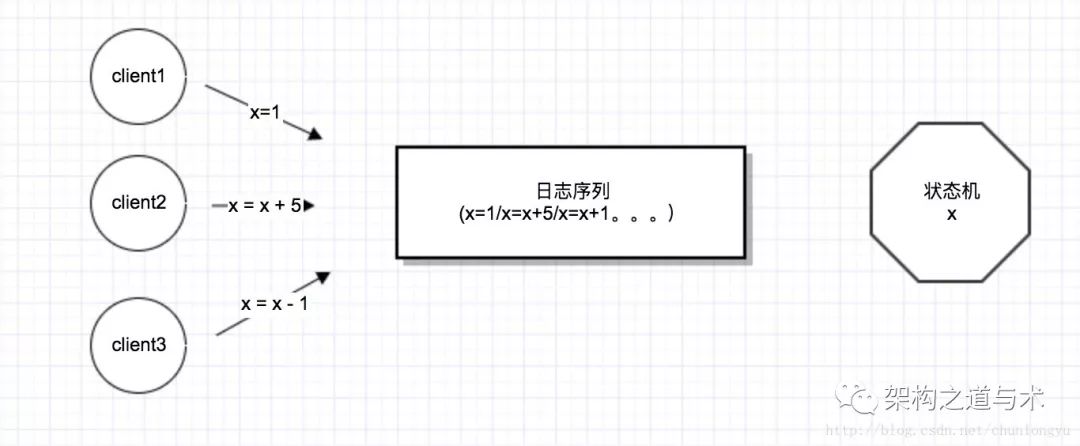
再复杂点,以mysql为例,客户端发送各种DML操作,这些操作落成binlog。然后binlog被应用,生成各种db表格。就是如下形式: 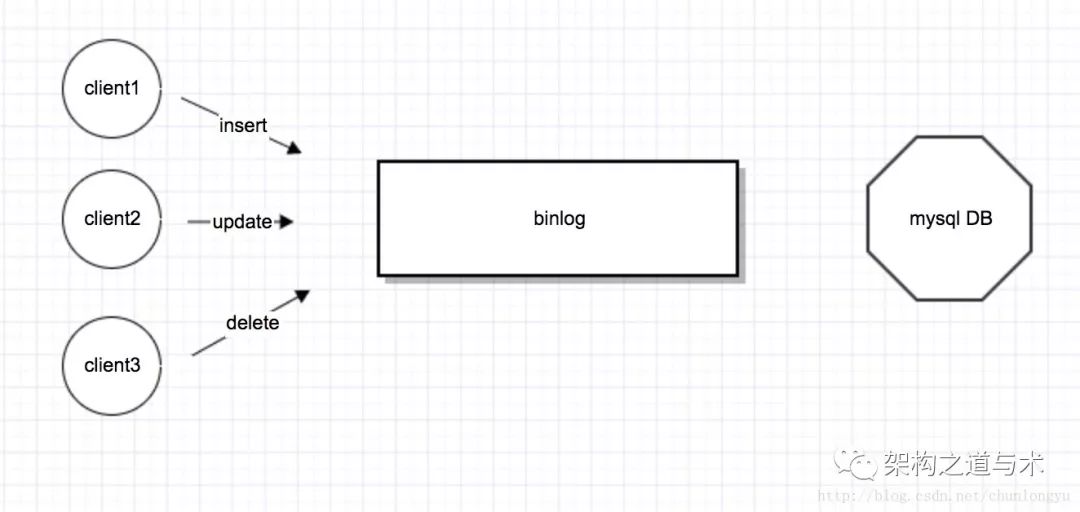
而在这里,就涉及到一个非常非常重要的思想:我们选择持久化导致数据(状态机)发生变化的“事件流(也就是日志流)”,而不是选择持久化“数据本身”。
为啥要这么做呢?原因有很多,我列举几个:
(1)日志只有1种操作,就是append。而数据(或者说状态),一直在变化,可以add/delete/update。把3种操作转换成了1种,这对于持久化存储来说,一下子就简单了很多!!
(2)如果我要做多机之间数据同步,如果你直接同步状态,状态本身的数据结构可能是一个很复杂的数据结构(比如关系数据库的关联表,树,图),并且状态还一直在变化,你要保证多个机器数据一致,要做数据比对,就很麻烦;而如果同步日志,日志是一个1维的线性序列,要做数据比对,非常容易!!
总之,无论从持久化,还是数据同步角度,存储状态机的输入事件流(日志流),都比存储状态机本身要更容易。
复制状态机
我们知道,状态机的原理就是:一样的初始状态 + 一样的输入事件 = 一样的最终状态。
因此,要保证多个node的状态完全一致,只要保证多个node的日志流是一样的就可以了!!即使这个node挂了,重启,重放这个日志流,就能恢复之前的状态。
也因此,我们就回到了上1篇最后的问题:复制日志!
复制日志 = 复制任何数据(复制任何状态机)。因为任何复杂的数据(状态机),都可以通过日志生成!!!
Multi Paxos与Basic Paxos
Paxos的出现,是先有Basic Paxos的形式化证明,之后再有Multi Paxos,然后是应用场景。因为最开始没有先讲应用场景,所以直接看Basic Paxos的证明,会很晦涩。
本文将反过来,就以上一篇最后提出的那个问题为例,先介绍应用场景,再一步步倒推出Paxos, Multi paxos。
一个朴素而深刻的想法
上文讲到,当3个客户端并发的发送3个请求时,下面6种可能的结果都是对的!!
因此,我们就是要找一种算法,保证虽然每个客户端是并发的发送请求,但最终3个node记录的日志,一定是同样的顺序!!(上面之1)
那如何做到呢???这里我提出一个朴素而深刻的说法:全世界对数字1,2,3,4,5,6。。。的顺序的认知,是一样的!!!所有人、所有机器,对这个的认知都是一样的!!
什么意思呢? 当我说2的时候,全世界的人,都知道2是在1的后面,3的前面!!!2代表1个位置,这个位置一定在在(1,3)之间。
我们把这个朴素的想法,应用到计算机里面,多个node直接复制日志,就变成如下这样:
当node1收到x=1的请求时,假设我要把它存放到日志中1号位置,先不要存,我先问一下另外2台机器,1号位置是不是已经存放了x=3或者x=5;如果1号位置被占了,那我就问2号位置。。。以此类推;如果1号位置没有人占,我就把x=1存放到1号位置,同时告诉另外2个node,把x=1,存放到它们各自的1号位置!!
同样, node2, node3做同样的事情。
这里的关键思想就是:虽然每个node接收到的请求的顺序不一样,但它们对于日志中1号位置、2号位置、3号位置的认知是一样的,大家一起保证,1号、2号、3号上面,存储的数据一样!
2PC
在上面的例子中,我们可以看到:每个node在存储日志之前,先要问一下其他所有人,之后再决定把这条日志写到哪个位置。
这也就是2个阶段:先问,再做决策。也就是Paxos 2PC的原型!!
Basic Paxos
把上面的问题再进一步拆解,不是3条日志,就1条。我们就先确定3个node的第1号日志,看有什么问题?
node1问了其他所有人,1号位置没有被占,因此它打算把x=1传播给node2/node3;
同样的时刻,node2问了其他所有人,1号位置也没有被占,因此它打算把x=3传播给node1/node3;
同样,node3也打算把x=5传播给node1/node2。
结果不就冲突了吗。到这里,大家就发现,不要说多条日志,就算是只确定第1号位置的日志,都是个问题!!!
而Basic Paxos就是用来解决这个问题:它怎么解决的呢?
1号位置,要么是被node1占领,大家都存放x=1;要么被node2占领,大家都存放x=3;要么是被node3占领,大家都存放x=5。
Basic paxos就搞了2条主要思路:
第1:1号位置的值一旦被大多数确定了,比如是x=5(node3占领了, node2从了node3),那我就接受这个事实。1号位置不能用了,我也得把自己的1号位置赋值成x=5。然后我就看看2号位置,看能不能把x=1存进去,同样的,如果2号也被占领了,我就只能把人家的值拿过来,填在我的2号位置。我就只能看3号位置。。。
第2:当我发现1号位置没有人占,那就告知其他人,锁定这个位置。不允许有人再占这个位置!除非这个人的权利比我大(也就是proposal id比我大)。
如果我发现1号位置为空,然后提交的时候,发现1号位置被别人占了,那就会提交失败,重试,进入第2个位置。。。
Multi Paxos
上面讨论的Basic Paxos只是保证1号位置的日志,在3个node上面1样。并且我们发现,为了让1号位置日志一样,可能要重试好多次,每个节点都会不断重试2pc。
这样一个不断重试2pc,直到最终大家达成一致的过程,就是paxos协议执行的过程,也就是一个paxos instance,最终确定一个值。
而Multi paxos,就是重复这个过程,确定一序列值,也就是日志中的每1条!!
最后
本篇从一个朴素的思想出发,最后引出paxos要做什么。下一篇,我们将详细讨论Paxos算法本身。
-----------------------------
在前面的序列2中,我们引出了Basic Paxos,其目的就是为了确定1条日志,1条日志对应到Basic Paxos里面就是一个value。
2个角色:Proposer和Acceptor
在前面的场景中,我们提到3个client并发的往3个node发送3条写指令。对应到Paxos协议里面,就是每个node同时充当了2个角色:Proposer/Acceptor。实际实现过程中,一般这2个角色是在同1个进程里面!
当node1收到client1发送的x = 1的指令,node1就作为一个proposer,向所有的acceptor(其他2个node + 自己)发出提议,希望大家都把x=1这条日志写到3个node上面;
同理,当node2收到client2发送的x = 3的指令,node2就作为一个proposer,向所有的acceptor发出提议,。。。
Basic Paxos的2PC
下面就来详细阐述Paxos的算法细节:
首先,每个acceptor需要持久化3个变量
(minProposalId, acceptProposalId, acceptValue)。初始阶段:minProposalId = acceptProposalId = 0, acceptValue = null。
下面是算法的2个阶段:
P1(Prepare阶段)
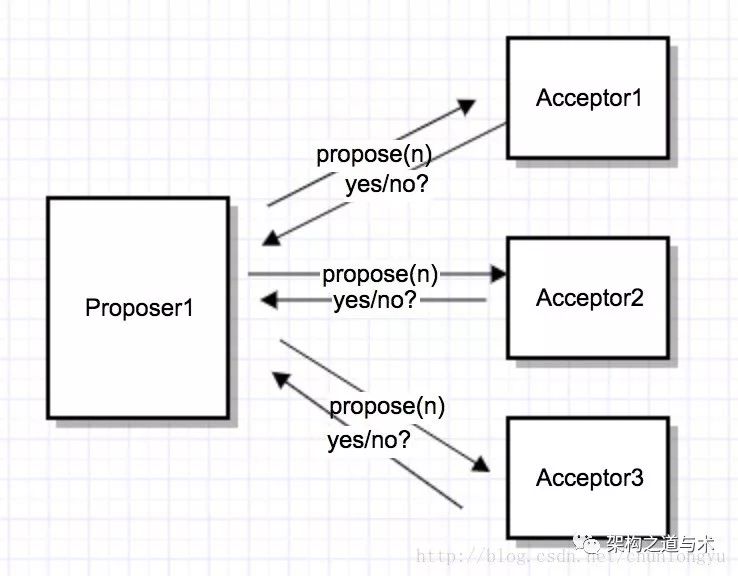
P1a: Proposer广播prepare(n),其中n是本机生成的一个自增id,不需要全局有序,比如可以用时间戳 + ip。
P1b: Acceptor收到prepare(n),做如下决策:
if n > minProposalId,回复yes。
同时 minProposalId = n(持久化),
返回(acceptProposalId, acceptValue)
else
回复no
P1c: Proposer如果收到半数以上的yes,则取acceptorProposalId最大的acceptValue作为v,进入第2个阶段,即开始广播accept(n,v)。如果acceptor返回的都是null,就取自己的值作为v,进入第2个阶段!
否则,n自增,重复P1a.
P2(Accept阶段)
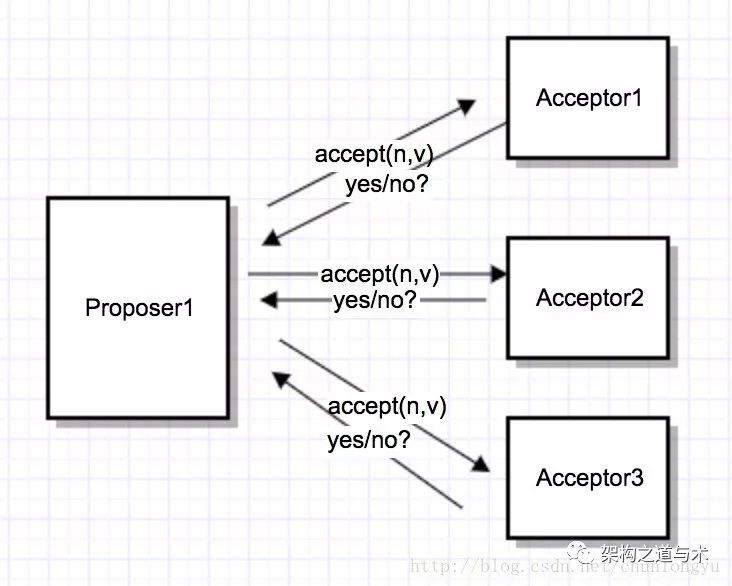
P2a: Proposer广播accept(n, v)。这里的n就是P1阶段的n,v可能是自己的值,也可能是第1阶段的acceptValue
P2b: Acceptor收到accept(n, v),做如下决策:
if n > = minProposalId, 回复yes。同时
minProposalId = acceptProposalId = n (持久化),
acceptValue = value
return minProposalId
else
回复no
P2c: Proposer如果收到半数以上的yes,并且minProposalId = n,算法结束。
否则,n自增,重复P1a
Basic Paxos的2个问题
(1)从上面的算法可以看出,Paxos是一个“不断循环”的2PC。在P1C或者P2C阶段,算法都可能失败,重新开始循环。这也就是通常所说的“活锁”问题,就是可能陷入不断循环。
(2)每确定1个值,至少需要2次RTT(2个阶段,2个网络来回) + 2次写盘,性能是个问题。
而Multi-Paxos就是要解决这2个问题,关于Multi-Paxos,下次待续!
-----------------------------------------------
在前面的序列中,我们知道Basic Paxos可以用来确定1条日志。而Multi-Paxos就是针对每条日志都执行1个2PC的Paxos协议,从而确定多条日志,也就是一个日志流。有了日志流,就能基于日志流建立一个”复制状态机“模型。
复制状态机
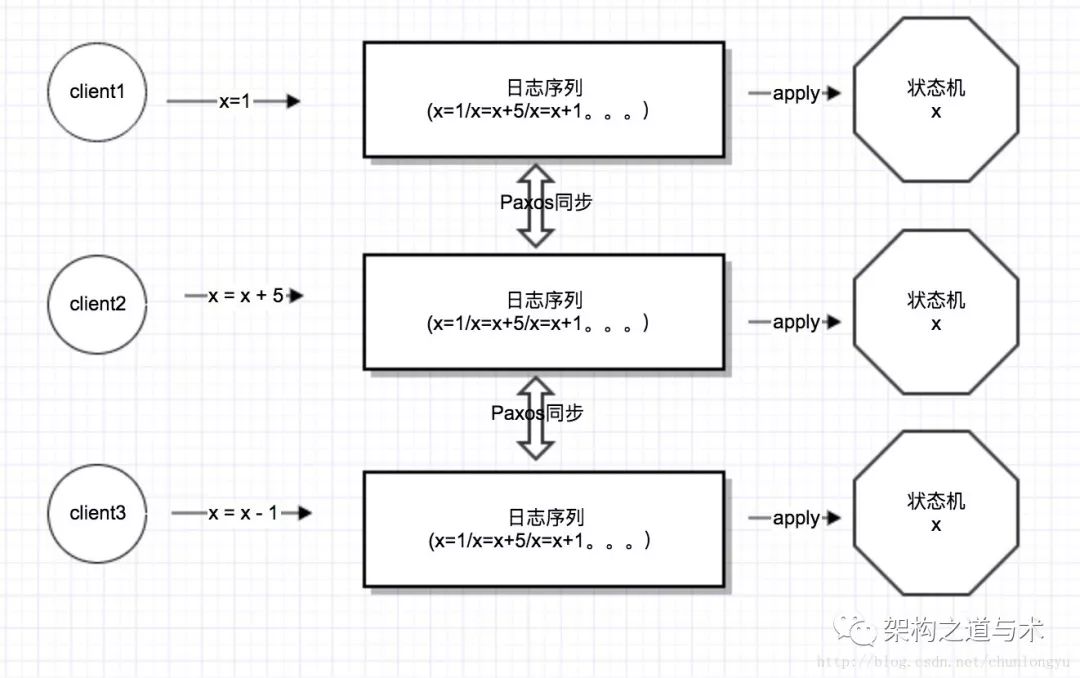
在上图中,有3台机器,每台机器上都有一个日志流+1个状态机。日志流是落盘的,而状态机是纯内存的。
通过Multi-Paxos保证3台机器上的日志流完全一致,那么把日志流apply到各自的状态机上,状态机肯定也就完全一致。这就是所谓的“复制状态机”模型。
对于客户端呢,是多写。多个客户端,并发的往这3台机器写入。
上面就是一个最最基本的,利用Basic Paxos协议来实现的一个复制状态机模型。
但是这个最基本的实现,有什么问题呢?
问题1:活锁问题
在前面我们知道,Basic Paxos是1个不断循环的2PC。所以如果是多个客户端写多个机器的话,每个机器都是Proposer,会导致并发冲突很高,也就是每个节点都可能执行多次循环才能确定一条日志。极端情况,就是每个节点都在无限循环的执行2PC,也就是所谓的“活锁问题”。
为了减少并发冲突,我们可以变多写为单写,也就是选出一个Leader,只让这个Leader充当Proposer。
其他机器收到写请求,都把写请求转发给这个Leader;或者让客户端把写请求都发给Leader。
解决方案1 – 无租约的Leader选举
在上面的basic-paxos实现的复制状态机中,我们知道可以多写。也就意味着,可以出现多个leader。我们的算法,并不需要强制保证,任意时刻只能有1个leader。
下面的leader选举算法来自standford的课程ppt:
可以看出,这个算法很简单,因为网络超时原因,很容易知道可能出现多个leader,但这并不影响Multi-paxos协议的正确性,只是可能增大并发写的冲突。
解决方案2 – 有租约的Leader选举
另外一种方案是严格保证任意时刻只能有1个leader,也就是所谓的“租约”。
租约的意思是:在1个限定的期限内,就是某台机器一直是leader。即使这个机器挂了,leader也不能切换。必须等到租期到了之后,才能开始新的leader选举。
这种方式会带来短暂的不可用,但保证了任意时刻只会有1个leader。
具体实现方式,可以参见PaxosLease
问提2:性能问题
在前面的系列中,我们知道Basic-Paxos是一个无限循环的2PC,1条日志的确认至少需要2个RTT + 2次落盘(1次是prepare的广播与回复,1次是accept的广播与回复)。
如果每条日志都要2个RTT + 2次落盘,这个性能就很差了。
而Multi-paxos在选出Leader之后,可以把2PC优化成1PC,也就只需要1个RTT + 1次落盘了。
解决方案:2PC –》 1PC
基本思路就是当一个节点被确认为leader之后,它先广播1次prepare,一旦超过半数同意之后,之后对于收到的每条日志,直接执行accept。
在这里,perpare就不再是对1条日志的控制了,而是相对于拿到了整个日志的控制权。一旦这个leader拿到了整个日志的控制权,后面就直接略过prepare,直接执行accept。
那如果有新的leader出现怎么办呢?
新的leader出现,它肯定会先发起prepare,导致minProposalId变大。这个时候旧的leader的广播accept肯定就会失败,旧的leader就会自己转变成一个普通的acceptor,新的leader就把旧的顶替掉了。
具体实现细节
在basic-paxos中,我们知道2PC的具体参数形式如下:
prepare(n)accept(n,v)
1
2
在multi-paxos中,多个一个日志的index参数,也变成了如下形式:
prepare(n, index)accept(n,v,index)
1
2
问题3:被choose的日志,状态如何同步给其他机器
对于1条日志,当Proposer(也就是上面的leader) 接收到多数派对accept请求的同意之后,就知道这条日志被”choose”了,也就是被确认了,不能再更改!
但是只有proposer知道这条日志被choose了,其他的acceptor并不知道这条日志被choose了。如何把这个信息传递给其他accepotor呢?
解决方案1:proposer主动通知
在standford的课程ppt里面,提到了这种方案。给上面的accept再增加一个参数:
accept(n, v, index, firstUnchoosenIndex)
1
Proposer在广播accept的时候,最后额外带来一个参数firstUnchosenIndex = 7。意思是说:7之前的日志,都已经“choose”了。
Acceptor收到这种请求之后,就检查7之前的日志,如果发现7之前的日志符合以下条件:
acceptedProposal[i] == request.proposal(也就是第1个参数n),就把该日志的状态置为choose。
解决方案2:acceptor被动查询
当一个acceptor被选为leader之后,对于所有未choose的日志(也就是未确认的日志),可以挨个再执行一遍paxos,来判断该条日志的、被大多数缺认的值是多少。
因为basic-paxos有一个核心特性:一旦一个值被choose(被确定)之后,无论再执行多少遍paxos,该值都不会改变!!因此,再执行1遍paxos,相当于向集群发起了1次查询!
Multi-Paxos的精髓之1 – 1个强一致的“P2P网络”
关于Multi paxos,还有很多的实现细节,后面会再从其他角度来论述。在此,先对本文所讲述的,做1个总结:
任何1条日志,也就2种状态(choose, unchoose)。当然,还有一种状态就是applied,也就是被choose的日志,被apply到状态机。这种状态跟paxos协议关系不大。
choose状态,就是这条日志,被多数派接受,不可更改;
unchoose,就是还不确定,引用下面来自阿里ob团队的李凯的话,就是“薛定谔的猫”,或者“最大commit原则“。1条unchoose的日志,可能是已经被choose了,只是该节点还不知道;也可能是还没有被choose。要想确认,那就再执行1次paxos,也就是所谓的“最大commit原则“。
精髓:整个Multi-paxos就是类似1个P2P网络,所有节点互相双向同步,对所有unchoose的日志进行不断确认的过程!!这个网络中,可以出现多个leader,可能出现多个leader来回切换,这都不影响正确性!
Multi-Paxos的精髓之2 – “时序“的透彻理解
Multi-Paxos保证了所有节点的日志顺序一模一样,但对于每个节点自身来说,可以认为它的日志并没有所谓的“顺序”。
什么意思呢?
1)假如1个客户端,连续发送了2条日志a, b(a没有收到回复,就发出了b)。那对于服务器来讲,存储顺序可能是a,b;也可能是b,a;也可能a, b之间还插入了其他客户端发来的日志!
2)假如1个客户端,连续发送了2条日志a, b(a收到回复之后,再发出的b)。那对于服务器来讲,存储顺序可能是a, b;也可能是a, xxx, b。但不会出现b在a的前面。
所以说,所谓的“时序”,只有在单个客户端串行的发送日志时,才有所谓的顺序。
多个客户端并发的写,服务器又是并发的对每条日志执行paxos,整体看起来就没有所谓的“顺序”。
写在最后
从上面的讨论可以看出,Multi-paxos并不像Basic-paxos那样有一个标准答案。针对Multi-paxos的方方面面,其实存在着不同的实现方案!!!
在后面的序列中,会从其他角度,进一步讨论Multi Paxos。
以上是关于(转)带你一步步走入Paxos的世界的主要内容,如果未能解决你的问题,请参考以下文章