浅谈Paxos算法原理及应用
Posted 匠心独运维妙维效
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈Paxos算法原理及应用相关的知识,希望对你有一定的参考价值。

在数字化银行建设过程中,金融产品不断的向开放式、线上化、智能化转型。随着用户量和信息量的不断增长,大数据、高并发、高可用成为很多业务系统设计和基础软件设计(比如数据库、消息队列等)必须考虑的问题,而分布式系统往往是解决这类问题的优选方法。由于可能存在网络分区、网络异常、服务器宕机等问题,分布式共识性算法是构建具有容错性分布式系统不可缺少的元素,常用于解决了分布式系统中的数据一致性问题、Leader选举问题等。本文将对大名鼎鼎的分布式共识算法Paxos的原理和应用进行介绍。

Paxos算法简介
Paxos算法是1990年LeslieLamport 在论文《ThePart-TimeParliament》提出的,是一个基于消息传递且具有高度容错性的一致性算法。但是初期由于Paxos难于理解并没有引起多少人的重视,直到2006年Google的三大论文出现,其中ChubbyLock服务使用了Paxos作为ChubbyCell的一致性算法,这才使得Paxos算法的人气从此一路飙升,可以说Paxos是分布式协议的鼻祖,在分布式领域有着非常重要的地位。
Paxos也有其自身的缺点:一个是难于理解;另一个是论文中并没有提供工程实现方法,对工程实现支持并不好。因此在工程实践中,常常是借鉴Paxos算法的核心思想,同时结合系统特点和痛点,进行Paxos算法改造来满足系统需求,并逐渐衍生出了多个Paxos算法的变种,比如Multi-Paxos、Fast-Paxos、Cheap-Paxos、GeneralizedPaxos、Mencius等。
Paxos要解决的问题:假设有一组可以发起提案的进程集合,一个一致性算法要保证在提出的多个Value中,只有一个Value被选中(Chosen).如果没有Value被提出,就不应该有Value被选定。当有一个Value被选定,所有进程都应该能学习到这个被选定的Value。
1、基本概念

三种角色:Proposers,提案的发起者;
Acceptors,提案的接受者,即投票者;
Learners,最终决议的学习者和执行者。
在Paxos算法中,一个节点可以充当多种角色。Proposer可以提出提案,Acceptor可以接受提案(即为提案投票),如果某个提案被最终选定(Chosen),那么该提案里的Value就被选定了。
2、算法原理
Paxos算法设计了Prepare、Accept、Learn三个阶段,前两个阶段实现从多个Proposer提出的提案中选择一个提案(即选择一个Value)并达成共识,第三个阶段让Learners学习到这个最终被选定的提案。
1.选择一个Value并达成共识
这部分涉及到两个角色,即Proposer和Acceptor。如何从Proposers提出的多个Value中选定一个Value,是Paxos算法的核心内容。
【算法流程】:
Proposer[N,V] |
Acceptor [ResN, [AcceptN, AcceptV]] |
|
| 第一阶段
|
Proposer向超过半数的Acceptor发送编号为N的Prepare请求,Prepare(N, ) 注:N递增,不重复 |
|
| 若N<=ResN,不响应或响应<error> 若N>ResN,1.令ResN=N,2.如果已经接受过提案,返回Promise响应(Pok, [AcceptN, AcceptV];如果没有接受过提案,响应(Pok, null)。 |
||
| 第二阶段
|
若收到超过半数的Pok,发送自己的提案Accept(N,V)。V为Pok响应中最大AcceptN对应的AcceptV,如果响应中没有提案,V由Proposer自己决定。 若收到的Pok未超过半数,重新发起Prepare请求(回到第一阶段)。 |
|
| 若N>ResN接受提案,令AcceptN=N,AcceptV=V,回复Aok。 若N<ResN,不接受提案,不回复或者回复<error>。 |
||
| 若Aok数过半,确定V被选定。 若Aok数不过半,重新发起Prepare请求(回到第一阶段)。 |
注:
提案由提案编号N和提议值Value组成,表示为[N,V]。
[ResN, [AcceptN, AcceptV]]中,ResN表示Acceptor已经响应过的Prepare请求的最大编号,[AcceptN, AcceptV]表示Acceptor已经接受过的编号最大的提案。
[算法分析]
Paxos算法中主要有四种类型消息:Prepare、Promise、Accept、Accepted。
1)Proposer先发起一个Prepare消息,来获得提议的权利,同时学习已经被选定的提案。Acceptor通过回复Promise消息,对提议权的请求进行投票。
2)当Proposer收到超过半数的Promise消息后,就获得了提议权,并把学习到的提案Value值放到自己的提案里面。然后通过Accept消息发出自己的提案。
3)Acceptor通过回复Aeccpted消息,对提案进行投票。
4)当Proposser收到超过半数的Accepted消息后,这个提案就被选定了。
5)如果一直没有提案被选出,那么Proposer就会重新获取提案编号,再进入第一阶段,重复这个Paxos算法流程,直到最后有提案被选中。
2.Learners学习被选定的Value
Paxos算法中,对Learners如何学习到选定的Value提出了3种方案,而每一种方案都有其优缺点,具体如下:
| 方案一 | 方案二 | 方案三 | |
| 方案内容 |
Acceptor接受一个提案,就将该提案发送给所Learner |
Acceptor接受了一个提案,就将该提案发送给主Learner,主Learner再通知其他Learner |
Acceptor接受了一个提案,就将该提案发送给一个Learner集合,Learner集合再通知给其他Learner |
| 优点 |
Learner能快速的获取到被选定提案 |
通信次数变少了,大概通信M+N |
集合中Learner数量越多,可靠性就越好 |
| 缺点 |
通信次数较多大概M*N |
出现单点问题(主Learner可能出现故障) |
网络通信复杂度高 |
说明:M是Acceptor的数量,N是Learner的数量
在算法的实践中,使用Proposer将通过的提案发送给Learners也是一个不错的选择,可根据具体情况选择合适的方案。
MGR,mysqlGroupReplication的缩写,即MySQL组复制技术。MGR是MySQL官方在5.7.17版本推出的高可用解决方案,基于原生的复制技术,以插件的方式提供。支持多节点并发地执行事务是MGR的一个重要特性,我们知道MGR采用share-nothing的复制方案,组内每个成员都有自己完整的数据副本,节点之间的数据是最终一致的。如何做到的呢?先来了解一下MGR中事务的生命周期,如下图所示。

1.事务在各自的MySQLServer层启动、执行,这个过程无需和MGR集群内的其他节点进行协调、通信。
2.当事务需要提交时(prepare之后,写binlog之前),将事务信息(包含binlog、write_set、gtid、节点uuid)发送到MGR中的通信模块,事务消息将基于Paxos协议在全集群范围进行原子广播,每个节点都将收到整个集群发生的所有事务,且所有事务在每个节点内的排序是完全相同的。
3.通信模块将事务按照排序顺序发送到本节点的全局事务认证模块。全局事务认证模块对事务进行冲突检测,并将检测结果返回MySQLServer层。
4.根据检测结果,本地事务将更新日志写入binlog并commit,或者回滚;异地事务将更新日志写入relaylog等待应用,或者丢弃。
从MGR事务的生命周期中,可以看到基于Paxos的通信模块(即MGR中的组通信引擎XCom)对节点间数据一致性起到了至关重要的作用,也是MGR的核心。下面我们介绍一下基于Paxos的通信模块(XCom)的具体实现。为了避免单Leader写入性能瓶颈问题,MGR并没有使用传统的Multi-Paxos,而是采用了类似Mencius的算法。在XCom的算法里,每个节点都有一个唯一的编号,在全局有序的消息序列中,每个节点都有属于自己特定的slot,如下图所示,共三个节点,编号分别是0、1、2。
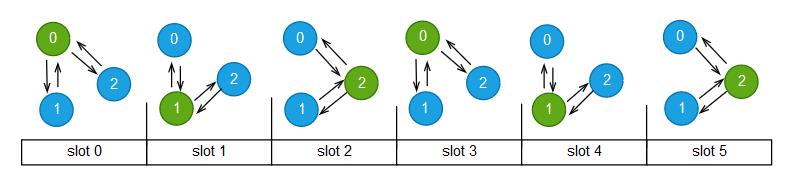
节点0持有slots:0, 3, 6, ...
节点1持有slots:1, 4, 7, ...
节点2持有slots:2, 5, 8, ...
正常情况下,没有leader选举,每个节点都是它所属slots的Leader,这是协议里约定好的。在自己所属的slots里,可以直接发起事务提案(省去了Paxos算法中Prepare阶段),当有过半节点接受(Accept)提案后,就可以将事务信息发送到本节点的全局事务认证模块。
但是此算法可能导致全局slot序列中有gap产生,如下图所示,节点1和节点2已经对slot1和slot2的消息达成了共识,但是对slot0的消息还没有达成共识。
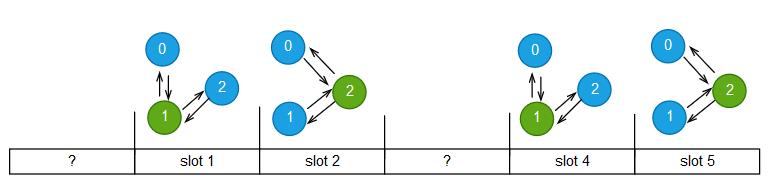
这时候,是不能对slot1和slot2的消息进行应用的,所以需要有人在slot0上提一个noop提案,令整个系统继续向前推进。当节点0正常的情况,节点0自己会适时提出noop提案的,否则需要其他节点帮助slot0提一个noop提案,这时候就需要执行Paxos的整个流程,包括prepare阶段(选择一个Leader来发起noop提案)。
以上便是Paxos在MGR通信模块中的具体实现。Paxos算法在工程中的应用还有很多,例如Google提出的分布式锁服务ChubbyLock,其中ChubbyCell基于Paxos算法实现了副本间数据的一致性及集群Leader的选举;阿里自研分布式数据库OceanBase采用Paxos算法实现数据一致性;著名的Raft协议也是对Paxos算法的一个简单实现;而国产分布式数据库TiDB,其调度/元数据存储组件PD,及底层存储组件TiKV均使用Raft协议保证了数据一致性,实现了Leader的故障转移等等。可以说在分布式系统的世界中,Paxos算法的影子随处可见。

金融科技干货分享
每周一篇成长快乐
以上是关于浅谈Paxos算法原理及应用的主要内容,如果未能解决你的问题,请参考以下文章