基于R的文本挖掘及可视化--挖一挖音乐诗人李健
Posted 生信草堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于R的文本挖掘及可视化--挖一挖音乐诗人李健相关的知识,希望对你有一定的参考价值。
生信草堂
号外,号外,号外
你想和生信分析大神做好朋友么?
你想认识更多爱好生信分析的小伙伴么?
你想让自己的生信分析走上快车道么?
添加我们的微信bioinformatics88为好友
标注“加入生信草堂交流群”
在群里请大家注明自己本名,单位,研究领域
便于小编管理
生信大讲堂微信公众平台,作为浙江大学农业与生物技术学院作物所研究生第七党支部“生信大讲堂”生物信息系列讲座的重要线上平台,结合学科特色,坚持以“四讲四有”中“讲奉献有作为”作为活动核心价值观,为广大科研工作者提供了学习生物信息学相关学科知识的资源及平台。

李健,中国内地流行乐男歌手、音乐制作人。
2003年推出首张个人创作专辑《似水流年》。2015年补位歌手参加某果台《我是歌手第三季》,最终获得总决赛亚军 。2017年作为逆战阵容参加《歌手》,最终获得总决赛第四名。

李健作为公认的音乐诗人,不仅在音乐上颇具造诣,在其他方面也是首屈一指,至少清华毕业已经可以秒杀一片。理工科的汉子也很柔情,李健毕业于清华大学电子工程系,在毕业后做了两年的网络工程师后,李健毅然决然放弃工作,正式走上了音乐之路,当初进入清华也是因为自己在冬令营的一首歌让自己获得了50分的高考加分。

秀波大叔说过,李健的音乐不在于让别人听见,而是他与自己安静真挚、轻声细语的自我交流,声音质感特别清晰。听李健的歌,会给你一种内心空灵深邃之感,不同于王菲歌声澄澈得像一汪泉水,李健的声音纯净得像乡间麦田上的清风,心灵净土上的一种质朴与满足。

(楠哥沉醉的样子hhh)
在《我是歌手》或《歌手》的舞台上,李健一直以一种儒雅书生示人,外表冷峻中足够阳光,优雅中足够理性;歌声空灵深邃,飘逸又或宁静。
看李健唱歌,几乎很少有很多的肢体语言,面相平和,就像是在念一首诗,徜徉自己心中一方净土;听李健唱歌,总是会情不自禁被勾走了魂,虽然说不清楚那是种什么意境,但足够让人沉醉在这如梦如幻般的天籁中。

李健的音乐适合在恋爱的时候听,这个时候你会觉得很幸福,世界是那么美好,阳光和煦;适合在分手的时候听,这个时候你会觉得总有一方心灵净土是属于自己一个人的,那是平静;适合没谈恋爱也没分手的时候听,这个时候你会觉得有了这份清新淡雅、深邃空灵,其他一切都没那么重要了。当你需要音乐疗伤的时候,不妨考虑一下李健的歌……

OK,关于李健的介绍到此结束,下面进入主题,对本地文本进行文本挖掘及可视化。简单来说,今天要做的就是画词云图。词云是在对文本进行一定分词后根据词频绘制而来的一种文本信息可视化的表现形式。为啥要画词云,显而易见,哪个词出现的频率最多,一定程度上说明这个词的重要性,也可以反映出文本想要的突出的重点。
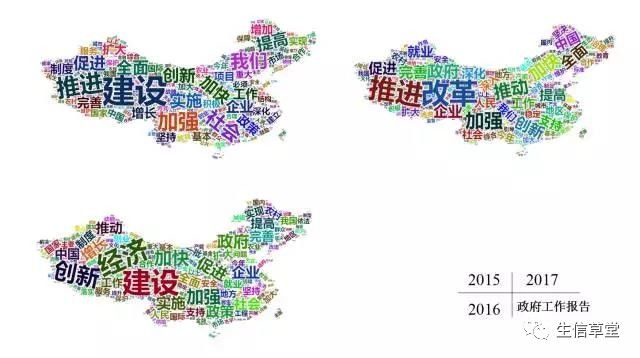
利用2015-2017年的政府工作报告绘制词云,2015年出现最多的是“建设”“加强”“推进”“创新”等,2016年出现最多的词是“建设”“经济”“创新”“政府”等,2017年是“改革”“推进”“政府”“全面等,每一年国家发展战略在一点点发生改变,详情参考每天《新闻联播》。
绘制词云有很多工具,最简单的是线上的一些工具,比如WordItOut、Tagxedo、ToCloud、WordArt等,有兴趣的可以自己试试,这里不做分享。今天要分享的制云工具是R。
R的功能强大,比如数据分析、可视化等,这里不再赘述。利用本地文档进行绘制词云,我们需要用到R的两个包jiebaR和wordcloud2。jiebaR是专门用户汉字分词的包,要求R版本大于3.3。Wordcloud2是利用分词结果绘制词云的包,要求R版本大于3.1.0。jiebaR有包自带的模型及词库等,因此没有特殊要求可以直接使用默认参数,对于有特殊要求的分词,也可以自己添加词库、停用词等(参考https://github.com/qinwf/jiebaR)。
>install.packages("jiebaR")#安装包
>library(jiebaR) #载入jiebaR包
>engine = worker() #生成分词器engine
>Segment(“权力的游戏”,engine)
[1] "权利" "的" "游戏"爬了李健的一百首歌曲的歌词。
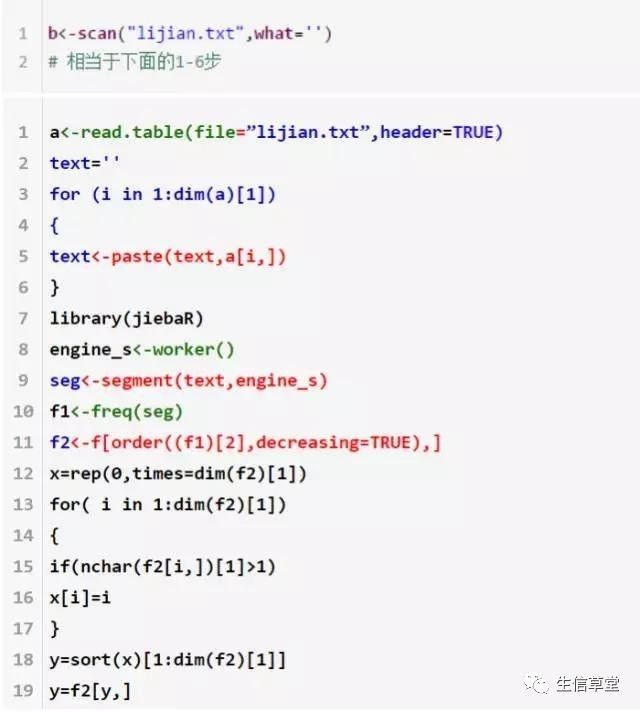
第一步:读取
>text<-scan(“lijian.txt”,what=’’)
Or
>a<-read.table(file=”lijian.txt”,header=TRUE)
>text=''
>for (i in 1:dim(a)[1])
+ {
+ text<-paste(text,a[i,])
+ }
> head(text)
[1] " 似水流年" "1" "《绽放》" "紫色的火"
[5] "穿越夜的云朵" "流星一样飞过"###第一种scan读取到的文本保存时列表,而read.table()是数组,因此需要将数组元素合并到一起,才能被下一步的分词器识别。
第二步:分词
>library(jiebaR)##加载包
>engine_s<-worker()##初始化分词器
>seg<-segment(text,engine_s)##分词
>head(seg)
[1] "" "似水流年" "1" "绽放" "紫色" "的"
>f1<-freq(seg) ##统计词频
>head(f1)
char freq
1 三十年 1
2 对待 2
3 听不见 2
4 手术 2
5 经历 2
6 挖开 2
>f2<-f[order((f1)[2],decreasing=TRUE),]
##根据词频降序排列
>head(f2)
char freq
2131 的 736
1145 我 608
1058 你 479
611 在 275
1245 148
1012 是 146
>x=rep(0,times=dim(f2)[1]) ##去单字
>for( i in 1:dim(f2)[1])
+ {
+ if(nchar(f2[i,])[1]>1)
+ x[i]=i
+ }
>y=sort(x)[1:dim(f2)[1]]
>y=f2[y,]
>head(y) ##查看y
char freq
1154 永远 52
1423 我们 47
603 什么 37
740 没有 35
1400 一样 32
1078 世界 31第三步:绘图
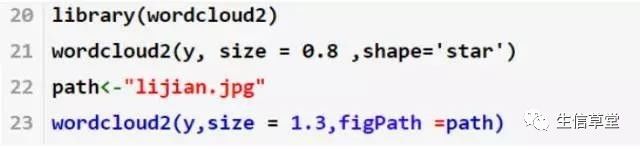
Wordcloud2包支持绘制包自带形状(star/rectangle/circle等)、字符形状(包括汉字和字母、自定义形状)
>library(wordcloud2)#加载wordcloud2包
>wordcloud2(y, size = 0.8 ,shape='star')#绘制成五角形状词云
>path<-"F:/软件/R/Rspace/pacong1/lijian.jpg"# 自定义形状
>wordcloud2(y,size = 1.3,figPath =path)
>letterCloud(y, size=1, word=”李健”) #绘制成字符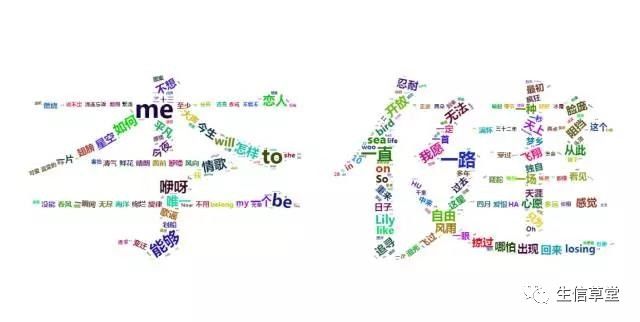
最后,说一下要注意的地方。
统计词频之后进行了词频降序排列,目的是让出现词频最多的词尽量出现在图形中心,而不会在边缘显得突兀。词频过大,最后在图中会将该词省略掉,比如上图“李健”中就少了“永远”“什么”这些高频词,原因就是词频过大超出了最后生成图轮廓范围,这些词就会被去掉。
其次,还有一步是进行了去单字的操作,绝大部分单字都没太大价值,比如“的”,因此最好把这些词过滤掉再画图,保证结果的简洁明了。
大家也可以用自己感兴趣的文本试着练一下这个炫酷技能,说不定画个“❤”形还能撩到妹呢 /微笑。

学术手拉手
长按关注生信大讲堂
以上是关于基于R的文本挖掘及可视化--挖一挖音乐诗人李健的主要内容,如果未能解决你的问题,请参考以下文章