用文本挖掘来认识周杰伦
Posted 偏执狂大包纸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用文本挖掘来认识周杰伦相关的知识,希望对你有一定的参考价值。
周杰伦在唱什么
——基于6.5W字歌词的文本挖掘与分析
周
董
的
歌
听朋友说今天这位很火的周同学厦门站的演唱会票票被抢爆了,恰好也在今天做了一次与他有关的课堂汇报。
感谢周董,帮助我完成了学术生涯中的最后一次课堂pre了。

web数据挖掘的课程选题选了文本挖掘与情感分析,然后脑子一热,想起之前的大数据民谣分析,就想把周董的歌词来瞎搞一翻,统计了下,从2000年来周董的所有歌歌词加起来有约6.5万字,充其量只能算是个小数据分析吧= =。
首先,数据源方面,我手动从度娘上搜集了结论自2000年出道以来所有专辑中的歌曲(从最开始的<JAY>到最新的<周杰伦的床边故事>),共14张专辑,238首歌曲(238有可能有统计误差。。。),约6.5万字。然后撸起袖子开始干啦,对了,工具用的是R语言(自带分词包,吾等初级数据小工的利器~)。【源代码也在最后附上~】


(一)文本处理过程

1、读取
首先,用函数readLines(),逐行读取歌词文本,存为一个序列格式的变量,一行保存为序列中的一个元素,初步去除无字符的行(回车或空格为一行的情况)。具体代码如下:
---------------------------------------------------------
songs = readLines("C:/Users/Carrie/Desktop/数据挖掘作业/周杰伦歌词/周杰伦所有歌词.txt",encoding="UTF-8") #以每行为一个变量的方式读取文本
songs<-songs[songs!=""] #去除回车键组成的一行
songs<-songs[songs!=" "] #去除空格组成的一行
songs[1:10] #查看前10行文本的情况
---------------------------------------------------------

2、分词、统计及可视化
步骤一:分词并清洗数据(去除停用词和特殊符号)
利用jiebaoR包的分词功能,先设置分词引擎后对文本进行分词处理。随后用自定义构造的停用词表(歌词专用)作为参照库去除停用词,再去除词汇中的数字、字符、空格等。具体代码如下:
----------------------------------------------------------
## 分词
install.packages("jiebaR")
install.packages("jiebaRD")
library(jiebaRD)
library(jiebaR)
cutter=worker()#设置分词引擎
segWords<-segment(songs,cutter)#对文本进行分词处理
## 去除停用词
f = readLines("C:/Users/Carrie/Desktop/数据挖掘作业/停用词.txt",encoding="UTF-8")###读取停止词
stopwords<-c(NULL)
for(i in 1:length(f))
{
stopwords[i]<-f[i]
}
segWords<-filter_segment(segWords,stopwords)#去除中文停止词
##去除文本中出现的数字和符号字符串,使用gsub()函数即可实现。
segWords<-gsub("[0-9a-zA-Z]+?","",segWords)###去除数字和英文
##在实现过程中,发现分词以后还会产生一些空格,类如” “的东西。这里用到stringr包,这也是个处理文本的神器
library(stringr)#加载stringr包
segWords<-str_trim(segWords)#去除空格
-------------------------------------------------------------
部分切词结果如下截图所示:

步骤二:构建词频表
利用plyr包中的count函数,统计词频,并且依据词频大小对词进行排序,并再次筛查是否存在符号变量。具体代码如下:
-------------------------------------------------------
## 构建词频表
#使用plyr包的count()函数,得到数据框格式的结果
library(plyr)
tableWord<-count(segWords)##形成词频表,tableWord是数据框格式
for(i in 1:31)
{
tableWord<-tableWord[-1,]
}
tableWord<-tableWord[order(-tableWord1$freq),]
tableWord<-tableWord[tableWord$x!=".",]
write.csv(tableWord, "词频总.csv", quote = F, row.names = F)
-------------------------------------------------------
所得词表的部分结果如下所示:
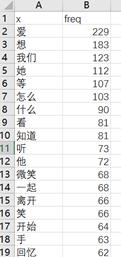
步骤三:绘制词云图谱
根据词频大小绘制词云,利用worldcloud2包中的worldcloud2函数,可设置云图的配色、形状轮廓灯,在此我们以周董照片为词云轮廓素材。具体代码如下:
-------------------------------------------------------
library(wordcloud2)
log<-system.file("examples/2.png",package="wordcloud2") #设置轮廓素材
colorVec = rep(c("#0099FF","#336699","#003366","#666699","#99CC33","#FF9900"), length.out=nrow(tableWord))#自定义配色
wordcloud2(tableWord,color = colorVec, size = 0.9,figPath =log)
-------------------------------------------------------
得到的云图就是文章开头的那个“深思”的周董啦,形状轮廓和配色都可以自己设哦~
3、情感分析(情感词库、过程)
Python的SnowNLP包中有专门进行情感分析的模块,该情感分析词典的训练集来自于购物及社交平台的评论文本,并且提供单个中文单词情感倾向的程度分值。相较于其他情感词典,该情感词典中的中文词量大,并且词语较为口语化,与歌词的特征较为匹配,另一方面,该情感词典给出各词汇的情感倾向程度得分,可量化情感强弱。基于以上两点,我选它作为情感分析的参照库。具体代码这里就不展示了,后面来看一看分析结果吧。
(二)结果分析--原来你是这样的周董
主题分析—— 情歌为主
将4年作为一个阶段,对不同时段的歌词进行频次分析,试图探究歌曲主题是否随时间有明显变化。
但由结果看出,以情歌为主的歌曲专辑这些年来主题并无大变化。
不过这可能与歌词词汇量规模偏小有关,从高频词可能无法准确看出歌曲主题的变化。

喜好分析 —— 最喜欢歌唱的时间
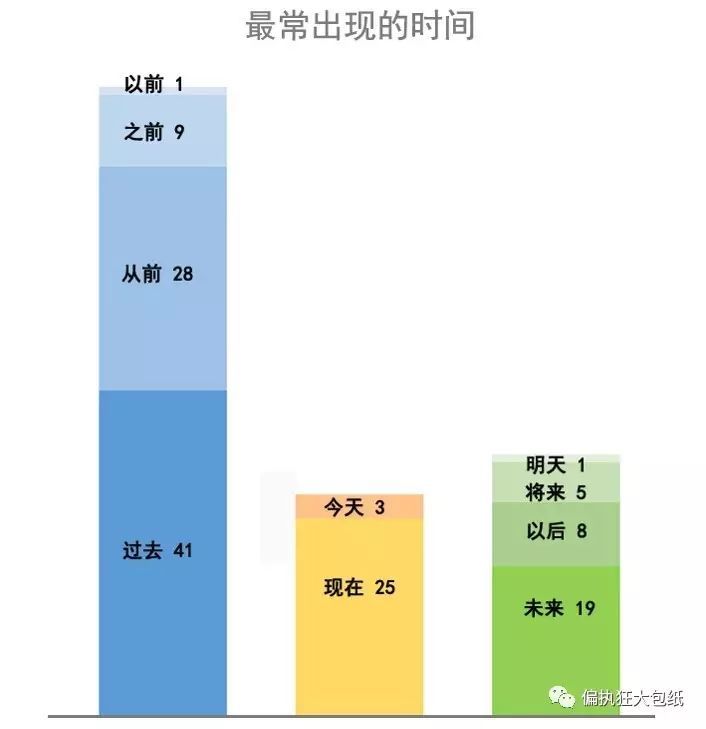
在时间维度上,关键词词频 “过去”>“未来”>“现在”。可以看出,周杰伦是一个活在过去的人,歌曲最爱回忆过去,有时畅想未来,偶尔提及现在。
喜好分析 —— 最喜欢的家人
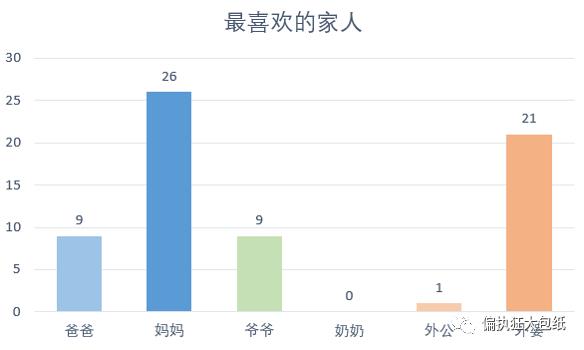
在人物维度上,关键词按词频统计依次是“妈妈”、“外婆”、“爷爷”、“爸爸”、“外公”。可以看出,周杰伦是一个非常喜欢歌唱妈妈和外婆的人,和她们的关系比较亲密。
喜好分析 —— 最喜欢歌唱的天气
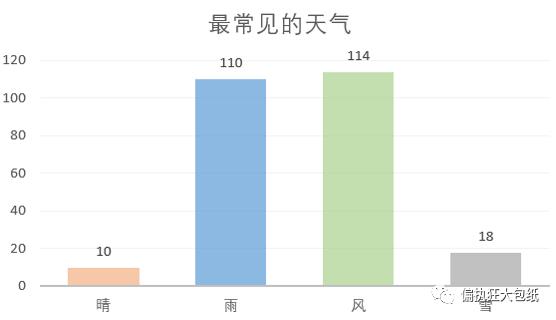
在天气维度上,关键词按词频分类统计天气类型,“风”、“雨” > “雪”、“晴”。 可以看出,周杰伦是一个较喜欢以风、雨渲染歌曲气氛的人。
情感分析 —— 不同季节情绪变化
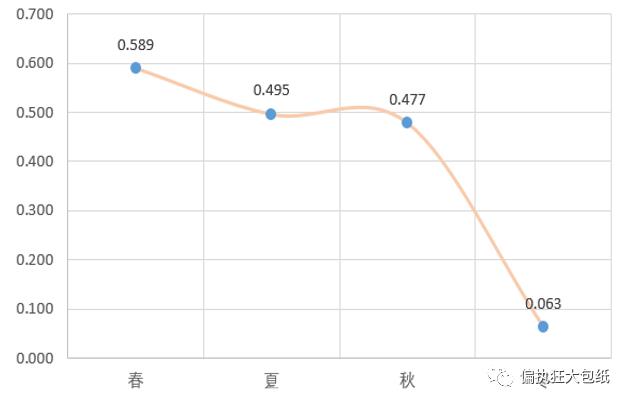
人工筛选并统计描绘不同季节的歌曲,对同时描绘多个季节的歌曲进行删除(例如《四季》),对四个季节的歌曲进行文本情感分析。
结果可看出,春、夏、秋、冬四季情感渐次下降。冬天得分达到最低点,且负面情绪首次超过了正面情绪,可以看出周杰伦在歌曲里的冬天最为消沉。
情感分析 —— 最嗨与最丧的专辑
对历年的14张专辑进行情感得分标记。
第1张专辑《Jay》情感得分最低,是最丧的专辑
第14张最新专辑《周杰伦的床边故事》情感得分最高,是最嗨的专辑
第11、12张专辑出现较大情感波动,《惊叹号!》专辑出现小的情绪波谷
周董画像
综上,周杰伦是一个表面上看起来酷酷的,但实际上深情款款;最爱回忆过去,有时畅想未来,偶尔提及现在;听妈妈的话,爱念叨外婆;在春天的阳光中开心,在冬天的风雪中低落的情歌王。从出道时的内向低落,一步步到成为爸爸后变得活泼开朗。
点击阅读原文,下载源代码和数据包(密码gecv)~
以上是关于用文本挖掘来认识周杰伦的主要内容,如果未能解决你的问题,请参考以下文章