读书札记丨文本挖掘的在线小工具
Posted 空间人文与场所计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读书札记丨文本挖掘的在线小工具相关的知识,希望对你有一定的参考价值。

那么我们与文本挖掘有什么关系呢?举个栗子,我们对《园冶》进行了文本分析,得知《园冶》中出现频率最高的词是“厅堂”(下文中会讲解分析的方法),那么是不是我们根据这个文本分析的结果来探究园林与“厅堂”之间的关系呢?这仅仅是小编对文本挖掘中最基础的分析结果所作出的思考。
那么什么是文本挖掘呢?
“文本挖掘(text mining),又称文本数据挖掘(text data mining),是一种多学科混杂的领域,涵盖了多种技术,包括数据挖掘技术、信息抽取、信息检索,机器学习、自然语言处理、计算语言学、统计数据分析、线性几何、概率理论甚至还有图论。文本挖掘利用智能算法,如神经网络、基于案例的推理、可能性推理等,并结合文字处理技术,分析大量的非结构化文本源(如文档、电子表格、客户电子邮件、问题查询、网页等),抽取或标记关键字概念、文字间的关系,并按照内容对文档进行分类,获取有用的知识和信息。”
—— http://blog.csdn.net/jdbc/article/details/50579848
下面小编来介绍几个文本挖掘中常用的在线平台:

1、NLPIR汉语分词系统
http://ictclas.nlpir.org/nlpir/
“NLPIR能够全方位多角度满足应用者对大数据文本的处理需求,包括大数据完整的技术链条:网络抓取、正文提取、中英文分词、词性标注、实体抽取、词频统计、关键词提取、语义信息抽取、文本分类、情感分析、语义深度扩展、繁简编码转换、自动注音、文本聚类等。”
—— NLPIR平台简介
此平台因为非商业化,所以对文本的篇幅大小有所限制,字数限制为3000字。

NLPIR的分析功能(图片来源于网络)
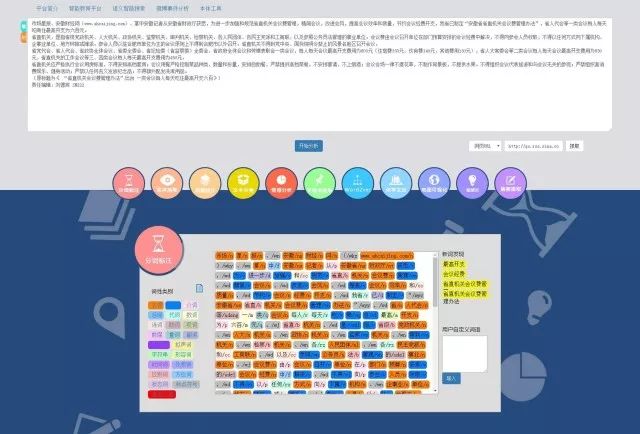
NLPIR的界面
1.1 分词系统
“NLPIR的分词系统可对原始语料进行分词、自动识别人名、地名、机构名等未登录词、新词标注以及词性标注。并可在分析过程中,导入用户定义的词典。”
—— NLPIR平台简介

NLPIR的分词工具
1.2 实体抽取
“NLPIR实体抽取系统能够智能识别文本中出现的人名、地名、机构名、媒体、作者及文章的主题关键词,这是对语言规律的深入理解和科学预测,其所提炼出的词语不需要在词典库中事先存在。”
—— NLPIR平台简介
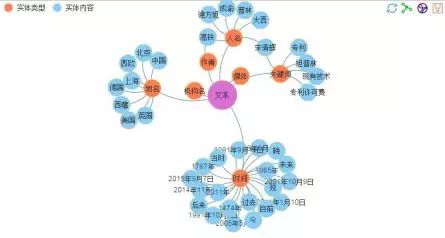
实体抽取力导向布局图
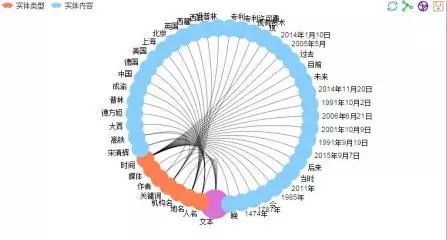
实体抽取和弦图表现
NLPIR的实体抽取(根据平台绘制)
1.3 词频分析
“词频分析展示了名词、动词、形容词三种开放词类的Top 10结果。”
—— NLPIR平台简介
并且提供了折线图、数据视图、柱状图三种不同的表现方式。

NLPIR的词频分析(根据平台绘制)
1.4 文本分类
“NLPIR采用深度神经网络对分类体系进行了综合训练。演示平台目前训练的类别只是新闻的政治、经济、军事等。我们内置的算法支持类别自定义训练,该算法对常规文本的分类准确率较高,综合开放测试的F值接近86%。NLPIR深度文本分类,可以用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等诸多方面。此外还可以实现文本过滤,能够从大量文本中快速识别和过滤出符合特殊要求的信息,可应用于品牌报道监测、垃圾信息屏蔽、敏感信息审查等领域。”
—— NLPIR平台简介
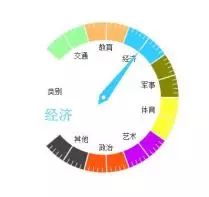
NLPIR的文本分类(根据平台绘制)
1.5 情感分析
“NLPIR情感分析提供两种模式:全文的情感判别与指定对象的情感判别。”
—— NLPIR平台简介
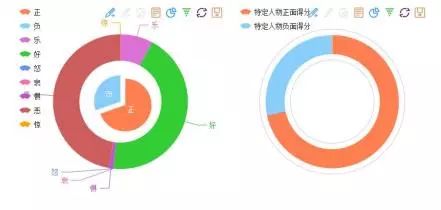
情感分析的饼状图表示
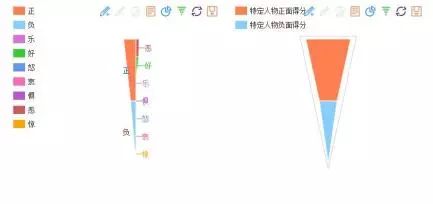
情感分析的漏斗图表示
NLPIR的情感分析(根据平台绘制)
1.6 关键词提取

文本表现
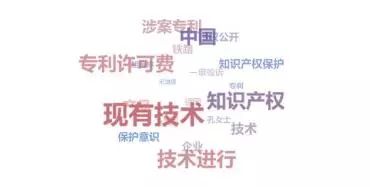
图表表现
NLPIR的关键词提取(根据平台绘制)
1.7 word2vec语义扩展
“POS-CBOW方法综合了词性、词的分布特点,采用word2vector改进模型,对5GB的微博语料进行训练,自动提取出了语义关联关系。如果训练文本调整为专业领域的生语料,该模型同样可以产生专业领域的本体关联关系。”
——NLPIR平台简介
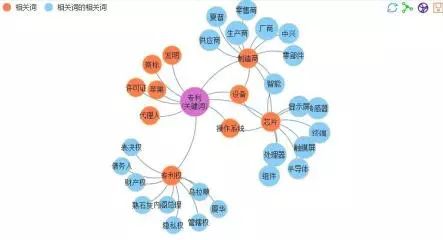
NLPIR的word2vec(根据平台绘制)
1.8 文本摘要
“NLPIR自动文本摘要中间件能够实现文本内容的精简提炼,从长篇文章中自动提取关键句和关键段落,构成摘要内容,方便用户快速浏览文本内容,提高工作效率。自动摘要中间件不仅可以针对一篇文档生成连贯流畅的摘要,还能够将具有相同主题的多篇文档去除冗余,并生成一篇简明扼要的摘要。用户可以自由设定摘要的长度、百分比等参数。其处理速度达到每秒钟20篇。”
—— NLPIR平台简介

NLPIR的文本摘要(根据平台绘制)
2、 MARKUS
http://dh.chinese-empires.eu/markus/
MARKUS是一个半自动的古籍标记平台,由荷兰莱顿大学魏希德教授主持建设的工具。利用MARKUS,可以自动或半自动的将中国文言文中的人名、地名、时间、官职等信息标识出来。
此平台在标记准备时需选择文本相应的时间段或朝代,以便根据不同的时间段进行工作。其次该平台也提供手工标记的功能,如果该平台标记的不准的话还可以进行校正修改。
使用前需先注册,否则有些功能无法正常使用。操作步骤如下:
2.1上传文本
该平台提供两种方式上传文本。一种方式是上传txt格式文件;另一种方式是直接复制文字到输入栏。
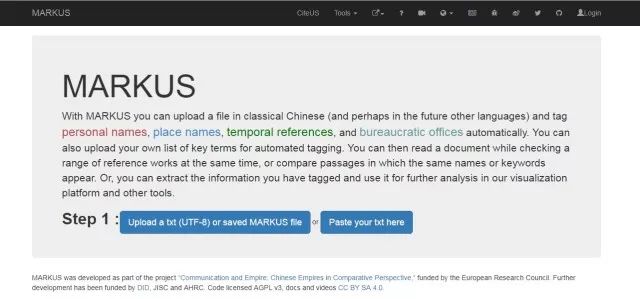
MARKUS的界面
2.2工作方式的选择
本平台有三种工作方式,这里我们一般选择自动标记方式。
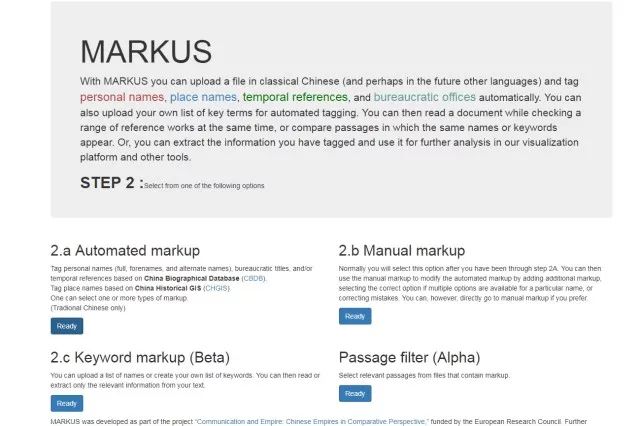
选择工作方式
2.3参数的设定
这里一般需要设置的是根据文本的编写时间,选择相应的时间段。
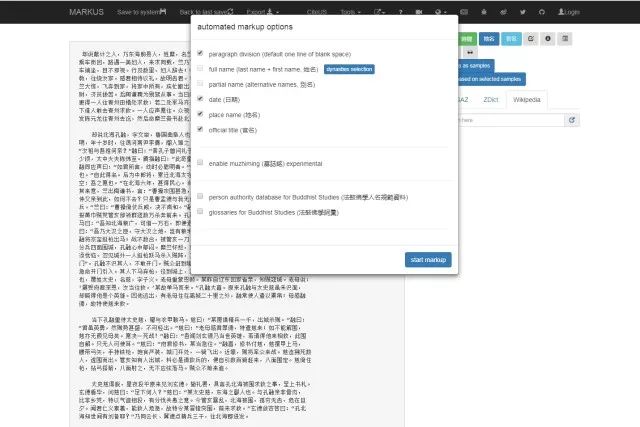
参数设定界面
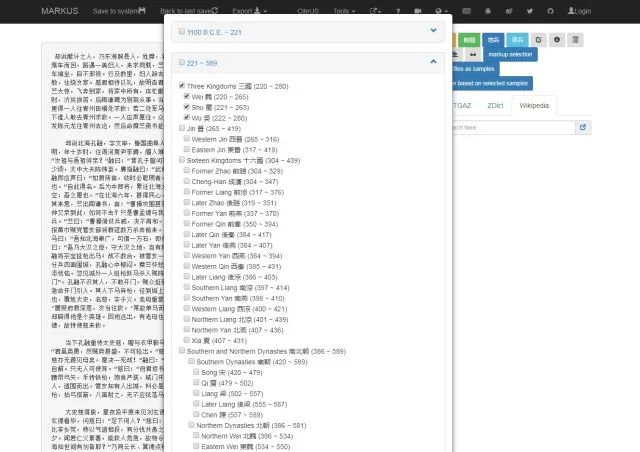
选择参数
2.4工作完成
平台完成了对文本的自动标记任务,在网页右侧可以看见“姓名”“别名”“时间”“地点”“官名”五个不同颜色的标签,同时在文本框中可看到根据不同标签对文字进行的标记任务。同时点击这些标签可以变换其显示的样式。
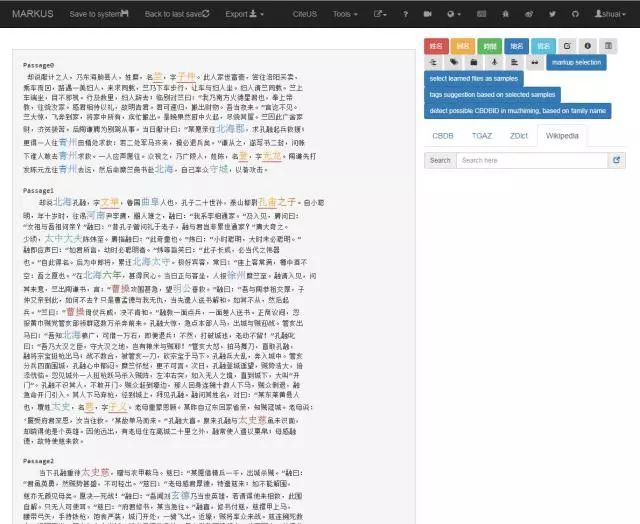
结果呈现
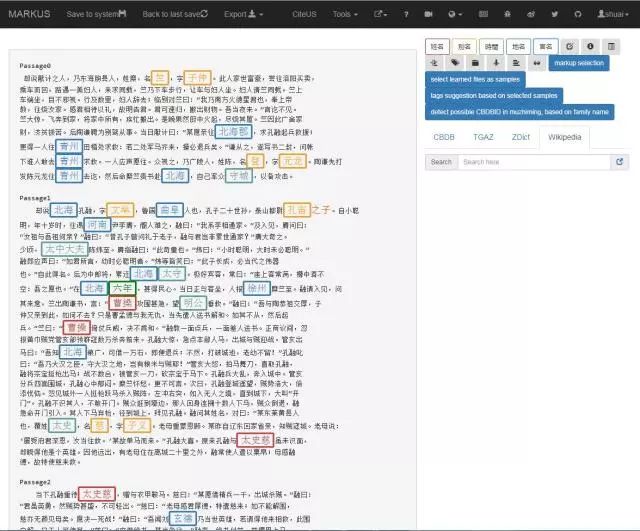
更改显示方式
2.5手动标记
作为数字工具,当然不能做到十全十美。后期也需要检查修改。本平台也提供了为用户手动标记的功能。在网页左侧点击工具栏,选择manual后就可对选择的文字进行标记了。
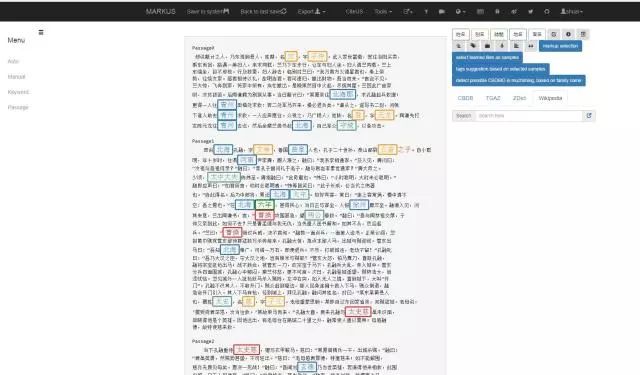
选择手动标记工具

选择标记标签
该平台也可提供关键字的设定、段落筛选的功能,同时也支持对标记数据的下载。
3、中国哲学书电子化计划
http://ctext.org/zhs
“中国哲学书电子化计划是一个线上开放电子图书馆,为中外学者提供中国历代传世文献,力图超越印刷媒体限制,通过电子科技探索新方式与古代文献进行沟通。收藏的文本已超过三万部著作,并有五十亿字之多,故为历代中文文献资料库最大者。”
—— 中国哲学书电子化计划简介
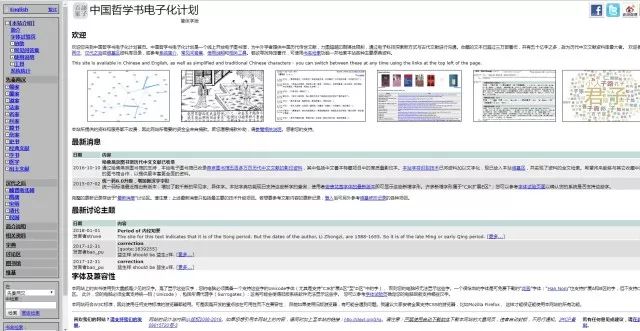
网页界面
该平台在阅读原典时提供了许多自带的功能。可以点击不同的功能图表进行查看。
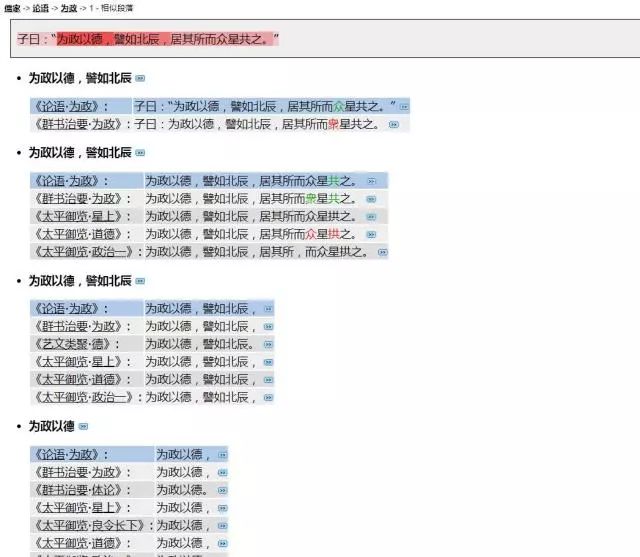
比如我们对《论语》中《为政》篇的一小节进行相似段落查询,可以显示其它著作中与该句相同或相似的句子。颜色越深,说明相似的次数越多。

本平台还嵌入了文本分析工具的应用程式接口。这些应用程式接口主要是对原典中的文本进行分析。用户可以根据不同的需求选择安装。

如我们对计成的《园冶》利用text tools进行N-gram分析,参数设置为2。
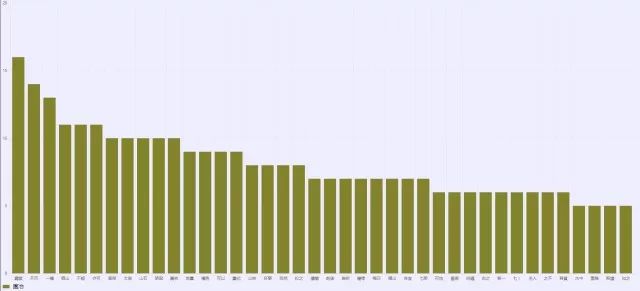
我们得出全文中出现最多的词依次是“厅堂”、“不可”、“一种”、“假山”、“不能”、“亦可”、“草架”、“太湖”、“山石”、“架梁”、“园林”、……
同时也可以查看该词在全文中出现的位置。
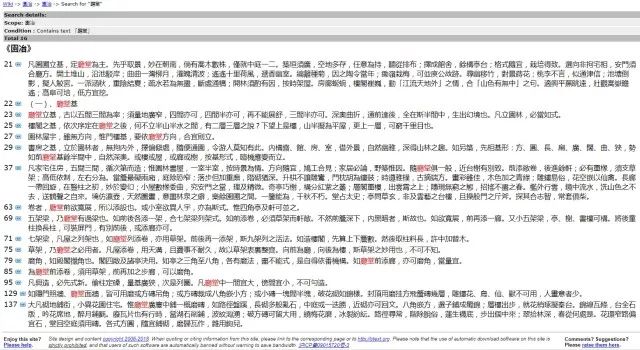
根据词出现的频率生成词云。

该平台也嵌入码库思(MARKUS)工具,全文输出工具。在此不做介绍了。
4、图悦
http://www.picdata.cn/indexb.php
图悦是一款在线的热词分析工具,它可以对于载入文本或指向文本内容的连接进行词频提取和词语权重分析,并可以导出成excel格式的文件,便于后期分析和处理。
图悦的界面
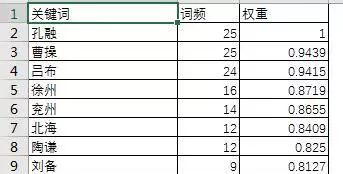
EXCEL导出数据
5.总结
文本挖掘的工具随着数字人文的发展而不断涌现,这些工作可为学者做一些重复机械低水平的工作,节省学者的时间精力,从而将时间精力转移到思辨上。上述几个工具只是文本挖掘工具中冰山一角,其它文本挖掘或文本可视化的工具还有很多。但无论工具的多少,最核心的是使用这些工具做些什么,也就是思辨上的问题吧!
编辑:刘帅帅
校对:勾乐梅、马昭仪
空间人文与场所计算实验室
微信ID:SHAPC_lab
长按左侧二维码关注
以上是关于读书札记丨文本挖掘的在线小工具的主要内容,如果未能解决你的问题,请参考以下文章