九沐·量化:基于文本挖掘的主题投资策略
Posted 九沐资本
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了九沐·量化:基于文本挖掘的主题投资策略相关的知识,希望对你有一定的参考价值。
1.引言
主题投资作为A股市场上一种重要的投资机会,反映了投资者对市场上发生的热点事件的解读,同时也是不同市场参与者的心理博弈过程。如果我们能通过一种方式第一时间抓住这些投资者关心的热点,并且找出这些热点的变化规律,我们就有机会更快地介入此类投资机会,获得丰厚的收益。
本报告首先介绍了一种文本挖掘的算法来构建主题数据,包括用来描述主题本身的主题词向量和描述其构成的个股集合。在此基础上,我们提出了主题的活跃期限有界性,从而将研究的范围进一步聚焦。同时,为了度量主题内个股和主题的关系,我们定义了四类因子,分别是动量因子,分析师推荐因子,新闻报道因子和行业相似性因子。这些因子的选取都是基于对历史的主题轮动规律一些数量化的观察。最后,我们将构建一个主题内选股的多空策略。实证结果表明,该策略从2014年初开始,在相对较低的回撤条件下,可以获得比较稳定的相对收益。
2.主题数据构建
2.1.热点主题挖掘
热点主题的挖掘方式有很多。最简单常用的方式是直接通过各大财经网站的主题概念板块抓取。但是通过爬取网站的方式来获取主题有诸多弊端。其一,这样的爬取方式非常依赖源网站本身,数据的质量也很依赖于源网站;其二,通过爬取网页的方式获得主题,很大程度上具有比较高的延迟性,也就是说,这种方式并不能第一时间获得市场上最活跃的主题。为了解决以上问题,我们介绍一种基于新闻文本挖掘的主题获取方式。通过该方式可以在主题异动的第一时间监控到主题的异动。
该算法的核心思想是,一个主题的异动往往带来的是对这个主题大量持续的报道,更有甚者,在主题还没有在市场上有所表现的时候,就已经有大量的新闻报道产生了,从而使得和该热点相关的新闻数量在这一时间达到一个突发的高点。从此角度出发,我们可以对近期的全量新闻进行文本聚类,将描述同一个事件的新闻聚到一个类别中,而热点事件由于受到广泛关注,很容易从聚类类别中“脱颖而出”。我们拿2015年2月28日,柴静发布雾霾深度调查视频《穹顶之下》为例,该视频的发布对A股市场造成了强烈的冲击,环保板块、大气治理板块保持了3到4个交易日的强势表现。也就是说,在市场对该热点有所反应之前,我们其实已经能够从新闻中捕捉到这样的新闻了。这些新闻大部分是对热点事件本身的报道,或者是一些专家学者对该热点的解读。因此,我们首先需要从全量文本中将该热点相关的新闻找到,在此基础上再进行信息提取。根据以上思路,热点主题的挖掘流程可以分为四个步骤:
1.新闻文本聚类。对算法执行当天的最近N天的全量新闻进行文本聚类。通过文本聚类,可以将类似新闻汇聚到一个集合中,从而可以在下一步对即将研究的新闻集合进行进一步处理。应用新闻聚类算法的核心是如何度量两个新闻文本之间的相似度。一般的做法是将新闻文本的相似度度量转换为两个文本的关键词向量之间的相似度度量,通过两个向量的cosine相似度即可描述文本之间的相似度。新闻文本的关键词向量可以使用TFIDF算法抽取,即对于每个文本,抽取TFIDF值最高的n个关键词作为关键词向量。新闻文本聚类过程一定要特别注意短文本聚类问题。由于短文本的关键词向量维度较小,很容易在聚类过程中出现分错类别的情况,因此,如有必要,可以通过标题聚类的方式将短文本进行归类,做特别处理。
2.筛选热点主题。通过上一步的新闻聚类,我们已经将类似新闻聚集到同一个集合中。我们关心的是那些包含的新闻数量最多的集合,因为这些集合中很可能包含市场热点。上文已经提到,对于热点事件,新闻记者会争相报导且频繁转发,从而导致此类新闻聚集到同一个集合中,形成大的集合。因此,在这一步,我们选取新闻数量排名前1%的类别作为待挖掘主题的热点文本集合。
3.候选关键词提取。在这一步,我们对第二步得到的文本集合进行关键词提取,我们希望通过这些关键词代替新闻文本来描述主题。通过文本抽取关键词的技术非常多,常用的算法包括上文提到的TF-IDF算法,类似Google搜索排序的TextRank算法,中科院研发的基于邻接词信息熵的ICTCLAS自然语言处理器等。一般来说,如果我们已经有比较好的外部知识库,比如比较完善的新词词典,或者主要词语的IDF得分词典,那么用相对比较简单的TF-IDF就可以解决大部分问题了。如果没有这样的知识库积累,可以考虑使用TextRank或者其他更复杂的算法。
4.确定主题名称(标签)。我们希望对每个挖掘出的热点文本集合打一个名称标签来说明这是一个怎样的主题或者概念,所以需要从候选关键词中选取一个最适合做主题名称的词语。一般来说,对于一些热点市场上会有一些比较统一、成熟的称谓,因此我们可以借鉴投资者对这一类热点的称谓来给主题打标签。具体的做法是:计算每个关键词加“概念”,“主题”,或“板块”这些后缀之后在新闻文本中出现的次数,取出次数最高的那个词语作为主题名称。
2.2.主题个股挖掘
对于每个主题,我们从新闻和研报文本中抽取管理个股。这里抽取的个股是候选个股集合,我们并不对个股和主题之间的相似性关系做更多描述。这些关系的描述后文会通过一系列因子给出。抽取的具体方法是,如果一篇文章中出现了“主题词+概念”的模式,则挖出文本中该模式附近的所有个股的词语,并将这些个股加入主题候选个股集合中,对应记录出现的次数。遍历所有文本后,对每个主题,过滤掉出现次数较少的个股,得到最终的候选集合。
总结来说,关键点在于两点:1.附近。这里的抽取算法抽取的是“主题词+概念”模式附近的词语。这里附近的衡量标准可以是以句号分隔的两个完整句子。2.过滤。对那些出现较少的个股,将其过滤,因为那些大概率是噪音。很多新闻会同时提及多个概念,但是从统计意义上来说,某两个主题同时被提及的概率则降低很多。因此,即使因为一篇文章提到了多个主题而混入噪音,我们也可以通过统计意义上的方法来去噪。
2.3.主题活跃期构建
随着时间的推移,越来越多的主题被沉淀下来,但是这些主题并非所有都是有研究价值的。我们认为,只有在主题的活跃区间内才有研究价值,也就是说,只有在新闻、研报中被提及达到一定的次数,说明市场的关注度较高,这部分的主题相对比较有研究价值。为了验证此想法,我们考察了主题库中所有主题的热度分布情况。
具体来说,定义:
绝对热度=研究区间内主题相关研报+新闻数量相对热度=绝对热度/研究区间时间
也就是说,用相对热度来表示平均每天主题关联的文本数量,总体上主题的相对热度分布如下图所示。
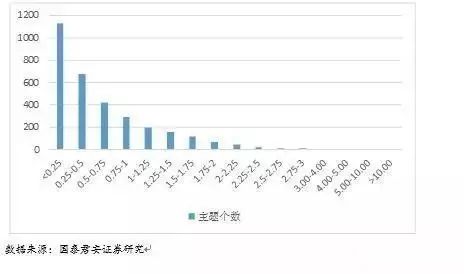
从图表中不难看出,超过80%的主题的相对热度都很低,平均每天相关的新闻、研报数量不到1个。因此,我们可以通过设定主题热度的阈值过滤那些非活跃的主题,留下活跃的主题。实验数据表明,在市场上某一特定时间点t,活跃的主题数量一般不超过300个。因此,为了确定每一个主题的活跃区间,我们可以使用绝对热度值来发现那些热度高涨的时间点。为了使得热度曲线更加平滑,实际操作中我们使用7天的移动平均值对绝对热度做平滑,得到MA(Heat-7d)曲线。设MA(Heat-7d)在t时刻的观察值为MA(Heat-7d)t,均值为x,标准差为s,则活跃区间T为:
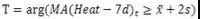
3.主题内选股因子
基于主题数据,我们考虑描述主题和其个股的关系。我们希望通过不同维度的指标描述其关系,并发掘通过这些指标是否能够找出主题内的龙头股,或者具有龙头潜力的股票。为此,我们将从个股动量维度、分析师推荐维度、新闻报道维度和行业维度四个角度来描述。
3.1.个股动量因子
主题的发展一般要经历潜伏期、出现期、成熟期、消退期的过程,也就是说,主题的发展并不是一蹴而就的,而是一个持续的过程。基于这样的发现,我们同样希望考察主题内的领涨股是否具有同样的特征。也就是说,考察主题下领涨股虽然经常变换,但是,这种变换是否也需要一定的时间。
假设定义一个主题下连续n天的移动平均收益作为考察一个股票是否是领涨股的根据,且如果主题下某个个股在T时间,其过去n天的移动平均收益排名整个主题的前10%,则该个股被认为是领涨股。根据以上定义,我们对所有在活跃期的主题数据进行了调研,并找出每个主题的所有符合领涨股条件的个股作为样本,考察其从领涨股变为非领涨股需要的时间。结果下图所示。
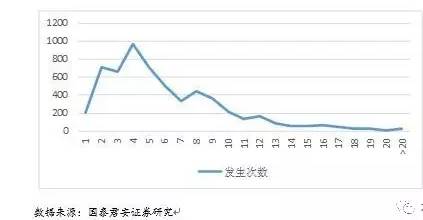
由上图不难看出,大部分主题龙头股持续时间在2-6个交易日,即龙头的切换需要一定的时间演变。因此,我们可以借助动量策略的思想,在第一时间介入个股,获得收益。当然,对于不同的市场行情和不同的主题炒作区间情况会有所不同,但是这并不影响我们将动量数据作为衡量龙头潜力的重要指标。这里,我们选择过去n天(n=1,2,…,10)的单日相对收益作为个股的动量特征。另一种做法是利用更多维度的特征值,例如取n=1,2,…,30,然后对这些特征进行降维,取出相对比较独立的特征。由于前十维特征已经能比较好的揭示动量信息,因此这里我们简单使用第一种方式。
在之前的报告《分析师对投资者行为的影响》一文中,我们发现在一定条件下,分析师评级上调,或者首次覆盖具有超额收益。借鉴这篇报告的思想,我们希望从研报文本的角度来挖掘个股因子。由于分析师会在深度行业报告中对未来可能有投资潜力的主题及其个股进行重点推荐,因此,我们可以通过考察研报中主题和个股的共现情况来决定是否要买入相关标的。具体来说,我们定义了两个因子来描述此信息,即共现相似度和TF-IDF相似度:
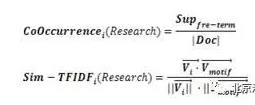
其中,共现相似度非常直接,描述的是主题词和个股词共同出现的频率。具体来说,对于某主题,通过文本匹配(或搜索)挖掘出最近N天的所有研报文本,计算文本中主题词向量中每个词和个股的共现项,如果该项数量大于事先设定的最小支持度(即阈值),则认为该项目是频繁项,记频繁项出现的次数称为其支持度。共现相似度公式实际上就描述了平均每篇文本中出现的共现项目的数量。但是,在研究的时间区间中(例如周换仓策略,研究时间区间即为约5个交易日),并非所有的候选股票都会被分析师推荐。实验数据表明,大部分情况该数值都为0,因此,这是一个非常稀疏的因子。为了解决稀疏性问题,我们引入了TF-IDF因子对其进行稠密化,即不是只有个股词本身出现才计算贡献度,而是只要个股相关文本出现就可以给出相似度贡献。例如,通过文本挖掘得到个股东方财富的关键词向量为:(东方财富,天天基金,互联网,移动互联网,金融数据,电子商务,信息技术,政通股份,运营商,彩票…)
通过该向量和上文已经得到的主题词向量计算cosine相似度,即可得到第二维因子。从逻辑上讲,TF-IDF因子实际上是对共现相似度因子的稠密化,因为个股向量中大部分关键词描述的是该股票从事的主要行业或者主要业务。
3.3.新闻报道因子
借鉴研报文本挖掘的思路,我们希望在新闻中使用类似的因子刻画个股的投资潜力。为了提高新闻文本的质量,我们在具体的操作中去除了门户网站的新闻,增加了行业深度网站的新闻。在这些新闻文本中,同样类似研报计算其新闻中的共现相似度和新闻中的TF-IDF相似度因子:

3.4.行业相似度因子
上文提到,很多主题是横跨多个行业的概念,例如“二胎”,“国企改革”等。我们希望从行业的角度考察主题内的领涨股是否具有一定的行业特征。因此,我们对2014年1月起的每个月的主题数据进行统计,观察注体内领涨股从属于该主题中主要行业的次数占比。即,如果一个主题中有n只股票,将这n只股票根据申万行业分类进行行业划分,行业内股票数最多的那个行业即为该主题的主要行业。对每个月的所有主题,计算领涨股从属主题内主要行业的次数与领涨股总个股的比例得到占比,观察占比和上证综指的变化关系,具体的统计结果和大盘走势比较如下图所示。
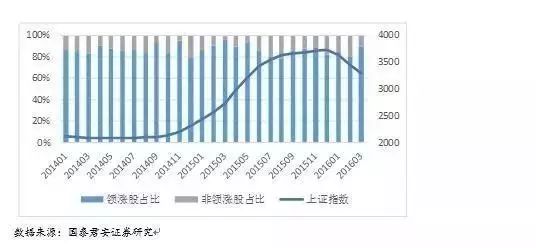
从上图不难看出,大部分情况下,领涨股从属主题内主要行业的概率都超过了80%,只有在大盘相对弱势的情况下下滑到70%左右。因此利用此信息,定义了行业相似度因子:

该因子衡量的是主题内某只股票所在的行业,其行业的个股数量占整个主题股票池中股票数量的比值。也就是说,如果个股从属主要行业,则该数值越大。
4.主题内选股策略和实证分析
通过上述四类因子的构建,我们已经可以描述主题和个股之间的关系。下面,我们通过这四类因子来对每个主题分别进行建模,从而希望能够通过主题内选股获得稳定的相对收益。
4.1.选股模型构建
对于每个主题,我们分别对其进行建模。由于我们可以获得历史上四类因子的数据,因此可以对相对主题指数的累计超额收益进行回归,得到回归参数,从而用该模型预测下一阶段主题内个股成为领涨股的潜力大小。
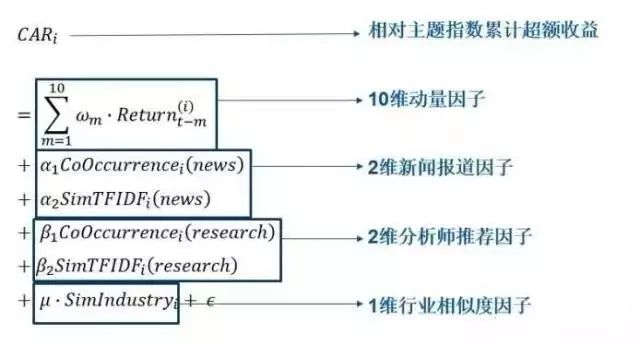
我们对模型回归后的参数进行观察,发现其对模型的贡献大小如表5所示。
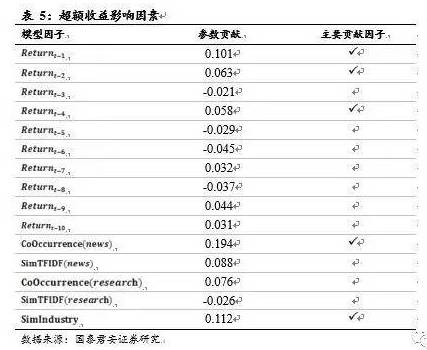
从表5不难发现,主要贡献因子有三维的动量特征,新闻共现因子,以及行业相似性因子。也就是说,模型在选股时偏重于那些主题内的主要龙头行业,并且新闻热度较高,同时具有动量特征的个股。
4.2.实证分析
利用以上模型,我们构建了周换仓的多空策略,在每周第一个交易日做多模型打分最高的前10%标的,做空打分后10%标的,考虑双边交易费用千二。
回测区间:2014年1月1日-2016年3月1日
初始净值:1
最终净值:1.4793
年化收益:21.57%
最大回撤:5.04%
最大回撤区间:2015-08-07至2015-09-07
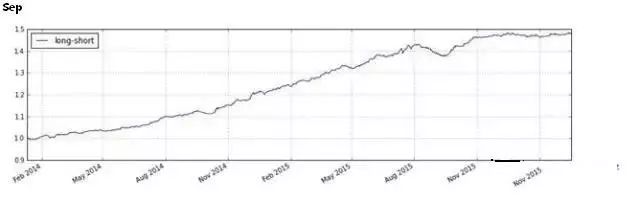
从策略回测结果可以看到,主题内选股策略在14年初到15年中这段牛市中表现非常稳健,而最大回撤则出现在第二次股灾中。查看这段时间的持仓发现,这段时间前期涨幅较大的“主题龙头”都经历了一波较大的回调。而在策略后期,策略曲线相对比较平缓,观察持仓发现,由于这段时间市场比较萎靡,能够达到上文提到的“活跃主题”的数量明显减少,因此样本数也减少很多,从而导致主题内个股的区分效应不大。
5.总结
通过上文的描述,我们已经可以从数据处理入手,构建一套基于主题投资的体系结构。我们总结基于主题投资的体系结构如图所示。
详细报告请查看20160705发布的国泰君安金融工程量化专题报告《基于文本挖掘的主题投资策略》。
联系我们:
电子邮箱:jmzb@jiumuziben.com
以上是关于九沐·量化:基于文本挖掘的主题投资策略的主要内容,如果未能解决你的问题,请参考以下文章