干货练习题︱基于今日头条开源数据的文本挖掘
Posted 素质云笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货练习题︱基于今日头条开源数据的文本挖掘相关的知识,希望对你有一定的参考价值。
今
日
头
条
文
本
挖
掘
最近笔者在做文本挖掘项目时候,写了一些小算法,不过写的比较重,没有进行效率优化,针对大数据集不是特别好用,不过在小数据集、不在意性能的情况下还是可以用用的。
代码和数据在我的github之中,戳原文阅读~
本次练习题中可以实现的功能大致有三个:
短语发现
新词发现
词共现
先来看看数据长啥样:
每行为一条数据,以!分割的个字段,从前往后分别是 新闻ID,分类code(见下文),分类名称(见下文),新闻字符串(仅含标题),新闻关键词。
亮点:关键词质量还挺高的,可以作为自定义词典
短语发现、新词发现模块

该模块可以允许两种内容输入,探究的是词-词之间连续共现,一种数据格式是没有经过分词的、第二种是经过分词的。
其中,算法会提到全部发现以及部分发现两种模式,这两种模式的区别主要在于考察指标的多少。
全部发现会考察:凝聚度、自由度、IDF、词频
部分发现会考察:IDF、词频
没有经过分词的原始语料
在今日头条数据之中就是标题数据了,一般用来新词发现,这边整体运行很慢,就截取前10000个。
得到的结论,如图: 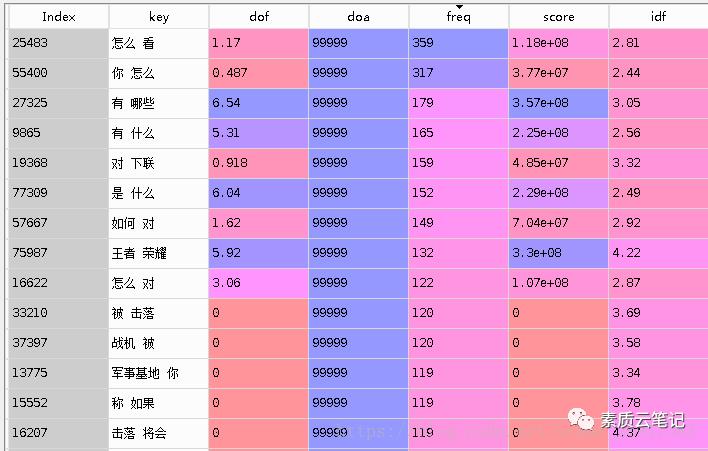
这边其实可以在Jieba分词的时候,预先载入一些停用词。
这边来看,发现比较好的只有:对下联、王者荣耀
当然了,主要是因为只载入了很少的语料,没有好好学。
经过分词的原始语料
比较适合用在已经分完词的语料比较适合:[[‘经过’,’分词’],[‘的’,’原始’],[‘原始’,’语料’],…]
当然,探究的是词-词之间的连续共现的情况。
此时,我用今日头条的关键词其实不是特别合适,因为关键词之间没有前后逻辑关系在其中。
得到的结论: 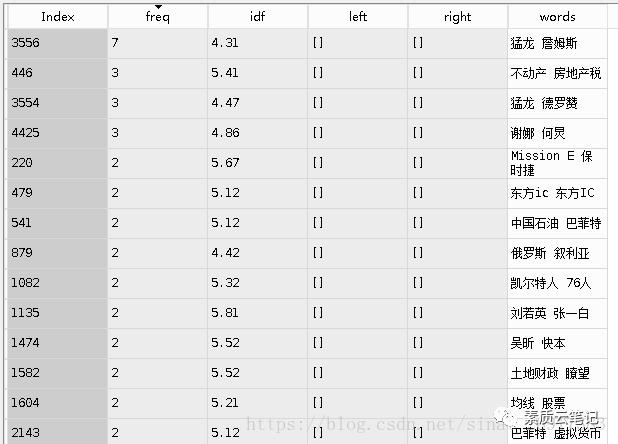
其中发现了的规律都没啥用,大家看看就行。
有一些比较有意思的对子,猛龙-詹姆斯、不动产-房地产税,这些都还算工整。
词共现模块
二元组模块跟4.1中,分完词之后的应用有点像,但是这边是离散的,之前的那个考察词-词之间的排列需要有逻辑关系,这边词共现会更加普遍。
该模块较多会应用在基于关键词的SNA社交网络发现之中,给张好看的图: 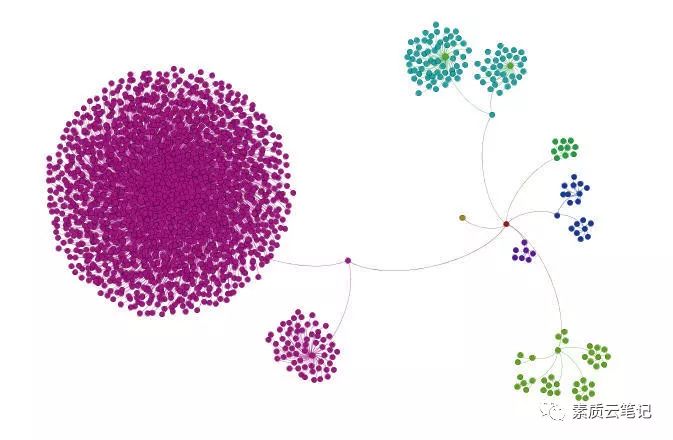
其中,在该模块写入了两种:
热词统计
词共现统计
词共现统计
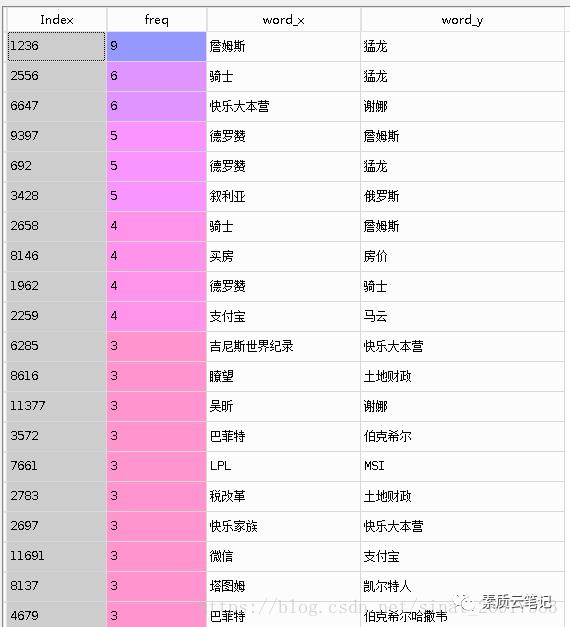
词共现比较注重同时提及的频率,这里比较好的对子有:
詹姆斯-猛龙、快乐大本营-谢娜、叙利亚-俄罗斯、快乐家族-快乐大本营...
这里可以发现很多有意思的小点,这块还是很有意思,看客可以自由发挥。
热词统计

这块很普通了,可以用来画词云。
得到了CoOccurrence_data 的表格,有了词共现,就可以画社交网络图啦,有很多好的博客都有这样的介绍,贴两张图:
以上是关于干货练习题︱基于今日头条开源数据的文本挖掘的主要内容,如果未能解决你的问题,请参考以下文章