应用Python做文本挖掘的情感极性分析
Posted 数据科学与人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了应用Python做文本挖掘的情感极性分析相关的知识,希望对你有一定的参考价值。
笔者邀请您,先思考:
1 文本情感分析是什么?
2 如何对文本做情感分析?
「情感极性分析」是对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析。其中,前者多用于舆情监控和信息预测,后者可帮助用户了解某一产品在大众心目中的口碑。
目前常见的情感极性分析方法主要是两种:基于情感词典的方法和基于机器学习的方法。
1. 基于情感词典的文本情感极性分析
笔者是通过情感打分的方式进行文本情感极性判断,score > 0判断为正向,score < 0判断为负向。
1.1 数据准备
1.1.1 情感词典及对应分数
词典来源于BosonNLP数据下载
http://bosonnlp.com/dev/resource
的情感词典,来源于社交媒体文本,所以词典适用于处理社交媒体的情感分析。
词典把所有常用词都打上了唯一分数有许多不足之处。
之一,不带情感色彩的停用词会影响文本情感打分。在
1.1.2 否定词词典
否定词的出现将直接将句子情感转向相反的方向,而且通常效用是叠加的。常见的否定词:不、没、无、非、莫、弗、勿、毋、未、否、别、無、休、难道等。
1.1.3 程度副词词典
既是通过打分的方式判断文本的情感正负,那么分数绝对值的大小则通常表示情感强弱。既涉及到程度强弱的问题,那么程度副词的引入就是势在必行的。词典可从《知网》情感分析用词语集(beta版)
http://www.keenage.com/download/sentiment.rar
下载。词典内数据格式可参考如下格式,即共两列,第一列为程度副词,第二列是程度数值,> 1表示强化情感,< 1表示弱化情感。

程度副词词典
1.1.4 停用词词典
中科院计算所中文自然语言处理开放平台发布了有1208个停用词的中文停用词表,
http://www.datatang.com/data/43894
也有其他不需要积分的下载途径。
http://www.hicode.cc/download/view-software-13784.html
1.2 数据预处理
1.2.1 分词
即将句子拆分为词语集合,结果如下:
e.g. 这样/的/酒店/配/这样/的/价格/还算/不错
Python常用的分词工具:
结巴分词 Jieba
Pymmseg-cpp
Loso
smallseg
from collections import defaultdictimport osimport reimport jiebaimport codecs""" 1. 文本切割 """def sent2word(sentence):
""" Segment a sentence to words Delete stopwords """
segList = jieba.cut(sentence)
segResult = [] for w in segList:
segResult.append(w)
stopwords = readLines('stop_words.txt')
newSent = [] for word in segResult: if word in stopwords: # print "stopword: %s" % word
continue
else:
newSent.append(word) return newSent在此笔者使用Jieba进行分词。
1.2.2 去除停用词
遍历所有语料中的所有词语,删除其中的停用词
e.g. 这样/的/酒店/配/这样/的/价格/还算/不错
--> 酒店/配/价格/还算/不错
1.3 构建模型
1.3.1 将词语分类并记录其位置
将句子中各类词分别存储并标注位置。
""" 2. 情感定位 """def classifyWords(wordDict):
# (1) 情感词
senList = readLines('BosonNLP_sentiment_score.txt')
senDict = defaultdict() for s in senList:
senDict[s.split(' ')[0]] = s.split(' ')[1] # (2) 否定词
notList = readLines('notDict.txt') # (3) 程度副词
degreeList = readLines('degreeDict.txt')
degreeDict = defaultdict() for d in degreeList:
degreeDict[d.split(',')[0]] = d.split(',')[1]
senWord = defaultdict()
notWord = defaultdict()
degreeWord = defaultdict() for word in wordDict.keys():
if word in senDict.keys() and word not in notList and word not in degreeDict.keys():
senWord[wordDict[word]] = senDict[word]
elif word in notList and word not in degreeDict.keys():
notWord[wordDict[word]] = -1
elif word in degreeDict.keys():
degreeWord[wordDict[word]] = degreeDict[word]
return senWord, notWord, degreeWord1.3.2 计算句子得分
在此,简化的情感分数计算逻辑:所有情感词语组的分数之和
定义一个情感词语组:两情感词之间的所有否定词和程度副词与这两情感词中的后一情感词构成一个情感词组,即notWords + degreeWords + sentiWords,例如不是很交好,其中不是为否定词,很为程度副词,交好为情感词,那么这个情感词语组的分数为:finalSentiScore = (-1) ^ 1 * 1.25 * 0.747127733968
其中1指的是一个否定词,1.25是程度副词的数值,0.747127733968为交好的情感分数。
伪代码如下:finalSentiScore = (-1) ^ (num of notWords) * degreeNum * sentiScorefinalScore = sum(finalSentiScore)
""" 3. 情感聚合 """def scoreSent(senWord, notWord, degreeWord, segResult):
W = 1
score = 0
# 存所有情感词的位置的列表
senLoc = senWord.keys()
notLoc = notWord.keys()
degreeLoc = degreeWord.keys()
senloc = -1
# notloc = -1
# degreeloc = -1
# 遍历句中所有单词segResult,i为单词绝对位置
for i in range(0, len(segResult)): # 如果该词为情感词
if i in senLoc: # loc为情感词位置列表的序号
senloc += 1
# 直接添加该情感词分数
score += W * float(senWord[i])
# print "score = %f" % score
if senloc < len(senLoc) - 1:
# 判断该情感词与下一情感词之间是否有否定词或程度副词
# j为绝对位置
for j in range(senLoc[senloc], senLoc[senloc + 1]): # 如果有否定词
if j in notLoc:
W *= -1
# 如果有程度副词
elif j in degreeLoc:
W *= float(degreeWord[j])
# i定位至下一个情感词
if senloc < len(senLoc) - 1:
i = senLoc[senloc + 1] return score1.4 模型评价
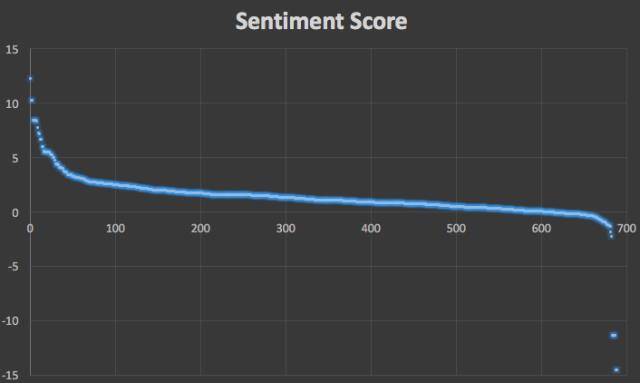
Score Distribution
其中大多数文本被判为正向文本符合实际情况,且绝大多数文本的情感得分的绝对值在10以内,这是因为笔者在计算一个文本的情感得分时,以句号作为一句话结束的标志,在一句话内,情感词语组的分数累加,如若一个文本中含有多句话时,则取其所有句子情感得分的平均值。
然而,这个模型的缺点与局限性也非常明显:
首先,段落的得分是其所有句子得分的平均值,这一方法并不符合实际情况。正如文章中先后段落有重要性大小之分,一个段落中前后句子也同样有重要性的差异。
对于正负向文本的判断,该算法忽略了很多其他的否定词、程度副词和情感词搭配的情况;用于判断情感强弱也过于简单。
总之,这一模型只能用做BENCHMARK...
2. 基于机器学习的文本情感极性分析
2.1 还是数据准备
2.1.1 停用词
(同1.1.4)
2.1.2 正负向语料库
来源于有关中文情感挖掘的酒店评论语料,
http://www.datatang.com/data/11936
其中正向7000条,负向3000条(笔者是不是可以认为这个世界还是充满着满满的善意呢…),当然也可以参考情感分析资源使用其他语料作为训练集。
2.1.3 验证集
Amazon上对iPhone 6s的评论,来源已不可考……
2.2 数据预处理
2.2.1 还是要分词
(同1.2.1)
import numpy as npimport sysimport reimport codecsimport osimport jieba
from gensim.models import word2vec
from sklearn.cross_validation import train_test_split
from sklearn.externals import joblib
from sklearn.preprocessing import scale
from sklearn.svm import SVC
from sklearn.decomposition import PCA
from scipy import stats
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
from sklearn.metrics import f1_score
from bayes_opt import BayesianOptimization as BO
from sklearn.metrics import roc_curve, aucimport matplotlib.pyplot as plt
def parseSent(sentence):
seg_list = jieba.cut(sentence)
output = ''.join(list(seg_list)) # use space to join them
return output2.2.2 也要去除停用词
(同1.2.2)
2.2.3 训练词向量
(重点来了!)模型的输入需是数据元组,那么就需要将每条数据的词语组合转化为一个数值向量
常见的转化算法有但不仅限于如下几种:
(请原谅不知死活的胖子直接用展示的ppt截图作说明,没错,我就是懒,你打我呀)
Bag of Words

Bag of Words
TF-IDF

TF-IDF
Word2Vec
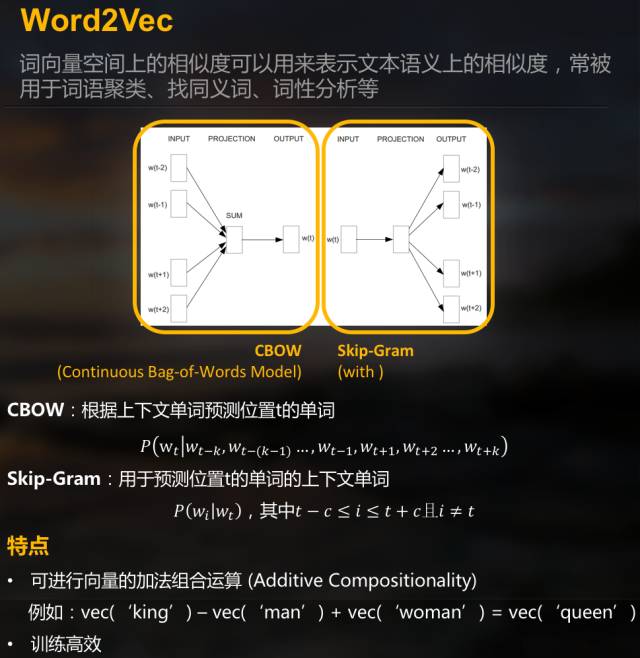
Word2Vec
在此笔者选用Word2Vec将语料转化成向量
def getWordVecs(wordList):
vecs = [] for word in wordList:
word = word.replace('
', '') try:
vecs.append(model[word])
except KeyError:
continue # vecs = np.concatenate(vecs)
return np.array(vecs, dtype = 'float')
def buildVecs(filename):
posInput = [] with open(filename, "rb") as txtfile:
# print txtfile
for lines in txtfile: lines = lines.split('
')
for line in lines:
line = jieba.cut(line)
resultList = getWordVecs(line)
# for each sentence, the mean vector of all its vectors is used to represent this sentence
if len(resultList) != 0:
resultArray = sum(np.array(resultList))/len(resultList)
posInput.append(resultArray) return posInput# load word2vec modelmodel = word2vec.Word2Vec.load_word2vec_format("corpus.model.bin", binary = True)# txtfile = [u'标准间太差房间还不如3星的而且设施非常陈旧.建议酒店把老的标准间从新改善.', u'在这个西部小城市能住上这样的酒店让我很欣喜,提供的免费接机服务方便了我的出行,地处市中心,购物很方便。早餐比较丰富,服务人员很热情。推荐大家也来试试,我想下次来这里我仍然会住这里']posInput = buildVecs('pos.txt')
negInput = buildVecs('pos.txt')# use 1 for positive sentiment, 0 for negativey = np.concatenate((np.ones(len(posInput)), np.zeros(len(negInput))))
X = posInput[:]for neg in negInput:
X.append(neg)
X = np.array(X)2.2.4 标准化
虽然笔者觉得在这一问题中,标准化对模型的准确率影响不大,当然也可以尝试其他的标准化的方法。
# standardizationX = scale(X)2.2.5 降维
根据PCA结果,发现前100维能够cover 95%以上的variance。
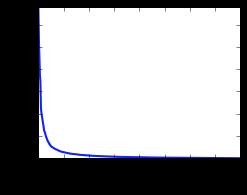
PCA
# PCA
# Plot the PCA spectrum
pca.fit(X)
plt.figure(1, figsize=(4, 3))
plt.clf()
plt.axes([.2, .2, .7, .7])
plt.plot(pca.explained_variance_, linewidth=2)
plt.axis('tight')
plt.xlabel('n_components')
plt.ylabel('explained_variance_')
X_reduced = PCA(n_components = 100).fit_transform(X)2.3 构建模型
2.3.1 SVM (RBF) + PCA
SVM (RBF)分类表现更为宽松,且使用PCA降维后的模型表现有明显提升,misclassified多为负向文本被分类为正向文本,其中AUC = 0.92,KSValue = 0.7。
""" 2.1 SVM (RBF) using training data with 100 dimensions """clf = SVC(C = 2, probability = True)
clf.fit(X_reduced_train, y_reduced_train)print 'Test Accuracy: %.2f'% clf.score(X_reduced_test, y_reduced_test)
pred_probas = clf.predict_proba(X_reduced_test)[:,1]print "KS value: %f" % KSmetric(y_reduced_test, pred_probas)[0]# plot ROC curve# AUC = 0.92# KS = 0.7fpr,tpr,_ = roc_curve(y_reduced_test, pred_probas)
roc_auc = auc(fpr,tpr)
plt.plot(fpr, tpr, label = 'area = %.2f' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.legend(loc = 'lower right')
plt.show()
joblib.dump(clf, "SVC.pkl")2.3.2 MLP
MLP相比于SVM (RBF),分类更为严格,PCA降维后对模型准确率影响不大,misclassified多为正向文本被分类为负向,其实是更容易overfitting,原因是语料过少,其实用神经网络未免有些小题大做,AUC = 0.91。
"""2.2 MLP
using original training data with 400 dimensions"""model = Sequential()
model.add(Dense(512, input_dim = 400, init = 'uniform', activation = 'tanh'))
model.add(Dropout(0.5))
model.add(Dense(256, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(32, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
model.fit(X_train, y_train, nb_epoch = 20, batch_size = 16)
score = model.evaluate(X_test, y_test, batch_size = 16)print ('Test accuracy: ',
score[1])
pred_probas = model.predict(X_test)
# print "KS value: %f" % KSmetric(y_reduced_test, pred_probas)[0]
# plot ROC curve
# AUC = 0.91fpr,tpr,_ = roc_curve(y_test, pred_probas)
roc_auc = auc(fpr,tpr)
plt.plot(fpr, tpr, label = 'area = %.2f' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.legend(loc = 'lower right')
plt.show()2.4 模型评价
实际上,第一种方法中的第二点缺点依然存在,但相比于基于词典的情感分析方法,基于机器学习的方法更为客观
另外由于训练集和测试集分别来自不同领域,所以有理由认为训练集不够充分,未来可以考虑扩充训练集以提升准确率。
来自网络,感谢作者分享。
您有什么见解,请留言。
文章推荐:
加入数据人圈子或者商务合作,请添加笔者微信。

数据人网是数据人学习、交流和分享的平台http://shujuren.org 。专注于从数据中学习到有用知识。
平台的理念:人人投稿,知识共享;人人分析,洞见驱动;智慧聚合,普惠人人。
您在数据人网平台,可以1)学习数据知识;2)创建数据博客;3)认识数据朋友;4)寻找数据工作;5)找到其它与数据相关的干货。
我们努力坚持做原创,聚合和分享优质的省时的数据知识!
我们都是数据人,数据是有价值的,坚定不移地实现从数据到商业价值的转换!
点击阅读原文,进入数据人网,获取数据知识。
链达君,专注于分享区块链内容。
脚印英语,专注于分享英语口语内容。
以上是关于应用Python做文本挖掘的情感极性分析的主要内容,如果未能解决你的问题,请参考以下文章