文本挖掘|如何透过UGC评论文本洞察用户的偏好?以马蜂窝北京食评为例
Posted 泥沙上下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本挖掘|如何透过UGC评论文本洞察用户的偏好?以马蜂窝北京食评为例相关的知识,希望对你有一定的参考价值。
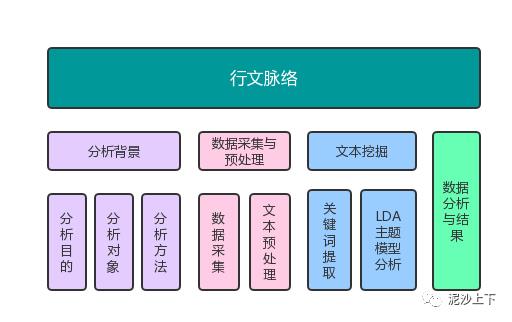
最近在了解growth hacker,学习到分析数据的价值,把这篇旧文翻出来重新打量,并计划后续进行完善,初稿先mark住。以下是本文的行文脉络:
全文共:5037 字
预计阅读时间: 13 分钟


一、分析背景
1.1 分析目的
自 2000 年以来,国内游客数量呈现持续高位增长,推动中国步入了大众旅游时代和国民休闲新阶段,成为世界上拥有国内游客数量最多的国家。而互联网的普及,2017年中国在线度假市场规模飞速发展。
旅游产品是一种典型的体验性产品,消费者在决策过程中往往产生感知风险,这使得旅游消费者在作出购买决策之前需要根据更多的信息来辅助自己作出正确的选择。而随着互联网+的时代到来,旅游社交网站蓬勃发展,越来越多的用户热衷于在旅游社交网站中来记录自己的旅游体验,分享自己的评论,经验,感受,重感,这就是所谓的在线旅游文本,也是本文的研究对象。
旅行社交网站作为社会媒体的一部分,其各方面的在线旅游文本汇集了大量的旅游信息,对现实世界中的每个人都有重大影响,也是我们间接了解现实客观世界和主观世界的一面窗户。如果我们对该行业中的优质社交平台的信息进行分析,除了可以了解该领域的发展进程和现状,还可以对该领域的人群行为进行一定程度的预判。因此,旅游社交网站这些各方面的文本数据汇集了大量的旅游信息,对数据进行文本挖掘,不仅可以获得有价值的信息,还能得到一些有实际意义的结论。
在线旅游UGC文本作为重要的信息源,数据充足丰富。网络评论是用户生成内容(UGC)的一种,并且大多数在线旅游评论出于主动,具备有效性、准确性和真实性。通过分析用户原创内容,可以从游客自身的角度研究游客的行为特征,这为旅游研究提供了一种新的途径。还可以实践内容分析法在旅游研究中的应用,通过挖掘游记文本内容进行游客目的地感知形象、游客行为决策或是游客的满意度等方面的研究。
旅游偏好选择一般指消费者在旅游过程中因不同观念、不同状态、甚至不同文化观念而导致的差异化选择,这些选择可以包括目的地景点、游玩方式、美食等,也包括用户的兴趣点。随着景点中的美食正在成为用户选择旅游目的地的重要影响因素,对各旅行目的地的美食景点偏好选择进行挖掘,不仅有利于当地的特色美食品牌形象构建及推广,还有助于还有助于提高游客的旅游满意度、扩大城市的旅游影响力。
1.2 分析对象选择
因此,本文以“马蜂窝”网站为研究平台,以北京地区的在线美食评论内容为研究对象,研究用户对北京地区美食的偏好维度和偏好程度,以此获得北京游客对北京美食的综合形象特征。
马蜂窝是北京一家创建于2006年的旅游平台网站,给广大网友提供一个旅游交流的平台。截止2012年12月,蚂蜂窝旅行网用户覆盖数达到313百万人,居国内UGC型在线旅游网站榜首。截至2013年2月,蚂蜂窝旅行网注册用户量已经超过600万。而北京作为世界著名的旅游城市、中国文化中心和政治中心,其独特的融合风格与历史文化每年吸引了大批游客来此观光游览,并书写了大量评论,因此,选取该平台,该城市开展研究具有一定的代表性。
1.3 分析方法
在本文中,笔者主要采用内容分析法对来京游客发表的美食评论进行分析。首先是通过python爬虫采集游客分享的美食评论,然后进行深层次的文本分析,包括关键词提取,以及文章内容LDA主题模型分析。

二、数据采集与预处理
2.1 研究样本数据选取
“马蜂窝” 旅行网作为国内目前领先的自由行服务平台,其景点、餐饮等评论信息均来自用户的真实体验与分享,是旅游社交平台的领导者之一,因此本文选定“马蜂窝”中的北京美食评论作为本研究的样本数据。
首先,编写python爬虫代码,使用爬虫采集了来自马蜂窝城市页-北京,美食下的所有的所有餐饮店铺链接,并爬取各个店铺的信息,及该页面的所有评论数,数据采集的时间区间为2018.1.1~2018.7.15,采集的字段为店铺名称、店铺位置、店铺评分、店铺评论内容,共计204家餐饮店铺信息,以及5587篇评论内容。以及最终得到的数据如下图所示:

2.2 文本预处理
2.2.1 文本清理
1. 去除无用评论
根据对用户习惯的猜测,推测用户在评论文本时可能存在随意复制粘贴无关内容发表评论以换取积分,而显然这样评论对于本文来说是无用的评论,所以本文将将类评论数据人工删除。另外,由于马蜂窝的用户并非仅有中国人,有些外国游客也会使用马蜂窝来获取旅游咨询,因此,程序所抓取的在线旅游评论文本数据也包含了一定的英文评论文本,由于本文仅研究中文文本,因此该类文本属于杂志文本,应事先将其去除。
2. 去除重复评论
由于程序爬虫没有限制不允许爬取重复评论,以及没有设置剔除重复评论,导致了部分数据采集结果为重复数据。然而,这些重复的评论对于本文中的研究来说没有意义,甚至会对造成结果偏差,所以需要将重复数据剔除。
经过简单的去重处理后,本文最终随机抽取了204家餐饮店铺的5565条评论作为本文的最终测试集。
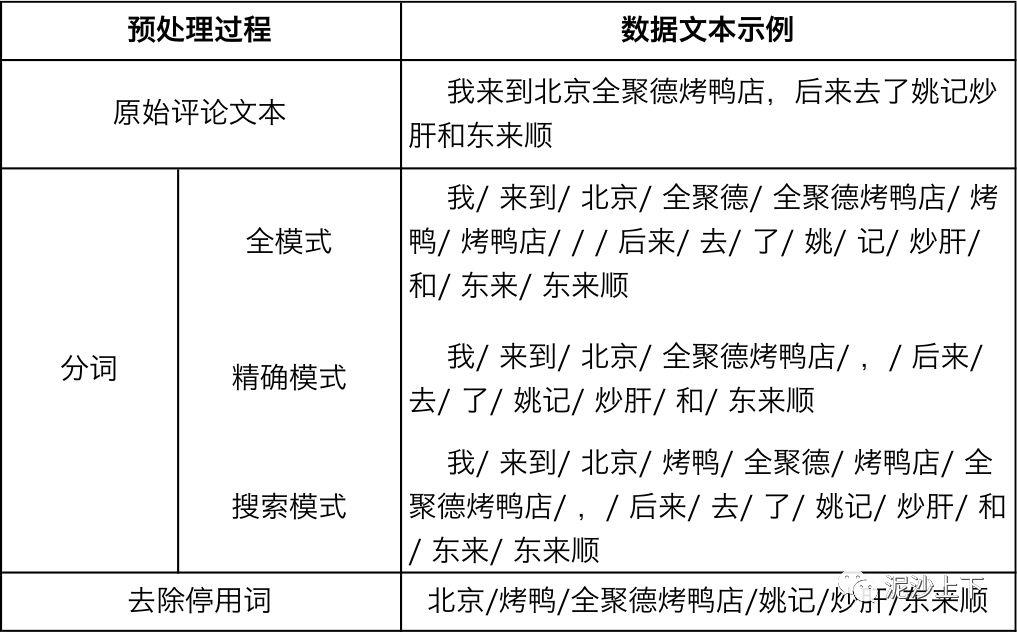
2.2.2 中文分词及停用词处理
1. 文本分词
中文文本由各种词汇组成,而这一些词汇并非像英语那样有间隔隔开,因此需要对中文文本进行分词处理。本文使用python jieba分词来对文本进行分词处理,它具有 3 类分词模式,有 3 类分词模式,即全模式、精确模式、搜索引擎模式。
精确模式:试图将句子最精确地切开,适合文本分析
全模式:把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义
搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
为了避免歧义和切出符合预期效果的词汇,本文采取的是精确(分词)模式。
2. 去停用词
这里的停用词包括以下三类,包括标点符号、特殊符号(包括表情)以及无意义的虚词。本文采用了哈工大的停用词库,并根据关键词提取效果,再更新了停用词并使用。

三、文本挖掘
3.1 关键词选取
通通过对所采集的游记文本内容进行分词和词频统计,得到大约五万个词。其中频次大于 100 的词汇有 1516 个,本文剔除了不足以分析的单个字和虚词以及地名,然后挑选出最能表现美食、餐饮环境和个人行为特征的代表性词汇。
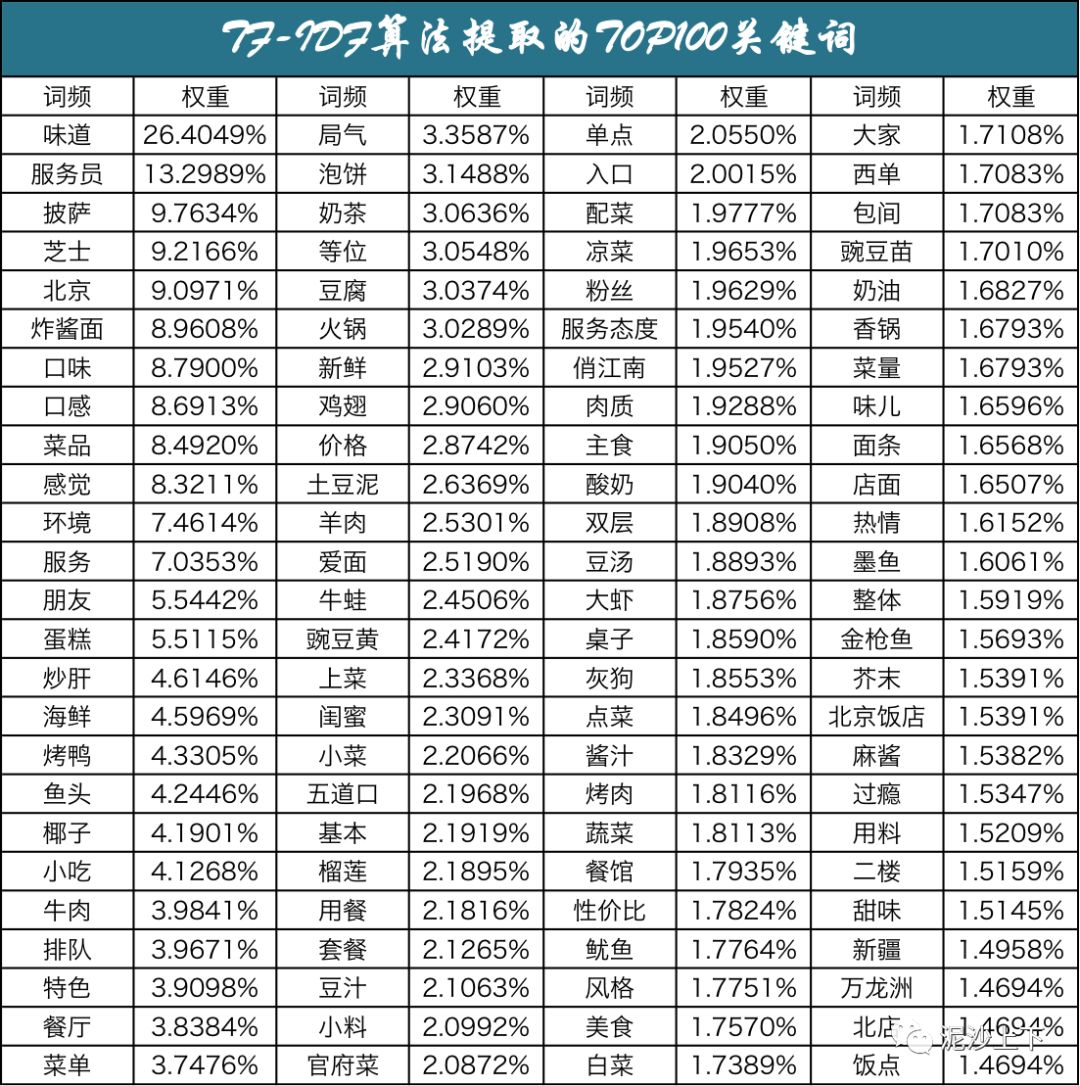
编写代码程序,对这类词汇采用TF-IDF (termfrequency–inverse document frequency) 的关键词提取方法:用以评估一字/词对于一个文件集或一个语料库中的其中一份文件的重要程度。在提取某段文本的关键信息时,关键词提取较词频统计更为可取,能提取出对某段文本具有重要意义的关键词。
本文在利用jieba分词在经预处理后的语料中抽取出的TOP100关键词,如下图所示。
本文选取 TOP500 的关键词来绘制关键词云。因为前20的关键词中,仅有炸酱面和烤鸭两款北京特色小吃,而烤鸭的形象比较具象,因此选取烤鸭味背景, 词云如下:
3.2 LDA主题模型分析
LDA是一种典型的无监督、基于统计学习的词袋模型,即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。主题模型通过分析文本中的词来发现文档中的主题、主题之间的联系方式和主题的发展,通过主题模型可以使我们组织和总结无法人工标注的海量电子文档。由于关键词获取游客评论偏好分类较为粗略,达不到全面的效果,因此本文再用LDA主题模型来发现样本数据中的潜在主题。
类似Kmeans聚类,LDA模型的主题数也需要人工来确定,在尝试了多个主题数之后,确定了最终的主题数为3,以完成LDA分析。尽管经过文本预处理后的样本数据比较纯净,通过每个主题下的“主题词”,已经可以辨析出若干主题,但是仍有1个主题下存在关键词杂糅的情况下,同样,本文剔除了不足以分析的单个字和虚词,然后挑选出最能表现美食、餐饮环境和个人行为特征的代表性词汇,然后获得了3个主题分类,如下表所示。
同样,本文剔除了不足以分析的单个字和虚词,然后挑选出最能表现美食、餐饮环境和个人行为特征的代表性词汇,然后获得了3个主题分类,如下表所示。
3.3 数据分析与结果
通过LDA模型分析可以看出,高频关键词被分为很多类。 现在将阈值选为3,参数为50进行划分,可以将游客美食选择偏好分为3个维度。
第一个维度包括 “高端”、“优惠”、“两人”、“露天”、“聚餐”等关键词,表示游客进行餐饮选择时伴侣人数、心理状态选择等选择敏感因素。
第二个维度包括“披萨”、“芝士”、 “炸酱面”、“烤鸭”等表示美食品种类型相关的关键词,以及“日料”、“泰式” 等美食地域风格的关键词。
第三个类包括 “服务”、“服务员”、“停车位”、“灯光”、“排队”等与餐厅接待设施相关的关键词, 以及“味道”、“口味”等表示美食综合评价的关键词。
综合高频关键词和 LDA 模型话题分析结果,本文对评论文本高频词所形成的维度进行梳理,最终得到包括就餐偏好、食物类型偏好、就餐环境偏好等五类。
1)就餐偏好
就餐偏好是影响消费者进行美食选择时的重要因素之一,通过话题关键词,可以看出来,它主要由出行人数、就餐目的、 期待就餐氛围和预算来决定。我们可以认为,大多数消费者在选择餐饮目的地前,会考量几人就餐,就餐目的是娱乐放松还 是正式会谈,就餐预期环境时高端还是比较休闲,也包括了人均预算。因此餐饮行业的商家在进行品牌塑造和宣传时,可以从这几方面发力给消费者留下印象。
2)食物类型偏好
食物类型偏好反映了来北京美食消费者的两方面特征,一方面:对北京传统美食特征的感知;第二方面,对都市美食特征的感知。很显然,对于来京的美食消费者来说,北京的传统美食是必须体验项,而炸酱面比烤鸭、爆肚更深入人心。披萨、 芝士、千层蛋糕等流行的快餐食品,则是许多游客匆忙行程中的选择。
3)就餐环境偏好
就餐环境偏好反映了在满足前两个维度后,游客对于消费水平的更高要求。在满足味蕾的第一条件下,美食消费者对服务员、服务态度、环境、停车位、风格、特色,是否需要等位等餐厅服务接待的水平有了更高、更加个性化的要求。
3.4 结论
本文主要是借助网络内容分析法,运用 python 爬虫、jieba 分词、TP-IDF 关键词提取以及LDA模型的话题分析,对马蜂窝的美食平罗数据进行了研究,从而获得了来北京旅游的美食消费者在进行美食选择时候的偏好信息和行为特征。
1. 两人同行,休闲娱乐导向为主
通过对评论中提及的就餐偏好、花费、出游人数以等基础信息的关键词进行分析发现,相对于其他人群的美食选择偏好,旅游中的消费选择人数较为有限,通常是两人同行,一般具有期待高性价比的特征,主要以休闲娱乐为目的,选择随机性比较强,随当下胃口而定,呈现出休闲旅游的特征。
2. 必吃:传统美食;离不开:潮流快餐;乐于尝鲜:特色打卡餐厅
进一步了解了来北京游客中的美食消费者的美食类型选择偏好特征:来京美食消费者对美食类型偏好鲜明,主要分成 3 类。
第一类:更倾向于具有北京传统风味的美食,其中以炸酱面、烤鸭、炒 肝、爆肚为代表;
第二类:更偏好新鲜潮流的快餐美食,其中以甜食为主,如奶茶、芝士、千层蛋糕;
第三类:偏好选择具有个性化和独特风格、特色单品的店铺,这类游客一般会选择创新菜系餐厅、私房菜馆、主题餐厅等具有鲜明个性化特色的餐饮目的地,这也反应了我国旅游人群的需求日益提高并个性化发展的特点。
3. 看重服务接待水平
研究还发现了,在满足了口味、味道、口感、正宗口味等味蕾满足后,消费者对用餐环境和接待设施、水平有一定的要求。美食消费者十分看重餐厅服务员的服务态度、餐厅环境与装潢、是否需要排队,是否有充足的停车位等餐厅服务接待水平。
因此,餐饮行业商家在进行品牌形象塑造的时候,有以下几个建议:
1. 可以从主打美食品种入手,发觉消费者习惯性选择的偏好类型
2. 从店铺的硬件设置和软件设置两方面发力,培训专业的服务人员,提高服务水平,设计装潢餐厅外观,并设计人性化且美观的用餐设施,提供交通和时间便利的用餐条件,给消费者打造更好的用餐环境和消费体验。
3.5 讨论
美食的网络评论中有大量照片和情感有关的词汇,但是本文未将其进行研究, 因此在今后的研究中需要对游客分享的图片和情感等信息进行深入的研究。
此外,本文仅选择了马蜂窝一个网站的数据作为样本数据,今后可以进行不同网站样本内容的对比研究。另外,在进行研究的过程中,还可以进行内容词向量与关联词分析,或者采用ATM模型与词聚类等方式进行更深入研究。
--------------
/六七月份过得有些苦涩,really multitasking,体力脑力压力多重压榨,哭唧唧的同时也坚持下来了,倍感幸运,接下来继续加油!/
以上是关于文本挖掘|如何透过UGC评论文本洞察用户的偏好?以马蜂窝北京食评为例的主要内容,如果未能解决你的问题,请参考以下文章
128在线民宿 UGC 数据挖掘实战--基于 LDA 模型的评论主题挖掘
[python]评论文本挖掘:找出兴趣相投的用户并作产品推荐