文本挖掘Python带你笑看江湖
Posted Python爱好者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本挖掘Python带你笑看江湖相关的知识,希望对你有一定的参考价值。


为了缅怀金大侠,我们使用Python对其15部小说展开分析,通过文本挖掘,为大家展示别样的江湖恩怨情仇。
数据获取
文本处理
分别将小说的人物(names)、功夫(kungfu)、派别(bangs)写入txt文件中,并与小说放在同一个文件夹中。
file='D:/CuteHand/jr_novels/names.txt'
#本地文件夹,根据需要修改
#可以使用os模块的添加路径
with open(file) as f:
# 去掉结尾的换行符
data = [line.strip() for line in
f.readlines()]
novels = data[::2]
names = data[1::2]
novel_names = {k: v.split() for k, v
in zip(novels, names)}
金庸小说充满恩怨情仇,其中,《倚天屠龙记》中张无忌一生遇到很多女人,如赵敏、周芷若、小昭、蛛儿,朱九真,杨不悔等,到底谁是女主角呢?我们来看下这几位美女在小说中分别出现的次数。
file='D:/CuteHand/jr_novels/倚天屠龙记.txt'
with open(file) as f:
data = f.read()
Actress=['赵敏','周芷若','小昭','蛛儿',
'朱九真','杨不悔']
for name in Actress:
print("%s"% name,data.count(name))
赵敏 1240
周芷若 819
小昭 352
蛛儿 231
朱九真 141
杨不悔 190
将这几位美女在小说中出现的次数进行可视化,可以更直观地看出哪位才是张无忌的归属:
#可视化,重点在于学习使用matplotlib库画图
#导入需要的包
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
%matplotlib inline
#画图正常显示中文
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 用来正常显示中文标签
mpl.rcParams['axes.unicode_minus']=False
# 用来正常显示负号
actress_data = {'赵敏':1240,'周芷若': 819,
'小昭': 352,'蛛儿': 231,
'朱九真': 141,'杨不悔': 190}
for a, b in actress_data.items():
plt.text(a, b + 0.05, '%.0f' % b,
ha='center', va='bottom', fontsize=12)
#ha 文字指定在柱体中间,
#va指定文字位置
#fontsize指定文字体大小
# 设置X轴Y轴数据,两者都可以是list或者tuple
x_axis = tuple(actress_data.keys())
y_axis = tuple(actress_data.values())
plt.bar(x_axis, y_axis, color='rgbyck')
# 如果不指定color,所有的柱体都会是一个颜色
#b: blue g: green r: red c: cyan
#m: magenta y: yellow k: black w: white
plt.xlabel("女角名") # 指定x轴描述信息
plt.ylabel("小说中出现次数") # 指定y轴描述信息
plt.title("谁是女主角?") # 指定图表描述信息
plt.ylim(0, 1400) # 指定Y轴的高度
plt.show()
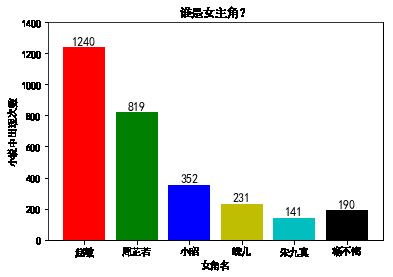
众所周知,张无忌最终和赵敏在一起了,而与周芷若之间很是坎坷…;小昭挺喜欢的角色,可惜被不可抗拒的外力给分开了;蛛儿,暂且说是女方单恋吧;朱九真 只是过客,不过也算是张无忌情窦初开喜欢的一个;杨不悔只能说是玩伴。
文本挖掘
接下来,通过分析小说人物的出场次数来判断小说的主要人物。
#继续挖掘下倚天屠龙记里面人物出现次数排名
namelist=[name.strip() for name in
novel_names['倚天屠龙记']]
namelist=''.join(namelist)
namelist=namelist.split('、')
count = []
num=10 #统计前10名
for name in namelist:
count.append([name, data.count(name)])
count.sort(key=lambda x: x[1])
_, ax = plt.subplots()
numbers = [x[1] for x in count[-num:]]
names = [x[0] for x in count[-num:]]
ax.barh(range(num), numbers, align='center')
ax.set_title('倚天屠龙记', fontsize=14)
ax.set_yticks(range(num))
ax.set_yticklabels(names, fontsize=10)
plt.show()
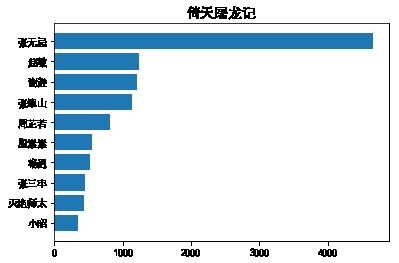
网上收集了下金庸小说的功夫和门派种类,分别写入kungfu.txt和bangs.txt中,其中武功246种,门派120个。
#加入功夫和门派数据
file='D:/CuteHand/jr_novels/'
with open(file+"kungfu.txt") as f:
kungfu_names = [line.strip()
for line in f.readlines()]
with open(file+"bangs.txt") as f:
bang_names = [line.strip()
for line in f.readlines()]
#编写文本挖掘可视化函数
#寻找小说出现最多的十大人物
def find_main_characters(novel):
file='D:/CuteHand/jr_novels/'
with open(file+'names.txt') as f:
df = [line.strip() for
line in f.readlines()]
novels = df[::2]
names = df[1::2]
novel_names = {k: v.split() for
k, v in zip(novels, names)}
with open(file+'{}.txt'.format(novel)) as f:
data = f.read()
count = []
namelist=[name.strip() for name
in novel_names[novel]]
namelist=''.join(namelist)
namelist=namelist.split('、')
for name in namelist:
count.append([name, data.count(name)])
count.sort(key=lambda x: x[1])
_, ax = plt.subplots()
num=10
numbers = [x[1] for x in count[-num:]]
names = [x[0] for x in count[-num:]]
ax.barh(range(num), numbers, align='center')
ax.set_title(novel+"出现最多的十大人物",
fontsize=16)
ax.set_yticks(range(num))
ax.set_yticklabels(names, fontsize=14)
#寻找小说出现最多的十大武功
def kungfu(novel):
file='D:/CuteHand/jr_novels/'
with open(file+'{}.txt'.format(novel)) as f:
df = f.read()
namelist=kungfu_names
count = []
num=10 #统计前10名
for name in namelist:
count.append([name, df.count(name)])
count.sort(key=lambda x: x[1])
_, ax = plt.subplots()
numbers = [x[1] for x in count[-num:]]
names = [x[0] for x in count[-num:]]
ax.barh(range(num), numbers, align='center')
ax.set_title(novel+"出现最多的十大武功",
fontsize=16)
ax.set_yticks(range(num))
ax.set_yticklabels(names, fontsize=14)
#寻找小说出现最多的十大门派
def bang(novel):
file='D:/CuteHand/jr_novels/'
with open(file+'{}.txt'.format(novel)) as f:
df = f.read()
namelist=bang_names
count = []
num=10 #统计前10名
for name in namelist:
count.append([name, df.count(name)])
count.sort(key=lambda x: x[1])
_, ax = plt.subplots()
numbers = [x[1] for x in count[-num:]]
names = [x[0] for x in count[-num:]]
ax.barh(range(num), numbers, align='center')
ax.set_title(novel+"出现最多的十大门派",
fontsize=16)
ax.set_yticks(range(num))
ax.set_yticklabels(names, fontsize=14)
#将三个函数合成一个主函数
def main(novel):
find_main_characters(novel)
bang(novel)
kungfu(novel)
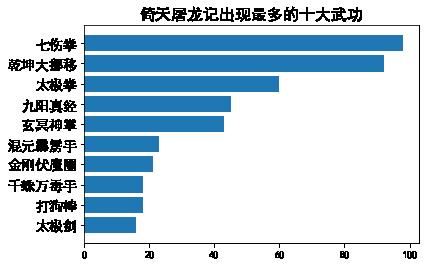
main('倚天屠龙记')
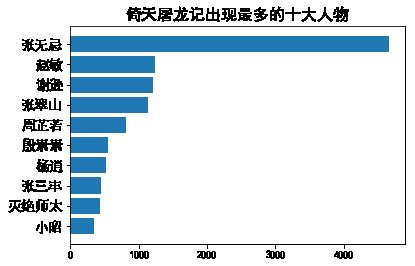
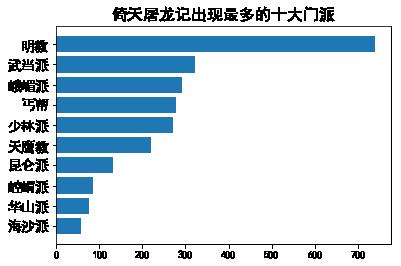
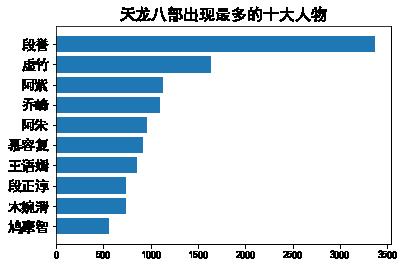
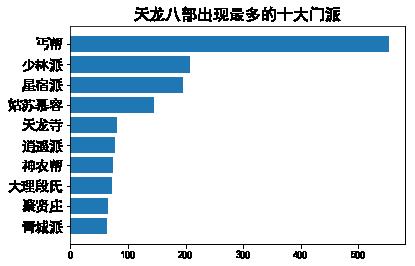
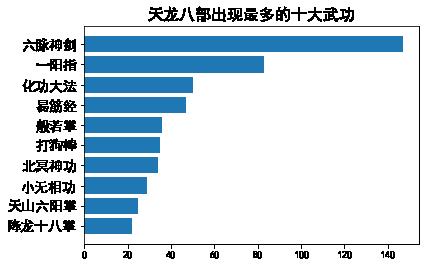
main('天龙八部')
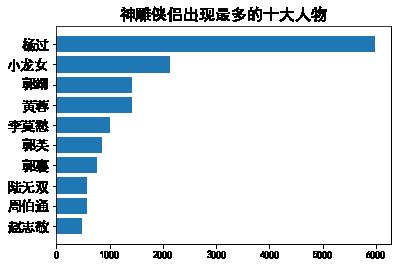
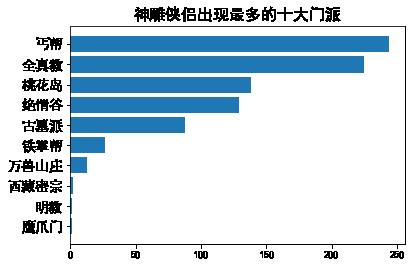
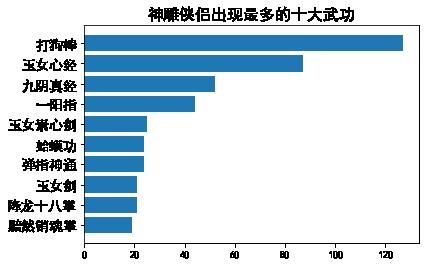
main('神雕侠侣')
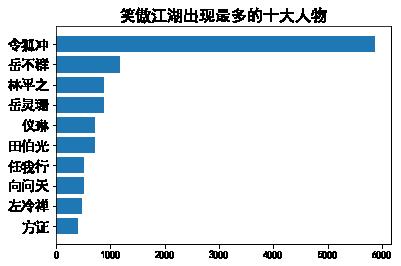
main('笑傲江湖')
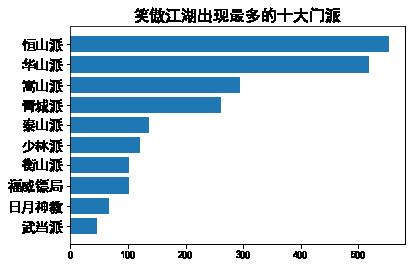
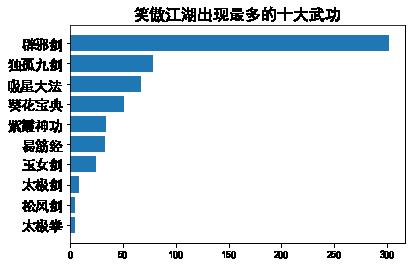
寻找人物关系
使用gensim和jieba包对文本做进一步挖掘,寻找人物之间的关系。一般要先安装相应的包,只要在Anaconda Prompt上输入pip install gensim和pip install jieba进行安装即可。
import gensim
import warnings
warnings.filterwarnings(action='ignore',
category=UserWarning,module='gensim')
warnings.filterwarnings(action='ignore',
category=FutureWarning,module='gensim')
import jieba
for _, names in novel_names.items():
for name in names:
jieba.add_word(name)
file='D:/CuteHand/jr_novels/'
with open(file+"kungfu.txt") as f:
kungfu_names = [line.strip()
for line in f.readlines()]
with open(file+"bangs.txt") as f:
bang_names = [line.strip()
for line in f.readlines()]
for name in kungfu_names:
jieba.add_word(name)
for name in bang_names:
jieba.add_word(name)
books = ['天龙八部','鹿鼎记','神雕侠侣','笑傲江湖',
'碧血剑','倚天屠龙记','飞狐外传','书剑恩仇录',
'侠客行','鸳鸯刀','白马啸西风','雪山飞狐']
sentences = []
for novel in books:
print ("处理:{}".format(novel))
with open(file+'{}.txt'.format(novel)) as f:
data = [line.strip()
for line in f.readlines()
if line.strip()]
for line in data:
words = list(jieba.cut(line))
sentences.append(words)
model = gensim.models.Word2Vec(sentences,
size=100,window=5, min_count=5, workers=4)
首先,来看下《倚天屠龙记》里张无忌与哪位女角的关系最紧密。
Actress=['赵敏','周芷若','小昭','蛛儿',
'朱九真','杨不悔']
for a in Actress:
print("张无忌与%s的相关度" % a,model.
wv.similarity('张无忌',a))
结果如下:
张无忌与赵敏的相关度 0.7922112
张无忌与周芷若的相关度 0.7983359
张无忌与小昭的相关度 0.60103273
张无忌与蛛儿的相关度 0.7526051
张无忌与朱九真的相关度 0.5569755
张无忌与杨不悔的相关度 0.5574214
从文本挖掘上看,张无忌似乎与周芷若“关系”更加紧密。不过,周芷若与赵敏的相关度非常接近。
其次,运用12部小说(其中,射雕英雄传、越女剑和连城诀可能存在非法字符,读不出来)交叉判断人物之间的关系。
def find_relationship(a, b, c):
"""
返回 d
a与b的关系,跟c与d的关系一样
"""
d, _ = model.wv.most_similar([c, b], [a])[0]
print ("给定“{}”与“{}”,“{}”和“{}”有类似的关系".
format(a, b, c, d))
find_relationship('小龙女','杨过' ,'黄蓉')
输出结果(Interesting!):
给定“小龙女”与“杨过”,“黄蓉”和“郭襄”有类似的关系
词云
通过对小说文本中出现频率较高的“关键词”予以视觉上的突出,形成“关键词云层”或“关键词渲染”,过滤掉大量的文本信息,大家可以试着通过关键词来自行串起故事的梗概和判断人物的关系。
#引入需要的包
import jieba
import jieba.analyse
import numpy as np
import codecs
import pandas as pd
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
#读入《倚天屠龙记》文本内容
text=codecs.open('D:/CuteHand/jr_novels/倚天屠龙记.txt',
'rb','gbk').read()
tags=jieba.analyse.extract_tags(text,topK=100,
withWeight=True)
tf=dict((a[0],a[1]) for a in tags)
#识别中文文本
wc=WordCloud(font_path='C:WindowsFontsSTZHONGS.TTF')
wc=wc.generate_from_frequencies(tf)
plt.figure(num=None,figsize=(12,10),facecolor='w',edgecolor='k')
plt.imshow(wc)
plt.axis('off')
plt.show()

生成特定形状的词云
backgroud_Image = plt.imread('D:/CuteHand/jr_novels/地图.jpg')
#可以自己找适合的图片做背景,最后是背景白色
wc = WordCloud(
background_color='white',
# 设置背景颜色
mask=backgroud_Image,
# 设置背景图片
font_path='C:WindowsFontsSTZHONGS.TTF',
# 若是有中文的话,这句代码必须添加
max_words=2000, # 设置最大现实的字数
stopwords=STOPWORDS,# 设置停用词
max_font_size=150,# 设置字体最大值
random_state=30
# 设置有多少种随机生成状态,即有多少种配色方案
)
wc.generate_from_frequencies(tf)
#img_colors = ImageColorGenerator(backgroud_Image)
#字体颜色为背景图片的颜色
#wc.recolor(color_func=img_colors)
plt.figure(num=None,figsize(12,10),
facecolor='w',edgecolor='k')
plt.imshow(wc)
# 是否显示x轴、y轴下标
plt.axis('off')
plt.show()

将上述过程包装成函数,方便批量处理
def jr_cloud(novel,file):
import jieba
import jieba.analyse
import numpy as np
import codecs
import pandas as pd
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
text=codecs.open(file+'{}.txt'.format(novel),
'rb','gbk').read()
tags=jieba.analyse.extract_tags(text,topK=50,withWeight=True)
tf=dict((a[0],a[1]) for a in tags)
wc=WordCloud(font_path='c:windowsontssimsun.ttc',
background_color='white')
wc=wc.generate_from_frequencies(tf)
plt.figure(num=None,figsize=(12,10),
facecolor='w',edgecolor='k')
plt.title(novel,fontsize=18)
plt.imshow(wc)
plt.axis('off')
plt.show()
file='D:/CuteHand/jr_novels/'
novels = ['天龙八部','鹿鼎记','神雕侠侣','笑傲江湖',
'碧血剑','倚天屠龙记','飞狐外传','书剑恩仇录',
'侠客行','鸳鸯刀','白马啸西风','雪山飞狐']
jr_cloud(novels[0],file)

#鹿鼎记词云
jr_cloud(novels[1],file)

#笑傲江湖词云
jr_cloud(novels[3],file)

人物关系网络分析
最后运用网络分析法,将小说中的人物关系用图形展示出来。
import networkx as nx
import matplotlib.pyplot as plt
import jieba
import codecs
import jieba.posseg as pseg
names = {}
# 姓名字典
relationships = {}
# 关系字典
lineNames = []
# 每段内人物关系
# count names
jieba.load_userdict(novel_names['倚天屠龙记'])
with codecs.open("D:/CuteHand/jr_novels/
倚天屠龙记.txt", "r") as f:
for line in f.readlines():
poss = pseg.cut(line)
# 分词并返回该词词性
lineNames.append([])
# 为新读入的一段添加人物名称列表
for w in poss:
if w.flag != "nr" or len(w.word) < 2:
continue
# 当分词长度小于2或该词词性不为nr时认为该词不为人名
lineNames[-1].append(w.word)
# 为当前段的环境增加一个人物
if names.get(w.word) is None:
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1
# 该人物出现次数加 1
# explore relationships
for line in lineNames:
# 对于每一段
for name1 in line:
for name2 in line:
# 每段中的任意两个人
if name1 == name2:
continue
if relationships[name1].get(name2) is None:
# 若两人尚未同时出现则新建项
relationships[name1][name2]= 1
else:
relationships[name1][name2] =
relationships[name1][name2]+ 1
# 两人共同出现次数加 1
with codecs.open("D:/CuteHand/jr_novels/person_edge.txt",
"a+", "utf-8") as f:
for name, edges in relationships.items():
for v, w in edges.items():
if w >500:
f.write(name + " " + v + "
" + str(w) + " ")
a = []
f = open('D:/CuteHand/jr_novels/person_edge.txt',
'r',encoding='utf-8')
line = f.readline()
while line:
a.append(line.split())
#保存文件是以空格分离的
line = f.readline()
f.close()
#画图
G = nx.Graph()
G.add_weighted_edges_from(a)
nx.draw(G,with_labels=True,font_size=9,
node_size=800,node_color='r')
plt.show()
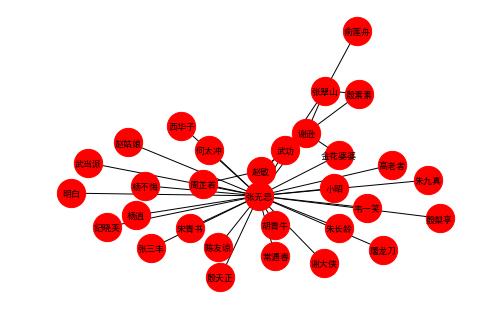

Python的爱好者社区历史文章大合集:
小编的转行入职数据科学(数据分析挖掘/机器学习方向)【最新免费】
小编的Python的入门免费视频课程!
小编的Python的快速上手matplotlib可视化库!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告扩展制作免费学习视频。
玩转大数据分析!Spark2.X + Python精华实战课程免费学习视频。
以上是关于文本挖掘Python带你笑看江湖的主要内容,如果未能解决你的问题,请参考以下文章