电力大数据应用文本挖掘技术开展客户投诉原因自动分类
Posted 朗新研究院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了电力大数据应用文本挖掘技术开展客户投诉原因自动分类相关的知识,希望对你有一定的参考价值。
以客户为中心,持续提升优质服务水平是电力企业服务转型的深刻内涵。本文以用户投诉为切入口,运用文本挖掘技术构建机器学习模型,将投诉工单由定性分析转为定量分析,实现客户投诉关键原因的自动分类,进而制定精确改善策略,优化用户体验,提升服务效率。
【名词解释】文本挖掘是对文本进行分析处理,将其转化为结构化数据,并从中提取有价值信息的计算机技术。文本挖掘,首先对文本做分词的基础上抽取特征,将文本数据转化为可供分析的结构化数据,然后利用分类、聚类、关联分析等技术实现相应的目标。
电力企业现有的客户服务工单分类较为笼统,导致客服人员在进行工单跟踪处理时很难把握客户投诉的关键原因,既影响工作效率,又影响客户满意度。
1、现有投诉工单分类较为笼统
当前针对投诉工单分类,投诉类别的划分相对比较笼统,如:电力施工人员服务规范类投诉、抄催人员服务规范类投诉,但是,客户具体投诉的原因到底是什么?电力施工人员如何服务不规范?仅仅根据现有的工单投诉类别,难以识别和获取。
2、人工挖掘投诉关键原因效率低下
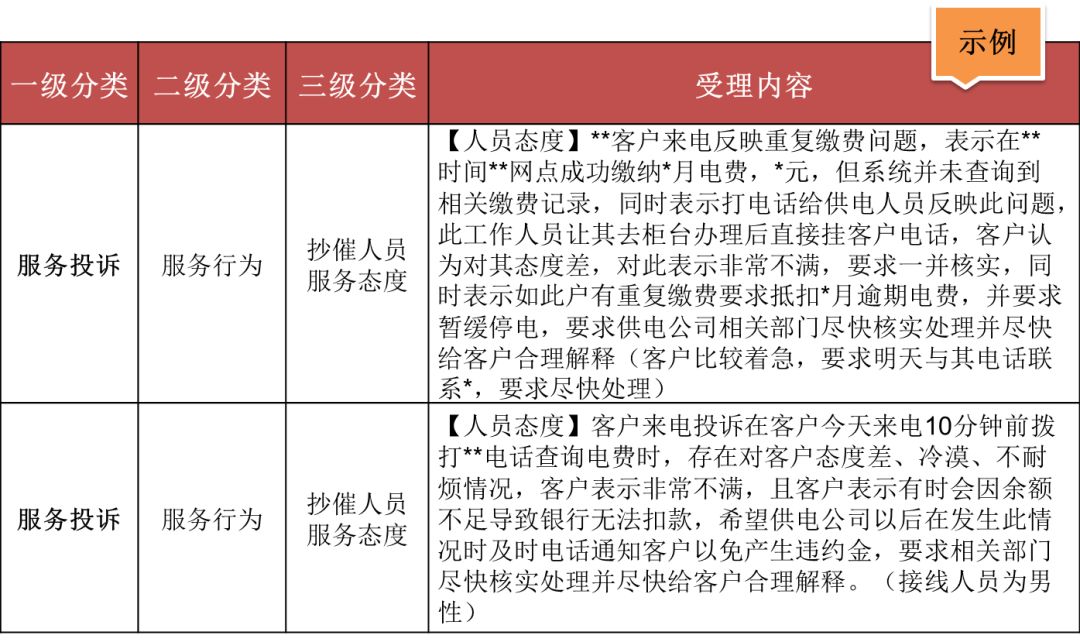
在投诉工单受理中,其实已经详细的记录了用户投诉的关键原因,由于缺乏统一规范的记录标准,客服人员难以直接对受理内容进行汇总分析。当前,针对用户投诉关键原因的分析,都是由人工根据投诉工单的受理内容逐一归纳,再对归纳的原因进行专项的统计及分析,进而制定专项服务策略。受理内容繁杂、投诉工单数量大并且人工分类受主观性影响等,致使人工挖掘投诉关键原因效率低下,且结论归纳不能保持一致。具体投诉工单受理记录如下表:
表1 投诉工单受理记录
下文通过某省居民用户的投诉工单为例,演示如何运用文本分类与机器学习技术,实现用户投诉原因的自动化分类。如下图投诉工单原因自动分类总体建模思路所示,以下主要从大数据建模和模型自动化两个角度展开描述。
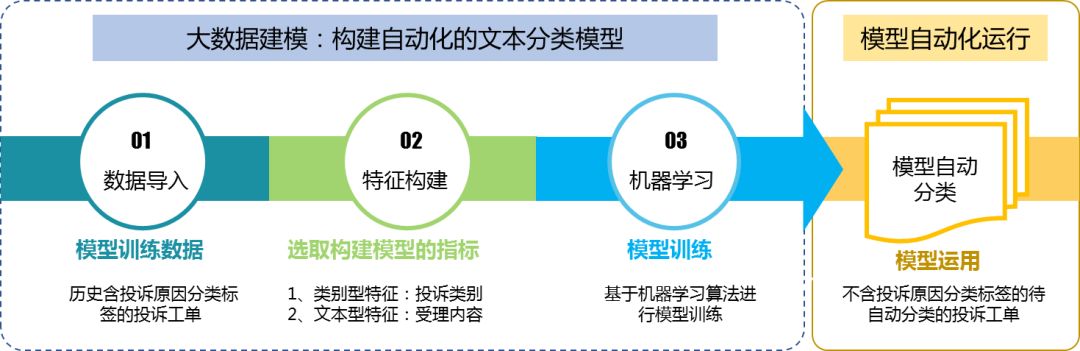 图1 投诉工单原因自动分类总体建模思路
图1 投诉工单原因自动分类总体建模思路
1、大数据建模
通过收集历史工单数据,应用文本分词与机器学习算法等技术开展模型训练,形成自动化的文本分类模型。具体过程如下:
任何模型都需要数据作为支撑,构建投诉原因的自动分类模型时,需要准备历史投诉工单作为模型的训练数据。本案例采用7000多条的投诉工单作为本次模型构建的研究数据,并对7000多条投诉工单以人工方式打上对应的投诉关键原因标签。
注:本案例标签类别是根据历史近2年投诉工单,归纳了113条客户投诉背后的关键原因并对应的设置唯一的原因编码而得。
分析投诉工单,确认与用户投诉关键原因相关的指标为模型训练的因变量并做相应的处理:投诉类别指标(一级分类、二级分类、三级分类),及投诉工单的受理内容,处理步骤如下:
文本分词:运用字符匹配的方法对工单的受理内容进行分词;
构建向量空间模型:构建一个向量空间,将受理内容分词后的结果放入同一空间中;
特征选择与表示:运用TFIDF方法,将空间模型里的文本向量用数字形式表示(类似于类别数据的编码),文本数据的每个特征均对应一个TFIDF值,TFIDF值越大表示该特征对分类所起的作用越大。TFIDF方法的核心思想是文本数据中的某个特征出现的频率较高,但出现过该特征的文本较少,则认为该特征具有很好的类别区分能力;
特征降维:将所有特征的TFIDF值从大到小进行排序,选取前n个TFIDF值较大的特征来控制词特征的数量(特征的TFIDF值越大,表示该特征对分类所起的作用越大),对比不同特征条件下模型的准确率(f1_score(micro))、模型运行速度选取最优的特征,以此达到特征降维的目的。
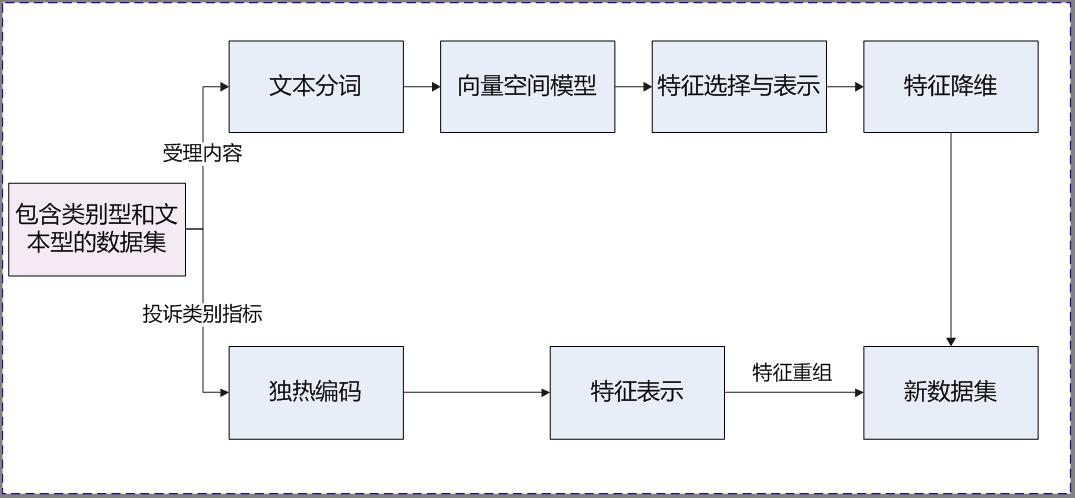
图2 特征处理的整体流程
注:在本案例当中,对投诉内容进行特征降维非常关键。文本分词后,没有特征降维也可以直接进行文本分类。但是,如果不做降维,分词后的向量空间特征维度可以达到上万甚至上百万,会严重影响模型速度及模型效果。本案例在对投诉内容进行分类的过程中,通过TFIDF方法进行特征降维,一方面排除了不好的特征词对模型结果的干扰,另一方面提高了模型的运行效率。
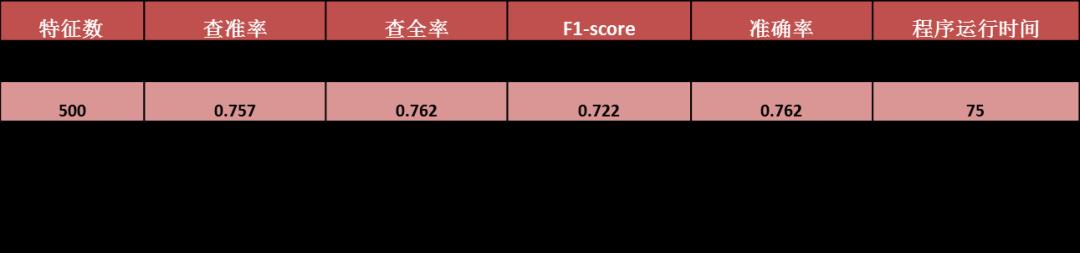
本案例建模中文本分词的初始特征有12000个左右,通过TFIDF方法进行特征降维,分别选择100,500,1000,2000,3000个特征进行模型效果分析。并通过查准率,查全率,F1-score(查准率和查全率的调和平均数),准确率,程序运行时间5个指标评估不同特征条件下模型的准确率运行效果,发现特征数在500个的时候,模型的准确率达到了最优,且程序运行时间也相对比较短。
表2 特征模型效果分析
用于文本分类的算法有很多,如传统机器学习算法(线性支持向量机、随机森林、XGB、朴素贝叶斯)、深度学习(cnn、fasttext)等。在确认完模型的特征指标后,需要进行算法选择,并根据准确率precision、召回率recall、评分f1_score(micro、macro)、模型运行时效等指标对各机器学习算法的优劣进行评价,确定最优模型。由于文本分类类别高达100多类,本次分类不能只选用传统的准确率高低为模型优劣的评价标准,还需用评分f1_score(micro、macro)指标做为辅助判断模型优劣的评价标准。
图3 建模探索过程
2、模型自动化运行
通过设置定期提取工单数据的系统任务,并调用已经构建好的分类模型,可以实现待分类投诉工单的原因自动化分类。由于目前模型的命中率为76%,因此模型尚未达到完全自动化。模型输出结果后,仍需人工对模型结果进行简单的复核确认,以此确保投诉原因分类的准确性。
运用自动分类技术替代传统人工分类技术,可以有效的提高工作效率,有着现实积极意义:
首先,工作时间缩短。运用自动分类技术后,一方面仅需对投诉原因分类进行复核,缩减投诉原因分类步骤;另一方面,对于一些原因分类模糊的投诉工单,可以直接参照模型自动归纳的原因分类,缩短人工抉择时间,并降低误判的概率。通过客户调研发现,以传统人工方式进行工单分类的平均耗时约为30秒/单;应用自动分类技术以后,绝大部分工单已通过模型准确归类,在此基础上再由人工对工单分类进行复核,效率将大大提升,预计核查一件工单的平均耗时约为6秒。以处理投诉工单10000单为例:通过自动分类技术仅需1005分钟【模型运行时间5分钟,人工复核1000分钟(0.1分钟/单)】,通过传统人工方式分类需要5000分钟(0.5分钟/单),运用自动分类技术则每个月可节约3995分钟,相当于节约8人/天工作量(1个员工1天工作时长为480分钟)。
其次,分类标准制式化。人工分类时,存在一定的人为主观性,而自动分类技术后采用统一的分类规则,可以有效规避多人归纳标准不统一的问题。
1、现有模型的命中率仍有提升空间
现有模型的命中率为76%,可以尝试在样本、算法、词库3个方面对模型进行优化。样本优化方面,随着模型识别工作的开展,带标签的投诉样本将逐步增加,随着训练集的不断扩大,模型的识别能力将逐步增强;算法优化方面,目前深度学习与传统机器的学习的算法效果相近,随着训练集的扩大,可以选择更多的深度学习算法进行模型优化;词库优化方面,目前文本分类采用的是搜狗词库,该词库不能完全识别电力营销系统的专业术语,因此可以基于业务需求构建电力行业专业词库,提高分词的准确率。
2、文本挖掘技术的应用拓展
本案例结合文本挖掘技术,初步实现了基于投诉工单中的非结构化文本数据及类别型数据的自动分类应用,帮助客服人员快速挖掘用户投诉背后的关键原因。文本挖掘技术的应用方向非常广泛,可以应用在各场景下用户反馈至系统中的文本信息的自动归类(如意见单的意见内容信息),帮助客户快速有效分析文本信息,检索文本内容的关键信息,归纳文本信息的类别;同时,可以进一步运用文本挖掘技术对各类文本信息进行情感评分,结合文本分类结果,实现个性化的文本信息标签管理;还可以直接对用户行为信息进行文本分类应用,打破以往只能用结构化数据记录用户行为进行分析的壁垒。
【结语】大数据时代,数据已经成为重要的生产因素,面对形形色色的数据,非结构化的文本信息蕴含着巨大的信息价值。我们将持续关注电力大数据的研究与应用,欢迎各位学者和同行交流切磋!
【文/陈曼芝、郭富磊等,大数据业务部】
注:文章仅代表作者观点,欢迎转发和评论。转发请标注来源,谢谢!
【相关阅读】
以上是关于电力大数据应用文本挖掘技术开展客户投诉原因自动分类的主要内容,如果未能解决你的问题,请参考以下文章