干货丨文本挖掘二三式
Posted 上海新金融风险实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货丨文本挖掘二三式相关的知识,希望对你有一定的参考价值。
风控说 由NFRL实验室出品
来源:Zrobot
第一式:文本挖掘是什么
随着信息技术与互联网的发展,可利用的数据与信息越来越多地在互联网中产生,并以数字化的形式存储。Web中99%的可分析信息都是以文本形式存在的,一些机构内90%的信息也是以文本形式存在的。社交媒体的兴起让互联网的信息更加丰富,不仅有一般媒体的新闻、企业的信息还有用户产生的内容,其中包括大量的评论信息。对这些文本信息进行挖掘具有非常重要的意义,可以用于客户反馈分析、品牌声誉分析、信息预测等方面。
文本挖掘是指从大量文本数据中发现知识,抽取隐含的、未知的、潜在有用的模式的过程。
文本挖掘是数据挖掘中的一个研究领域,只是数据挖掘的研究对象大多是结构化的数据,而文本挖掘的研究对象是非结构化或半结构化的信息。文本挖掘是一个多学科混杂的领域,包括数据挖掘技术、信息抽取、信息检索、机器学习、自然语言处理、计算语言学、统计数据分析、线性几何、概率理论、图论等。
第二式:文本挖掘怎么挖
使用机器学习的方法进行文本挖掘,需要将文本分为训练集和测试集两部分,使用训练集数据进行训练和评估,如果模型评估效果较好,那么使用测试集数据进行测试。主要的处理过程有:文本预处理、特征选择、特征加权、模型算法(模式发现)、性能评估等。
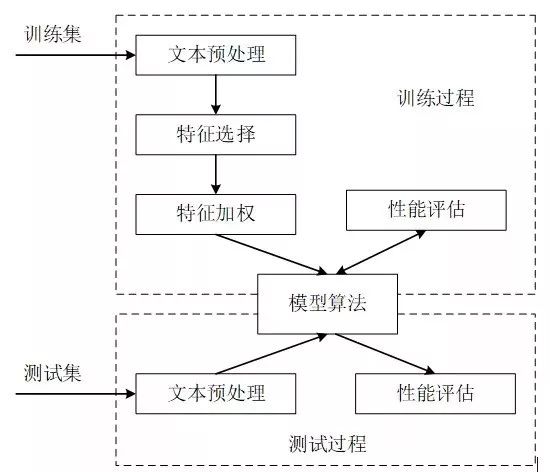
文本挖掘流程
1.文本预处理(Data Pre-processing)
由于处理的是非结构化的文本,计算机无法直接理解和处理,且文本中包含一些不需要的信息,因此第一步需要将文本数据进行预处理,包括分词(word segmentation)、去停用词(remove stopwords)等等。
1.分词
①分词概念:词语是组成文本的基本单位,分词是指将语句文本分割成词或词组并按照一定的规范重新组合词序列的过程。在英文中,单词之间以空格作为分隔符,而在中文中,语句没有形式上的分隔符,因此中文要比英文稍微复杂些。
②中文分词(Chinese word segmentation)的难点:歧义和未登录词识别
歧义是指同样的一句话,可能有两种或者更多的切分方法。主要的歧义有两种:交集型歧义和组合型歧义。例如:表面的,因为“表面”和“面的”都是词,那么这个短语就可以分成“表面”、“的”和“表”、“面的”,这种称为交集型歧义(交叉歧义)。由于没有人的知识去理解,计算机很难知道到底哪个方案正确。组合型歧义较交集型歧义则更加复杂,必须根据整个句子来判断。例如,在句子“这个门把手坏了”中,“把手”是个词,但在句子“请把手拿开”中,“把手”就不是一个词。
命名实体(人名、地名)、新词,专业术语称为未登录词,即在分词词典中没有收录,但又确实能称为词的那些词。最典型的是人名,人可以很容易理解,但要是让计算机去识别就比较困难了。
③中文分词的方法:目前中文分词算法主要有基于词典的分词、基于统计的分词和基于理解的分词三种。
基于词典的分词方法,是将文本切分后的一小段与一个词典里的词进行比较,如果存在,则划分为一个词。这种分词方法实现起来比较简单,但太依赖词典的规模,词典越大分词的正确率越高。词典可以自定义,对于拥有大量术语的某些特定领域,一般会倾向使用这种方法进行分词。但是这种分词方法不能很好地处理歧义问题,和新登录词识别的问题。
基于统计的分词方法的思想是,找出输入字符串的所有可能的切分结果,对每种切分结果利用能够反映语言特征的统计数据计算它的出现概率,然后从结果中选取概率最大的一种。这种方法的原理可以用“存在即合理”来解释。但是有时候也会有一些不切合实际的效果。基于统计的分词方法的好处是不需要词典,但也有一定局限性,对于长于二字的词的处理延伸,没有很有效的方法。
基于理解的中文分词方法,是让计算机模拟人对中文的理解,根据人的习惯,将句子进行切分。它的基本思想就是利用句法、语法的分析来处理中文分词中的歧义切分。这种方法需要拥有十分完善的语言知识体系,而汉语言本身结构复杂,并混杂方言和俗语等知识,因此这种分词方法仍然处于研究阶段。
④中文分词的工具:现在已经有比较成熟的分词工具,如ICTCLAS、IKAnalyzer、SCWS、结巴分词、庖丁解牛分词等等。目前比较流行的进行文本挖掘的软件是R语言和Python,如果使用R语言和Python进行文本数据处理和分析的话,有一些分词的包可以直接导入,如Jieba、Rwordseg等等。

语句分词结果示例
2.去停用词
对文本进行分词处理后发现,很多词语并不具有实际的含义,并且对后续文本挖掘产生非正面的影响,需要将这些词移除,以降低这些词对于文本挖掘的效果。如“啊”“是”“真的”等,这些词的词频往往很高,不但不能反映和区别主题,还会增大计算机处理的难度和准确度。将这些词移除的过程就是去除停用词(remove stop words)的过程。
去停用词通常使用两种方法,一种是基于统计的方法,另一种是基于停用词表的方法。前者一般需要计算每个词的词频,如果高于某个阙值或者低于某个阙值就将其删除。后者通过文本构建一个停用词表,可以人工构建,也可以基于统计的学习方式构建,然后再根据这个停用词表与分词得到的词语逐一进行匹配,若匹配得上,则将该词语删除,若匹配不上,则将该词语保留。

停用词示例
2.特征选择(Feature Selection)
分词并去除停用词之后,我们发现词语的数量仍然是非常多的,如果把这些词都作为特征来表示文本,那么模型的维数会非常的高,这将大大影响文本挖掘的效果,也会给计算机处理计算带来困难,而且这些特征并不一定都是必要的、有价值的,因此有必要去掉一些冗余,进行特征选择,即根据某种准则从原始特征中选择部分最有区分类别能力、最有效的特征,以降低特征空间维数。
目前常用的文本特征选择方法有:文档频率(Document Frequency ,DF)、信息增益(Information Gain,IG)、互信息(Mutual Information,MI)、χ2统计量(Chi-square Statistic,CHI)等。
进行特征选择之后,形成文档词频矩阵(Document Term Matrix,DTM)。即索引是篇章序号,列名称为经过特征选择之后的各个特征词,矩阵元素是该特征在该文档里出现的次数。
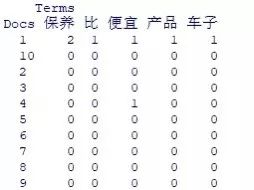
文档词频矩阵示例
注:“Docs”指文档,“Terms”指特征词。
自然语言文本另一个典型特征称为“特征稀疏”。在所有可能的特征中,只有很小百分比的特征会出现在所有单个文本里。也就是说,当文本用二值特征向量表示时,几乎所有向量的值为0,元组的维数是稀疏的,一些特征经常出现在少数文本中,这意味着模式的支持度非常低。
3.特征加权(Feature Weighting)
文本是一种计算机不能直接处理和计算的非结构化的数据,若想让计算机可以直接处理和计算,需要作一些形式上的转换才可以。对文本进行形式化的转换和表示,即文本表示。一般说来,文本表示有三种常用方式,分别是布尔模型(Boolean Model)、向量空间模型(Vector Space Model)和概率模型(Probabilistic Model)。在使用的过程中,我们需要考虑不同文本所具有的特点和想要达到的目标来选择文本表示方式。就目前使用情况而言,向量空间模型最具优势,也是使用最多的。
向量空间模型,它的核心思想是将一个文档转换为一组高维空间的特征向量,由这组特征向量构成文档的特征向量空间。向量空间模型把对文本内容的处理简化为向量空间中的向量运算,并且以空间上的相似度表达语义的相似度,直观易懂。当文档被表示为文档空间的向量,就可以通过计算向量之间的相似性来度量文档间的相似性。在这个模型中,每个文本被表示为高维空间中的一个向量d=(t1,t2,t3,....tn),其中tk是项,1≤k≤n。然后根据各项tk在文本中的重要性赋予一定的权重wk,文本d就可以被记为(t1:w1,t2:w2,....tn:wn)。图为一个向量空间模型,包括T1、T2、T3三个维度,D1表示在T1、T2、T3方向上分别2、3、5个单位长度,即D1=2T1+3T2+5T3,同理,D2=3T1+7T2+T3,D3=0T1+T2+2T3。
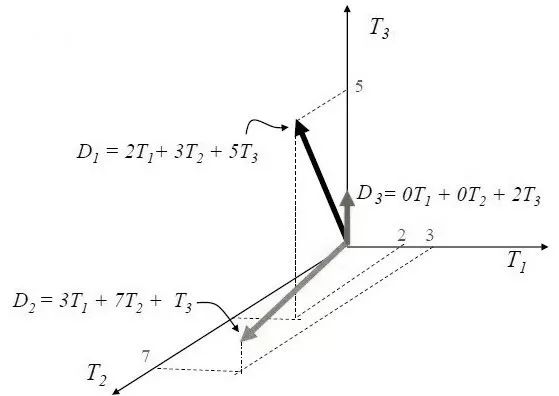
向量空间模型示例
空间向量模型有3种主要的权重表示方法,分别是:布尔权重、词频权重、TF-IDF权重。
(1)布尔权重
布尔权重是建立在集合论和布尔代数的基础之上,分别用1或0来表示某特征词在文档中出现或不出现的方法,也是最简单的权值计算方法。对于一篇文档而言,如果某特征词的权值为1,则证明该词出现在该文档之中,且出现次数至少为1次;如果该特征词的权值为0,则证明该词从未出现在该文档之中。其公式如下:
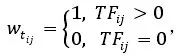
其中,Wtij表示特征词i在文档j中的权重,TFij表示特征词在文档中出现的次数。
这样的优点是效率很好,缺点是在文档中出现一次与出现百次的词语均标注权重为1,从而不能表示某特征词对于该文档的重要性程度。
(2)词频权重
词频(Term Frequency,TF),顾名思义,是将某特征词在文档中出现的频次作为权重,这是对布尔权重的一种改进。词频权重是使用比较多的一种权重方式,如云图就是基于词频权重绘制的。其公式如下:
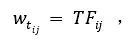
词频权重的优点是对布尔权重做了改进,使某个特征词对某篇文档的重要性得以显现;由于词频代表的是某个给定的词语在某篇文档中出现的次数,通过词频来标记该词的重要性,但是不可避免的是,由于不同的文档长度不尽相同,长文档倾向具有较高的词频,短文档倾向具有较低的词频,这使得用词频标注权重具有考虑不全面之处。
(3)TF-IDF权重
TF-IDF(Term Frequency–Inverse Document Frequency)权重是在词频权重的基础上进行的,该方法可以更为理性地评估某个词语对于不同文档的贡献程度。TF即为词频(Term Frequency),IDF是逆文档频率(Inverse Document Frequency),其计算方法为:用文档总数量除以含有该词语的文档数量,再将得到的商取对数从而得到最终的值。这样做的原因:一是为了突出某特征词对某篇文章中出现的频次越高,该词对该文档越重要;二是为了突出含有某特征词的文档数目越多,该特征词就越不重要。其公式如下:
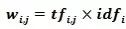
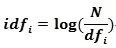
其中,表示 在文本 中的词频, 表示的逆文本频率,N 表示文本总数。
这种权重计算方法解决了不同长度的文档对于词语频数的影响,是目前最为常用的词语权重计算方法。但是它的效率显然不如前两种方法高。
4.模型算法(Algorithms)
对文本进行了一系列处理之后就可以利用计算机进行各种算法的机器学习,面向特定的应用目的进行模式发现。这些算法与数据挖掘的一般方法大致相通,包括文本分类、文本聚类、等等。涉及分类的可以使用的机器学习算法有朴素贝叶斯模型、KNN模型、支持向量机模型以及神经网络等,涉及聚类的可以使用基于划分的方法、基于层次的方法、基于密度的方法、基于网格的方法以及基于模型的方法等。
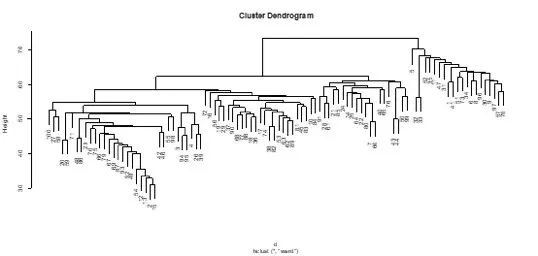
文本聚类结果示例
5.性能评估(Evaluation)
进行算法学习和挖掘后产生的结果不一定是理想的效果,完全可信的、有用的,需要利用已经定义好的评估指标对获取的知识或模式进行评价。如果评价结果符合要求,就存储该模式以备用户使用;否则返回到前面的某个环节重新调整和改进,然后再进行新一轮的发现。可以使用查全率、查准率、F1值进行评估。
查全率是衡量所有实际属于某个类别的文本中被分类器划分到该类别的比率,查全率越高表明分类器在该类上可能漏掉的分类越少,它体现系统分类的完备性。计算方法如下:

查准率是衡量所有被分类器划分到该类别的文本中正确文本的比率,查准率越高表明分类器在该类上出错的概率越小,它体现系统分类的准确程度。计算方法如下:

Fl标准即考虑了查全率,又考虑了查准率,将两者看作同等重要。计算方法如下:

第三式:文本挖掘怎么用
文本挖掘具有广泛的应用前景,它不仅可以用于企业有决策需求的业务部门,而且可以用于提供综合信息服务的网站。从企业角度来看,任何一个企业都不能再只关注企业内部的情况,必然要关心竞争对手、合作伙伴、市场变换、用户评价等企业外部环境,而文本挖掘是获取这些非结构化或半结构化信息的最好途径。
文本挖掘可以将文本挖掘技术应用到Web日志、Internet上的博客主页等。分析Web日志,可以得到客户感兴趣的信息以及客户是否有了新的信息需求,增强对最终用户的Internet的信息服务质量,改进Web服务器系统的性能;分析Internet上博客的主页,可以更全面地了解作者的研究方向等,将挖掘出来的知识与客户兴趣比较,可以为客户提供与之研究兴趣相近的信息资料。
文本挖掘可以为企业收集和分析数据,以识别出现的威胁或问题。跟踪新闻稿、专利公布、合并与收购活动可以帮助确认由于竞争对手、供应商、顾客或合作伙伴的策略变化而导致的潜在威胁。监控和分析新闻组和邮件列表中顾客张贴的内容和对呼叫中心的投诉可以帮助发现市场动态和品牌观念的趋势。
文本挖掘可以基于评论数据提供用户对于产品的感知和评价,进行客户反馈分析,一方面可以帮助用户做出购买决定,另一方面也可以帮助商家进行生产指导和决策支持。评论数据也可以从另一角度完善用户的个人基本属性、资产情况、兴趣偏好等,帮助企业更好地了解客户,并进行个性化推荐。对评论信息进行情感分析,可以挖掘出在网络上恶意辱骂、散播虚假广告、威胁公共安全等的恶意用户,从而维护干净健康的网络环境。除此之外,还可以根据评论数据创建新的维度,作为其他模型的辅助部分,来提升其他模型的模型效果。
参考书籍:
[1]Hinton, G.,et al.,Deep neural networks for acoustic modeling in speechrecognition: The shared views of four research groups. Signal ProcessingMagazine, IEEE,2012. 29(6): p. 82-97.
[2]Hu M Q and Liu B. Mining and summarizing customer reviews[C]. In Proceedings ofACM SIGKDD International Conference on Knowledge Discovery and Data Mining(KDD-2004). 2004. doi:10.1145/1014052.1014073
[3]Hu, Minqing, & Liu, Bing. 2004a. Mining and summarizing customer reviews.Pages 168 -177 of: Proceedings of KDD '04
[4]Kathleen T. Durant & Michael D. Smith. 2006. Mining SentimentClassification from Political Web Logs. Proceedings of WEBKDD '06
[5]Scikit-learn Tutorials.[EB/OL]. http://scikit-learn.org/dev/tutorial/index.html
[6]Serre,T.,et al.,Robust object recognition with cortex-like mechanisms. PatternAnalysis and Machine Intelligence, IEEE Transactions on, 2007. 29(3): p.411-426.
[7]Yue Zhang. Maximum Entropy Modeling Toolkit for Python and C++.[EB/OL].http://homepages.inf. ed.ac.uk/lzhang10/ maxent_toolkit.html
[8] 王仁武,蔚海燕,范并思.商业分析——商业数据的分析、挖掘和应用.上海:华东师范大学出版社.2014
[9] 李荣陆.文本分类及其相关技术研究[D].复旦大学,2005.
[10] 林少波.中文文档分类特征提取方法的研究与实现[D].重庆:重庆大学,2011.
[11] 文本特征提取. [EB/OL].http://blog.csdn.net/pipisorry/article/details/41957763
[12] 徐冰. 基于统计学习的文本情感分析关键技术研究 [D]. 2011.
[13] 姚天昉, 程希文, 徐飞玉等. 文本意见挖掘综述[J]. 中文信息学报, 2008, 22 (3): 71-80
[14] 翟剑锋.深度学习在自然语言处理中的应用[J].电脑编程技巧与维护,2013,18:74-76.
[15] 赵军, 许洪波, 黄萱菁等. 中文倾向性分析评测技术报告[R]. 北京: 中文信息学会, 2008.
[16] 自然语言处理——TF-IDF.[EB/OL].http://cpmarkchang.logdown.com/ posts/ 193915- natural- language-processing-tf-idf

有智慧 无边界
上海新金融风险实验室
关注并星标
欢迎投稿 欢迎联系我们
邮箱:contact@nfrl.tech
更多精彩内容
以上是关于干货丨文本挖掘二三式的主要内容,如果未能解决你的问题,请参考以下文章