文本挖掘-wordcloud主题模型与文本分类
Posted 淘数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本挖掘-wordcloud主题模型与文本分类相关的知识,希望对你有一定的参考价值。
本文主要介绍文本挖掘的常见方法,主要包括词频分析及wordcloud展现、主题模型、文本分类、分类评价等。分类主要包括无监督分类(系统聚类、KMeans、string kernals),有监督分类(knn、SVM)。
一、文本挖掘概念
将数据挖掘的成果用于分析以自然语言描述的文本,这种方法被称为文本挖掘(Text Mining)或文本知识发现(Knowledge Discovery in Text)。
文本挖掘主要过程:特征抽取、特征选择、文本分类、文本聚类、模型评价。
主题模型(Topic Mode)介绍
主题模型是专门抽象一组文档所表达 “主题” 的统计技术。
最早的模型是 probabilistic latent semantic indexing (PLSI),后来 Latent Dirichlet allocation
(LDA,潜在狄利克雷分配模型) 模型成为了最常见的主题模型,它可以认为是 PLSI 的泛化形式。LDA 主题模型涉及到贝叶斯理论、Dirichlet 分布、多项分布、图模型、变分推断、EM 算法、Gibbs 抽样等知识。
二、实例分析
0.数据预处理
数据来源于sougou实验室数据。
数据网址:http://download.labs.sogou.com/dl/sogoulabdown/SogouC.mini.20061102.tar.gz
文件结构
└─Sample
├─C000007 汽车
├─C000008 财经
├─C000010 IT
├─C000013 健康
├─C000014 体育
├─C000016 旅游
├─C000020 教育
├─C000022 招聘
├─C000023
└─C000024 军事
采用Python对数据进行预处理为train.csv文件,并把每个文件文本数据处理为1行。
1.读取资料库
setwd("d:\Testing\R\w12")
csv <- read.csv("train.csv",header=T, stringsAsFactors=F)
mystopwords<- unlist (read.table("StopWords.txt",stringsAsFactors=F))
2. 数据预处理(中文分词、stopword处理)
library(tm)
#移除数字
removeNumbers = function(x) { ret = gsub("[0-90123456789]","",x) }
#对词进行处理
3.wordcloud展示
library(wordcloud)
#不同文档wordcloud对比图
sample.tdm <- TermDocumentMatrix(corpus, control = list(wordLengths = c(2, Inf)))
tdm_matrix <- as.matrix(sample.tdm)
png(paste("sample_comparison",".png", sep = ""), width = 1500, height = 1500 )
comparison.cloud(tdm_matrix)
title(main = "sample comparision")
dev.off()

#按分类汇总wordcloud对比图
n <- nrow(csv)
zz1 = 1:n
cluster_matrix<-sapply(unique_type,function(type){apply(tdm_matrix[,zz1[csv$type==type]],1,sum)})
png(paste("sample_ cluster_comparison",".png", sep = ""), width = 800, height = 800 )
comparison.cloud(cluster_matrix)
title(main = "sample cluster comparision")
dev.off()
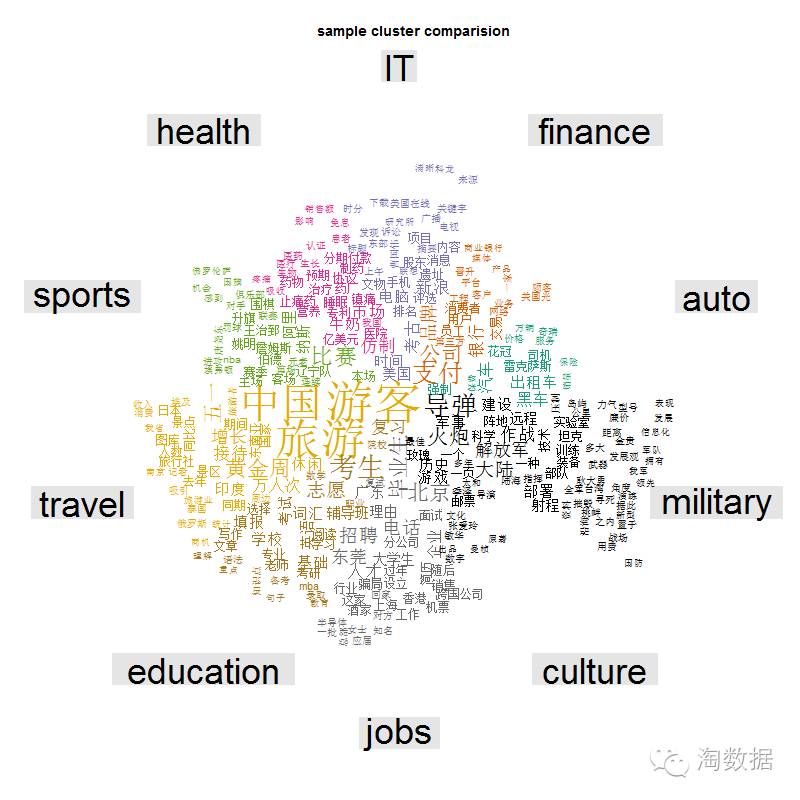
可以看出数据分布不均匀,culture、auto等数据很少。
#按各分类画wordcloud
sample.cloud <- function(cluster, maxwords = 100) {
words <- sample.words[which(csv$type==cluster)]
allwords <- unlist(words)
wordsfreq <- sort(table(allwords), decreasing = T)
wordsname <- names(wordsfreq)
png(paste("sample_", cluster, ".png", sep = ""), width = 600, height = 600 )
wordcloud(wordsname, wordsfreq, scale = c(6, 1.5), min.freq = 2, max.words = maxwords, colors = rainbow(100))
title(main = paste("cluster:", cluster))
dev.off()
}
lapply(unique_type,sample.cloud)# unique(csv$type)
#列出第一副和最后一幅图

4.主题模型分析
library(slam)
summary(col_sums(sample.dtm))
term_tfidf <- tapply(sample.dtm$v/row_sums( sample.dtm)[ sample.dtm$i], sample.dtm$j, mean)*
log2(nDocs( sample.dtm)/col_sums( sample.dtm > 0))
summary(term_tfidf)

sample.dtm <- sample.dtm[, term_tfidf >= 0.1]
sample.dtm <- sample.dtm[row_sums(sample.dtm) > 0,]

α估计严重小于默认值,这表明Dirichlet分布数据集中于部分数据,文档包括部分主题。
sapply(sample_TM, function(x) mean(apply(posterior(x)$topics,1, function(z) -sum(z*log(z)))))

数值越高说明主题分布更均匀
#最可能的主题文档
Topic <- topics(sample_TM[[“VEM”]], 1)
#每个Topc前5个Term
Terms <- terms(sample_TM[[“VEM”]], 5)
Terms[, 1:10]

从结果来看,与原有手工10大分类“汽车、财经、IT、健康、体育、旅游、教育、招聘、文化、军事”对比,可以发现旅游、军事等主题还比较明显,但总的效果不是很理想(可以和“按分类汇总wordcloud对比图”对比一下)。
5.文本分类-无监督分类,包括系统聚类、KMeans、string kernals。
sample_matrix = as.matrix(sample.dtm)
rownames(sample_matrix) <- csv$type
系统聚类
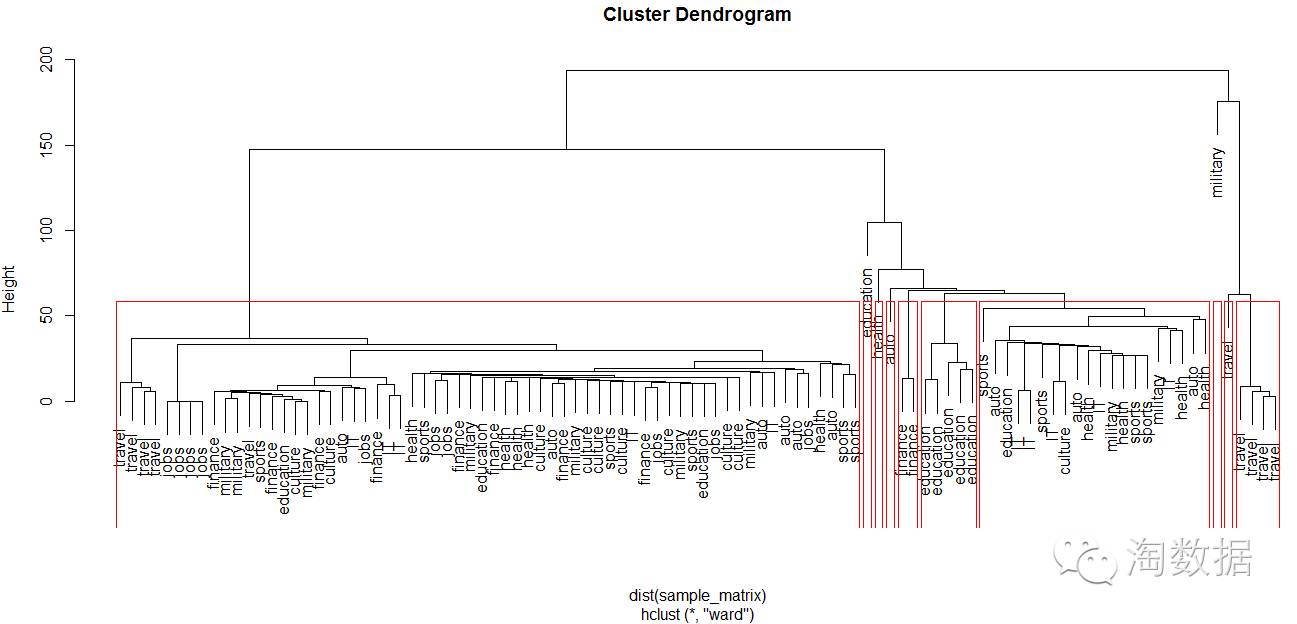 可见和主题模型得出结论相同,数据分布过于集中。说明数据集可能还不够具有代表性。
可见和主题模型得出结论相同,数据分布过于集中。说明数据集可能还不够具有代表性。
lKMeans分类
sample_KMeans <- kmeans(sample_matrix, k)
library(clue)
#计算最大共同分类率
cl_agreement(sample_KMeans, as.cl_partition(csv$type), "diag")
复制代码

分类效果比较差。
l string kernels
library("kernlab")
stringkern <- stringdot(type = "string")
stringC1 <- specc(corpus, 10, kernel=stringkern)
#查看统计效果
table("String Kernel"=stringC1, cluster = csv$type )
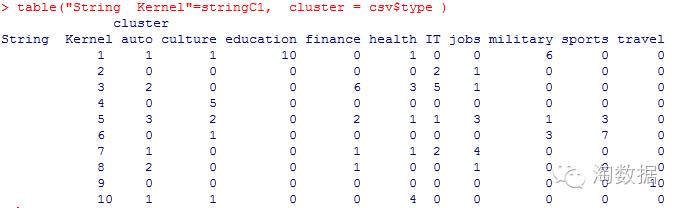
可以看出travel、education分类准确,auto、it、health等分类效果差。
6.文本分类-有监督分类,包括knn、SVM
把数据随机抽取90%作为学习集,剩下10%作为测试集。实际应用中应该进行交叉检验,这里简单起见,只进行一次抽取。
n <- nrow(csv)
set.seed(100)
zz1 <- 1:n
zz2 <- rep(1:k,ceiling(n/k))[1:n] #k <- length(unique(csv$type))
zz2 <- sample(zz2,n)
train <- sample_matrix[zz2<10,]
test <- sample_matrix[zz2==10,]
trainC1 <- as.factor(rownames(train))
l Knn分类
library(class)
sample_knnCl <- knn(train, test, trainC1)
trueC1 <- as.factor(rownames(test))
#查看预测结果
(nnTable <- table("1-NN" = sample_knnCl, sample = trueC1))

sum(diag(nnTable))/nrow(test)

看样样本集少预测效果是不好。
l SVM分类
rownames(train) <- NULL
train <- as.data.frame(train)
train$type <- trainC1
sample_ksvm <- ksvm(type~., data=train)
svmCl <- predict(sample_ksvm,test)
(svmTable <-table(SVM=svmCl, sample=trueC1))
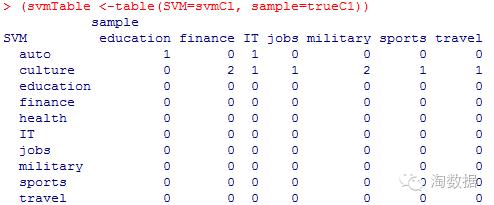
sum(diag(svmTable))/nrow(test)
看上去svm方法效果比较好些。
7.其他分类
文本数据经过矩阵化转换后,变为普通的Matrix或data.frame结构,传统数据挖掘方法都可以使用,如决策数、神经网络等,对此不再细述。
总结
本文介绍了文本挖掘常见的方法,因学习时间比较短,很多细节部分也没有展开描述,加之数据集选的不给力(样本少),计划下载些新闻进行分类预测暂且搁置。
另外对大数据量的文本的分析,可以考虑R结合Hadoop进行分布式分析。
以上是关于文本挖掘-wordcloud主题模型与文本分类的主要内容,如果未能解决你的问题,请参考以下文章