文本挖掘在国际酒店的应用
Posted 同程艺龙技术中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本挖掘在国际酒店的应用相关的知识,希望对你有一定的参考价值。
项目背景
国际酒店业务中一个很大的难点是基础信息整合,而酒店房型合并恰恰是最难的一个,合并错误率高发,造成较高的用户投诉与赔偿。为解决这一问题,我们采用文本相似度与文本分类算法构建模型,有效地提高了房型合并的准确率与合并率,降低了用户投诉。

现有问题
01
数据来源多,且不一致
国际酒店的数据来源多,主要包括以下两方面:1)酒店多。目前同程艺龙拥有120w海外酒店,不同国家、不同类型酒店的房型名称有较大的差异。2)供应商多,表述差异大。海外酒店的房型以英文为主,供应商提供的中文房型名称大多为各自处理的结果,表达差异较大,极难做到源头的统一。
02
数据总量大,数据增速快,增量大
同程艺龙的120w海外酒店的房型数据,目前已达到了亿级。每天的供应商新增或修改的房型数据量,已达到百万/天。
03
人工维护成本高
由于海外酒店的数据来源多,数据总量大且快,若所有酒店由人力维护,则需投入较大人力,且需要人力持续处理。海外酒店房型存在较大差距,人工处理也会出现一些难以避免的错误。图1为人工根据经验进行匹配的结果,人工根据词语”双人房,double”认为可匹配到大床房。但是忽略了,信息中的semi-double,导致匹配错误。图2是台湾的一家酒店房型,台湾地区酒店”superior room”对应的中文名称是“精致房”。而在其它地区酒店的”superior room”常规对应的是”高级房”,人工根据经验也容易出现错误。

图1床型判断错误

图2台湾酒店房型
解决方案
为了提高房型合并的准确率,共进行了三轮迭代:
1)基于规则的方法。从房型数据中提取关键词,对关键词进行分组,然后结合人工处理经验总结的词语组合规则,得到房型名称。这种方法需要投入大量人力梳理规则,并且由于海外酒店的特殊性,很难构建一个完全覆盖所有情况的规则集。
2)字符串相似度。该方法从标准房型中提取的关键词,构建关键词库。然后采用关键词匹配的方法,构建向量空间模型。通过向量相似度,得到供应商房型和标准房型的相似度。这种方法相较上一迭代减少了人力投入,但是会因文本高相似度,造成匹配错误。例如,“双人房,标准价”匹配到“标准房”。
3)基于机器学习算法,构建自动识别模型,解决房型合并中的90%的问题。 该方案包括数据收集,模型构建,对外接口与人工干预后台四个模块,这里主要介绍数据与模型构建两个模块。
图3国际酒店房型合并
数据
01
标准房型
为了保证准确率与用户认可度,我们根据酒店官网的信息,构建同程艺龙的海外酒店标准房型库。这部分数据用于构建文本相似度模型,以保证输出的房型有效且用户认可度高。
02
训练样本
人工根据供应商房型数据,依据原算法识别的房型名称,对房型名称进行分析统计后,按各房型名称数量分布抽取样本数,然后根据经验与统一标准进行房型标注。这一部分数据结合机器学习算法,用于构建有监督学习模型。
算法模型
现有房型合并,我们基于文本相似度与机器学习算法,构建了文本相似度计算模型与文本分类器,用于房型标准化。整体的模型包含文本处理,文本相似度与文本分类器,结构如下图所示:

图4房型识别模型
01
文本处理
供应商房型数据中,往往包含了较多的非房型信息,例如限定地区客人,接送机服务等。为了提升识别准确率,我们对房型数据做了以下处理。
1)编码识别,去除非中、英文房型数据
2)英文文本的书写规范处理,繁体中文处理
3)去除停用词、无效与干扰信息
4)文本同义词转化,根据常用同义词库,对房型文本进行同义词转化
5)数值处理,将中英文文本中不同表达形式的数值,统一由阿拉伯数字表示
02
文本相似度
相似度计算模块主要采用Jaccard、LCS与N-Gram算法,结合实际业务需要,构建相似度计算逻辑。在计算相似度之前,需要对供应商房型名称进行基础房型名称识别,基础房型包括:别墅,套房,公寓,客房等。然后,对基础房型一致的供应商房型和标准房型,分别进行计算词集相似度与字符串相似度。
我们采用Jaccard相似度计算词集相似度。Jaccard相似度,主要用于比较有限样本集之间的相似性和差异,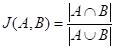 , A,B为词集合。当Jaccard相似度为1时,认为房型可匹配。即要求供应商房型名称对应的词集,与标准房型对应的词集完全一致。当标准房型词集为供应商房型词集的子集时,也认为两者可以匹配。
, A,B为词集合。当Jaccard相似度为1时,认为房型可匹配。即要求供应商房型名称对应的词集,与标准房型对应的词集完全一致。当标准房型词集为供应商房型词集的子集时,也认为两者可以匹配。
字符串相似度计算,是基于最长公共子序列实现的。最长公共子序列(Longest Common Subsequence,LCS),是指在所有的子序列中最长的那一个。房型的lcs=(供应商房型名称,标准房型名称),根据lcs与标准房型之间的差异度,判断相似性。采用lcs计算房型相似度,减少了特征提取的工作,且保持了较高的匹配率与准确率。但是lcs也有较明显的缺点,因为限制了顺序,导致例如“豪华标准客房,带阳台”与“豪华带阳台,标准房”无法进行匹配。
为了保证准确性,相似度计算完成之后,我们采用N-Gram算法,对涉及床型,卧室,人数的信息进行校验。避免将:“双人床”合并入“双床”,流程如图5所示。
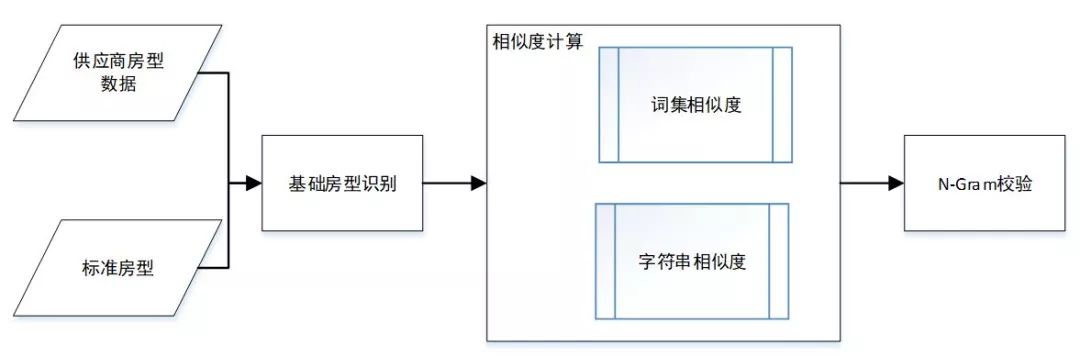
图5文本相似度流程
03
文本分类
文本分类模块,我们采用有监督学习的方法训练文本分类器,用于识别相似度模块未能识别的房型。现阶段因为人力问题,我们标注了160种房型,包括中文与英文样本,总样本量为1w。
对同一批训练样本,我们分别采用textCNN与fastText训练了分类器,用于房型识别。对比识别结果发现fastText更适用于现阶段的任务。因为,在样本量较少的情况下,采用fastText训练的分类器识别准确率高于textCNN。并且fastText在保持高精度的情况下加快了训练速度和测试速度。
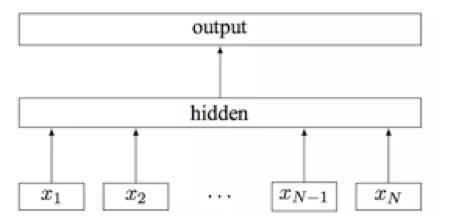
图6 fasttext模型结构
fastText模型包括三层:输入层、隐藏层、输出层。fastText的输入是词向量,输出是一个特定target,隐含层是对多个词向量的叠加平均。fastText利用单词的embedding叠加获得文档向量时,叠加了字符级N-Gram特征,对分类效果有一部分的提升。在输出时,采用分层softmax,这大大降低了模型训练时间。
目前,我们采用的是fastText构建的分类器用于房型识别。根据分类器输出的类别与置信度,对置信度达到阈值的房型名称,进行基础房型校验与单酒店标准房型一致化处理,模型输出一致化后的房型。
单酒店标准房型一致化处理,是保证分类器输出的结果能与标准房型一致,例如,“标准客房”、“标准间”和“标准房”在同一家酒店只能有一种表达。标准房型的一致化处理,是采用5.2.1中字符级相似度计算方法实现。

图7文本分类流程
算法效果
1
本地测试结果
根据业务要求,我们制定了合并率和标准房型一致率,用于衡量识别效果。合并率=N / M,标准房型一致率= N1 / N。M表示输入房型数,N表示输出房型数,N1表示与标准房型一致的房型数。
模型上线前,我们对港澳台和海外酒店,分别抽取了500家酒店进行测试,下表为测试结果。
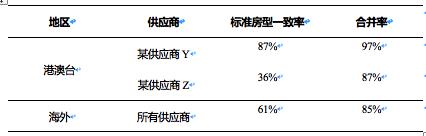
表1线下测试结果
1
业务反馈
新房型合并算法上线后,对酒店房型进行了全量的校验。人工校验过程要求房型结果不出现低进高,和会引起投诉的问题。例如:“客房”类房型不能合并入“套房”类房型,床型,人数和景观不能出现错误。目前人工校验准确率为99%,基础房型识别准确率是100%,新版房型合并算法减少了线上因为”低进高”带来的投诉与赔偿问题。
图8小程序呈现效果
新版房型合并上线后的业务反馈:
• 启用新版房型使分销产量有较大提升
• 启用新版减少了40%因投诉产生的赔付
以上是关于文本挖掘在国际酒店的应用的主要内容,如果未能解决你的问题,请参考以下文章