文本挖掘--词云的绘制
Posted 医学统计园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本挖掘--词云的绘制相关的知识,希望对你有一定的参考价值。
这是一条不务正业的推文!之前教程把SPSS所涉及的基本统计学分析方法,详细进行了讲述,暂时还想不到别的分析。IBM SPSS旗下的MODELER可以进行数据挖掘,比如随机森林,决策树等等。但是相比于Python编程,SPSS MODELER几乎没什么优势,唯一就是不需要写代码。所以如果有其他SPSS的需求,都可以向我提出。
之前的投票结果发现大家除了SPSS、Graphpad之外,还比较关注R语言作图分析。这节课我就讲一讲利用R语言进行文本数据挖掘,词云的绘制。
投票结果
1.安装或加载R包
if (!requireNamespace("wordcloud2", quietly = TRUE))
install.packages("wordcloud2")
library(wordcloud2)2.利用wordcloud2自带数据熟悉作
a.绘制星形(shape=”star”)词云
wordcloud2(demoFreq, size = 1,shape = 'star')
b.绘制五角形(shape=”pentagon”)词云
wordcloud2(demoFreq, size = 1,shape = 'pentagon')
当然也支持中文词云的绘制
wordcloud2(demoFreqC, size = 1,shape = 'pentagon')
3.自定义图形
a.绘制鸽子词云
batman = system.file("examples/t.png", package = "wordcloud2")
wordcloud2(
demoFreqC,
figPath = batman,
size = 1,
color = "skyblue",
)
b.绘制心形词云
wordcloud2(demoFreqC,
figPath = "1.png",#图片相对路径
size = 1,
color = 'random-dark')
c. 自定义颜色
ordcloud2(demoFreqC, figPath = "1.png", size = 1,
color = ifelse(demoFreqC$V1>1000,"red","skyblue")
)
以上只是个热身,下面我们开始对300首唐诗进行简单挖掘。先来看下300首唐诗的前三首,就有两首是杜甫写给李白的
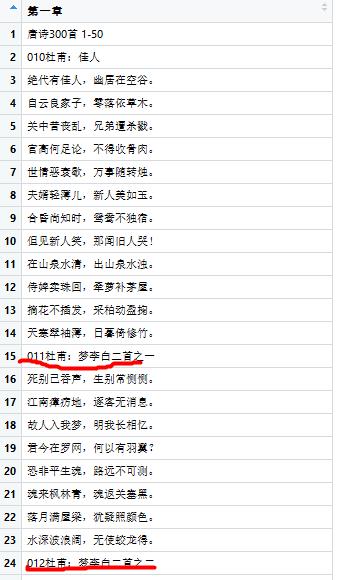
1.初步探索各作者作诗频率
#预览诗词
View(poem)
#提取作者名:诗名
author_title = poem[, 1][grepl("^[0-9]", poem[, 1], perl = T)]
#提取作者名
authors = gsub("[0-9]*(.{2,3})\:\S+", "\1", author_title, perl = T)
#做成dataFrame
authors_dataframe = as.data.frame(table(authors))
#预览包含作者名,以及写诗的数目
View(authors_dataframe)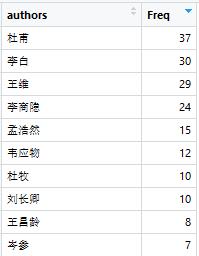
a. 发表诗词大于10次的作者
x1=authors_dataframe[authors_dataframe$Freq>10,]
pielab=paste(x1$authors,"(",round(x1$Freq/sum(x1$Freq)*100,2),"%)")
pie(x1$Freq,labels = pielab
,col = c("skyblue", "rosybrown1", "aquamarine",
"gray82", "wheat1", "lightgreen")
,radius = 1.1
,cex.lab=1
,main = "10首以上诗词的作者分布"
,angle=90
,border=NA)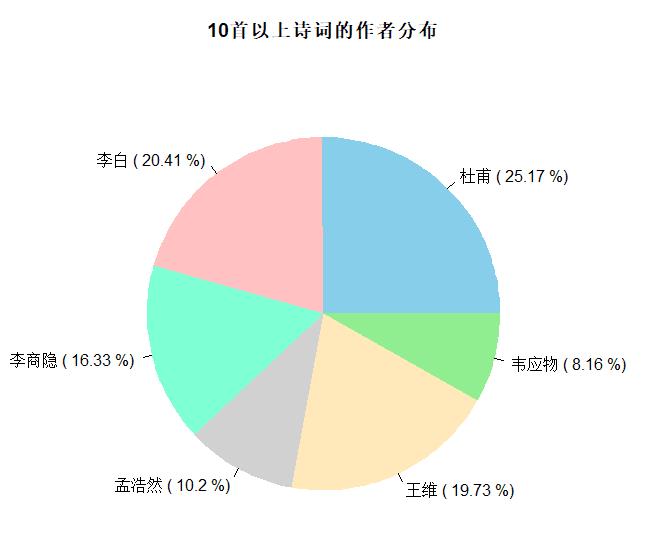
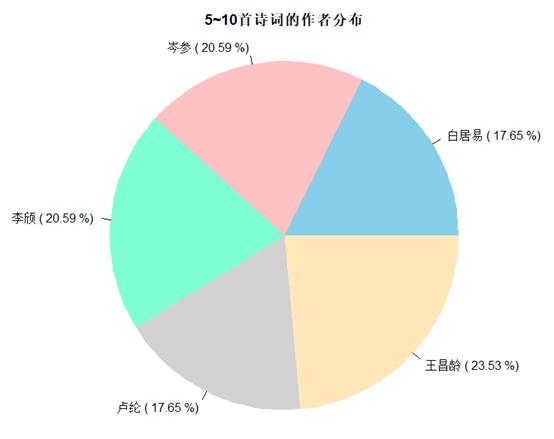
b. 发表诗词5-10次的作者
x1 = authors_dataframe[authors_dataframe$Freq > 5 &
authors_dataframe$Freq < 10, ]
pielab = paste(x1$authors, "(", round(x1$Freq / sum(x1$Freq) * 100, 2), "%)")
pie(
x1$Freq,
labels = pielab,
col = c(
"skyblue",
"rosybrown1",
"aquamarine",
"gray82",
"wheat1",
"lightgreen"
),
radius = 1.1,
cex.lab = 1,
main = "5~10首诗词的作者分布"
,angle = 90
,border = NA
)
2. 选取杜甫—李白的诗词进行挖掘
a. 对诗词进行预处理
利用perl语言整理成这个样子,第一列:作者+诗名;第二列:诗词内容。一共306行,也就是说有306首诗词:
b. 词频处理包的安装与加载
jieba(结巴),没错就是这个处理词频的包—结巴包。
if (!requireNamespace("jiebaR", quietly = TRUE))
install.packages("jiebaR")
library(jiebaR)c.看看杜甫的诗
#选择作者是杜甫的行
author_DuFU = poems[, 2][grepl("杜甫", poems[, 1], perl = T)]
#进行字符转换
author_DuFU = as.character(author_DuFU)
#利用jieba包产生一个对象
wk = worker()
#统计词频
x1 = freq(segment(author_DuFU, wk))
#作图
wordcloud2(
x1,
size = 0.4,
figPath = "dufu.png",
color = ifelse(x1$freq > 1, 'red', 'green')
)杜甫的关键词有:将军,先帝,公孙,君臣⇒关心国事和历史,先天下之忧而忧。风尘,人生,白首,妻子,春色⇒ 重感情,易多愁善感。日暮,江湖,感时,寂寞,天涯,涕泪⇒有些悲观,可能还爱哭,聊感寂寞。三峡,临颍,江南,关塞,西山⇒又胸怀四海。
d.挖挖李白的诗
author_LiBai = poems[, 2][grepl("李白", poems[, 1], perl = T)]
author_LiBai = as.character(author_LiBai)
wk = worker()
x1 = freq(segment(author_LiBai, wk))
wordcloud2(x1, minSize = 40)
wordcloud2(
x1,
size = 0.2,
figPath = "x3.png",
color = ifelse(x1$freq > 1, 'red', 'green')
)李白的关键词有:我,欲,来,还,去⇒注重自我感受,十分洒脱,想来就来,想走就走。不可,不为,不得,之难,难于上青天⇒生活之事,多有不可为,不得之,所以会时常抱怨。
又是一个长篇推文,加上代码2000多字,纯代码免费分享。不用打赏,点看和下方的就行。
以上是关于文本挖掘--词云的绘制的主要内容,如果未能解决你的问题,请参考以下文章