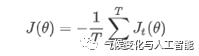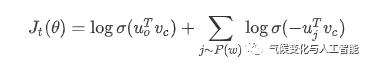文本挖掘可持续发展的政策透视
Posted 气候变化与人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本挖掘可持续发展的政策透视 相关的知识,希望对你有一定的参考价值。
如今,在环境问题和气候变化问题的双重压力之下,中国的能源转型和生态文明建设成为国家战略的一部分。“凡事预则立,不预则废”,顺利完成转型任务和生态文明建设需要一系列制度安排和政策工具的衔接。
目前,在可持续发展领域中的各类、各级制度安排和政策工具种类繁多、覆盖面广,并且正在形成一个系统化、全面的支撑体系。
以挖掘文本信息为目的,平台致力于对特定领域的政策文本进行解析和理解,并尝试从中获取具有价值的观点和结论。
本文利用
Mikolov (2013)
构建词向量的方法,构建基于政策文本的词向量表达,并对政策文本提供的信息进行透视分析。
1 政策文本的词向量表达
简单来说,我们利用
skip-gram
模型计算词向量,目标函数是
:
由此可得对于每一个中心词t在给定上下文的情况下概率的最大化。而对于每个中心词的词向量计算,由于skip-gram的神经网络拥有无比巨大的权重,因此考虑了随机负采样来对一小部分的权重进行更新,而随机词的抽取概率是其权重在全部单词权重的一元分布概率:
其中,我们选择
Sigmoid
函数计算词向量的概率。
实验数据
:
实验数据主要分为两个部分
: (1)
来自新华网的可持续发展政策相关报道新闻文本
(10000
条
)
;
(2)
来自政府公开的可持续发展领域相关政策文本
(230
条
)
。同时,我们整理了典型的政策句法示例:
“促进创新能力提升”、“加快研发新能源汽车制造”、“加强技术与成果转移”等。
使用
HanLP
提供的预训练分词模型得到上述文本的切分结果:
新闻文本
:
切分词数为
451521
,词数为
16947
;
政策文本
:
切分词数为
242456
,词数为
3917
。
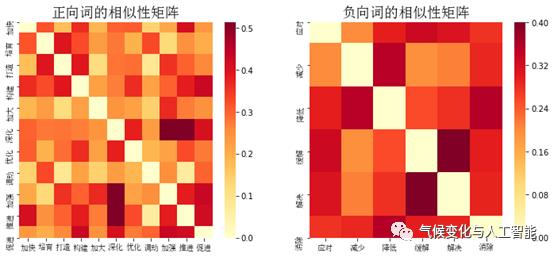
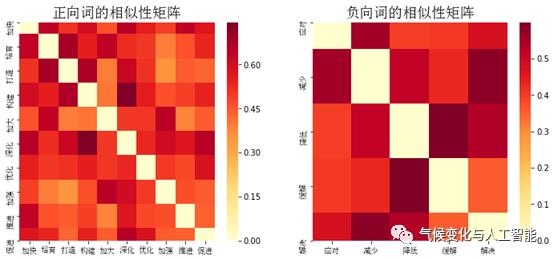
2 动词的相似性
在对词向量表达进行应用之前,我们的探索包含一个假定,即政策文本的上下文具有较强的关联性,句法信息能够为我们理解政策的上下文提供很好的基础。因此,我们从动词开始,分析典型动词之间的相似度。
在对词向量表达进行应用之前,我们的探索包含一个假定,即政策文本的上下文具有较强的关联性,句法信息能够为我们理解政策的上下文提供很好的基础。因此,我们从动词开始,分析典型动词之间的相似度。
通过量量计算动词之间的相似性
(
相似性矩阵是对称的
)
,可以得到
:
总体而言,固定的动词表达在政策文本中相似性整体强于新闻文本中的表达,同时政策文本中的正向词表达的相似性也明显高于新闻文本。事实上,这一探索的结果也表明不同类型的政策文本可能传递不同情感方向和程度的信息。
3 基于词向量的类比
词向量的计算除了帮助我们对巨大的语料库进行转化并提供词语层面的相似性测量之外,还具有令人惊叹的特性——类比 (Analogy)。
一般而言,我们可以定义基于词向量的类比评估: a:b :: c:?
其中输出的d即是预测得到的类比词的下标。这也意味着,类比词满足b-a = d-c的关系。
当然,词之间的类比关系同样具有不同的形式和含义,比如我们定义,动词:名词 :: 动词:名词符合句法上的格式,同时限定动词为正向动词集合中的元素,名词为频繁出现的动宾短语中的元素,即得到如下的结果:
不同文本中的词向量类比
(
左为新闻文本,右为政策文本
)
“加强
+
环境保护
-
经济”得到了医德、从重、严肃的类比,从语义上讲,
(
受限于
)
输入语料的大小和内含的语义并没有对上述的类比关系提供很好的基础,继而我们只能隐约地理解由“经济”引申出的类比词落在一系列的环境处罚问题和医疗问题上,而这在一定程度上也是有迹可循的
(
取决于语料的情况
)
。
“发展
+
经济
–
促进”得到了改革、人力资源社会保障厅和信息化的类比,其中多是政府部门的实体。这一结果主要受到语料性质的影响,即语料均来源于政策文件,其中多数表述均以特定的政府部门为主体,继而影响了类比的结果。
随着语料的丰富和输入样本质量的提升
(
比如在文本的预处理阶段,我们并没有对停用词进行很好地处理
)
,词向量表达的计算不仅能够变得更为精确,还能提高类比的准确度,为我们提供更多可供挖掘的信息。
4 展望
本次探索词向量表示和类比功能是对于针对小规模政策文本信息挖掘的一次简单尝试,作抛砖引玉之用。
随着更多政策文本数据的投入和模型的改良,我们将从句法、语义等方面提供更多的探索和尝试。
以上是关于文本挖掘可持续发展的政策透视 的主要内容,如果未能解决你的问题,请参考以下文章