DevOps 之旅:运维人员如何开始学习源代码?
Posted 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DevOps 之旅:运维人员如何开始学习源代码?相关的知识,希望对你有一定的参考价值。
编辑
闫丽慧@SAP
作者简介

陈晨
基础架构工程师,目前就职于中国银联。主要负责IaaS平台、容器平台以及运维管理平台的建设工作。
一、 前言
西汉·司马迁《史记·淮阴侯列传》:
上问曰:“如我能将几何?”
信曰:“陛下不过能将十万。”
上曰:“子有何如?”
曰:“臣多多而益善耳。”
在数据中心规模越来越庞大的互联网时代,运维人员如何从一个“兵士”转变为一个“将军”,如何像管理一台主机一样管理一个集群?
所有的一切,让我们从一个纯粹的运维人员转变为一个DevOps专家开始吧——本篇主要介绍一些运维人员开始学习源码的入门知识。
二 、转变自己的心态
1. 主动拥抱变化
运维人员完全没必要对阅读源代码带有恐惧感。
俗话说的好,不懂运维的开发不是好架构师。
笔者始终认为,运维人员普遍经历了生产化的锻炼,注重代码的可测试性、可维护性,也更严谨,这些都是成为一名优秀开发的重要元素。
据笔者的了解,国内优秀的互联网企业,很多运维人员的开发能力是相当强的。
2. 注重计划性
阅读源代码是一个循序渐进的过程,看的太慢是不对的,看的太快消化不了以致怀疑自己的智商也是不可取的。
阅读源代码必须要有清晰的计划,像读书一样去读。
3. 直面英文
想要读好源码,阅读英文资料是不可避免的。刚开始读英文资料是痛苦的,以后也终将是痛苦的。只是痛苦着痛苦着,你就习惯了。
4. 学会共享
大部分运维人员没有进社区提问的习惯。
实际上,只需要最基础的英文,就可以和国际上的各种程序员进行交流。而且开源的氛围非常好,乐于回答问题的人也非常多。
当然,不光要获取,还要学会分享。
社区是大家共享的结果,如果遇到可以回答的问题,也请耐心回答,不要回复“上网查一查就知道了”这类的内容。
三、相关知识链接
1. 开源社区
任何开源软件必然依托于社区,有社区就有主页。社区终将伴随你阅读源码的整个过程。
一般来说,社区至少会有以下分类:
开源软件的定义和描述
如何获取源码或者安装包
如何给开源社区做贡献
开源软件使用和配置的文档
开源软件部署架构的文档
给开发者看的社区开发的流程和方法
开发者使用的开发框架、测试框架
社区的重大事件;
比如说,openstack的社区主页,基本上就拥有以上全部内容:
2. 开源协议
了解开源代码所遵守的协议,有助于保护知识产权、避免法律问题。
常见开源协议:

3. 获取源代码
笔者大致统计了一下比较热门的开源软件的源码托管方式,如下:
| type | urls |
|---|---|
| mysql | |
| redis | |
| memcached | |
| ceph | |
| suse linux | |
| docker | |
| haproxy | |
| keepalived | |
| jboss | |
| kvm | |
| penstack | |
| OVS | |
| HADOOP | |
| jmeter | |
| ELK | |
| ansible | |
| apache |
基本上,所有的开源代码都可以在github获取,因此,学会使用github就是不可避免的一个步骤了。
4. 向开源社区贡献
向开源社区做贡献,在很多运维人员面前可能显得遥不可及,是这样吗?
给开源社区做贡献有很多方式,并不一定都是贡献源码。很多方式很容易上手,并取得成就。
通过和社区的互动,会更快的帮助我们了解软件,并逐渐在某一个或者多个方面成为专家。
4.1 贡献文档
私以为贡献文档是最有效、最快捷的为社区做贡献的方式,而且还有利于自身的学习。
例如haproxy的官网就如此鼓励你来贡献文档:
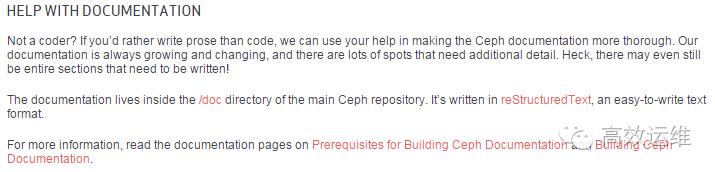
而且,由于国内资料的缺乏,很多优秀的开源软件还特别的征收中文翻译,一些国内的开源社区也会征收相关中文文档。
4.2 代码审查
代码评审是指在软件开发过程中,通过对源代码(或者其他提交物)进行系统性检查的过程。
例如在openstack中,社区鼓励任何人都可以参与到review中。
你可以不需要自己写代码,而只是帮助社区判断一段代码的修改是否合理(当然,大多数情况下你的review只是被core review作为参考)。
通过这个流程,你可以实时跟进社区代码的新特性,以及借鉴到很多有经验的开发人员的代码编写方式,还能培养自己的开发习惯,使自己变得更加严谨。
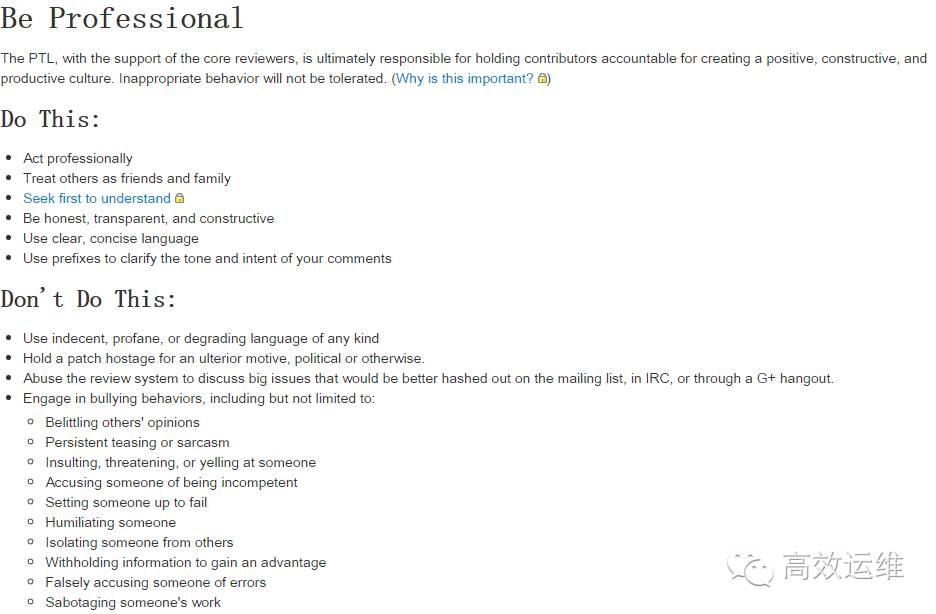
笔者贴上一段OpenStack对reviewer的要求:
4.3 Bug报告
还有什么比自己发现开源代码Bug更加令人激动的事情呢?
Bug报告即包括向社区提交发现的Bug,也包括帮助社区确定一个Bug是否确实存在以及其影响性。
对于很多刚入门的人,发现Bug为时尚早,但是可以去帮助社区去判断Bug的影响性。例如:

4.4 分享案例
社区也许还鼓励大家贡献自己的最佳实践。通过这个方式,你会更系统的了解你自己所使用的开源项目的集成经验,以及更严谨的对待每一个细节问题。例如ceph官网:

4.5 贡献源码
最难的也是最有成就感的当然是直接贡献源码啦。
直接贡献源码前你必须熟悉开源社区源码提交的方式,多花点时间是值得的。
比如OpenStack,除了需要注册账号、签署协议以外,代码提交流程也较为严谨,如下:
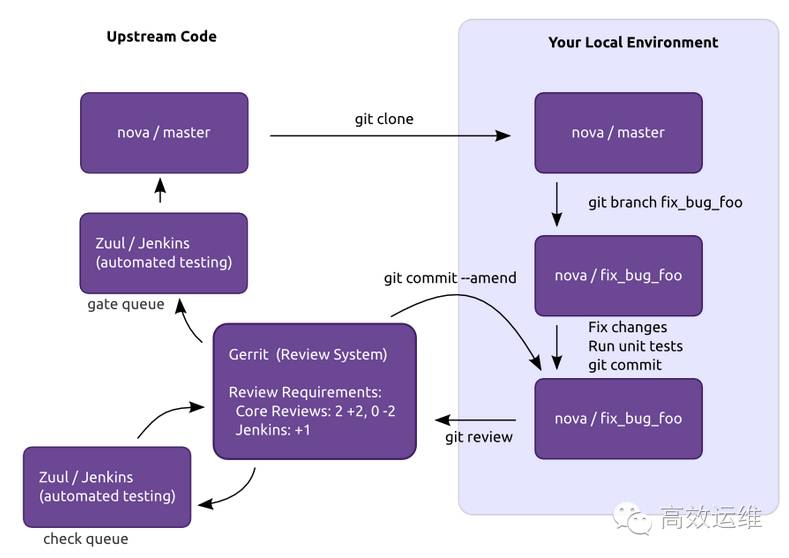
通过Git维护版本、远程和本地版本;通过Gerrit做代码审查;通过Jenkins做持续集成。花点时间,注册一下账号,融入社区吧。
当然,笔者也发现一些较为广泛使用的开源软件,竟然还是通过直接发送邮件和diff文件提交代码,由维护者自行决定是否合并。
4.6 参加会议
最高大上的就是参加开源社区的年度大会啦。
社区的meetup一般分为线上线下两种。积极参加会议你可能会获得如下的好处:
有机会了解社区的关注点和动向
接触业内的权威人士
主导社区的发展方向
例如,openstack今年在奥斯丁的会议,就对openstack的发展、技术分享等多项重要内容进行了沟通,参会人数更是达到了上万人。
5. 设计模式
设计模式在高级编程语言如java,python中非常常见。庞大的代码逻辑如果不能很好的进行代码的组织,则持续开发的效率很快就会下降。
设计模式/软件设计模式是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。
使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性。
笔者认为设计模式就像是参考了人类社会的运行分工,以更容易理解的方式组织代码的逻辑。从很多设计名称的名字就可以一窥一二:工厂模式、代理模式。
了解开源软件使用的主要设计模式,对理解代码之间的调用逻辑很有帮助。
笔者在阅读OpenStack的时候,发现openstack大量使用代理模式和工厂模式,基于这个,很快就明白了很多函数的作用以及源码维护者为什么要这样设计。
作为入门,笔者给出一个不错的网站,仅供参考:
下面用一个图片来整体描述一下设计模式之间的关系:
6. 并发与串行
读者可能会接触到如下的并发概念:进程、线程、协程和goroutine。
很多注重性能的开源软件对这三者的选择是非常有考究的。掌握三者的基本概念和区别,并带着问题如下的问题去看源代码:
为什么要有这种并发方式而不用其他的?
并发能多大程度的提高效率?
每次并发一个进程、线程,系统开销是多少?
以上四种都属于并发控制。
实际上很多高性能软件通过异步事件循环等“串行”方式实现高性能,例如haproxy、jquery。你可能需要了解异步、事件循环、回调等知识。
7. 模块化
无论是一个函数、一个文件、一个目录、一个JAR包,都可以称之为模块。
如果是你要写一个庞大的程序,必然也希望借鉴很多开源模块,或者对自身一些常用的功能进行模块化封装以便复用。
开源代码也是这样,一般来说,他们会这样构建他们的通用模块:
优先选择业内已经成熟的模块
对一些需要修改的模块优先选择补丁或者运行时修改的方式进行替换
针对个性化需求开发一些自己定制的模块
这里仍然以openstack为例,openstack复用了很多成熟的模块,例如:
alchemy作为DAO接口,eventlet作为协程并发;monkey_patch是openstack开发的运行时修改代码的包;oslo系列和wsgi等是openstack自己开发的模块。
8. 数据结构
部分开源软件涉及复杂的数据结构和算法,例如ceph、hadoop、Haproxy。此时,对数据结构和算法一定程度的掌握是必须的。
如果有志于成为ceph等开源软件专家,请务必系统的学习数据结构与算法。
数据结构是指相互之间存在一种或多种特定关系的数据元素的集合,是在内存中存储的数据的组织方式。
数据结构和算法紧密联系,精心选择的数据结构可以带来更高的运行或者存储效率。
不论是否精通编程,应该都听过数组、链表/列表、堆栈等。他们都是数据结构中最基本的内容。
笔者的建议是,使用一门你熟悉的编程语言,分别实现主要的数据结构。
9. 算法
算法!算法!算法!算法是任何程序员的必修课。
笔者的建议是,无论从事开发、测试还是运维,都应当有一定的算法基础。
常见的算法有快速排序、堆排序、二叉树查找等,复杂一点有解决一致性问题的paxos算法。
笔者仍然推荐读者用熟悉的代码实现基本算法。
不过,不管是以hadoop为代表的大数据技术,以openstack为代表的云计算技术,都贯穿着这样一个概念:
与其花费巨大的资本和人力去研究算法,不如通过简单的扩展实现性能的提升。
Hadoop用简单的MapReduce实现分布式计算、Openstack通过简单的横向扩展给应用提供更高的计算能力。
这当然是题外话了,有兴趣的同学可以深入研究。
10. 系统调用
很多和操作系统紧密联系的开源软件,大量使用了系统调用。因此,熟悉开源软件调用的系统调用也是必不可少的步骤了。
系统调用是由操作系统实现提供的所有系统调用所构成的集合即程序接口或应用编程接口(Application Programming Interface,API),是应用程序同系统之间的接口。
大家最熟悉的系统调用可能就是打开一个文件了,我们看看用perl语言打开一个文件的方式:
open(FILE,”>>file”);
print FILE “hello”;
close FILE;以上简单的几行代码,会被perl的解释器转译成linux操作系统的系统调用,他的函数原型是头文件 fcntl.h:
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);熟悉这些系统调用才能更容易的掌握源代码的功能实现。
再比如,你要研究docker,就至少得把docker调用的6个namespace隔离的系统调用使用一遍,通过各个namespace手动创建一个隔离的容器。
或者说,在研究haproxy的时候,你得先掌握epoll的系统调用,否则都难以了解他是如何实现高性能的。
热文推荐:
光看文章不过瘾? 来GOPS2016上海站吧
和陈晨在会场面基
2 天 60 位运维行业顶级大咖,倾囊相授!
现在报名可享受 8 折优惠,欲购从速!
↓↓↓ 点击"阅读原文" 【直接报名】
以上是关于DevOps 之旅:运维人员如何开始学习源代码?的主要内容,如果未能解决你的问题,请参考以下文章