Docker与实现DevOps的三种方式
Posted 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Docker与实现DevOps的三种方式相关的知识,希望对你有一定的参考价值。
编辑
周小璐@灵雀云
编者按
可能很多人都读过 Gene Kim 的《The Phoenix Project》,这是一本融合了IT专业知识的纪实小说,讲述了PU公司通过IT项目与公司业务结合继而将公司起死回生的故事,既有商业实战模式的真实企业案例,同时将IT运维的解决之道融入其中。
三位作者Gene Kim 、KevinBehr和George Spafford,结合多年的IT相关经验,站在一个管理者的角度讲述了IT运维的四种工作类型和DevOps的三种方式(Three Ways of DevOps)。
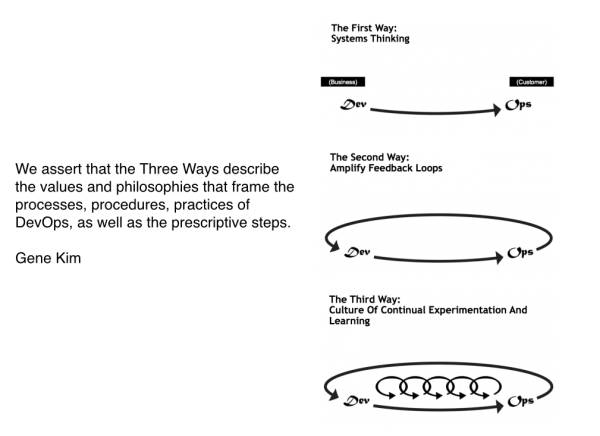
遵循【第一种方式(The First Way)】意味着思考系统的端到端流程,例如,考虑一次软件变更需要经历的所有步骤,从客户的初始需求一直到生产环境部署。正如Gene Kim等人在“凤凰项目”中所说的那样,这有助于避免局部最优和消除工作孤岛;
【第二方式(The Second Way)】增加了反馈回路,问题因此可以得到快速识别和纠正。一个典型的例子是使应用程序的生产日志可以随时提供给开发团队;
【第三方式(The Third Way)】意在培养一种不断实验以及通过反复实践达到精通的文化。Netflix的ChaosMonkey服务可以看作第三方法在实践中的一个极端示例。
Docker如何在这三种方式中发挥作用呢?
以下为译文:
Docker和第一种方式—系统思维
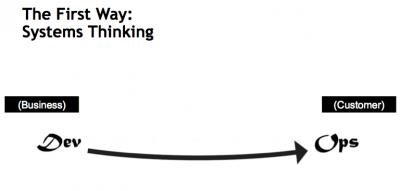
这种方式将系统作为整体的价值流来理解,管理这个流的目的是达到全局最优或减小瓶颈。DevOps的行话一般叫【Ah-ha to the Cha-Ching】的时间,书面语中叫【lead time】。我更喜欢将这个过程形容为商品从生产到消费的过程。
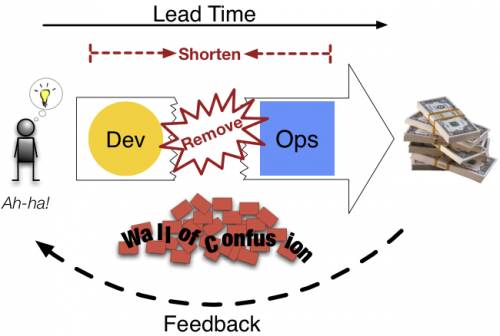
为了达到第一种效果,要在不减慢全局工作流的同时,提高本地进程的速度。需要遵循三个主要原则:
第一,提高流程中每个过程组件的速度;
第二,减少每个子进程的资源和时间浪费;
第三,通过功能隔离,进一步优化进程,从而能更好地可视化和理解全局的流程。
Docker和这种方式有什么关系呢?
以下从速率(Velocity),差异性(Variation)和虚拟化(Visualization)三个角度展开:
第一、速率(Velocity)
开发流程(Developer Flow)
大多数使用Docker的开发人员,在个人电脑上搭一个多容器的测试环境。他们用Vagrant或Boot2Docker运行一个本地的虚拟实例,作为Docker主机。在这个环境中,就可以测试这个由多个容器组成的服务栈了。
集成流程(Integration Flow)
通过Docker化的build机制,可以将持续集成的工作流程化。 一个CI系统可以设计为多个虚拟实例,每个实例都是独立的Docker主机(比如build slave),还有些build环境采用Docker-in-Docker的方式。这样将build环境和测试环境做了清晰的隔离。这种情况下,最初的虚拟实例一直在运行着,因为嵌入的Docker主机可以被CI slave实例重建。内部的Docker主机只是一个Docker镜像,可以像其它Docker实例一样被实例化。
就像开发者的个人电脑一样,集成服务可以作为Docker容器运行在这些build slave中。不但测试服务的效率获得了指数级增长,还能让测试场景更多样化,基于同一模板的测试可以在几秒内被重复创建。可能需要几天完成的集成测试可以在几分钟内完成。
Docker加速CI流程的另一种方式在于其Union FileSystem和Copy on Write(COW)机制。Docker镜像通过层级文件系统创建,只有最上层是可写的。
比如mysql容器在某次测试停止后,镜像还是原始的状态,可以创建新一轮的测试,这大大提高了在整个流程中创建环境的速度。
部署流程(Deployment Flow)
蓝绿部署是一个流行的CD(Continuous Delivery)流程,常用来向生产环境无缝地迁移应用。生产环境部署的挑战在于保障无缝和实时的更新(从一个版本到另一个)。蓝绿部署的过程是这样的:集群中的一个节点(绿节点)更新到版本,其它节点不更新(蓝节点),先测试绿节点。蓝绿部署的关键在于两点:
更新所有节点花费的时间要尽可能少;
如果集群需要回滚,也要尽可能的快。
Docker容器可以让更新和回滚更高效。另外,由于应用被隔离了,每次更新涉及的变化组件更少,这个过程也更清晰。Docker对于像dark launch和canarying等其它部署方式带来的优势也类似。
第二、差异性(Variation)
Docker image在软件交付过程中发挥的作用之一,在于基础设施和应用都可以被封装到Docker镜像中。
Java的口号是“write once run anywhere”,但由于Java的产物只被包含了应用,对于Java runtime和特定的运维环境有很多依赖。
但对于Docker来说,开发人员用Docker镜像来打包真实的基础设施(比如基础OS,中间件,runtime和应用)。这种收敛的隔离,降低了交付流程(开发,集成和生产部署)中多个环境间潜在的差异。
如果开发者能在笔记本上测试一组Docker镜像,那么这些服务同样能在集成测试和生产部署中运行起来。
将Docker作为基本的部署机制的话,镜像是二进制的,整个流程中的所有环境并没有太大的差异性。与传统方式中,每个阶段都要另外搭建一套环境形成鲜明对比。
在2014年旧金山举办的DockerCon上,Gilt Group讲述了他们如何利用Docker作为其基本的部署机制。
Gilt以不可变基础设施的方式,利用了微服务架构,换句话说,他们生产环境中的基础设施是不能更新的,只能被替换。
如果你看过他们CTO Michael Bryzek 的演讲视频,就会知道他们整个流程看起来也是不可变的,我给它杜撰了个名字【Immutable Delivery】。
Gilt在采用Docker部署之前,部署流程中是1000多条发布脚本,管理着1000多个软件库和25种部署模式。这种旧的方式为整个流程带来很多差异性,脚本的查找和所有权问题经常为流程带来瓶颈。
第三、虚拟化(Visualization)
在微服务架构中,服务被定义为有边界的环境。当这些服务被封装为Docker容器,并作为交付流程的一部分,马上就成为真实世界可见域。
从DevOps运维的角度来看,MTTR (Mean time to Repair/Restore)是系统成功的关键要素。
当这些服务被封装为Docker容器,并作为交付流程的一部分,马上就变得可见了。服务的可见性能够帮助组织更快地隔离,发现和确认所有权,从而提高整体的MTTR。
小结
流程的Docker化可以在减少软件交付的成本和风险的同时,提高更新的频率。
Docker和第二种方式—反馈回路
第二种方式旨在放大和缩短反馈回路,可以快速和持续地纠错。一个系统bug如果没有影响到消费者,就不是bug。
精益原则告诉我们,早日发现潜在的下游错误,就能减少服务交付上的成本。
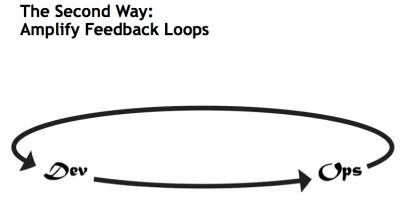
上面提到的3个V(Volicity,Variation,Visualization)在第二种方式中依然适用:
快速纠错是必需的;
差异性也在第二种方式中扮演了重要角色,因为基础设施的复杂性,需要更快去定位系统的问题;
最后,软件交付物需要被改进和封装(比如虚拟化)到代码中(比如源代码,源代码仓库),从而减少整体软件交付的Lead Time。
1、速率(Velocity)
和第一种方式类似,这个角度重在效率的提升。需要注意的一点是Dev到Ops的流程并不是单向的。它可能会因为bug被打断,而走向相反的方向,所以要在所有的方向上达到高效,就要回答这几个问题:
可以多快地掉头?
系统要多久能查找到问题源?
系统多久可以恢复到正确的状态?
在丰田的精益生产中,有一个名为【Andon Cord】的概念,说的是一旦生产线发现问题,生产线会自动停止,进行检修,保障缺陷产品不会流向下一个流程。
所以,即使是一个很小的错误,工人也会停止生产线,因为他们知道纠错也是整个流程的一部分。

而Docker打包,提供交付物的方式,能让组织在问题发生时迅速停止流程,缩短纠错时间。
2、差异性(Variation)
还是和第一种方式类似,这里从基础设施的复杂性出发。
大型的软件系统可能很脆弱,一个基于软件的服务可能是由成千上万个class、libraries及不同的接口组成的,交付上的差异性会让错误很难被定位。
而Docker的交付模式和整个流程中标准的交付物,减少了差异性,从而降低了未来交付流程中错误也变得多样性的风险。
3、虚拟化(Visualization)
不可变的交付流程的优势之一,在于流程中大部分的交付物都是二进制的,服务交付团队可以从代码中创建元数据,也可以在任何阶段虚拟化。
经常可以看到Docker image中看到Git Commit相关的命令行,还有很多元数据相关的技术也可以被嵌入到Docker image中。
R.I.Pienaar 曾经写过一篇有趣的博客,他在自己的镜像中都嵌入了元数据,还加入了很多实用的监控脚本,比如可以获取这些信息:
镜像被build的时间,地点和原因
基础镜像的信息
如何启动、验证、监控和更新它
Git仓库的信息
镜像的Tag信息
镜像归属哪个项目
是否任意用户都可以丰富这些元数据
所有这些都是加强反馈环的方法,这些嵌入的元数据可以加速错误的定位,从而减少整个服务交付的Lead Time。
DevOps的第三种方式
第三种方式中,对前两种方式做了结合,通过持续学习(Continuous Learning)的过程完整实现这个循环回路。
在DevOps领域,我们通常用Kaizen来暗指一个组织中持续进步的方法。这里的Kaizen指组织在所有的行为中倡导持续试错和学习的文化。
遵循第三种方式的组织会倡导体验式学习,美国著名的管理学大师Edward Deming称其为Plan Do Study Act Cycle (PDSA),PDSA将你所有的实践都看做实验。
1999年,Steven Spear和Kent Brown在《哈佛商业评论》发表了一篇名为《Decodingthe DNA of the Toyota Production System (TPS)》的文章,TPS 一直被作为精益生产的起源,DevOps正是从精益原则衍生而来。
在这篇文章中,Spear和Brown认为TPS是一种科学的做事方式,可以适用于任何事情。
笔者最喜欢文中的这句话:【TPS is a community of scientists continuouslyexperimenting】。
《Toyota Kata》(Kata这个词来自日语,中文称为『套路』,用来描述一套精心设计的动作,常被用在日本的歌舞伎艺术或武术中)的作者Mike Rother将这种思想更进一步。
Rother建议TPS团队的管理者在实践PDSA的过程中,结合上愿景,就像通过重复的动作来强化记忆肌肉一样。
Rother建议,在PDSA的循环周期中,为所有的行为设定一个阶段性的目标,开始下一个阶段时,从这个阶段的结果中学习,进步。
他们会扪心自问:这个实验阶段的结果是否偏离了最终的愿景?
以上这些方法都可以融入到组织实现DevOps的过程中。
Docker和第三种方式—不断实验及学习的文化
为了让组织更像一个科学家团队,首先要有可靠的实验装备,比如试管、烧杯、显微镜、护目镜等。在DevOps团队中,Docker就是实验装备。
在软件和服务交付的业务中,唯快不破。这里的【快】不仅指服务交付的速度,还代表着你复制这些服务,以及应对消费者态度的速度。
实践1:选择流程
最近笔者在和一个大型的金融机构交流,他们基于Docker为其内部用户提供了一个CaaS(Container as a Service)服务。这个机构中有100多位数据科学家,每天进行大量的数据分析,这些数据科学家要将分析工具和数据进行正确的匹配。
在这个CaaS服务诞生之前,完成这项工作非常艰难。一些数据适用于Hadoop这类工具,一些适用于Spark这类工具,而另一些适用于R语言。如果匹配错了,会造成大量的时间浪费。
第一个阶段的改进中,他们将这些数据分析工具封装在了容器中(还不是Docker),这种方案的效果是:数据科学家们在几分钟就可以将容器化的数据集和分析工具集进行配对,然后决定这种配对是否合适,效率提高了两个数量级。
但这个阶段的问题是:这个『数据-工具』流程的lead time大概是两天。于是他们又对流程进行了改进,使用了Docker,现在几个小时就可以完成『数据-工具』流程。
再回想下这个解决方案的效果。在CaaS方案之前,数据科学家们为了节省时间,只能忍受那个凑合的配对,而现在他们可以通过多次实验,找到最合适的数据-工具匹配。
这个模型适用于任何类似的选择流程。
实践2:更标准的工具
最近,我在用棒球数据教我12岁的孩子学习分析学,当我在他的笔记本上安装R和一些棒球的R语言包的时候,我在Twitter看到了同事Jessie Frazelle的一篇博客『Using an R Container for Analytical Models』,介绍了如何创建一个R语言的容器。
在这篇博客的启发下,我和儿子做了一个Docker镜像,里面包含了R语言基础镜像,还有1871年以来的所有棒球数据。
现在我们可以随时从Docker Hub上下载这个镜像,到任何电脑上,开始学习。现在我们在计划将这个工具推广到一个棒球俱乐部中,方便大家用R语言分析棒球数据。
END.
原文链接:
活动预告
5月21日,灵雀云【释放云的无限潜能之微服务】为你带来微服务干货!
时间:5月21日(周六) 14:00-17:00
地点:北京市朝阳区望京街10号 望京SOHO T3 A座 5层3Q
点击【阅读原文】报名参会!
以上是关于Docker与实现DevOps的三种方式的主要内容,如果未能解决你的问题,请参考以下文章