大规模开发团队如何实现DevOps转型? 来自微软全球开发平台工程团队的实践经验
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大规模开发团队如何实现DevOps转型? 来自微软全球开发平台工程团队的实践经验相关的知识,希望对你有一定的参考价值。
微软全球开发平台工程团队从敏捷到DevOps的转型
2013年11月13日,我们宣布了Visual Studio2013,以及微软研发云Visual Studio Online (VSO)的正式商用。紧接着我们经历了一次长达七小时的服务中断。我们的服务运行在一个“弹性扩展单元”中,为大约一百万用户提供服务。当时恰逢峰值流量时间段,欧洲和美国东西海岸的用户均已上线,在市场部门对外公布正式商用的同时,我们正在通过“功能开关”启用各种本被隐藏的新功能。随后发现负责服务间通信的IP端口,这个重要的网络层组件未能如期生成我们需要的遥测数据。当时因为新功能发布,已经产生了大量请求。从技术的角度来看,这造成了一个很尴尬的情况,如图1所示。当时的细节情况可以参阅这里。[i]
图1:VS 2013的发布因为VS Online服务一系列尴尬的中断而面临窘境。
从市场的角度来看,本次发布活动无疑是一个巨大的成功。VS Online服务借助这一转折点,成功地实现了两位数的用户数月增量。(增长的趋势还在继续,随后一年里,百万级别的用户数顺利翻倍。)
功能与后端保障之间的权衡
那段时间里,VSO只有一个托管在芝加哥数据中心内的弹性扩展单元。我们很清楚,需要通过多个单独部署的弹性扩展单元进行横向扩展,但我们总是更重视与功能有关的工作,忽略了使用多个弹性扩展单元为网站提供更周全的保障这件事情。发布会上遭遇的情况让我们改变了自己的想法。相关团队决定将本已计划好的功能改进工作延期,全力解决后端的保障工作。我们需要通过某种方式对VSO的后续更新进行“金丝雀部署“。原本使用的芝加哥弹性扩展单元(我们称之为SU1)保持不变,但我们打算在该弹性扩展单元之前增加另一个单元,新增的单元被命名为SU0。
在这一过程中,首先我们会将所有冲刺(sprint)版本部署至圣安东尼奥 (Scale Unit 0),在这个位置运行一段时间。如果感觉一切正常,才会将其滚动部署至芝加哥的单元 (Scale Unit 1),如图2所示。当然,如果SU0遇到问题,还可以修复问题并重新启动新一轮的部署。后来我们又在这个序列中加入了更多Azure数据中心。到2014年秋季,我们增加了阿姆斯特丹作为第五个数据中心。随着业务继续扩展至全球更多地区,很快我们还将加入澳大利亚。在以上过程中,我们都在使用Visual Studio Release Management来处理部署流程和自动化滚动更新等操作,每一个冲刺版本都是这样部署的。
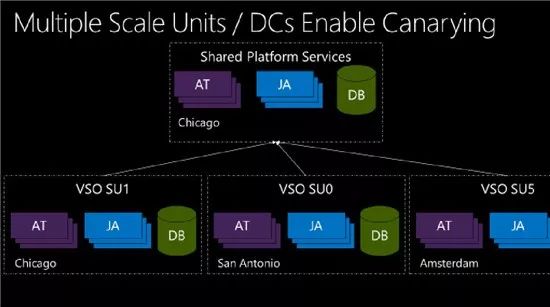 图2:2013年11月之后,VSO从原本的一个数据中心扩展至多中心,借此实现“金丝雀”部署和全球落地。
图2:2013年11月之后,VSO从原本的一个数据中心扩展至多中心,借此实现“金丝雀”部署和全球落地。
对于线上环境服务质量的重视立刻获得了立竿见影的效果。从2014年4月服务月度点评(图3)中可以看到,2013年11月共出现了43个线上问题(LSI),六个月后骤降至7个,其中仅两个来自正式发布(非预览)的服务。我们还在持续完善自己的DevOps实践和运维实践,注重保持线上环境的健康状况,不过接下来还有很长的路要走。
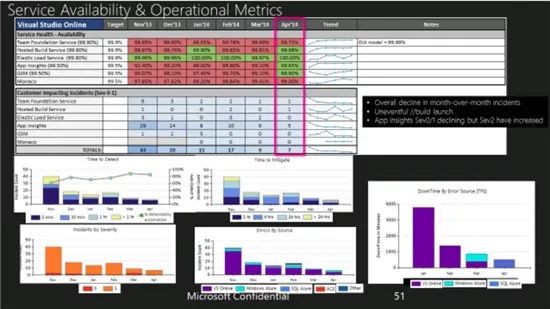
图3:到2014年4月,VSO仅触发了7个LSI,六个月前这一数据还是43个。在这七个LSI中,只有两个是已经正式发布的服务造成的。
我们如何从敏捷转型为DevOps
七年来,微软全球开发平台工程团队 (Developer Division, DevDiv)一直在拥抱敏捷。借助切实可行的工程实践,我们从XP时代逐渐积累的技术债减少了15倍。我们为部门内部负责不同方向的团队和产品负责人提供Scrum培训,并将为客户提供价值作为一切的核心。在发布Visual Studio 2010时,该产品线获得了前所未见的客户认可。[ii]
发布VS2010之后,我们很确定是时候将Team Foundation Server转型为软件即服务 (SaaS)的研发云产品了。该服务的SaaS研发云最早被命名为 Visual Studio Online (VSO),现在已经改名为Visual Studio Team Services(VSTS) 研发云,托管于Microsoft Azure (不过在我们工程团队内部还是习惯使用VSO来称呼这个产品)。为了继续延续之前的成功,我们需要开始采用更多的DevOps实践,这也意味着我们需要将实践从敏捷转型为DevOps。这两者有何差别?
DevOps文化的特点之一在于需要从使用中学习经验。对于敏捷,有一种心照不宣的假设,认为产品负责人是无所不知的,能够正确提出产品的规划和新的需求列表。与之相反,在运行某种高度可靠的服务时,你可以用近乎实时的方式观察用户是如何使用不同功能的。你可以更频繁地发布新版,通过实验进一步完善,衡量并询问客户对不同改变的看法。这一过程中所收集的数据将成为后续一系列改进的依据。通过这种方式,DevOps产品的需求列表实际上是一系列假设,最终会变为软件运行过程中所做的实验,并可促成持续不断的反馈循环。
如图4所示,从敏捷中催生出的DevOps基于四大趋势:
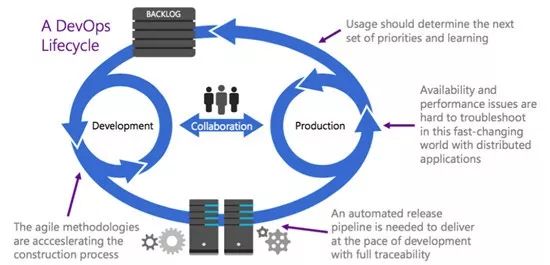
图4:这四大趋势推动了DevOps的演变。
与很多“生于云端”的公司不同,我们最开始并没有SaaS产品,客户主要在PC端本地环境中使用我们的软件(Team Foundation Server最初发布于2005年,现已发布了2017版)。在开发VS Online,也就是现在的VSTS研发云时,我们决定为SaaS和“盒装”版本的产品维护同一个代码库,但采取云为先的开发策略。工程师在推送代码后将触发持续集成流程。当为期三周的冲刺结束后,我们会发布到云端,进行4-5个冲刺后,会为“盒装”产品发布一个季度更新,过程如图5所示。
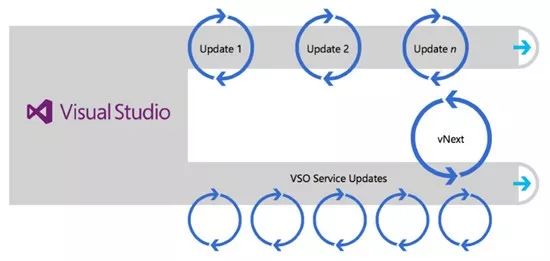
图5:我们为VSTS研发云(SaaS产品)和TFS(本地运行产品)使用了同一个代码库。每三周,我们会将新功能部署至VSTS研发云。每季度,这些更新会滚动发布至TFS。在发布重大TFS更新,如2015版时,则会基于当时VSTS研发云的版本进行。
暴露控制
在开发服务的过程中,高频率发布会让我们获益匪浅。在我们的工作中,我们会在为期三周的冲刺结束后发布。借此我们可以更及时地将工作成果展现给用户,但我们需要对暴露的时机进行一定的控制。这方面我们遇到了一些问题:
l 如何处理需要多次冲刺才能完成的功能?
l 如果明确知道某个功能随后需要改动,又该如何针对不同功能进行实验以便了解使用情况和用户反馈?
l 如何通过“灰度上线”在做好对外发布和公开推广之前引入新的服务或功能?
对于所有这些问题,我们选择了功能开关这种模式。功能开关是一种控制机制,决定了要将何种功能暴露给哪些用户或用户组。随着团队针对新功能开展工作,我们可以通过功能开关服务注册一个开关,这种开关默认处于关闭状态。在准备好让某些用户尝试新的功能后,即可为这些用户在生产环境中打开对应的开关,并根据需要决定何时关闭。如果要改动对应的功能,无需重新部署即可关闭这个开关,停止该功能的对外暴露。
通过这种方式实现渐进式的暴露控制,功能开关还提供了一种供我们在生产环境中进行测试的好方法。通常一开始我们会将新功能暴露给内部员工,随后暴露给早期用户,随后逐步暴露给更广泛的客户群体。通过对性能和使用情况进行监控,可以确保新的服务组件在大规模环境中可以正常无障碍运行。
代码速率和分支
当我们于2008年首次采用敏捷开发时,我们认为可以通过适当的质量门禁 (Quality gate) 和代码分支结构开发出更高质量的代码。早期的开发工作会使用一些异常复杂的代码分支结构,只能接受按照严格定义编写的代码,通过封闭签入(gated checkin)机制,确保新提交的代码必须和主干代码完成预合并,并经过构建策略的检查后才能真正进入配置库。
这种代码分支结构造成了一种始料未及的后果:很多时候我们需要花费数周甚至数月的时间才能把叶子分支上的代码逐层合并进入主干。而分支中的代码将长时间处于未合并状态,这又会为合并工作造成大量遗留债务。当工作成果已经准备好进行合并后,主干可能已经进行了大幅度的改动,导致出现合并冲突,进而需要花费大量人力物力进行协调。
2010年,我们采取的第一个措施是将代码分支结构大幅“压平”,仅保留很少的分支,并且保留的分支大部分也是临时的。我们明确了目标,要优化代码流动速度,换句话说,就是将代码签入和可被其他人获取的间隔时间降至最低。
随后我们使用Git打造了一个分布式版本控制系统,该系统目前也已被VSTS研发云和TFS所支持。我们的大部分客户和同事依然在使用集中化的版本控制系统,因此VSTS研发云和TFS可以同时支持这两种模式。Git的优势在于可以实现非常轻量级的临时分支。我们可以为工作项创建特性分支,并在将变更合并到代码主干后进行立即清理掉该特性分支。
提交后的所有代码位于Master(主干)中,同时Pull-request工作流结合了代码审阅和质量门禁功能。借助这些能力,代码合并工作已经可以通过简单的小批次操作持续进行,每个人随时都可以看到最新的代码。
这种流程可以在短时间内对不同开发者的工作进行隔离,随后以持续的方式集成在一起。这种临时分支还降低了后期维护的开销,可在不需要时彻底删除。
Agile on Steroids
我们依然在遵循Scrum的原则,但为了促进交流和跨地域扩展,只保留了其中的精髓。例如我们工作主要以功能小组 (Feature crew) 为单位,这类似于Scrum中团队的概念,但产品负责人需要加入团队并参加所有日常工作。产品负责人和工程主管联手代表整个团队。
我们还运用了团队自治和组织整合 (Organizational alignment) 的原则,借此功能小组中产生了新的变化。团队往往涉及多个领域,我们通过整合开发人员和测试人员的职业晋升路径将这两个角色统一成了一个工程角色(此举大幅提升了士气)。
所有团队都是内聚的。每个小组有8-12名工程师,我们会尽可能确保他们至少可以共同工作12–18个月,很多团队的合作时间甚至更长。如果因为工作原因需要调整,我们会建立第二个小组来处理积压的工作,而不会让工程师在不同小组间来回更替。每个功能小组都有自己的团队办公室,如图6所示。这样的办公室并不是那种大面积开放式空间,而是一个专属的房间,可供大家针对同一个领域开展工作并自如地交流。团队办公室旁边还为可能的突发情况准备了小的“焦点办公室 (Focus Room)”,这种办公室中,我们也非常鼓励自由的交流。到了每日站立会议时间时,大家都会站起来畅所欲言。

图6:在同一个团队办公室中干活的功能小组成员。
根据经验,我们最终选择以三周为一个冲刺周期。事实证明对于我们这种需要全球协作的任务,很难在更短的时间里为客户提供足够多的价值,而如果选择更长的周期,则会影响新功能的发布速度。微软内部一些部门以两周为一个冲刺周期,但也有一些部门甚至会每天多次针对新工作成果展开各种实验,不会受到冲刺的约束。
从概念上来看,“完工”的定义其实很好理解。构建,运行,这样就行了。当一次冲刺结束后,你的代码会正式部署给数百万用户,如果代码中存在任何问题,你(以及其他每个人)立刻就能知道,并可立即开始修复问题根源。
我们会轮流担任ScrumMaster 这个角色,这样每个人都有机会体验Scrum Master的管理责任。在对外交流方面,我们会让冲刺的仪式 (Ceremony) 尽可能简洁。每次冲刺开始时,队员从产品积压工作列表 (Product Backlog)中领取任务,并通过一封篇幅不超过一页的邮件就自己的冲刺计划进行描述,邮件中需要添加指向VSTS研发云中产品积压工作列表内容(PBI)的超级链接。大家可以通过回复这封邮件的方式共同对冲刺进行审阅,同时,团队还会提供一个大约三分钟左右时长的视频。视频中包含演示,会从客户的角度介绍通过本次冲刺所能实现的目的。
我们还会确保计划尽可能简单。通常来说,会针对未来18个月的工作制定愿景,并朝着这个方向努力。愿景可以通过多种形式体现,例如技术尖峰 (Spike)、故事板 (Storyboard)、概念视频,以及概括性文档。我们以每6个月为一季,“春季”或“秋季”,在这段时间内我们会围绕整个团队的承诺和依赖关系坚持不懈地完成工作。每三次冲刺后,功能小组的领导者会聚在一起进行一次“功能沟通会”,借此分享希望达到的优先级,修正后续工作方向,与其他团队交流寻求新的目标并确保所有团队保持一致。例如可以使用功能沟通会重新对网站工作和用户可见的功能进行划分。
构建—度量—学习
在经典敏捷实践中,由产品负责人对产品积压工作项 (PBI) 进行优先级排序,大家会或多或少地将其视作一种需求。PBI 可能体现为用户故事,形式可能非常简单,但必须是确定无误的。我们以前就是这样工作的。
但现在不是了。为了遵循DevOps实践,我们会将PBI视作“假设”。这些假设必须能转化为实验,借此获得能够支撑或减少实验的证据,随后,我们还可以从这些证据中学到切实可行的经验。[iii]
进行一个足够好的实验,要求有具备统计学意义的样本,同时还有用于对照的控制组,此外还需要理解不同因素的影响结果。例如图7中的这个例子,我们遇到了一个问题:VSTS研发云的新用户并没有立刻创建团队项目,而没创建团队项目会导致用户无法执行其他绝大部分操作。图7展示了在网页上开始创建团队项目时的界面。
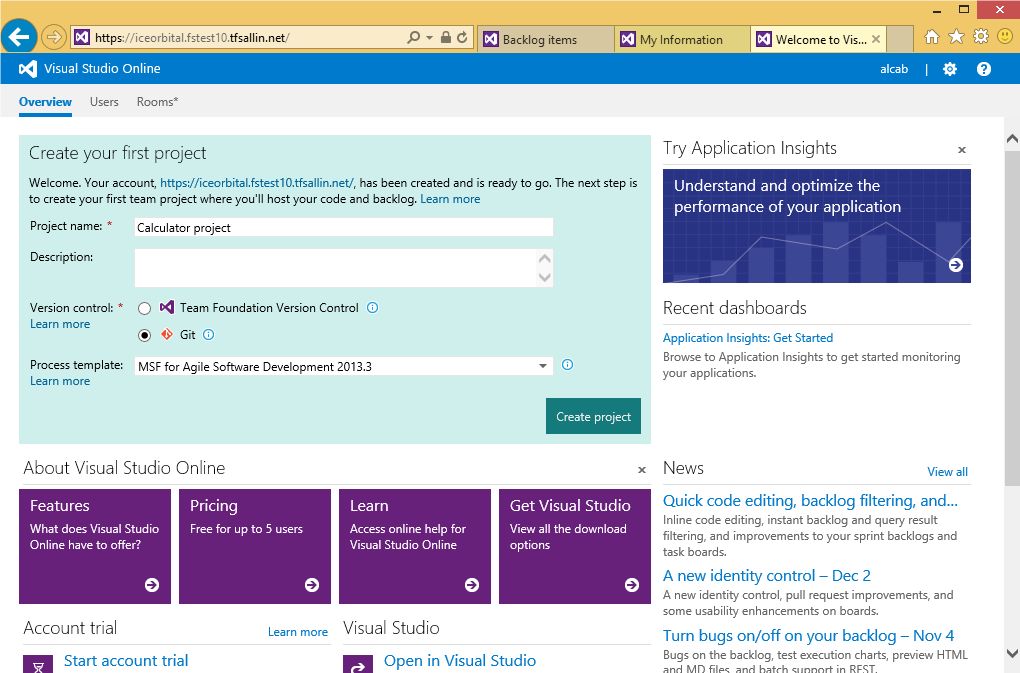
图7:原本的方法需要执行太多操作,并且很容易让用户分心,很多用户希望能以更自然的操作来创建项目。
我们修改了Web端和IDE中的这部分体验。图8显示了IDE中的新体验,该体验会鼓励用户通过两个界面注册VSTS研发云并建立项目。我们借助六个弹性扩展单元中的两个对这个新体验进行了实验。
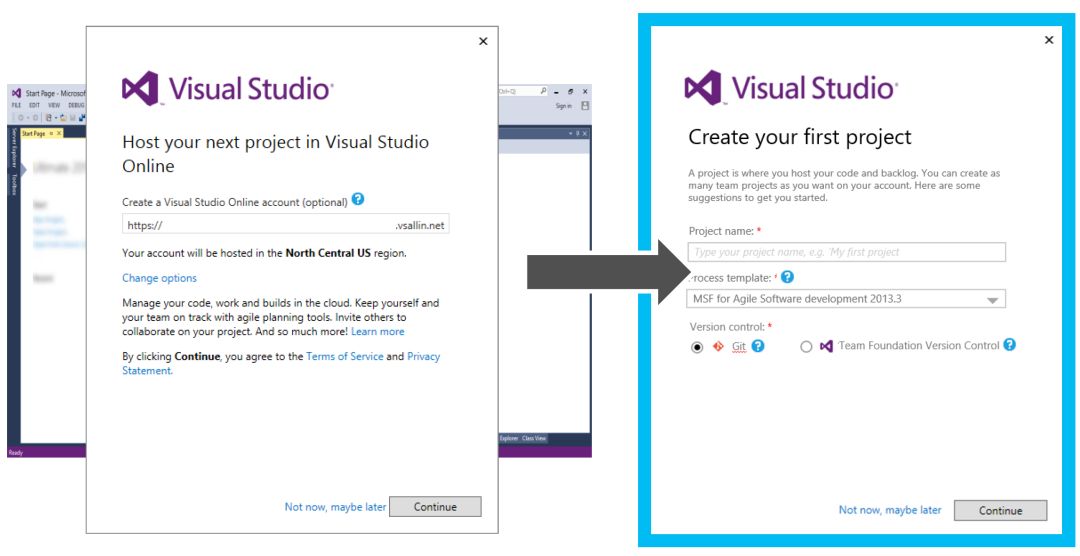
图8:在两个弹性扩展单位中为IDE实现了更完善的项目创建体验实验。
这次IDE实验的影响如图9所示。新客户创建团队项目的比例由3%增长至20%(增幅约七倍)!
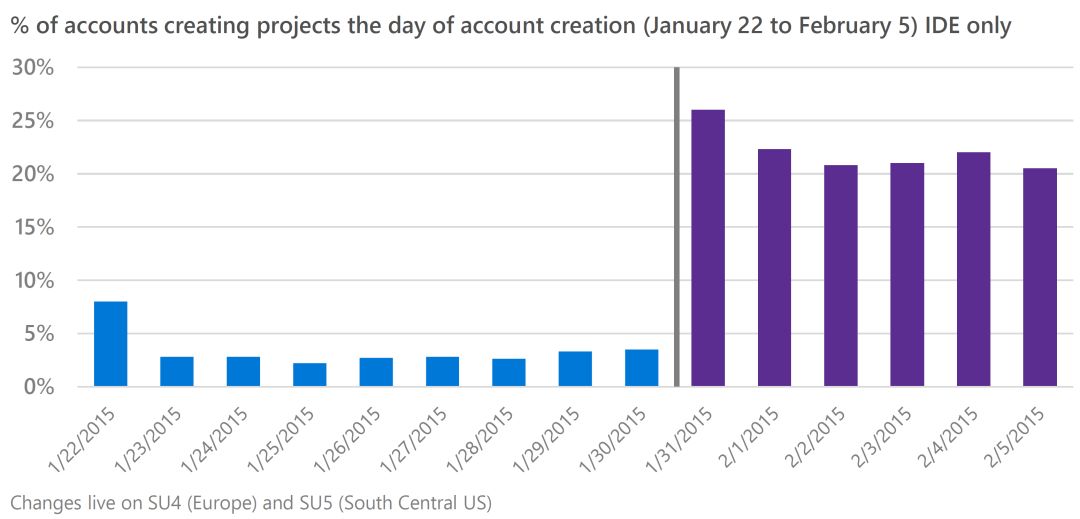
图9:IDE中的流程变动让新用户通过IDE创建项目的比例从3%增长至20%。
于此同时,我们还改进了Web界面的注册过程,也获得了非常明显的效果。图10展示了Web注册所做的改动。
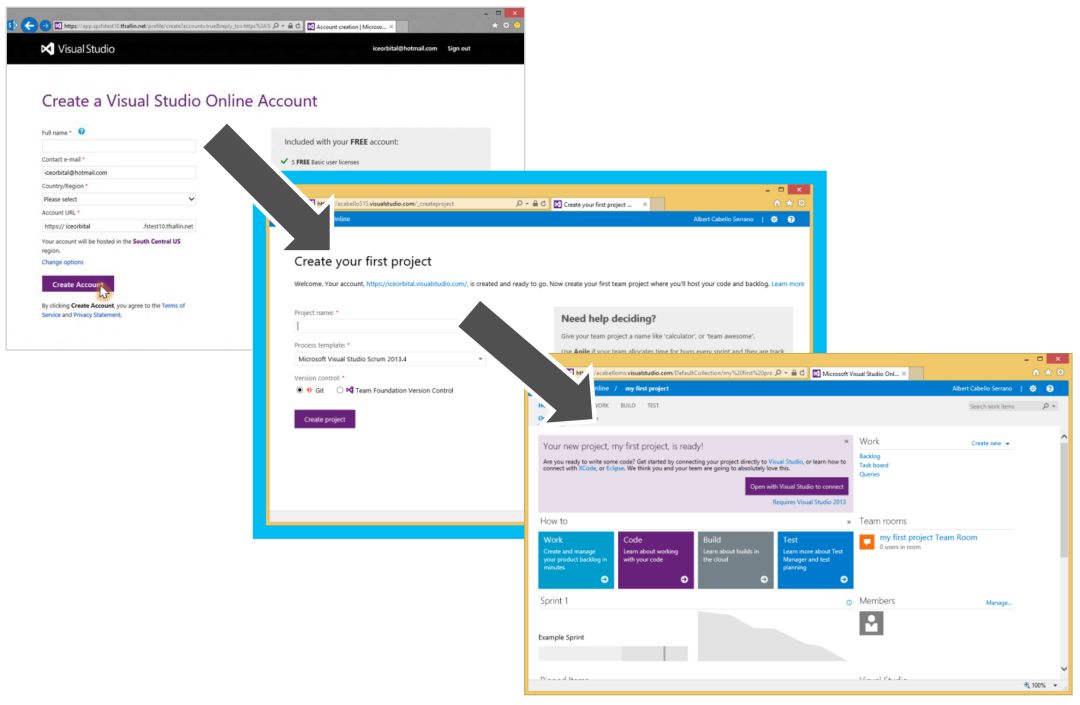
图10:Web注册通过类似的简化可以在第二个界面上直接建立项目。
我们统计了在注册帐户当天就建立了团队项目的用户比例。这一比例从原本的约18%增长至30%(约1.7倍),如图11中从绿色过渡至黄色的柱状条所示。虽然结果喜人,但其实这一结果与我们预期相差较远,同时与IDE方面的所取得的大幅提升之间有很大的差距。
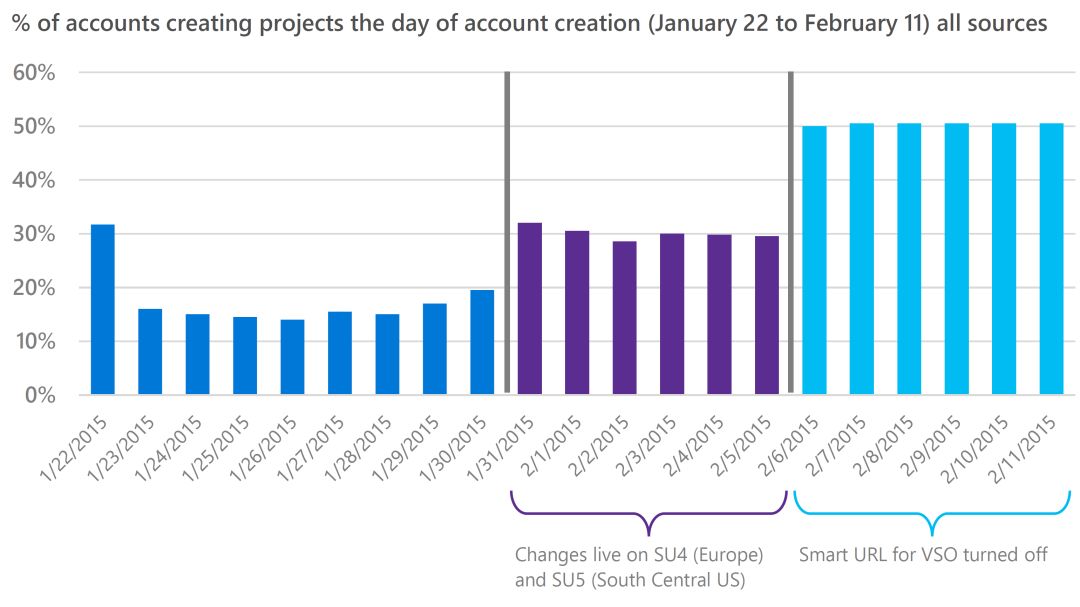
图11:Web帐户创建的结果由于两个实验出乎意料的相互干扰而被误导。排除这些因素后,结果就很清楚了。
后续调查中发现,我们其实还在同一时间进行了另一个实验。在这个实验中,位于漏斗顶端很多不符合要求的用户也被鼓励注册帐户,但他们并未这样做。这也证明了我们的控制组不够完善,两个实验相互之间产生了干扰。在停止了用于加速创建帐户的实验后,项目创建比例激增至50%,如图中绿色柱状图所示(增加2.8倍,比IDE中的效果还要好2.5倍)。
这个故事的寓意在于,实验的执行过程有好有坏,并不能总是很明显地确定结果是否合理,是否可重现,以及是否受到了妥善的控制。
为DevOps打造的工程系统
VSTS研发云是一种24x7x365可用的全球化服务,提供了包含财务保障的99.9%高可靠性。但是要注意,99.9%的SLA并不是我们努力实现的目标,而是最低程度的保障,因为低于该标准我们就要给用户退款。我们的目标是做到100%的高可用和客户满意:不因为维护而停机,无需全新安装只需更新,整个过程完全自动化。这就要求所有服务必须相互解耦,具备明确的调用规则和清晰的版本控制。与很多客户的系统类似,VSTS研发云也运行在Azure公有云上,整个基础架构都由Azure提供。
自动化部署
该服务的部署和网站可用性工程是由一个名为服务交付 (SD) 的小型团队管理的,该团队直接向工程团队负责。每次冲刺后的下一个周一,SD团队会开始进行部署。部署过程可通过Visual Studio Release Management自动实现,如图12所示。我们会在工作时间内进行部署,这样一旦遇到问题也可以更方便地进行调查和补救。由于VSTS研发云中存储了客户数据,而数据库架构经常需要更新,因此无法进行真正意义上的回滚,只能进行前滚。滚动操作会自动从一个弹性扩展单位延续到下一个弹性扩展单元,首先从金丝雀弹性部署单元SU0开始。借助这种方式,我们可以循序渐进地对功能暴露进行控制,检查运行状况和用户体验,以便推进下一步的部署。
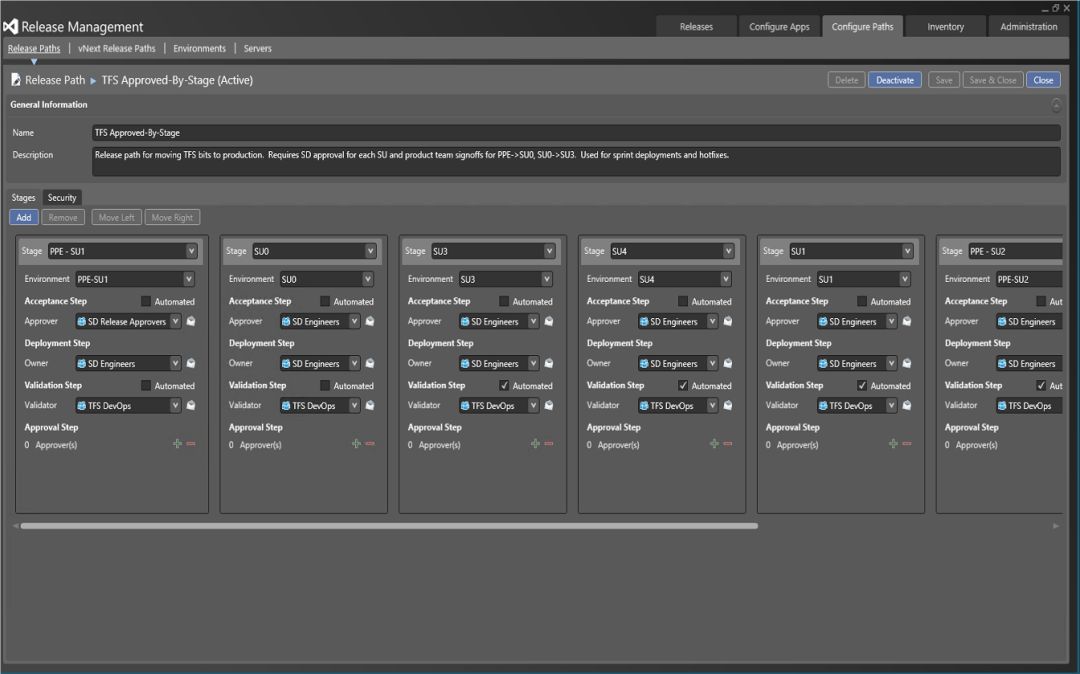
图12:VS Release Management控制着从一个弹性扩展单位按顺序向着下一个弹性扩展单位进行部署。
每个部署都从SU0开始,部署完成后维持运行几小时,随后继续进行下一单元部署。如果遇到问题,能在SU0顺利解决是最理想的情况,我们会针对问题根源进行修复,随后继续部署。如果数据受损必须进行灾难恢复(万幸这种情况只出现过一次),我们也只会在SU0中针对自己的数据,而非客户的数据进行恢复。
遥测
遥测机制可以说是VSTS研发云中最重要的代码。如果服务本身有问题,监控机制也必须保持可用状态。如果服务遇到问题,监控警报和仪表板需要能立刻汇报相应的问题。图13展示了一个服务运行状况概述的示例。
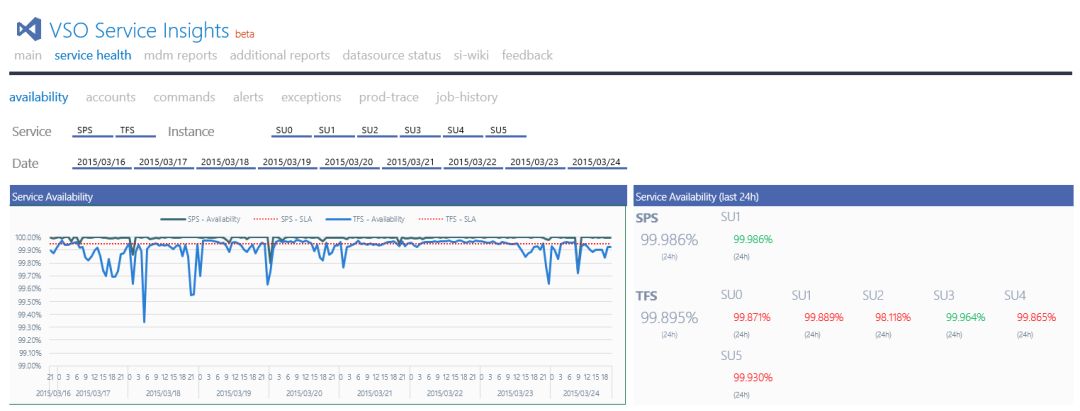
图13:这是组成VSTS研发云服务遥测功能的众多顶级图表之一。
VSTS研发云每个组件都经过精心设计,能针对可用性、性能、使用情况,以及排错提供360°视图。遥测也遵循了类似原则。
我们宁愿做可能会没有用的工作,也要尽可能收集一切信息。
我们会努力专注于各种切实可行的度量指标,而不是那些浮夸无用的指标。
除了反馈本身,我们还会度量各种结果和比例,借此来确定所采取的各类措施的效果。
平均每天我们会收集60GB-150GB的遥测数据。虽然可以向下挖掘至特定客户的相关信息,但按照我们的隐私策略,除非客户选择与我们分享,否则所有的数据都会匿名化处理。我们收集的部分数据包括:
活动日志。我们会针对VSTS研发云服务收到的Web请求收集所有数据。借此可以追踪每个命令的执行耗时和次数,进而判断特定调用或依赖服务是否变得缓慢或需要频繁重试。
跟踪记录。任何问题相关的堆栈跟踪(Stack Trace)信息都会被记录,并用于对调用序列进行调试。
作业历史。作业是一种对跨越服务的活动进行编排的工作流。
性能计数器。这些计数器与执行性能排错问题的计数器类似,可以追踪系统资源运行状况,VSTS研发云每天会生成约5千万条事件。
Ping Mesh。这是一种对网络基础层进行快速可视化的方法,借此可以保障全球网络连接的可用性。
综合事务。也叫“由外至内的测试”,通过Global Service Monitoring运行,可从全球用户的视角检测运行状况。
客户用量。在用量方面我们会度量自己的“流量入口”、转化漏斗、参与情况,以及首要客户。
KPI指标。这些是遥测系统通过计算汇总的指标,借此可判断服务的商业健康度。
追踪
最重要的一点,我们必须避免将任何事情当成是理所当然,每个人都接受“线上文化”的理念。换句话说,服务状态永远被我们放在第一位。如果线上遇到了问题,那么所有人必须优先加以处理,问题的检测和补救是此时的头等要务。我们的所有走廊里都安装了实时仪表板,服务运转好坏所有人都一目了然。
所有活动网站问题(LSI) 都会记录到VSTS研发云中,进而用于分析根源并每周审查。图14展示了LSI的一个范例。
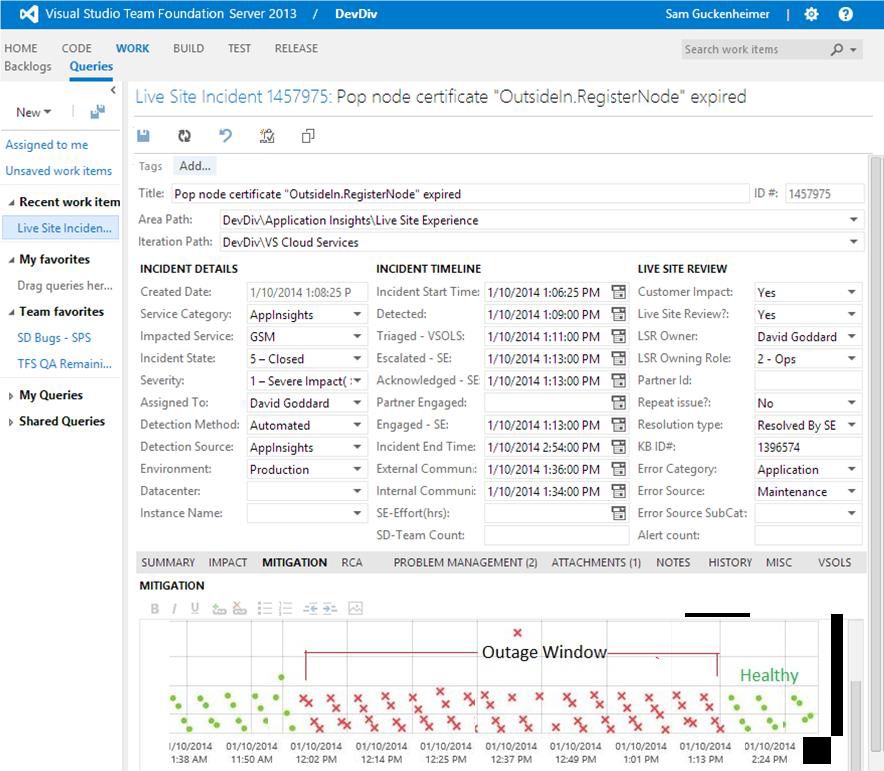
图14:生产服务遇到的每个事件,包括补救根源问题的相关细节均会通过LSI进行追踪。
当警报响起
DevOps的一个常见问题是:“谁带着传呼机?”在我们这里,成员遍布世界各地的服务交付 (SD)团队永远是24x7保障的第一道防线。如果需要将问题上报至开发团队,他们会按照功能小组所定义的指定负责人(DRI) 的工作时间安排进行上报。我们对服务层面的预期为,DRI能在5分钟(工作时间)或15分钟(下班时间)里接手。
我们对“补救”的看法也很重要。我们的补救不是切换一个虚拟机那么简单,而是要修复造成问题的根本原因。这种做法有点类似于丰田在工厂里安置的报警拉绳 (Andon cord),如果在流水线上发现残次品,任何工人都里可以拉绳报警。[i]我们希望从来源位置修复代码或配置问题,通过完善测试和发布流程预防相同问题再次发生。所有线上问题响应的度量指标都是以分钟为单位来衡量的。
这方面我们取得了一个巨大的成果,通过足够精确的警报机制,可以在无需人工介入的情况下自动联系DRI。为此我们建立了一个消除噪音和冗余警报,建立智能边界的运行状况模型,用它判断真正需要采取措施的时机,该模型如图15所示。借此我们在2015年2月将警报精确度提高了40倍,所有P0和P1警报都能自动上报给负责人。
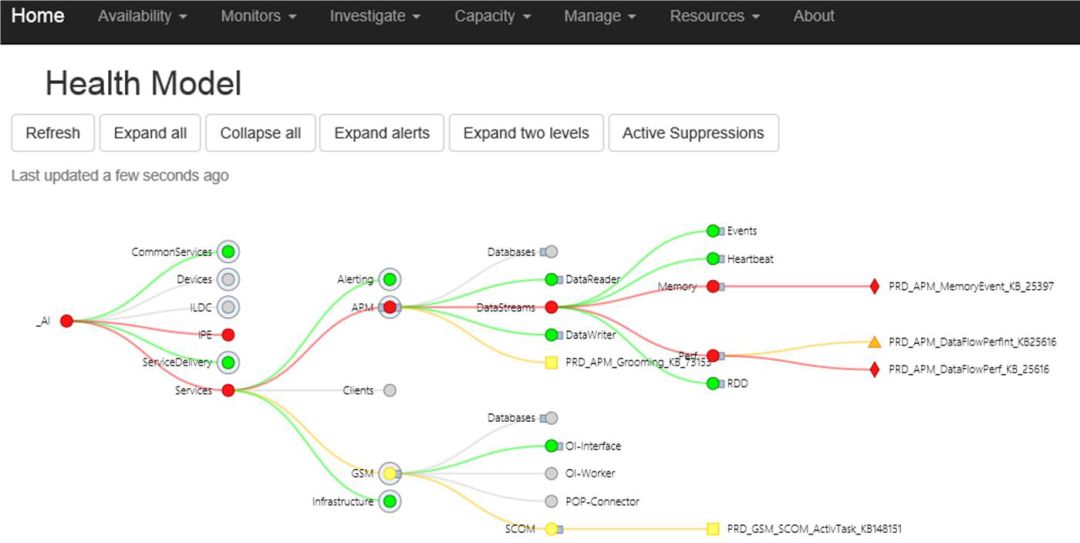
图15:这个运行状况模型可以自动消除重复的警报,并判断问题根源可能在哪个功能领域中。
从用户的体验中学习
尽管为工作制造了不少困难,但我们在工程中的方方面面都在逐渐更贴近用户体验。例如计算出99.9%的服务级别协议 (SLA)所采用的方法就是一个很好的例子。
SLA本身并不是我们的目标。我们的目标是100%的满意度。这意味着我们需要执着于可能只占0.001%的异常情况。因为异常情况往往隐藏在平均情况中,为了让SLA的计算更严谨,我们陆续开发了三代算法。这三代算法的具体情况如图16所示。最初我们使用了由外至内的监视(下图中虚线所示)用来追踪服务器的可用性。第二代算法主要关注相对所执行命令的总数,执行缓慢或失败的命令的相对数量,借此找出更普遍的异常情况所对应的问题(下图黄线和蓝线)。随着服务继续完善,“分母”已经排除了大部分不符合要求的客户所对应的情况。目前我们采取的计算方法是计算用户所遇到的服务不可用的分钟数在总使用分钟数中所占的比重,用黑线代表。
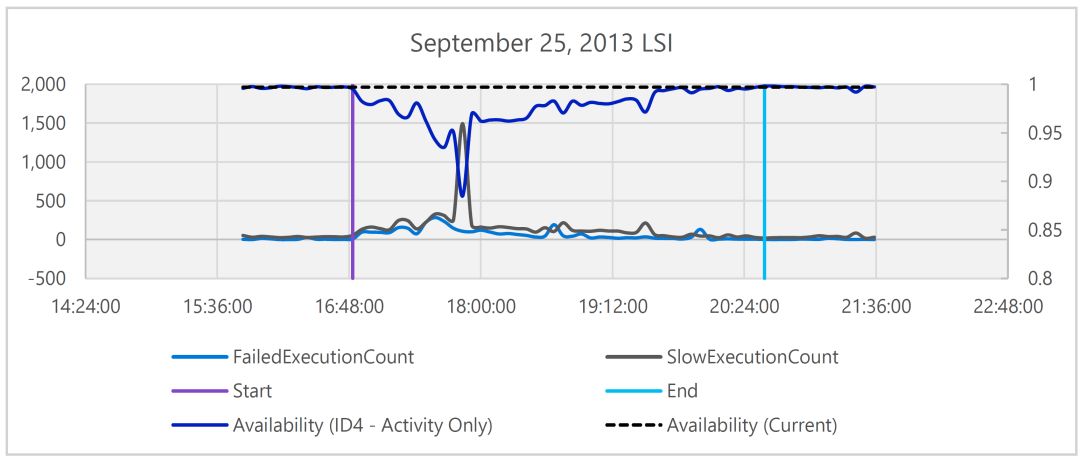
图16:这个LSI图对比了三种计算SLA的方法。由外至内的监视没发现任何问题,追踪命令执行结果的方法显示有一小时运行缓慢,而真实用户的监视发现经历了三个小时的响应延迟。
从上述四小时的统计可见,第一个(虚线)SLA显示没有任何问题。第二个(黑线)显示问题持续一小时,第三个显示性能低下持续三小时。实际上我们并不“需要”如此严格的度量,但还是这么做了。只为打造更优秀的服务。
安全性
作为例行安全实践的一部分,我们需要提供有保障的数据隐私、数据保护、服务可用性,以及服务安全性。过去,对于本地部署的软件,为了构建纵深防御机制预防安全问题,我们付诸了巨大的努力。很明显,现在依然需要这样做,此外我们还开始假设服务已经被攻陷,并考虑该如何检测这样的入侵行为。[ii]
除了使用SU0进行金丝雀部署,我们还可以通过这个数据中心进行安全演练,这么做的目的与消防演练类似,是为了进一步加固VSTS研发云服务。通过这样的弹性扩展单元进行模拟攻击,无需担心可能会对付费客户的服务造成任何影响。
新的开发模式
以往只开发本地部署的软件时,我们会通过对工程系统和流程进行优化实现最小化的平均故障间隔时间。换句话说,我们会将软件发布给客户,如果随后发现有错误需要纠正,修复成本是极为昂贵的,因此我们会尽可能提前采取一切措施发现可能存在的问题,尽量避免需要发布新的软件版本。
DevOps彻底改变了这种做法。如果能通过“无痛”的重新部署将修复成本降至最低,那么此时的目标将截然不同。周期时间、发现时间、补救时间,学习时间,所有这一切时间都需要降至最低。
这也催生出多种弹性设计模式。依赖项有可能发生故障,最有可能在流量峰值时期出现。因此服务必须能够平稳地降级,具备周全的重试策略,例如“断路开关”就是如此,[iii]而且需要能通过类似混沌猴子 (Chaos monkey) 那样的实践进行加固,这种方式是 Netflix 发明的。[iv]
灾难恢复计划至关重要,而我们会在模拟攻击的时候对这些计划进行测试。无心之失或重大灾难随时有可能发生,我们需要对此做好准备。
开源
在我们转型方法的过程中,越来越多地以用户和贡献者的身份加入到开源软件 (OSS) 社区中。OSS工作流程的中的重点在于分享、复用和协作。OSS鼓励提供可以单独发布,松耦合的协作服务。
如果针对我们遇到的问题有现成的 OSS 解决方案,我们会直接使用,而不会“重新发明车轮”。如果我们开发的一些东西能够让更多人获益,我们会分享给社区。对于创造出受欢迎组件的工程师,我们会给予奖励,同时我们也鼓励公司里的每个人直接利用获得批准可以使用的组件。任何工程师,都可以为公司里任何产品的改进贡献自己的力量。与此同时,在内部,我们还会提供企业代码监管机制,并要求为产品提供更长的支持时间。
学习的平均时间
事件发生后,只有经过调查并从中总结出经验教训才算彻底处理完成。我们会使用“5个Why”[v]从不同角度记录下次该怎样才能做得更好。如果出现影响到客户的故障,Brian Harry会以责任高管的身份发布博客文章,解释具体情况以及从中学到的经验。这个博客类似一种公共记录和追责机制,促使我们不断地精益求精。[vi]
客户对于这些博客文章的反应让我们感到吃惊。在介绍过自己是如何把事情搞砸后,客户对我们表示了感谢。这样的透明度是一种好事,相比供应商与客户之间传统的互动方式,可以塑造出更富有成效的关系。
业务与工程的融合
过去,很难将业务和工程问题放在一起考虑,因为那样需要花很长时间才能看到相关决策所产生的结果。DevOps改变了这一点。我们希望能在用户首次与我们互动时就提供出色的用户体验,也许用户只是在网上搜索信息,或者试用产品。我们希望在遥测技术的帮助下,与用户的每次接触都能让用户感到满意,我们也会尽可能与主要客户进行一对一互动,借此更好地了解他们的想法。
例如,我们会将每个客户的发展历程看作是一个漏斗,而我们会面临很多漏斗。这个历程可能始于某个网页,通过试用,最终成功使得用户开始在Azure、本地,或其他地方部署。如果在漏斗的任何一个环节我们对成功率不够满意,那么我们会针对改进措施提出假设,对相关变动进行实验,并度量实验的结果。我们会将业务实验与服务其他方面的实验一起评估,例如活动网站、当前和活跃用户的月增速等。我们会谨慎地确保可以关注最可行的度量值,而非那些华而不实的度量值。
我们还发现最好能将度量值与定性的客户反馈放在一起考虑。我们会通过多种方式收集反馈,其中最高级别的接触是“顶级客户项目”。我们会通过这些项目让工程团队的成员自愿地与某个最重要的客户建立联系,大约每月进行一次交流。借助这样的机会,我们可以更清楚客户喜欢什么,不喜欢什么,有什么愿望或困惑等,当然具体情况是不能在这里公布的。我们还有一个主要由MVP以及亲密客户组成的内部“圈子”,我们会大约每周一次与他们通过在线会议分享想法。他们会对假设阶段的场景发表自己的看法,通常这会以故事板的形式进行,并会在实际执行前很久就开始对优先处理的工作发表意见。此外我们还有uservoice.visualstudio.com 等渠道,供所有人提供建议并投票。
经验:卓越与否用实践来证明
随着接受DevOps,我们需要从七个实践领域对具体的成长进行评估,我们大家都认为这已经是“新时代的敏捷”。
图17:在掌握DevOps的过程中,我们试图通过七个实践领域进行持续的完善和改进。
敏捷的调度和团队。这一点与敏捷是相同的,但更轻便。涵盖多个领域的功能小组从一个通用的产品积压工作列表中领取任务,通过尽可能少的工作完成整个流程,并在每个冲刺结束后交付可供部署的成果。
技术债的管理。任何技术债都蕴含风险,最终会导致各种计划外工作,例如可能干扰计划内交付的线上问题。我们会慎重对待任何类型的技术债,并会通过周密的安排在它们影响到所交付的服务质量前顺利解决。(偶尔可能会判断失误,例如上文讲的VS 2013发布之前遇到的情况,但我们会通过沟通尽可能维持透明度)。
价值流。这意味着按照对客户的影响决定积压工作的优先级,专注于为客户提供价值。原本的敏捷方法中我们经常会谈到这一点,但直到现在,通过DevOps遥测机制,我们才可以度量这样做的成功与否,以及是否需要调整方向。
基于假设的积压工作。在使用DevOps前,产品负责人会根据有关人员的最佳反馈“美化”积压工作列表。但现在我们将积压工作视作一种假设,需要将其转变为实验,因此需要收集能够支持或减少这些假设的数据。我们会根据证据来决定后续的积压工作,以及到底是坚持进行(更多工作)还是尝试(其他不同的思路)。
证据和数据。我们对一切进行了监控和数据收集,不仅仅是为了了解运行状况、可用性、性能,以及有关服务质量的其他指标,这也是为了更好地理解使用情况,并收集与积压工作的假设有关的证据。例如,我们会对有关用户体验的改动进行实验,衡量对漏斗转化率的影响。我们会对不同用户群的使用情况数据进行对比,例如工作日和周末使用情况,借此假设出每种情况下可以继续改善体验的方法。
生产为先的心态。只有服务质量始终卓越,才能得到可靠的数据。我们会不断追踪线上网站的状态,对造成各种问题的根源进行补救,主动发现性能方面的异常,并判断造成这种情况的原因。
为云做好准备。只有对架构进行持续完善,重构为更独立、相互分离的多个服务,并借助公有云灵活的基础架构,才能提供24x7x365不间断运行的服务。如果需要更多容量,可以从云(我们使用了Azure)中获得。我们开发的每个新功能都首先以云端为主,随后才会被纳入本地运行的产品,仅有少数有意为之的例外情况。于此同时,我们可以确信自己的产品经过了大范围的加固,并能通过客户的坚持使用获得持续不断的反馈。
参考:
1. 相关详情回顾请参阅:http://blogs.msdn.com/b/bharry/archive/2013/11/25/a-rough-patch.aspx
2. 具体范例可参阅 Gartner ALM Magic Quadrant
3. Ries, Eric (2011), The Lean Startup.
4. Liker, Jeffrey (2003), The Toyota Way: 14 Management Principles from the World's Greatest Manufacturer
5. 参阅:http://aka.ms/redblueteam
6. https://msdn.microsoft.com/en-us/library/dn589784.aspx
7. http://techblog.netflix.com/2012/07/chaos-monkey-released-into-wild.html 以及http://blog.smarx.com/posts/wazmonkey-chaos-monkey-for-windows-azure
8. http://en.wikipedia.org/wiki/5_Whys
9. 示例:https://social.msdn.microsoft.com/Search/en-US?query=outage&beta=0&rn=Brian+Harry%26%2339%3bs+blog&rq=site:blogs.msdn.com/b/bharry/&ac=4
原文:https://mp.weixin.qq.com/s/avcAo1XtY71H_ItJNhL6EQ
以上是关于大规模开发团队如何实现DevOps转型? 来自微软全球开发平台工程团队的实践经验的主要内容,如果未能解决你的问题,请参考以下文章