阿里DevOps转型之后,运维平台如何建设?
Posted 51CTO技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里DevOps转型之后,运维平台如何建设?相关的知识,希望对你有一定的参考价值。
阿里巴巴 DevOps 转型之后,运维平台是如何建设的?阿里巴巴高级技术专家陈喻结合自身对运维的理解,业务场景的分析和业界方法论的一些思考,得出来一些最佳实践分享给大家。
“我是这个应用的 Owner”是阿里巴巴 DevOps 转型的重要策略,运维有了这个策略以后,PE 大量的日常工作就可以释放出来,会有更多的时间去思考沉淀,去做编码,去做以前不曾做的事情。
运维的三个阶段
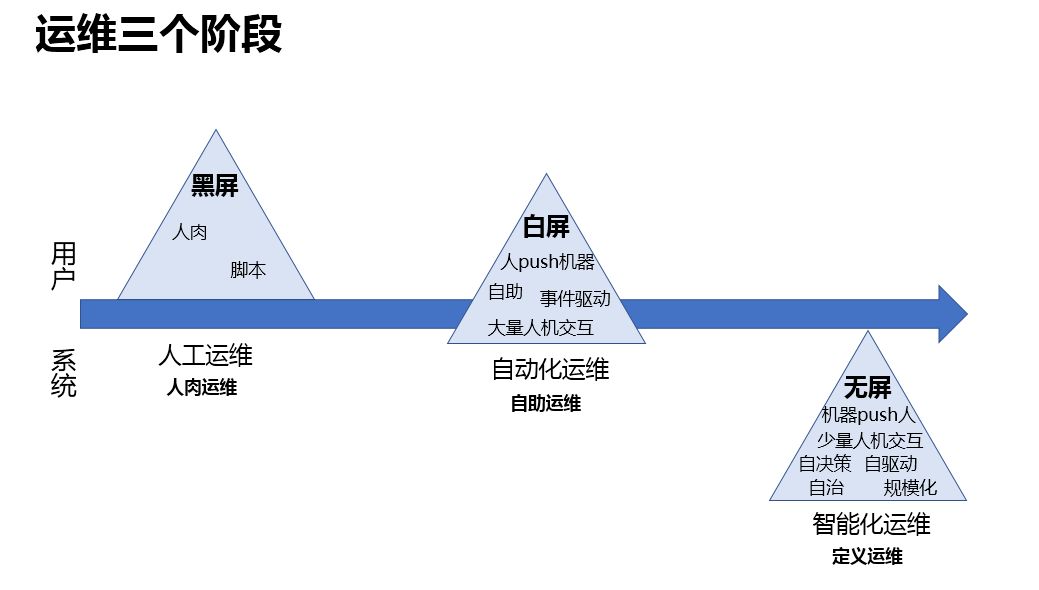
运维的三个阶段分别如下:
黑屏,人工运维,三角形是代表整个运维给用户的一些体感或者给研发的体感,目前很多企业可能还是这样。
白屏,自动化运维,以前把脚本做成工具去弄,有什么特征,人 push 机器去干活,自助运维。
无屏,智能化运维,用户对运维体感很少,但是运维这个领域是不变的。最重要的是人机交互变少了,无屏虽说是不可能的,非常极端,但是个趋势,少量的人机交互,它有自决策、自驱动。
自动化运维基础
做自动化运维,我认为有四大基础:
运维标准与规范。我们的标准有什么好处,让研发 follow 这个标准,标准会在工具里固化。
泛监控,运行时,静态,数据化,可视化。泛监控,不是说传统的监控,是把线上想知道的一切都数据化,最终数据不是给人看的,是给机器去消费的,数据是我们的生产资料,不是可视化,那不是我们的目标。
CMDB。CMDB 应该放什么,一般放服务器相关的、网络相关的、应用相关的这三个维度的相关信息。
经常有人会说 CMDB 不准,数据不准是因为没有把数据生产和数据消费形成闭环,如果形成了闭环数据不准,那是因为你不用这个数据,所以不准。
高效的 CI/CD/CD。我们一定要具备快速的交付能力,主要体现在两个方面:第一,新开发的能力能不能快速上线;第二,想扩容一台机器能不能快速扩出来。
上面两个能力抽象出来,有如下三块:
持续集成(CI),很多人说持续集成工具不好用,效率低,其实持续集成的本质是要自动化测试。如果研发部不具备自动化测试的能力,持续集成怎么做都是失败的。
持续集成里最重要的一点就是要推行单元测试、集成测试还有系统测试。单测是保证自己没问题,集成测试是保证跟上下游没问题,系统测试是保证整个系统没问题。
持续交付(CD),有很多人说持续交付本质是一个 Pipeline,CI 的目标是什么?快速正确打一个包出来。CD 的目标是什么?能够快速把一个包在不同的环境验证它是 ok 的,可以放到线上去,这就是持续交付要干的事。
持续交付里很关键的一点我们要解决,就是它的环境一致性、配置一致性。环境一致性可以用 Docker 解决,Docker 本身就是一种标准化的东西。
所以说第一条用 Docker,肯定是标准化的,另外一个问题,配置是不是一致,是不是动静分离。
持续部署(CD),是一种能力,这种能力非常重要,就是把一个包快速部署在你想要的地方。
持续部署有如下三个痛点:
对包的文件的分发,阿里有一个叫蜻蜓的产品,是做了 SP2P,在 P2P 的基础上加了一个 Super。
应用启动,很多应用启动的时候要两三分钟,这是很有问题的。
部署起来以后这个业务是不是正确的,大家一定要做一个 HealthCheck,不是运维做,是 PE 做,一定要把这个要求说出来,执行 HealthCheck 这个脚本。
运维系统的重要特性
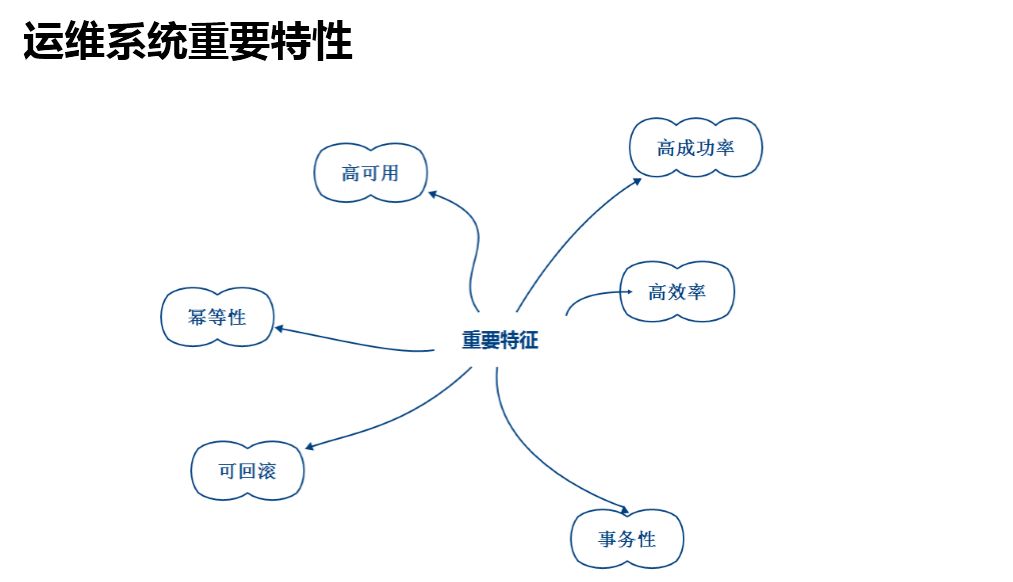
中间件研发首先关注稳定性,其次是效率,然后是易扩展。运维研发里面的六个重要特征,每一个都非常重要,以下是我感触比较深的几个:
高可用,在做同城容灾演练的时候,我把关一切,结果发现运维系统挂了,救命的东西没有了怎么办?所以说运维系统一定要高可用,不一定是高并发。
幂等性,幂等性是分布式系统设计中十分重要的概念,也非常重要。
可回滚,这个是做运维最基本的一个 sense,你做的任何操作是不是可控的。如果真正做可回滚,事情没有这么复杂。
高效率,如果你的企业发展非常快速,你的规模性效应已经来了,你的运维系统一定要具备很高效率,快速扩容、快速部署这个效率我们要追求极致。
研发定义运维,配置驱动变更
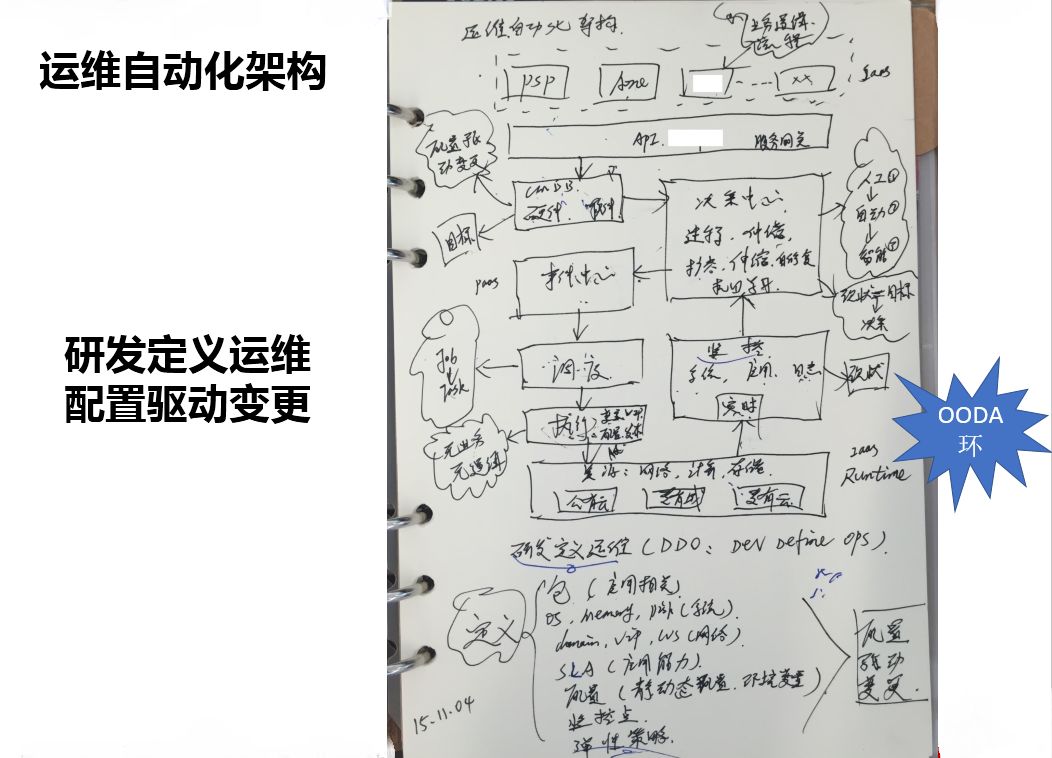
2015 年 11 月 4 日设想的架构图
从最下面看,是我们的基础设施,提供三种能力,包括集散、存储、网络。
从右下角的位置看,画的是一个泛监控,它会知道系统、应用等,在旁边标了一个字,现状,我要通过这个现状把线上的系统全部数据化,然后放到决策中心。
左上角有 CMDB,现在很多变更系统,很多强调流程。我本人是做研发出身,非常抵触流程,流程不是一个效率工具,它是阻碍效率的。
比如故障搞完以后就是一堆的流程,非常阻碍效率,是质量控制的一个工具。流程不是不要,是把流程做到系统里面去,让系统帮人做决策,而不是人在那里点。
CMDB 定义了我刚才说的目标,现状通过监控拿到了,目标也知道了,这个时候还觉得这个事情很复杂吗?
我认为这看你怎么去做。想做成人工还是做成自动或者做成智能,都取决于这个地方。所以智能里一定要有数据。
举个例子,通过智能分析出目标状态是使这个应用有 100 个 VM,但是现在状态只有 80 个,一看这两个不一样,要扩容 20 台,如果系统做得更智能一点,通过图上左边的事件中心提示我 20 台负载较轻的放在哪,可以调度过去,然后去做执行变更。
基于这些东西得出来两个结论,“研发定义运维”,“配置驱动变更”。
为什么是研发定义运维?
研发定义运维(DDO),研发最贴近业务,最应该清楚这个业务应该具备什么样的能力,只有研发才知道这个业务 KPS 是多少。
为什么是配置驱动变更?
配置就是把目标改变一下,你跟我说一个运维场景,我可以在这个图里面 run 起来,配置只需要改你的目标状态,比如把你的状态 10VM 变成 15 个 VM。
这就是“研发定义运维,配置驱动变更”前因后果的思考。
运维工具与方法论
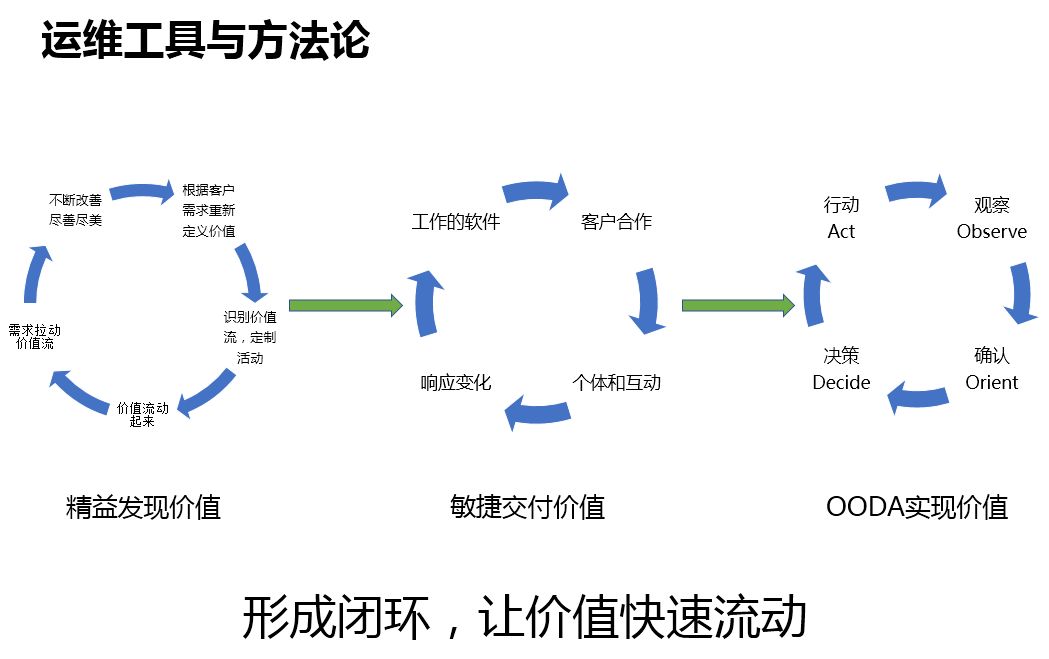
精益发现价值
价值来源于用户的需求,而不是自己的 YY,我们的价值来源于用户。
精益对我最大的感触就是要发现价值。精益思想,什么东西是有价值的,能够对用户带来物质上的或者身体上的愉悦的东西就是有价值的。
今天也有人问,DevOps 团队是该拆还是该合,我想他应该首先弄清楚面对的是什么样的问题,问题的优先级是什么?如果只解决一个问题,也许并不是 DevOps 团队拆不拆的问题。
敏捷交付价值
敏捷也是对我影响很多的。很多人谈敏捷,我们团队里也搞敏捷,敏捷是要快速交付价值,它是一系列的方法论。
但是在引入的时候千万注意,别人行的东西你不一定行,你需要的东西并不一定是敏捷,要因团队而异,形成一个环,持续反馈。
OODA 环
OODA 环,就是形成闭环,让价值快速流动。
应用运维平台 ATOM
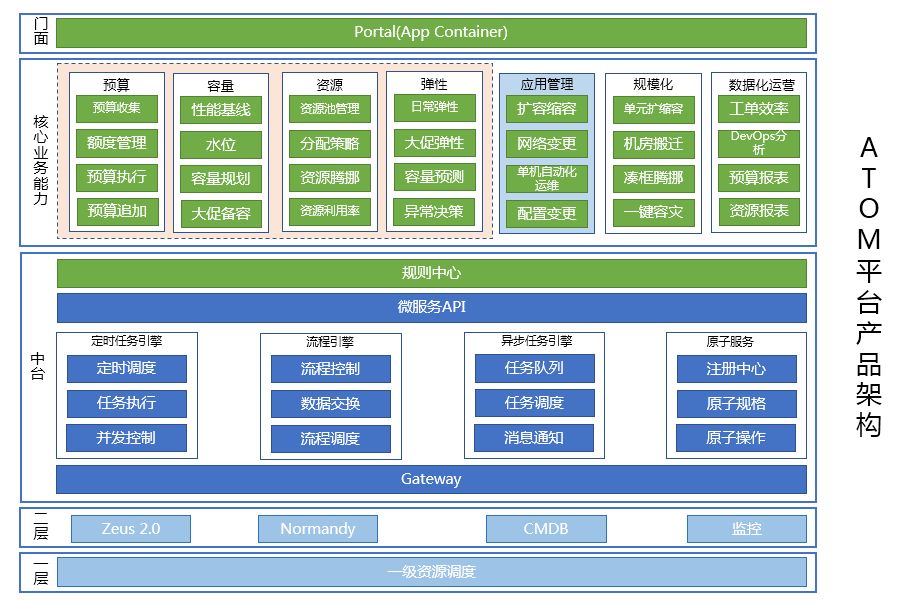
应用运维平台的基础设施是一层,二层是运维中台,最上面一块是要做的 PaaS 平台,这个平台分为如下三步:
预算、容量、资源、弹性。这个是 PaaS 平台上非常重要的一块,目的就是让资源快速流动起来,流向正确的方向来产生价值。资源如果常年不增不减,是有问题的。
应用管理。这是日常要做的操作,规模化,要快速对一个单元建站、扩容、缩容。
数据化运营。一定要讲数据,数据不是可视化出来一些报表,是要给结论,告诉用户这个数据完了以后应该是什么,规则中心是什么,是所有运维同学日常的运维经验沉淀。
批量腾挪工具

这个工具不是所有人都需要,可以解决机房的搬迁,凑框迁移。
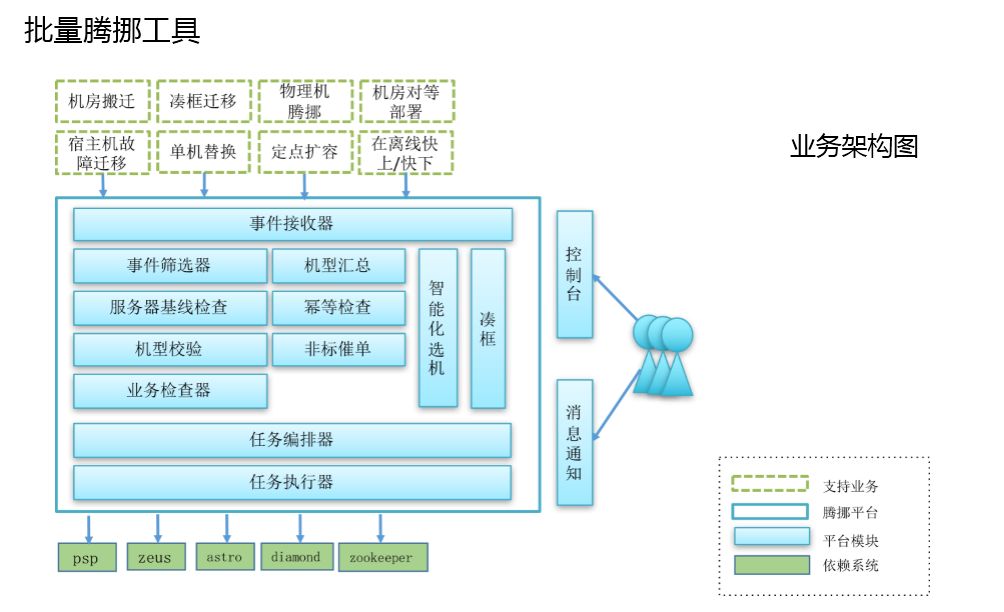
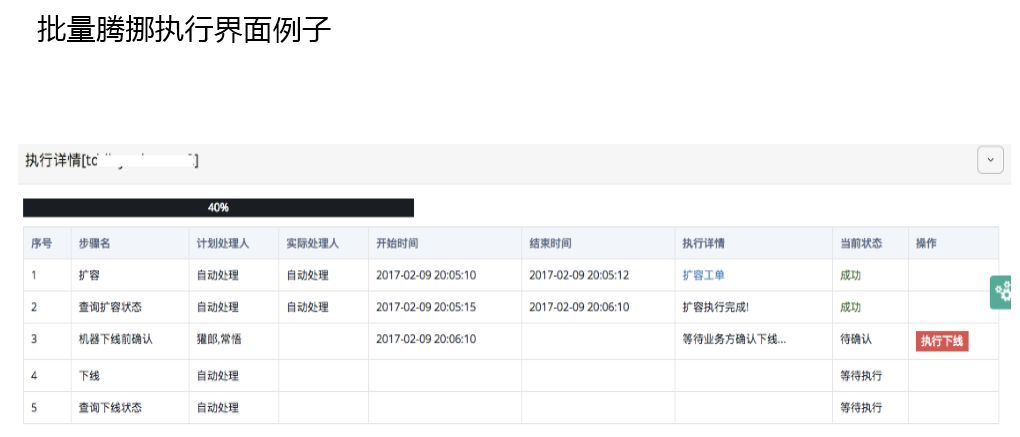
单机闭环,这是腾挪工具的关键,如果企业有一定规模,这个是需要的。
弹性伸缩工具

弹性伸缩是我们的决策中心。它决定你的资源往哪个地方流,非常关键。
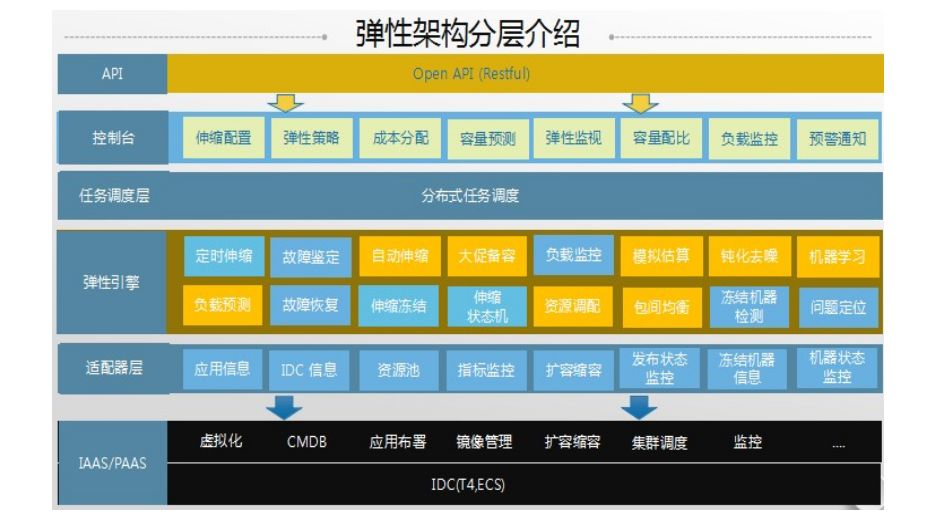
最后,这里是运维领域技术含量最深的一个地方,要搞机器学习、深度学习、强化学习、算法等。
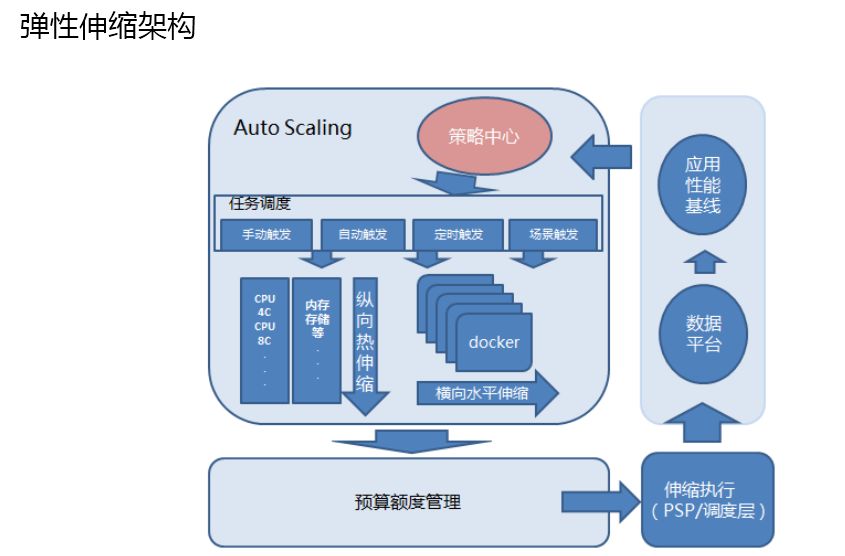
弹性伸缩架构,这个平台不一定很多企业都需要,这里主要介绍在双 11 的时候是怎么用的。
建一个站点起来只有 5000 的交易能力,可以通过 10 分钟时间让它具有 30000 万的能力,快速决策,快速调动起来。
弹性里面是一个 OODA 环,拿它的数据和应用极限做比较,得出来一个策略中心。
弹性一般有水平伸缩、垂直伸缩,对线上做管理,当然我们有额度,这是比较精细化的管理。
弹性有观察者模式还有自动化执行,每次弹性完以后有一个控制台,双 11 做全年压测的时候一般情况下不看这个。
实施效果
我们的展望,PE 转型以后,希望让研发来使用我们的运维,降低他运维的复杂度,降低运维的门槛。
我们是通过系统化的方式来做,研发只需要把他的目标写出来,让运维这个东西像山一样沉下去,感知不到。
然后是资源的闭环。规模化,现在 PE 做两大块,第一是规模化运维,然后是单应用运维,很多人理解把线上系统发布到线上去,扩容几台,这就是单应用运维。其实我们应用的蓝海是规模化运维,这会涉及到方方面面的事情。
简介:阿里巴巴高级技术专家。2014 年入职阿里负责持续集成持续交付平台研发团队,2015 年调入运维团队,负责交易运维、无线运维 2 个团队,带领团队保障日常运维及双 11 大促运维。2016 年开始负责 Sigma 弹性&资源运营团队,主要领域为集群弹性,应用弹性,资源运营,规模化运维,支撑双 11,在 2016,2017 连续 2 年获得双 11 卓越贡献奖。
编辑:陶家龙、孙淑娟
精彩文章推荐:
以上是关于阿里DevOps转型之后,运维平台如何建设?的主要内容,如果未能解决你的问题,请参考以下文章
聚美优品胡俊:自动化运维平台的建设经验 | UPYUN Open Talk No.25
Apsara Stack 技术百科 | 浅谈阿里云混合云新一代运维平台演进与实践
Apsara Stack 技术百科 | 浅谈阿里云混合云新一代运维平台演进与实践