外包环境下的 DevOps 实践
Posted DevOps时代
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了外包环境下的 DevOps 实践相关的知识,希望对你有一定的参考价值。

作者介绍:黄倚霄,来自广东移动。江湖人称“岛主”。
1. 面临的挑战
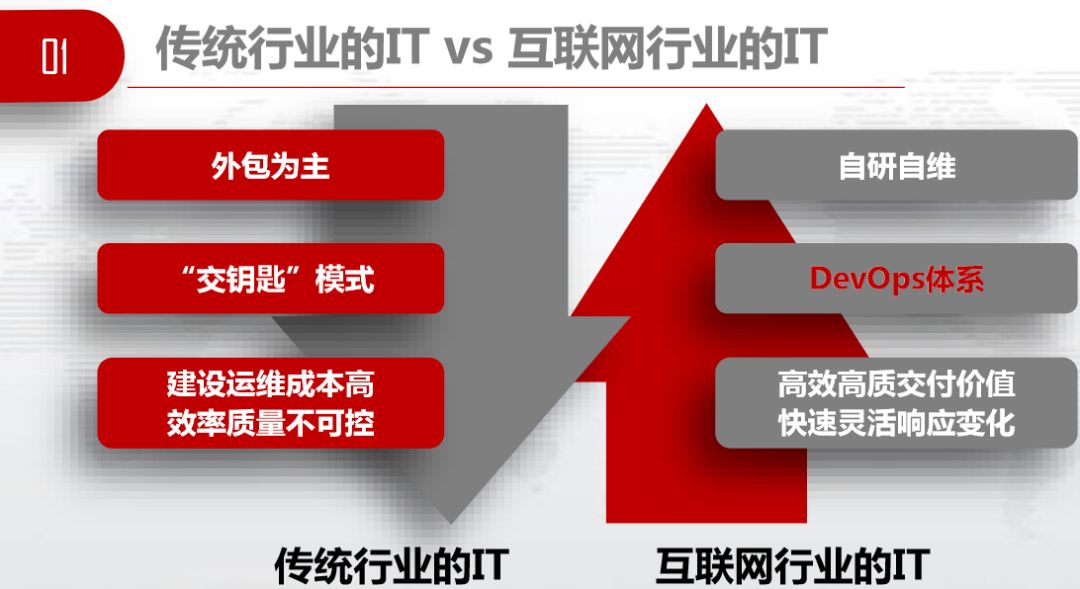
今年的2018GOPS·深圳站设了金融和通信专场。因为金融和通信行业面临着互联网最大的冲击。有了微信和QQ,谁还发短信?有了支付宝和微信支付,谁还随身携带银行卡?这些是互联网行业对金融和通信行业带来的冲击。传统行业和互联网行业差别巨大,我暂且不谈体制上、流程上、管理上、人员上的差别,今天我们谈谈IT上的差距。

传统行业以“交钥匙”模式为主,厂家开发完成后,拿包过来现场部署。运维成本高尚且不说,毕竟花的是国家的钱,最麻烦的是效率和质量特别差。对面的互联网行业主要是自研自维,他们用的是DevOps体系,高效高质的交付,灵活地应对变化。
2. 实践DevOps的道路选择
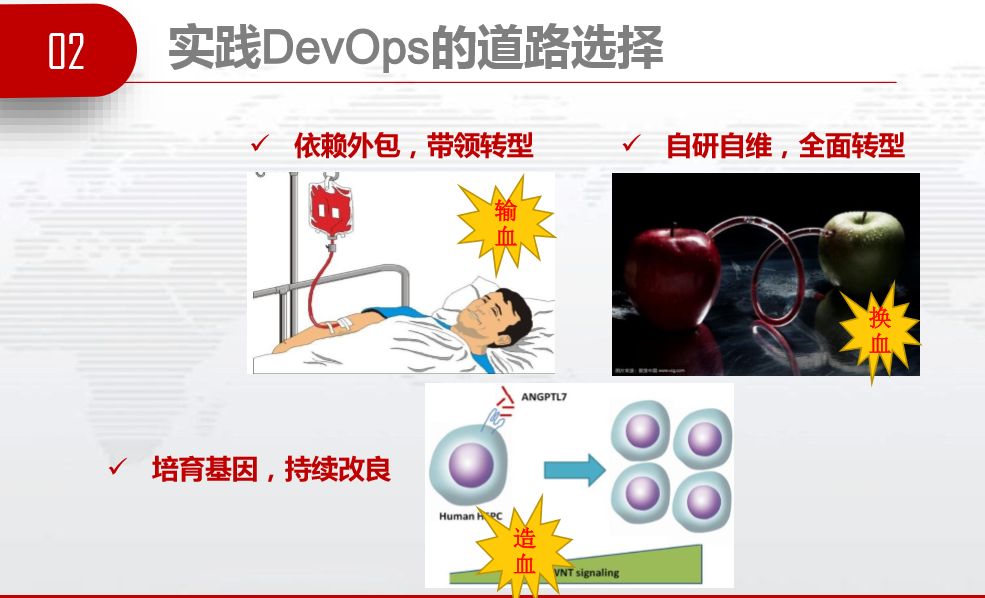
如何学习DevOps体系,有不同的选择。有些国企、传统行业选择依赖外包,希望通过外包带动我们转型。这就像“输血”,把外部新鲜血液输入到传统企业里。“输血”很好,可以解燃眉之急,但我们不能一直依赖它。
自研自维的全面转型,我们称之为“换血”,运营商在推全面IT化、数字化转型,招一大批计算机专业的新员工,组织大量的IT培训,希望可以学习自主研发,自己运维整个网络体系和IT体系。这是一个很好的愿景,但同时它是很难实现的。在实现过程中,可能会面临很多坎坷。所以我们选择了培育基因,持续改良这条“造血”之路。
3. 技术的实践
3.1 选择普适、完备的体系来对标学习
培育基因,总得有基因,基因从何而来。每个互联网行业都有自己的特性,也有其成功之处,难以全盘复制。所以我们应该找普适完备体系,我向大家推荐两个比较好的体系,一是高效运维社区的DevOps道法术器,二是中国信息通信研究院的《研发运维一体化能力成熟度模型》。
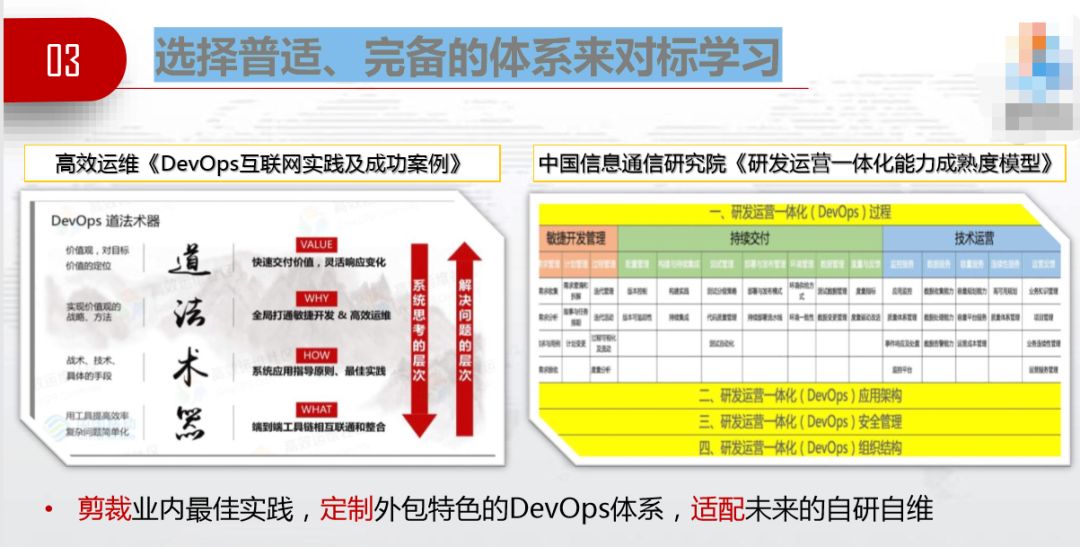
道法术器,中国风特别浓,我文化水平不高,不太敢学,还是来学国标吧。
中国信息通信研究院DevOps模型,当中包括42个过程,难以全学。比如敏捷开发管理,传统行业之前以外包为主,外包哪有敏捷开发,你连代码都没有。
“在瓶颈之外的任何地方作出的改进都是假象”—艾利•高德拉特《目标》
3.2 选取六大过程,优先解决痛点
我们需要从42个过程中选取切入点,用来解决目前的瓶颈和痛点。广东移动选择了以下六个过程作为切入点,
一是故事与任务排期,管理需求的涉众期望;
二是部署与分布模式,痛点是改进版本上线效率;
三是应用监控,为了解决故障定位慢的痛点;
四是事件响应及处理,解决的是故障处理的痛点;
五是高可用规划,提升系统可靠性;
六是度量指标,定性定量评估DevOps转型效果,持续优化。

3.3 选取六大过程,优先解决痛点
3.3.1 第一个过程——故事与任务排期
传统行业IT管理部门经常被用户部门投诉:半年过去了,我提的需求怎么还没开发。厂家很痛苦,个个都是大爷,随时随地加塞需求,个个都说自己的需求最紧急,我敢得罪谁?我们作为IT管理的角色,也很无奈,年初问大家有啥需求,个个不提,年中个个说急。比方说,集团2、3月份开工作会,1月份立项,立项时没需求,开完年度工作会提出一堆的需求。老板很困惑,到底是厂家不给力还是我们管理水平差,为什么大家都不满意。我们的药是管理好各方期望。我先声明一下,这个药并不能提高需求交付的速度,那个要等全盘引入DevOps敏捷开发体系才能解决。在DevOps体系还没落地之前,我们先管好各方期望,先让用户和老板不那么痛苦,我们自己也不那么痛苦,先缓解痛苦了,再考虑后面的改进。

需求管控分成两部分,一个是年度资源的管控,也就是制定年度版本发布计划。关键点是“排车次,分车票”。年初工作会还没开,我们可以根据项目金额和人天单价估算,估算全年可用的人力资源,假设有1.2万人,制定全年版本的分配计划。有点像列车时刻表一样,需求在哪天截止、哪天受理、哪天排版、哪天上线。分配各版本的资源数量,根据全年闲忙规律安排各个版本的资源数量。12个月里,并不是每个月都平均分配,年底特别忙,需求特别多,我们要为第三第四季度多安排。分配用户的资源比例,不是平均分配,要看谁对系统要求提得多。去年这个部门提出60%的需求,来年我给他们分60%的资源,年初分车票,用完车票只能等着,要不就只能向其他有车票的人协调。预留10%的机动资源,紧耦合系统功能要统一发车时间。
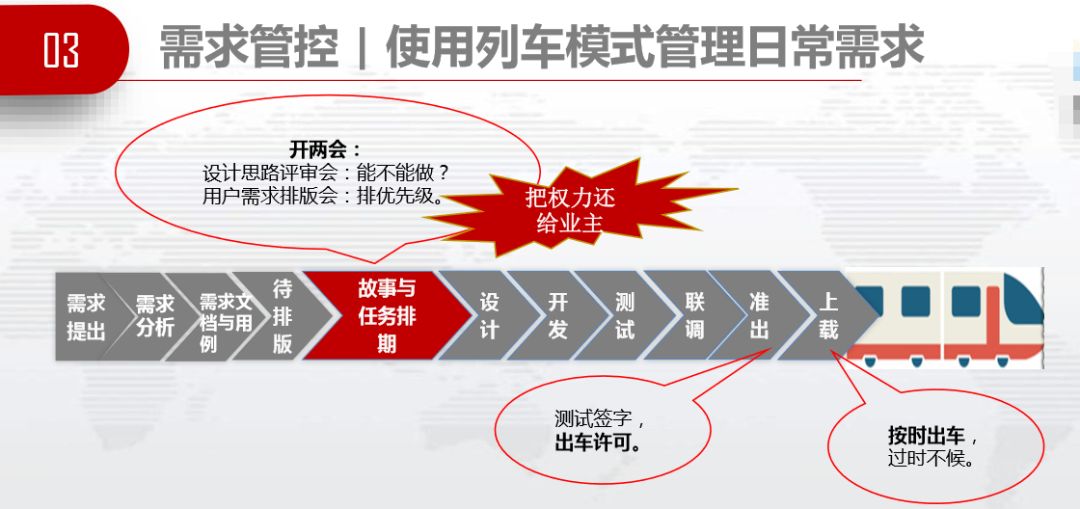
管好期望,皆大欢喜。大家知道发车时间表,用户知道他有多少资源可以,安排时不会乱提,不会毫无成本的提需求,开发者也知道自己要做什么事情,不会所有需求都是紧急需求。

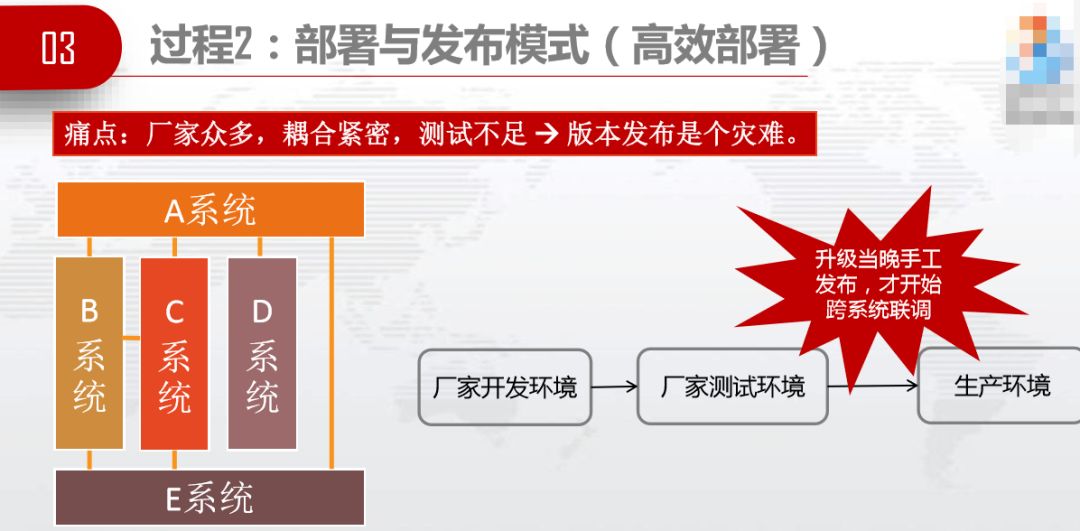
3.3.2 第二个过程——部署与发布模式
(下图)这是广东移动实际的系统关系图,耦合得非常紧,A系统发布,B、C、D得联调。一个厂家熬夜,其他厂家要跟着熬夜。我们升级当天晚上才开始跨系统的联调,所以版本发布是个灾难。
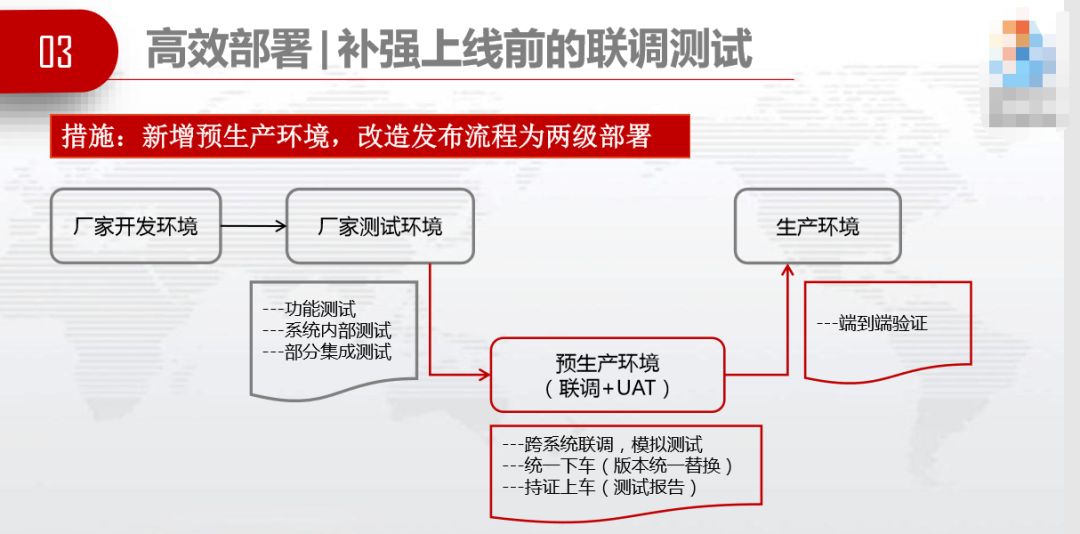
如何解决此问题,我们的措施是新增预生产环境,改造发布流程为两级部署。预生产环境做的是跨系统联调、模拟测试、统一版本替换,最后统一到生产环境上。预生产环境可以白天做,合作伙伴和同事都不用再那么辛苦熬夜值班割接了。
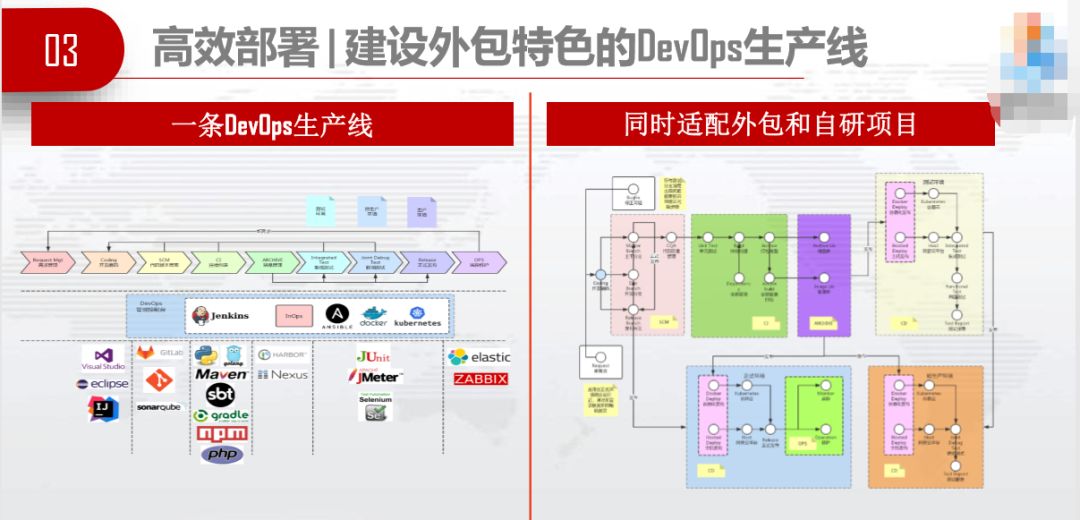
在我们做高效部署的过程中,我们向腾讯蓝鲸学习,本图由腾讯蓝鲸的运维自动化发展历程来。我们给自己定了目标,基准目标是跟厂家的软件发布包标准化,参数的配置文件标准化,升级流程标准化。挑战目标也有,厂商可以根据自己的技术实力,开展数据库脚本自动化、整体发布脚本化、用DevOps生产线驱动的自动发布。

厂家做的自动发布并不是让他们做一个自动发布的网站和系统,我们完全可以从DevOps体系中获得养分。(左图)参加过DevOps大会的都很熟悉,这条生产线本身就能做发布,只要引入就好了,不用新建。当然,为了适配外包模式,我们对生产线也做了一些改造,让它同时适配外包和自研项目。这边是外包项目,这边是自研项目。有源代码的走这条路,没有源代码的走那条路。
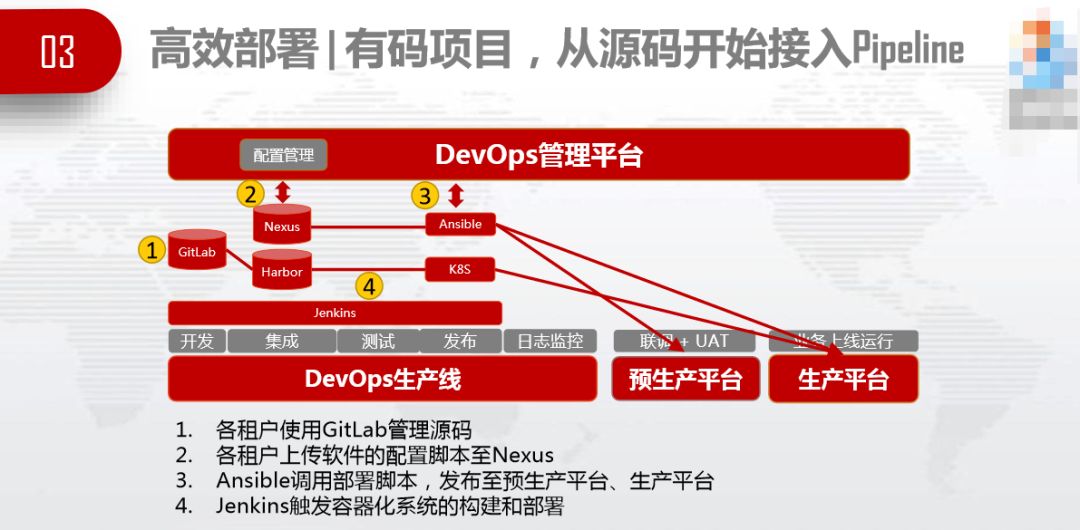
无码项目(无源代码缩写),从制品开始接入Pipeline,编译好的包上传到Nexus,由DevOps生产线驱动部署。
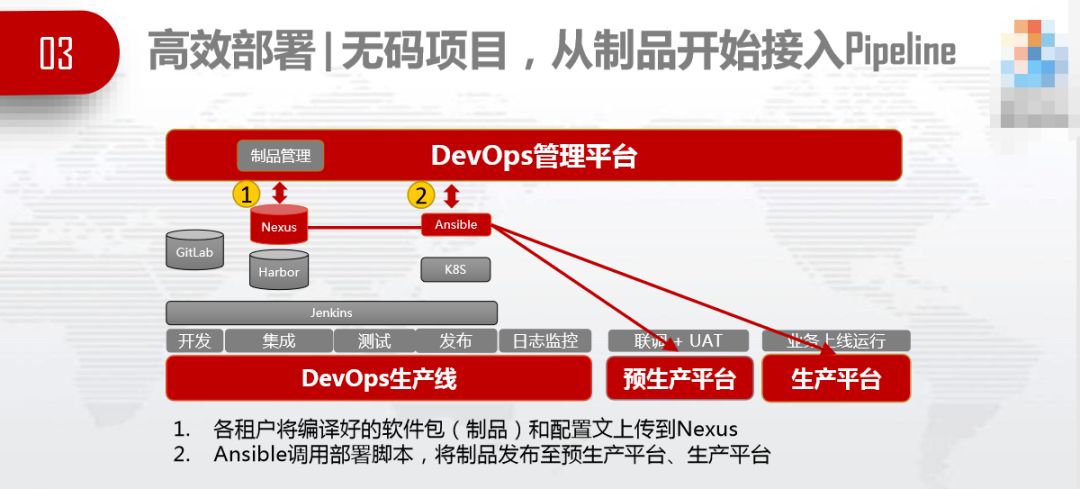
有码项目,各租户使用GitLab管理源代码,合作伙伴可以在自己的软件中心工作,不用到甲方现场,就可以将产品在pipeline上进行编译、测试、部署、发布到生产平台和预生产平台。
3.3.3 第三个过程——应用监控
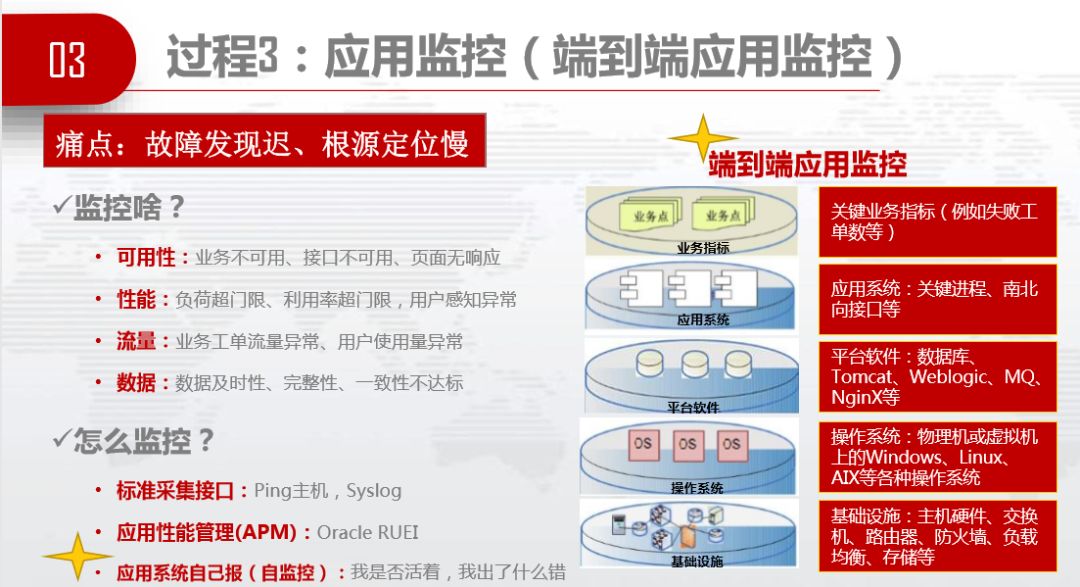
痛点是故障发现迟,根源定位慢。为了更快发现和定位故障,必须要开展应用监控,监控啥?可用性、性能、流量、数据质量。怎么监控?一是通过标准化采集接口,采集主机的负荷、指标、状态等,二是应用性能管理,我们用的是Oracle RUEI,三是应用系统自己报,要解开应用的黑盒子,只能让应用自己报。我们这里做的比较大的创新是端到端的应用监控,我们现在要把各层的应用监控串起来,成为端到端的业务监控,使得定位更加方便。
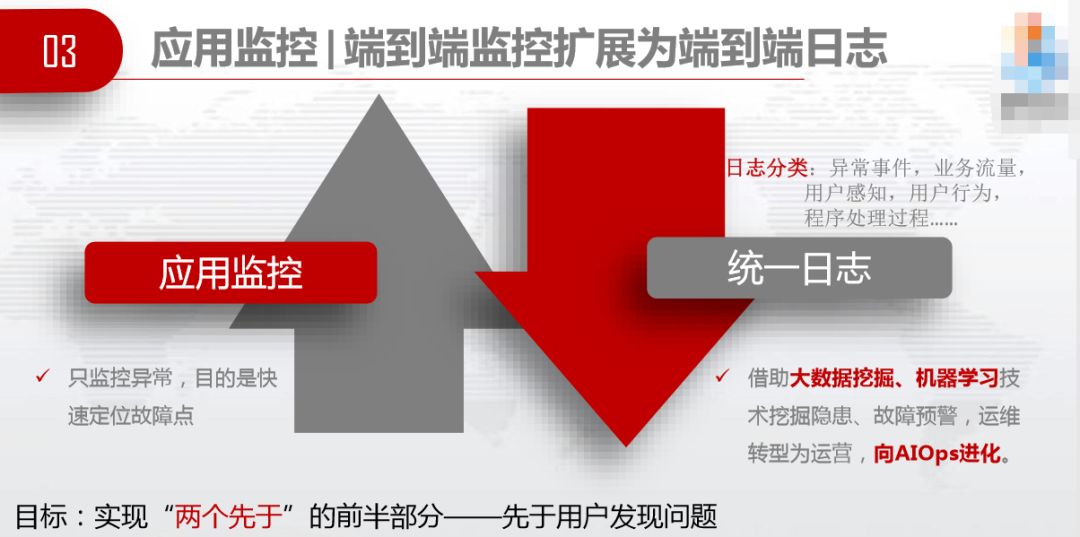
本次DevOps主题是AIOps,接下来我们要从应用监控扩展到统一日志。应用监控只是监控异常,目的是快速定位故障点。统一日志是借助大数据挖掘、机器学习技术挖掘隐患、故障预警,使得传统运维可以向运营转型,也向AIOps进化。我们的目标是做端到端监控、日志,目标是“两个先于”前半部分,一是先于用户发生问题,二是先于投诉解决问题。
3.3.4 第四个过程——事件响应及处理
痛点是故障修复忙乱,只能围观,束手无策。问题根源在于这哥们两次故障都穿绿色衣服,我们让他把这件衣服扔了,以后就再也没有故障了(开玩笑)。
运维工具脚本化傻瓜化智能化,具体措施是访谈厂家运维人员,问他们,常见故障有哪些?他们是怎么处理的?厂家运维人员说,接口拥塞、卡单、缺数、应用进程吊死,解决方法是手工过单、开启限流、增开服务器、手工补数、手工重启等。我们继续问,能否做到脚本化、傻瓜化,能做到给他们加分。傻瓜化之后,继续探索智能化。
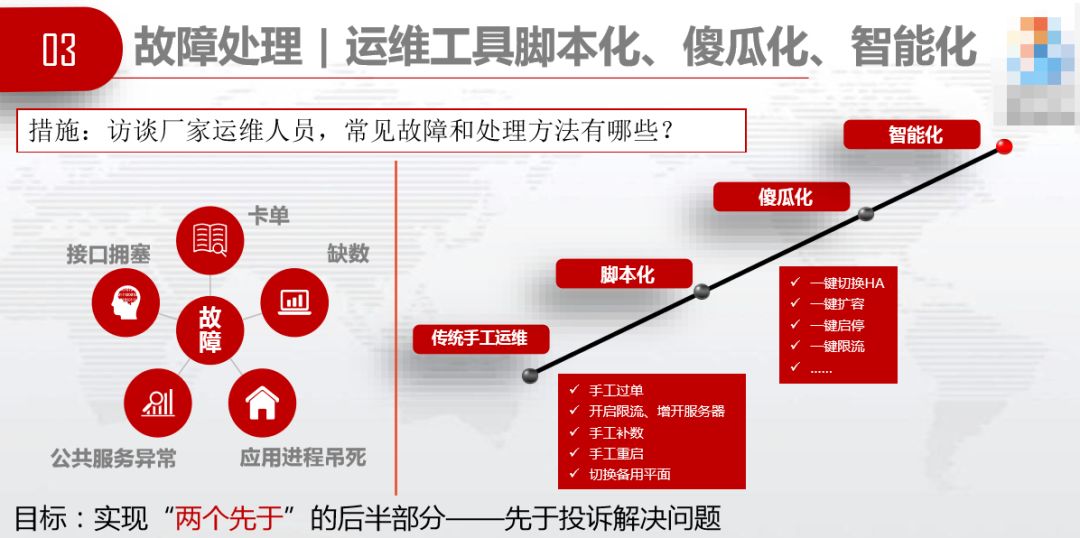
3.3.5 第五个过程——高可用规划
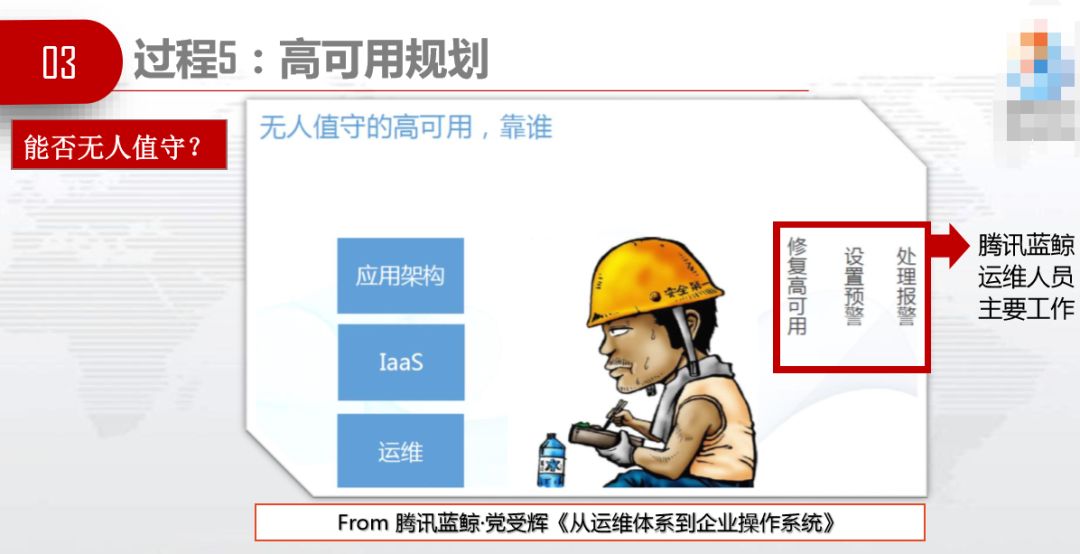
这张图是从腾讯蓝鲸咖啡党那里抄的。腾讯蓝鲸运维人员主要有三项工作,设置预警、处理报警、修复高可用。腾讯蓝鲸不用抢修故障,因为他们IaaS的运用架构是高可用,不需要抢。只需要在出现告警时,切换高可用,有时间再慢慢修复高可用,不用抢修。
运营商能否做高可用改造,上面是互联网行业的软件架构,他们用的是Cloud-Native、Docker、MS、Ceph、SDN,我们用的是集中式IBM SVC、传统三层网络结构、VLAN、VMware。全面重构应用系统自然是治本的方法,但是有困难和风险,我们可以先从部署层面开展HA改造,消除单点,不用改代码,不用中断业务,只需要在部署层面开展。花点钱多部署几套,这是“给飞行中的飞机加装引擎”。

如何做高可用规划,借鉴公众云的可用区,一个可用区出现基础设施故障不影响另一个可用区。每一层都有多可用区,按反亲和原则,业务系统跨不同的可用区进行部署。通过多可用区的部署实现高可用,简单粗暴。
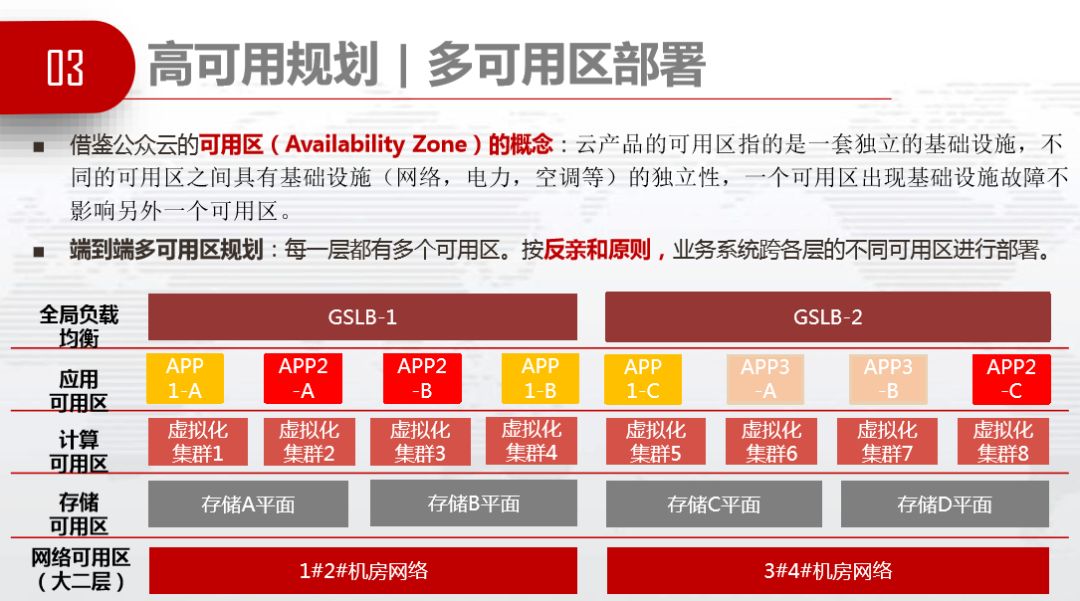
端到端的高可用部署体系有网络高可用、主机高可用、公共SaaS高可用、存储高可用和应用部署高可用。
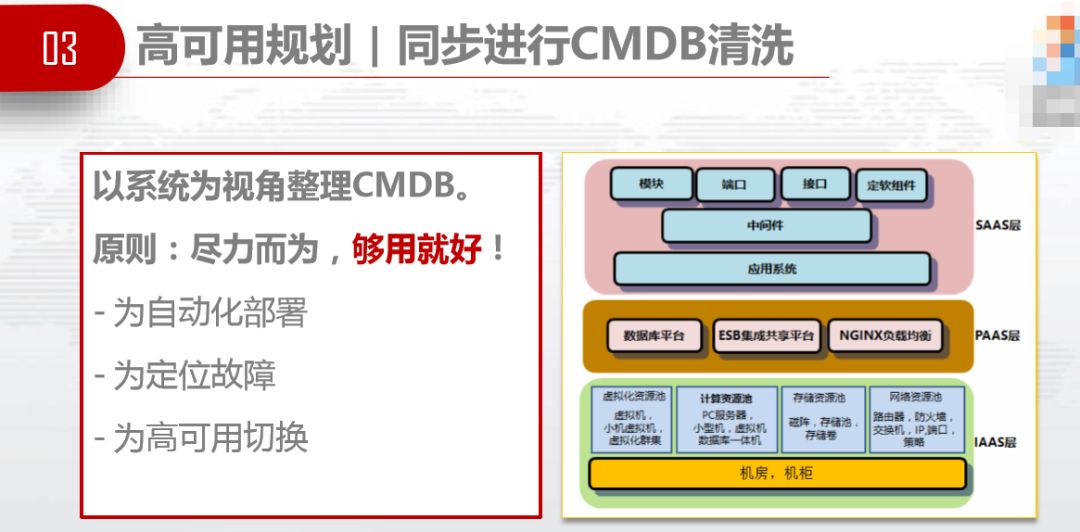
高可用规划的同时,要同步进行CMDB清洗。因为高可用规划必须有CMDB,不然你不知道谁跟谁反亲和。做到什么程度?为高可用切换、为故障定位、为自动化部署做CMDB,不要做大CMDB,够用就好,尽力而为,我们取的是CMDB最小级。
3.3.6第六个过程——度量指标
国企有一个特点,“铁打的营盘流水的领导”,在国企更要注意体系的可持续发展,将最佳实践固化形成企标。应用系统交维标准,必须满足一键部署、一键启停,一键切换HA。数据库编程规范很重要,我们制定了《数据库应用编程的N条军规》,数据库应用要非常重视规范性,否则做更多的高可用都是无效的。IaaS、PaaS、SaaS架构的规范,要求单平面故障时可支撑业务高峰,多可用区部署、反亲和写原则。DevOps工具选型建议,开源原则、主流原则、能力原则。

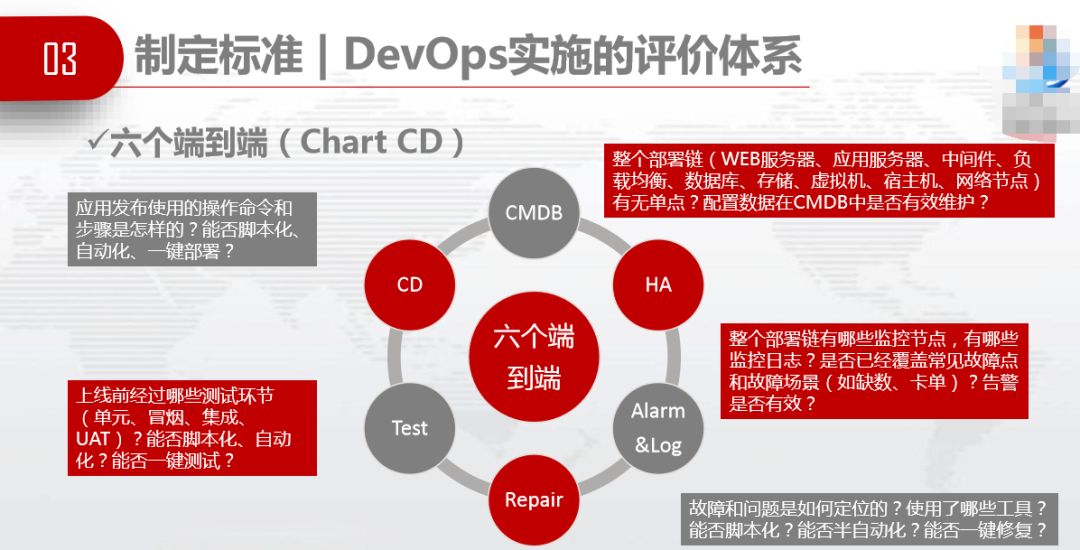
制定标准,DevOps实施的评价体系。六个端到端(Chart CD),端到端CMDB、端到端的HA、端到端的Alarm and log、端到端的Repair、端到端的CD。
4. 管理感悟
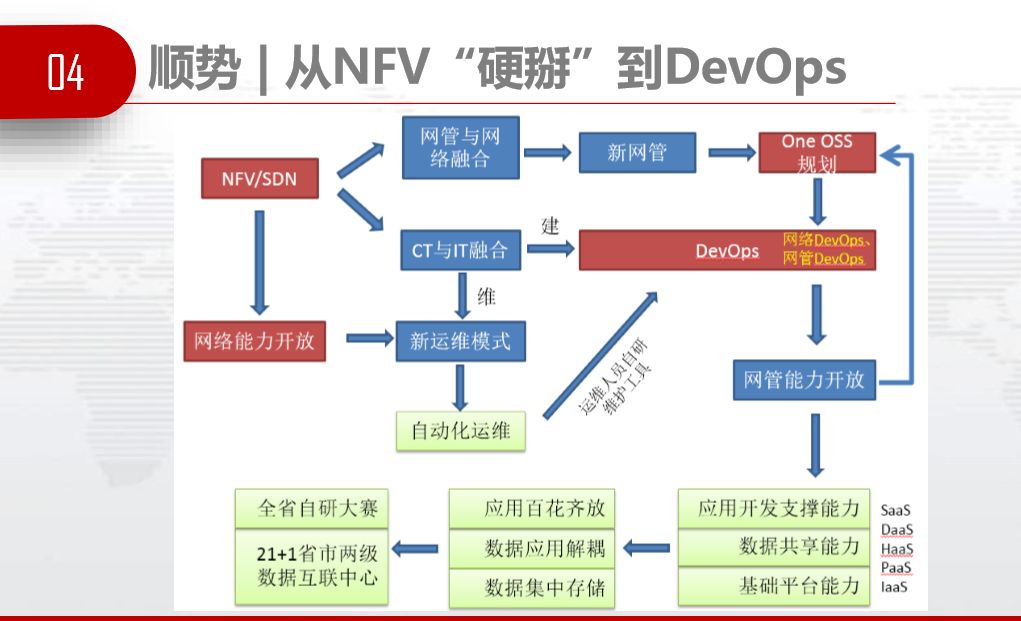
万事开头难,后面结尾也很难。架构还没改变,大家都在观望的时候,可以耐心培育种子,不妨先创造和谐有利的外部环境。我们总结了三个势,顺势、借势、造势。

顺势,运营商最近几年要做NFV,去年、前年时我们想办法从NFV“硬掰”DevOps,如果没有DevOps,根本无法做NFV。
借势,2016年,我还是GOPS的普通观众,只是在会场外边随便找了一个美女合影,结果就跟高效运维社区联系上了。 经过一来二回的联系,去年年底我们在广东移动开了家门口GOPS,请了萧总、乐神、咖啡党给我们领导讲课。实际上是想借势,我说的领导不一定会认同,我可以请专家过来讲。借势,我们要走出去,请进来,请到组织里,成为你的助势。

造势,开始时很多领导认为DevOps是自研,我们办了两届自研大赛,自研大赛的结果是引起老板重视,兴起学IT的热潮,开发了一批小工具,培养了一批IT高手。我们把势造起来,让大家觉得IT不那么难,做网络运维的人也可以写代码。从各大高校招的电信专业、光电专业、物理专业也可以写代码,同时为“换血”打下基础,有人才才可以转型,造势很重要。

不仅如此,今年2月份广东移动还组织了下一代网络智能运维IT技术沙龙,这个沙龙厉害了,主题是让同事上台讲。去年请外面的专家来讲,培育了一年,借足了势,今年就可以自己讲了。我请了计划部、网优、客响等不同部门的专家过来讲。萧帮主说“带着身边小伙伴,一起愉快地玩耍”。一起玩耍,一起造势,把DevOps势头造起来。

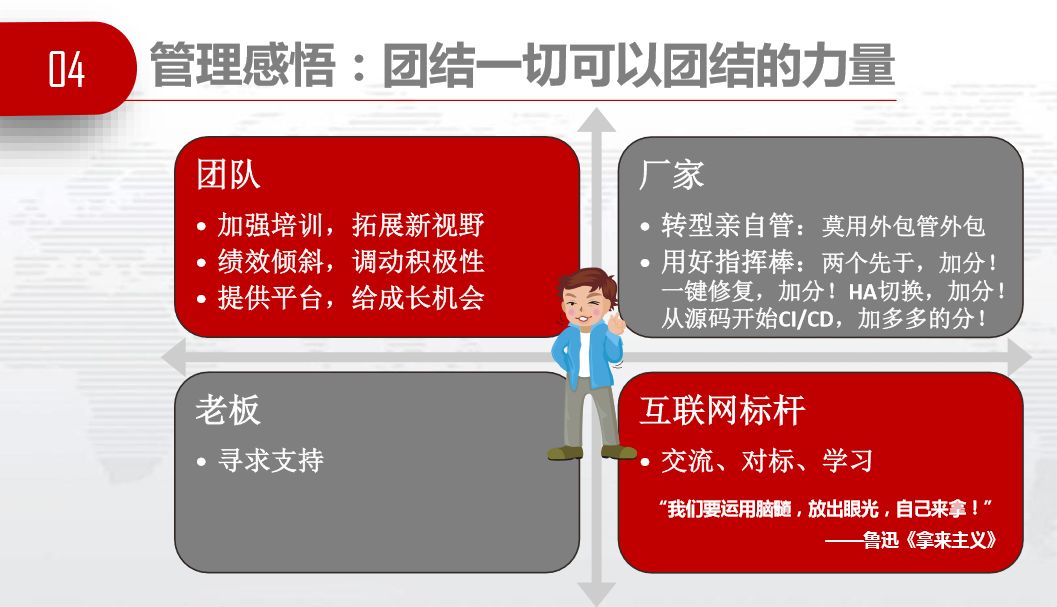
搞定外部环境后,团结一切可以团结的力量。对团队,我们要加强培训,拓展新视野,派去BAT、GOPS学习。绩效倾斜,我们鼓励愿意投身到转型工作中的员工,提供平台和舞台,给成长机会。我们让同事上台讲,对大家的鼓舞很有帮助。
对厂家,转型亲自管,莫用外包管外包。用好指挥棒,能做到两个先于可以加分,先于用户发现问题,先于投诉解决问题。能够一键修复的加分,HA切换的加分,从源码开始CI、CD的可以加分。
互联网标杆,鲁迅先生说过“我们要运用脑髓,放出眼光,自己来拿”。
我们要寻求老板的支持,没有老板的支持,所有事情在国企都是不可行的。
5. 总结
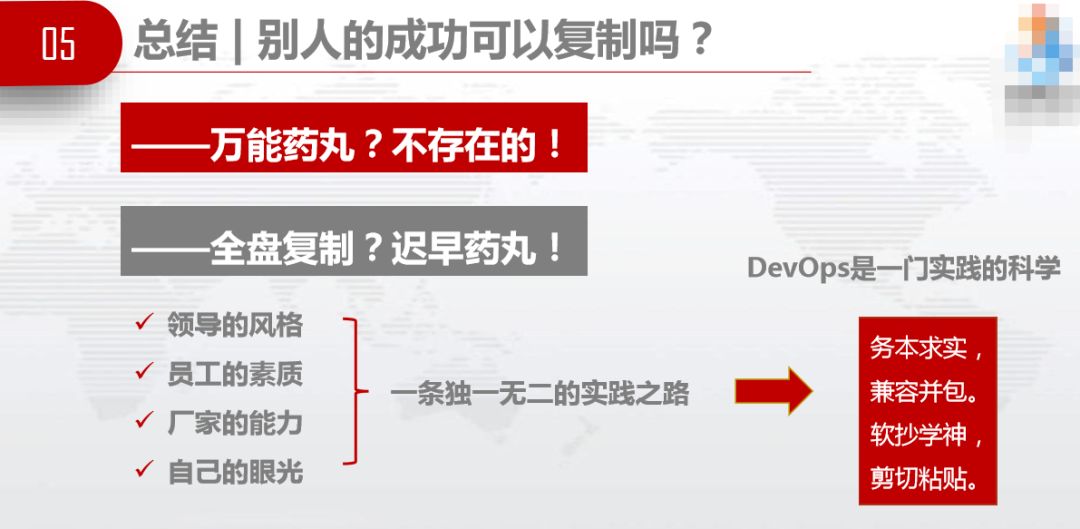
成功可以复制吗?李开复有一本书说《我的成功可以复制》,还有人写《我的成功不可复制》,DevOps转型的万能药丸不存在。领导的风格、员工的素质、厂家的能力和自己的眼光不一样,注定每个企业和团队的DevOps转型之路是独一无二的,必须边走边试边学。我们要务本求实,回归本心,你做DevOps是为了什么。我做DevOps转型是要解救熬夜值班的同事,让他们不用经常熬夜连轴转,这对我们同事来说是很好的救赎。软抄学神,大家可以到各地方学习,不一定要全抄,要学会剪切粘贴。
致敬和祝愿,今年是改革开放40周年,改革开放是从深圳这片土地开始的,根据中国的实际情况制定了发展之路,我们移动DevOps转型也是如此,根据日常生活所做的尝试和实践,我们不是从头做起,我们是站在巨人的肩膀上发展,一是高效运维社区,二是蓝鲸。我们从这两个巨人身上学习到很多东西,一并向他们表示感谢。如果有需要用到我们的朋友,我们随时愿意献出我们的梯子。

6. QA环节
台下:昨天我在问传统企业的DevOps怎么做。第一,DevOps比较关注的是业务价值,您不想让兄弟姐妹那么累,除此之外您做DevOps转型,实现了什么,实现了多少您对老板的承诺。
黄倚霄:我的目标不仅仅是不希望同事们那么忙那么累,我希望DevOps转型可以带来价值。我们网管系统是支撑网络运维,实际上也支撑业务发展,比如代维管理系统,它有很多需求,功能快点上线,对装维师傅的效率很有帮助。这个片子没有谈到您的提问,我们准备在4月份开始把某几个应用系统从源代码开始接入DevOps,放在我们的DevOps生产线上。我们已经成功尝试了一个小工具,原来大概半个月或者一个月更新一次版本,现在每天可以更新版本。我跟老板承诺,下半年实现某些系统交付周期,从一个月变成一天或者一周,这是DevOps给我们带来的业务上的价值。
台下:第二,你们有自研团队和厂家无码团队,你自研的占比会越来越大,厂家和合作伙伴会支撑您这么做吗?把源代码交给中国移动。
黄倚霄:作为移动,难以把管理软件变成自研,毕竟各个厂家沉淀十几二十年的东西,难以靠几个人用半年或者一年时间替代它。我们做的是关键组件资源,比如SSO、行列数据库关键组件。无论是自研还是外包,最终诉求是把源代码放在广东移动的DevOps生产线,放在广东移动的GitLab进行管理。我们保证是自己员工管理DevOps生产线,不让外包厂家管理,尽量消除大家的顾虑。所以还是有厂家愿意把源代码放在我们上面的,我们要扶持这种厂家。
台下:我们理解外包环境下的DevOps运行,核心在外包。合作方是非常重要的力量,推行DevOps非常重要,特别在我们行业体系下。合作方各有各的不同,有时候由于其定位、业务导向问题,需求不一样。运营商体系中,势必要推动大家往前走。通过指挥棒调整,这需要投入,有没有更好的解决方案,毕竟不是每个运营商都像移动这样可以有大投入的。
黄倚霄:借鉴毛主席打仗的做法,拉拢一批,忽视一批,打击一批。我们的蛋糕这么大,总会有人愿意配合你。计费系统的厂家有华为、亚信和联创三家可以选择,网络支撑的厂家就更多了,几十家,总会有人配合你的。我们作为甲方管理人员够不够坚定,领导是否足够支持你。当厂家去领导那里告状,你能否顶住。我们从痛点着手,解决的是现实中的困难,并没有做颠覆性的东西,你没理由不配合我。我从头到尾都是为了解决那几个痛点,我开始时并没有让你交出源代码,你可以不交,当厂家发现交制品非常累,交源代码钱又多又轻松,就一定会选择交源代码。
台下:非常赞同您谈到的外包转型,但同国企实践来看,除了您谈到的痛点,我们还有其他的痛点。一是人力资源方面,我们无法独立自主,我们由公司主持,在人力上难以实现增加人员;二是国企团队创新能力肯定不如厂家,一旦进入国企团队,其创新能力马上不足,这是我们的现实情况,您能给我们提出什么建议?
黄倚霄:第一,人力资源确实是长期的问题,万事开头难,你必须学会顺势、借势和造势,要顺着当前企业所在的痛点来改进,比如更快的交付、更高的运维质量。借势,多带你的领导和同事参加各种论坛,多向互联网行业和互联网公司学习,了解、对标,让他走出去看,他自然会有了解。人心是肉长的,有触动之后,要多向领导请示和汇报,多说案例。关于人力和团队的问题,首先要内部挖潜,从一个团队总能抽出一两个有想法有能力的人,让他专职做DevOps。很多人看到他做出来的东西很有意思,也会有兴趣有动力去学。你可以找出一个种子——造血,找到这个基因,并将其点燃。
台下:自有团队的创新能力怎么提升。
黄倚霄:我们国企的团队肯定没法像互联网公司那么有激情和那么高的能力,尽力而为,不要强求,比以前好就行了,不要跟互联网公司比,这影响幸福感(开玩笑)。
DevOps 落地为何这么难?
来 DevOps 国际峰会寻找找答案
DOIS 大会为您呈现互联网公司与海外企业的实践经验与工具技术,聚焦 DevOps 在金融、通信、零售等行业的系统性实践,不空谈!不务虚!专注 DevOps 落地!
扫描二维码进入大会官网
DevOps 国际峰会(DevOps International Summit,缩写:DOIS)是国内唯一的国际性 DevOps 技术峰会,由 OSCAR 联盟指导、DevOps 时代社区与高效运维社区联合主办,共邀全球80余名顶级专家畅谈 DevOps 体系与方法、过程与实践、工具与技术。
点击阅读原文,参与报名⬇️
以上是关于外包环境下的 DevOps 实践的主要内容,如果未能解决你的问题,请参考以下文章