如何搭建Devops平台定时任务处理集群
Posted 麒麟敏捷社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何搭建Devops平台定时任务处理集群相关的知识,希望对你有一定的参考价值。
在Devops平台麒麟ADCloud项目中有许多需要定时执行的任务,例如定时发布任务、定时流水线构建任务以及一些后台数据的定时同步任务等。这些定时任务在后台程序中由定时器触发执行,对时间的准确性和执行的稳定性都有很高的要求,且有一些定时任务的执行过程耗时较长,占用服务器资源较大。
单机执行的局限性
在麒麟ADCloud项目中,原先通过部署一个单独的后台进程服务Schedule实例来调度子线程执行这些定时任务。这种架构设计实现逻辑非常简单,但在后续迭代中,麒麟ADCloud项目增加了发布管理模块,增加了大量的定时发布任务。定时发布任务的耗时长,并发量大,且对Schedule执行的稳定性有更高的要求。但是单机执行的模式仅适用于定时任务占用资源和并发量较小的业务场景,而且不能保证Schedule服务的高可用,已经无法满足当前的业务场景需求。
分布式执行需要解决的困难
定时任务是由定时器触发,然后被执行,整个过程可以抽象为一个生产者、消费者的模式。在之前的单机架构中,只有一个生产者和一个消费者,只需要简单的设计生产者与消费者之间的通信与协调过程,实现简单。而在分布式架构中可能会存在多个生产者和多个消费者,使用分布式方式来执行定时任务需要解决的一个最大的问题,即对整个集群的协调与管理。主要包括以下几点:
生产者之间需要协调,不能少触发、重复触发任务。
生产者与消费者之间也需要通信与协调,且在分布式的环境中更加复杂。
消费者之间同样也需要协调,不能少执行或重复执行任务,且要保证负载均衡。
要保证高可用,生产者与消费者两个抽象地对象必须要保证至少各有一个在工作。
当某个消费者在执行任务的过程中挂掉,它正在执行的任务需要被其他消费者继续执行而不能丢弃。
解决的基本方案与优势
针对以上团队针对新的业务场景需求设计并实现了一套使用ZooKeeper来进行协调管理的Schedule服务实例集群。该集群采用主从式的分布式架构,即一个Schedule实例作为Leader来通过定时器触发任务,所有的Schedule实例包括Leader都参与执行任务,可以抽象为一个生产者多个消费者的模式。并通过ZooKeeper的临时节点特性与监听机制来实现Leader的高可用。因此,整个集群只要还存在一个Schedule实例即为可用状态。
任务的分配过程通过分布式队列来实现,该分布式队列利用ZooKeeper提供的监听机制与存储结构来实现。负载均衡策略为轮询式负载均衡,通过一个分布式循环栅栏来实现,该分布式循环栅栏也是通过ZooKeeper的监听机制与存储结构来实现的。
相比于之前的单机式架构,该设计方案解决了之前单机模式存在的几个主要问题,即不仅能够支持服务的高可用,且并发性能能根据服务器的负载情况扩缩容实例数动态地改变。
下面将对具体的实现流程进行比较详细的介绍。
关键工具ZooKeeper
ZooKeeper是一个开源的分布式应用协调服务框架,通过多台服务器节点构成,应用程序可以使用ZooKeeper所提供的客户端API与ZooKeeper服务框架进行数据交互。ZooKeeper服务端提供了简单原始的API,开发者可以基于此实现更高级的分布式协调服务,例如:分布式同步、配置管理、集群管理和命名管理等。下面将简单介绍下ZooKeeper总体结构、数据模型、监听机制。
ZooKeeper总体结构
ZooKeeper服务由多台服务器组成一个集群来保证整个ZooKeeper服务的可靠性与容错性,当有2n+1个服务器时只要有n+1个服务器有效整个服务仍可以有效运行。整个ZooKeeper的结构模型如下图所示。
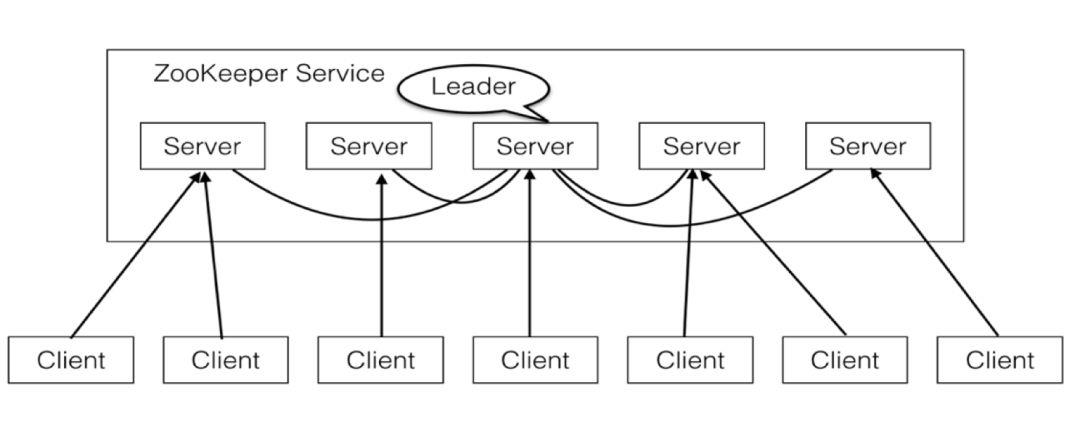

ZooKeeper数据模型
客户端程序通过调用ZooKeeper提供的客户端API与ZooKeeper服务建立会话(session)连接后就可以与ZooKeeper服务进行交互。ZooKeeper为客户端提供了数据存储的服务。在ZooKeeper服务框架中,会维护一个有层次结构用于数据存储的结构模型,它和标准的文件系统结构非常得类似,如下图所示。
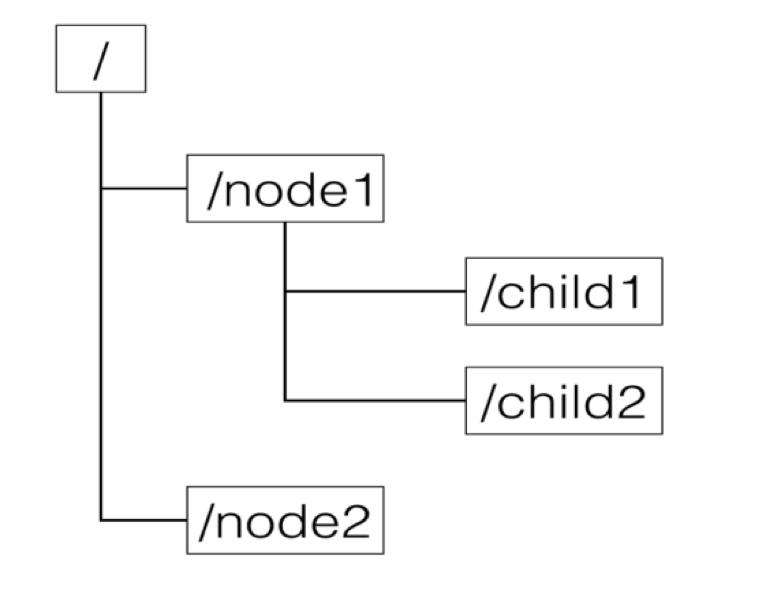
每一个node例如node1被称作一个Znode,它是ZooKeeper数据存储模型的基本单位。每一个Znode被节点路径唯一标识,例如/node1/child1。Znode可以有子节点,节点本身也可以存储数据。
Znode根据生命周期来划分有两种类型。
持久型(persistent):persistent类型的节点没有和特定的session绑定,当创建该节点的session因为超时或显式关闭结束时该节点还会继续存在,直到该节点被显示删除。
短暂型(ephemeral):ephemeral类型的节点是临时性的,当创建该节点的session因超时或显式关闭结束时,该节点就会被自动删除,但当该节点存在时其他session也可以访问该节点中关联的数据。ephemeral类型的节点不能拥有子节点。
Zookeeper监听机制
客户端不仅可以对ZooKeeper中的节点进行操作,ZooKeeper还提供了一个非常好用的Watch(监听)机制,可以在节点的结构信息或数据信息发生变化时通知客户端,而避免了客户端为了获取最新的节点数据不断轮训并提高了数据的实时有效性。Watch功能是ZooKeeper对于应用的重要特性,通过这个特性可以实现许多非常有用的功能如:集中管理、分布式锁等。
ZooKeeper中Watch的主要特性如下:
一次性触发:客户端获取某一节点的数据时可以在该节点上添加一个Watch,当节点的数据发生变化时ZooKeeper会自动通知客户端程序并将该Watch注销,但是客户端程序只会收到一次这样的通知,若该节点的数据再次发生变化时客户端不会再收到通知,除非客户端再次在该节点上添加一个Watch。
仅发送通知:ZooKeeper不会将最新的数据推送给客户端,只会通知客户端数据发生了变化。客户端需要自己调用ZooKeeper提供的客户端API对节点的数据进行获取。
ADCloud实践样例
总体架构
麒麟ADCloud后台进程整体架构由ZooKeeper集群、Schedule集群与数据库构成。Schedule集群为主从式结构,由Leader进行任务分配与集群管理,所有实例都参与任务的执行。集群的选主策略为根据注册时间进行升序排序。这里以两个Schedule实例的集群为例,如下图所示。
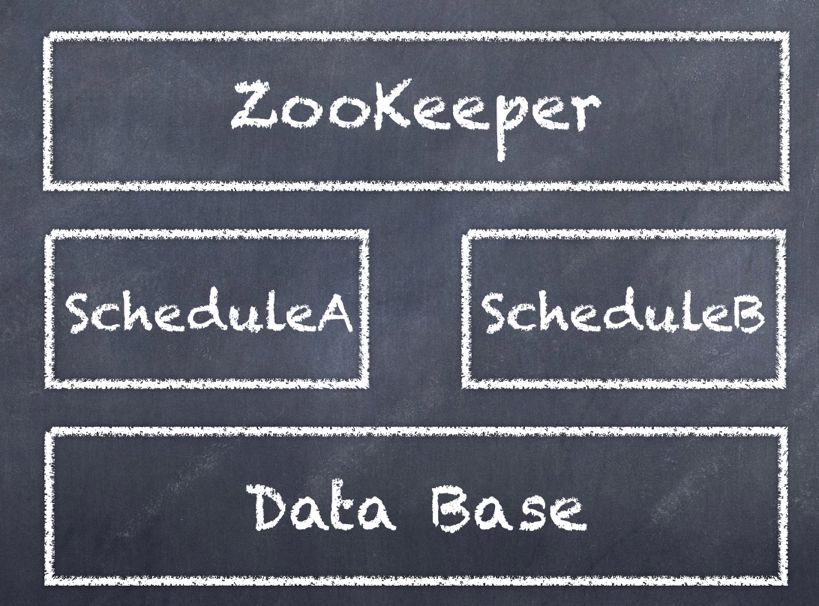
ZooKeeper上的存储目录结构如下图所示。
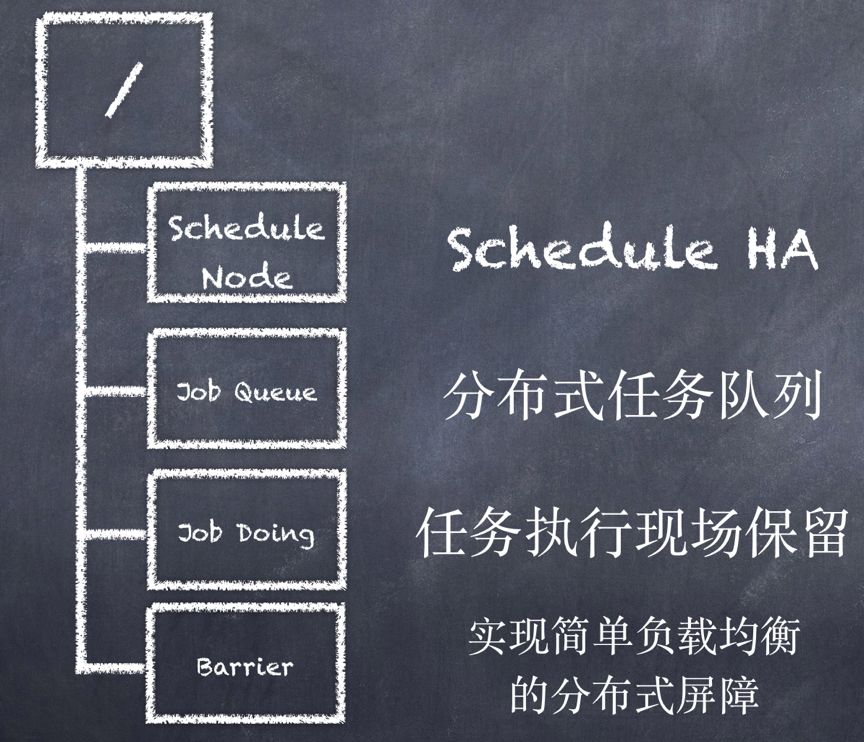
Schedule Node目录存放Schedule当前的实例节点信息包括实例ID、注册时间等。该目录用来实现Schedule集群的主从式管理、高可用与支持动态扩缩容。
Job Queue目录存放分布式的任务队列,队列中为需要被执行的定时任务。
Job Doing目录存放任务被执行的具体现场,包括执行该任务的具体Schedule实例ID,该任务的执行进度。
Barrier目录存放分布式屏障用来实现简单的轮询式负载均衡。
下面通过几个主要的业务场景来说明集群高可用与任务调度功能的具体实现逻辑。
初始化过程
Schedule集群初始化过程如下图所示
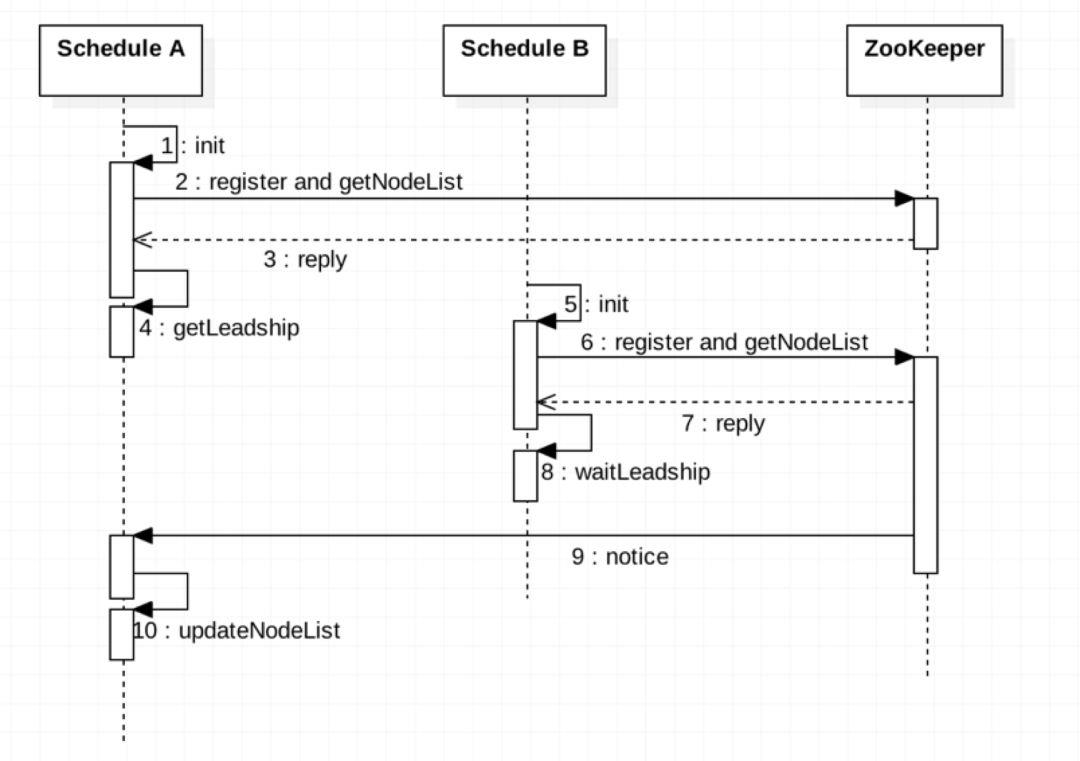
Schedule A实例最先启动然后在初始化方法中到ZooKeeper上进行注册一个保存实例信息的临时节点并对该列表进行监听,当列表变化时会收到通知。Schedule A检测到当前没有Leader,因此自己就是最早的节点,根据选主策略Schedule A获取到Leadership,然后在getLeadship方法中注册由Spring Boot框架提供的定时任务调度器。随后,Schedule B启动,在它的初始化方法中到ZooKeeper上进行注册并对该列表进行监听,检测到存在Leader,未获取到到Leadership。但当列表变化时会根据每个实例节点的创建时间再次检测自己是否获取到Leadership。Schedule A获取到Schedule Node列表变化的通知,更新本地的NodeList。每个实例的初始化过程中还包括了对ZooKeeper其他各个目录设置监听,在此就不作赘述。
定时任务扫描并添加进队列的过程
在上面的流程中Schedule A拥有Leadership,负责定时任务扫描并将定时任务添加进分布式任务队列的工作。这里以麒麟ADCloud中发布管理模块的定时步骤任务AdPlan为例子进行描述,如下图所示。
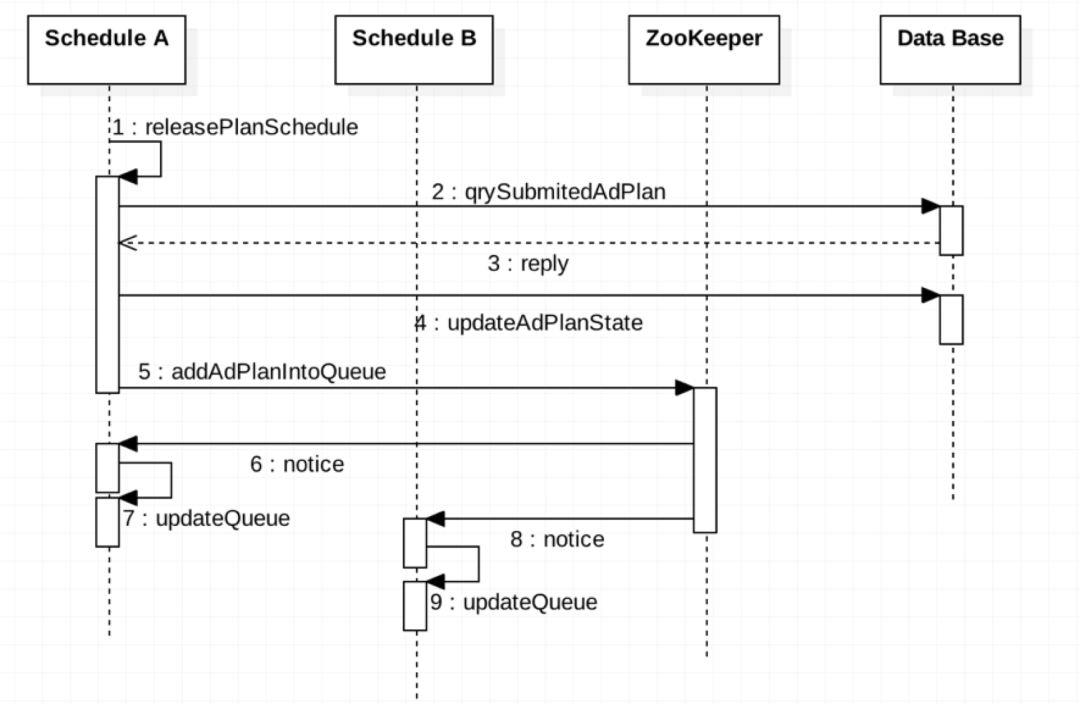
Schedule A中定时任务的调度器releasePlanSchedule定时触发方法扫描数据库中的AdPlan,若存在提交的AdPlan则更新数据库中的状态为执行中,随后将该AdPlan添加到ZooKeeper上的分布式任务队列中。
然后每个Schedule实例都会收到分布式任务队列新增任务的通知,更新本地的任务队列副本。
队列中任务的分配过程与负载均衡逻辑
队列中的任务通过抢占式的方式分配,即先到先得,然后使用分布式屏障Barrier来控制每个Schedule之间的负载均衡。分布式屏障Barrier同一时间只会存在一个,每个Schedule从队列中取出一个任务时就会增加Barrier的一个完成块,并被该Barrier阻挡。完成块总数等于当前Schedule的实例数,当完成块满后Barrier解除并在ZooKeeper上删除。
当节点列表变化时由Leader重置Barrier。若一个Schedule挂掉Leader则将其正在执行的任务重新放入队列中再次分配。
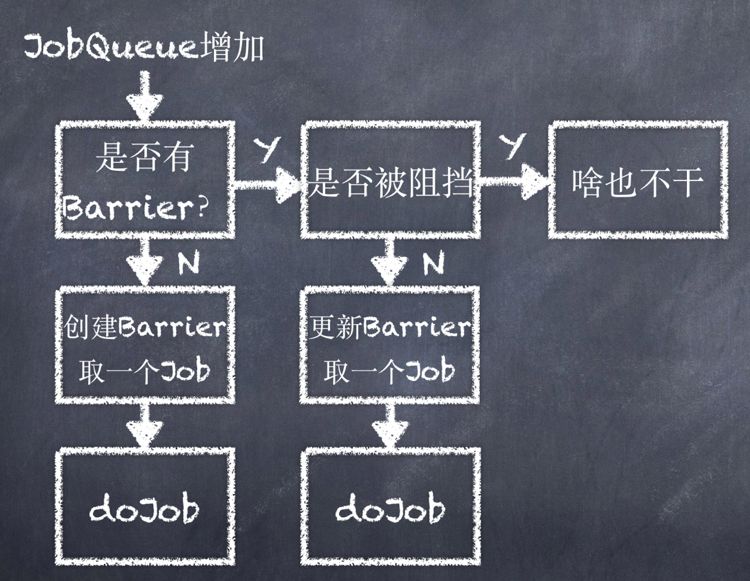
当队列增加一个新的任务后每个Schedule实例都会收到通知,如上图所示。首先会检测当前是否存在Barrier如果不存在,则创建一个然后取出一个任务进行执行。若当前存在Barrier则判断该Barrier是否阻挡了当前任务的执行,若没有则取出一个任务进行执行并增加Barrier的完成块,否则不执行任务工作。
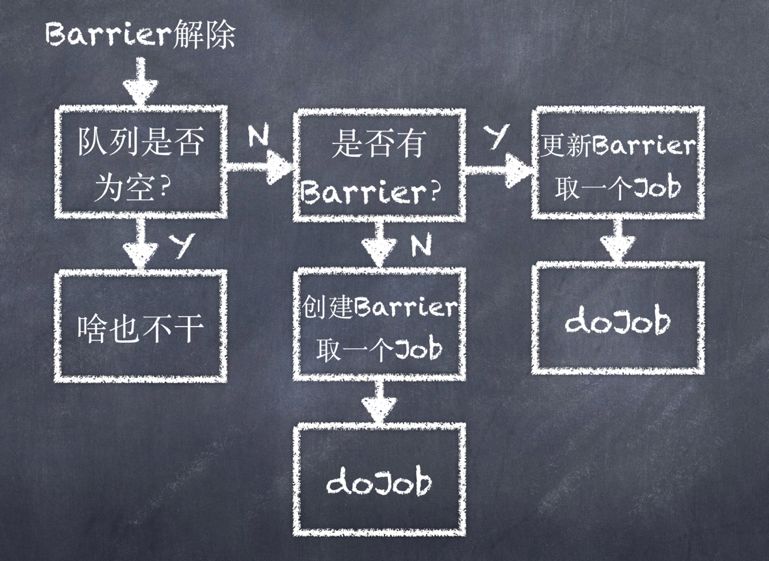
如上图所示,当Barrier解除后,Schedule判断队列是否为空,若不为空则判断当前是否存在Barrier。如果不存在Barrier则创建一个新的Barrier然后取出一个任务执行,若已经存在Barrier则增加现有Barrier的完成块数,然后取出一个任务进行执行。
Leader的切换过程
在集群运行的过程中,如果作为Leader的Schedule A实例关闭或者故障,则它注册在ZooKeeper目录Schedule Node中的临时节点会因没有保持心跳而消亡。其他的Schedule会收到通知,根据选主策略判断自己是否成为新的Leader,具体的流程如下图所示。
Schedule B收到通知然后获取到Leadership,将Schedule A执行的任务重新放入分布式任务队列中,并在Spring Boot框架中注册定时任务的调度器。
总结
本文通过一些主要的业务场景描述了一种使用ZooKeeper实现集群式执行定时任务的方案,从这些主要的方面阐述了该方案的设计思想。还有一些细节方面的逻辑过程由于篇幅限制在此就不作赘述了。如果对相关的技术细节感兴趣可以与我们联系,进行更加深入的探讨研究。
以上是关于如何搭建Devops平台定时任务处理集群的主要内容,如果未能解决你的问题,请参考以下文章