鲸品堂|给DevOps一个机会,助力业务快速创新
Posted 浩鲸科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了鲸品堂|给DevOps一个机会,助力业务快速创新相关的知识,希望对你有一定的参考价值。
我们先来看2013年美国软件行业的一个调查数据:
20世纪80年代之前:软件交付周期基本上是1~5年,交付成本需要数千万以上,风险非常高,一旦失败甚至可能导致企业破产。
20世纪90年代至20世纪末期:软件交付周期基本在3个月至一年,交付成本下降到数百万量级,风险中等,失败可能会导致一个产品部门解散。
21世纪至今:软件交付周期一般在半个月到3个月,交付成本下降到几万量级,这个风险是很低了,失败对企业影响非常小,即使是初创公司都能接受。
软件交付正向一个交付更快、成本更低、风险更小的方向发展,在这个趋势下,谁的交付能够更快、成本更低、风险更小,谁就能迅速占领先机,逐步成为行业的胜出方或者领先者。
那如何做才能拥有这种能力呢?
引入DevOps。


DevOps是什么?
在探究之前,我们先了解下DevOps这个词是怎么来的。2009年,比利时根特市举办了首届DevOpsDay大会,为了更方便在Twitter上传播,把DevOpsDay缩写为DevOps。从此,DevOps就被广为传播了。目前DevOpsDay已经在全球举办了几百场,并且越来越多的公司投入到DevOps之中,不仅创业公司在实践DevOps,领先的互联网巨头及其一些传统行业都在实践DevOps。
那DevOps是什么?从字面意思就是开发运维,在国内又叫研发运维一体化。
DevOps思想来源非常广泛,主要包括精益求精、约束理论和敏捷等。DevOps一般需要秉承三个原则:快速流动、持续反馈和持续改进。
快速流程原则:实现价值的快速流动,就是把客户需求快速交付。
持续反馈原则:能够在流动的各个环节感知问题,并快速反馈,迭代到下一轮改进中。
持续改进原则:针对反馈的问题寻求更好、更高效的解决办法,提供更快更好的手段保障流动更快、成本更低并且风险更小。
DevOps带来了哪些价值?
先来看一组数据,下图是2012年引入DevOps的互联网公司与普通企业的交付效能数据对比:
公司 |
部署频率 |
部署交付期 |
可靠性 |
客户响应 |
亚马逊 |
23000次/天 |
分钟 |
高 |
高 |
谷歌 |
5500次/天 |
分钟 |
高 |
高 |
NETFLIX |
500次/天 |
分钟 |
高 |
高 |
1次/天 |
小时 |
高 |
高 |
|
3次/周 |
小时 |
高 |
高 |
|
普通企业 |
9月一次 |
月或季度 |
低/中 |
低/中 |
从上述表格看,实践DevOps可以给企业带来更高的部署频率、更安全的交付模式和更快的客户响应度。
我们再看下PuppetLabs发布的2013~2016年度现状报告,报告指出DevOps实践的高绩效公司能够在如下方面远超低效同行:
产品交付和部署频率:频繁30倍
产品交付部署的前置时间:快200倍
产品交付部署成功率:高60倍
平均服务恢复时间:快100倍
生产力、市场份额更高:提升2倍以上
简单说DevOps集文化理念、工具和实践于一体。文化跟组织相关,我们这里不展开,本篇主要从实践和工具讲下DevOps(其实工具都是从实践中沉淀出来的)。
浩鲸DevOps平台目前正从2.0向3.0演进。1.0时代主要关注是工具沉淀、基础平台的搭建;2.0时代重点在于提升自动化能力,同时做了部分数据注智的探索,以及一些场景化的工具沉淀;3.0时代更偏向于数据注智,通过数据智能提升运维效率。
浩鲸DevOps1.0时代
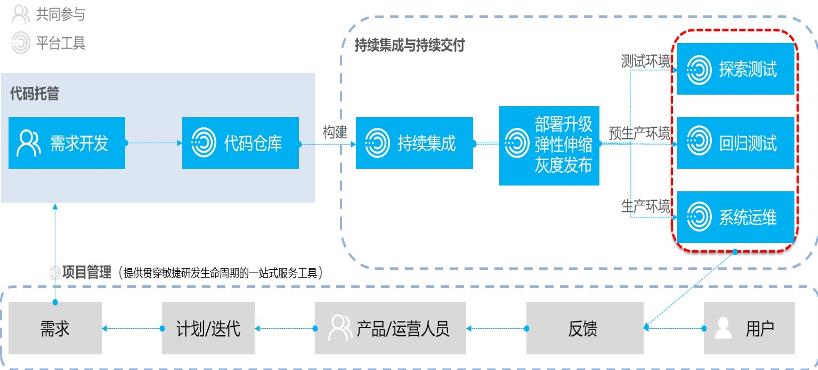
上图是一个软件研发交付的全流程,包括需求分析、需求研发、代码构建和发布等环节;发布到运行环境后,通过对系统感知形成反馈数据,最终通过产品规划分析再迭代到研发交付流程,最终形成闭环。
上述的软件交付流程中,需求管理、代码管理、持续构建、部署发布和系统感知都需要基于工具平台来支撑。
1.0时代我们的DevOps平台具备代码管理能力、持续构建能力、基于虚机物理机的应用和技术栈的发布管理,建立监控平台,可以对资源、技术栈、业务的性能和运行进行监控。
下面分享下我们在持续集成和发布管理工具的实践故事。
在项目上经常会发生这样的事情,新需求刚发布到生产环境就触发了故障。那是否有手段能提升质量?这个需要依赖持续集成的众多工具来实现,一方面我们引入代码规范检查工具,杜绝一些低级故障出现;另一方面我们提供单元测试工具,保障代码的正确性;此外再引入回归测试工具,保障业务功能没有问题。
在持续集成实践涉及的诸多工具中,我们重点讲下回归测试和数据库脚本方面的工具。
>数据库脚本管理工具
应用的数据库脚本非常重要,若数据库脚本有问题,会导致重大的生产事故。如何保障数据库脚本的质量是其中关键。
针对上述的问题,我们逐步沉淀出数据库脚本管理工具,有效提升数据库脚本的质量。
脚本变更拥堵问题:刚开始时,我们管理脚本都是通过一个大脚本来管理,脚本变更通过架构师来处理。后来发现脚本经常堵单,变更多了,架构师也容易遇到瓶颈。为了提升效率,我们做了针对性优化,脚本跟随需求单走,不再设置统一的大脚本。
脚本获取问题:脚本散落在需求单,又引发了脚本获取的问题。我们一个产品同时支撑多个项目,在线版本也不同。不同项目升级的需求单集也不一样,从而导致获取需求单集的脚本工作量很大,极易出错。基于这个情况,我们构建出脚本工具,能够从对应需求单中获取到对应的脚本,形成需求集的脚本。
脚本正确性问题:脚本集获取到了,但是脚本质量却很低,经常出现因脚本问题导致产品在测试环境部署发布失败。我们再次进行优化,需求单转单时进行脚本预解析和审计,这样能提前发现问题,提前拦截掉有问题的脚本。脚本的审计规则也一直在沉淀,从而大幅减少错误泄露到生产环境。
至此,我们沉淀出相对完善齐整的工具,从而提升脚本的质量。
研发经常发现新增一个需求代码后,会引发其他功能异常。为解决此类问题,我们需引入测试工具,做回归测试管理,并且嵌入进持续集成流程中,这样持续集成通过后,可以保障存量功能正常运转。
这就引出了一个测试平台管理的系列要求......
用例如何跟需求关联,如何保障需求的覆盖率:市面上开源测试工具还是非常多,使用后发现开源测试工具存在众多不便。我们的需求基于研发流程管理平台管理,但用例却落在了开源测试工具中,两者的关系只能通过表格来管理。若想看需求的用例覆盖率、本次发布的测试质量数据,需要通过人工处理。所以我们构建工具来打通需求和用例的关系,并逐步增加了数字化分析功能。
如何提升用例的开发效率:需求和用例关联解决了,但是用开源工具开发用例时候还是比较复杂,比如用例涉及到数据库,每个用例都需要实现一遍跟数据库对接功能,随着云化架构推广,技术栈越来越多,这个工作量越来越大。为此,我们增加实现用例管理,并逐步沉淀不同技术栈的能力。
面向数据库,我们沉淀了Altibase/HBase/
Informix/TimesTen/MongonDB/mysql/Oracle/Postgresql/QMDB/Redis/Sybase/XMDB等能力模板;面向接口,我们沉淀了Http/HttpInterceptor/MML/VC/DCC/Dubbo/WebService/SMS/EMPP等协议模板;面向消息,我们沉淀了ZMQ和阿里MQ能力。通过这些能力模板库,使得用例开发门槛更低效率更高。
实际上,目前测试平台还在不断优化提升,正在做测试平台的云化调度和弹性伸缩,这样压力大的时候可以扩展到新的资源上进行高效的回归测试。
构建高质量的制品是基础,就算有这么多工具保障,也可能会出现故障泄露,变更发布后引发重大故障。
那我们需要考虑在发布阶段提供工具来降低发布的风险,下面是我们这方面的工具实践。
大家应该都有这样的经历,刚入职时需要花一天以上的时间来准备电脑的软件环境,安装Office,安装IDE工具等。准备办公电脑环境都这么慢,那我们准备自测环境或者测试环境就更复杂了,尤其在云化架构下技术栈非常多,整个流程下来工作量非常大,并且极容易出错。
一键部署就是在不断解决上述问题的过程中沉淀下来的。
涉及这么多技术栈,环境如何准备:我们准备环境,每个技术栈都需要找对应的人来支撑,整个流程耗时长,效率也低。我们逐步把技术栈管理能力沉淀为工具,这样一键式就可以触发部署需要的技术栈。
技术栈之间冲突如何解决:单个技术栈已经可以顺畅部署了,多数环境会涉及多个技术栈,有时技术栈之间会存在端口等资源冲突问题。我们对工具进行持续优化,多个技术栈可以形成一个解决方案,预先给技术栈分配好相关资源。这时我们把多个技术栈形成一个解决方案模板,一次可以完成环境需要的多个技术栈的部署。
部分环境不标准导致中途失败如何解决:实际操作中使用到主机差异很大,有的主机操作系统是刚装的,有的是直接从其他环境中挪过来的,经常出现部分参数设置不对或端口被占用等问题导致中途失败。我们又对工具进行优化,引入了环境检查,引入中断后可以从断点继续处理。
目前一键部署工具已经再次进化,可以实现IaaS、PaaS和SaaS的一键式安装部署,根据实际需求输出解决方案,可以只部署PaaS+SaaS,或者选择部分。目前全部流程如下:
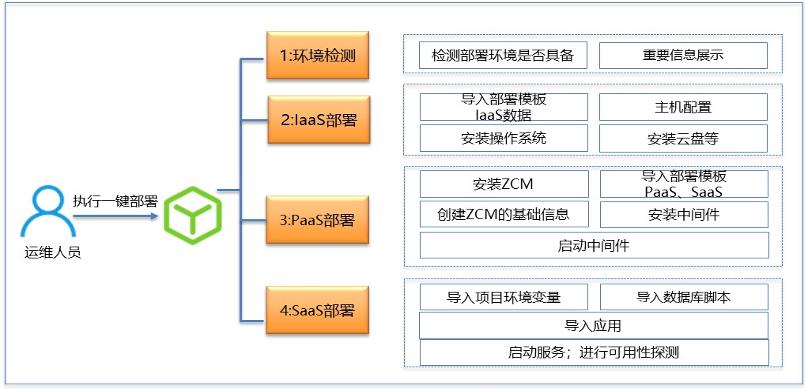
环境检查:检查环境是否具备,哪些不具备,不具备的环境需要人工干预。
IaaS部署:环境具备后,按部署方案模板导入IaaS数据,安装操作系统等。
PaaS部署:导入中间件模板,安装中间件和ZCM,并启动相关服务。
SaaS部署:导入业务模板、相关环境变量、执行相关脚本,启动相关业务服务,并且探测业务系统是否可用。
一键部署工具帮我们降低了诸多技术栈的门槛,使得我们能够专注于业务逻辑实现。
项目上线后,会不断发布需求或者故障的变更。我们的制品是通过持续集成输出,制品质量通过工具来保障,变更发布时还是存在一定的故障泄露风险。那有什么办法可以降低发布风险,即使泄露了也能及时回滚恢复,最好影响范围也尽量小?
我们发布工具就是在这个驱动下逐步沉淀的。
多产品的互相依赖时,如何进行在线升级:业务微服务化后,一般会包含很多子产品,实际变更也会涉及多个子产品。多个子产品存在依赖关系,若升级需要考虑依赖关系,否则会导致上层服务不可用,中断业务。我们把这个问题沉淀为工具,多个子产品形成一个解决方案,制品发布时将多个子产品打包一起发布。实际升级时会解析制品包,按依赖关系逐一进行子产品的滚动升级。
如何控制发布影响的范围:升级是可以在线了,但升级的影响范围还是没有解决。我们把业界的灰度发布引进来,对工具进行持续改进,通过灰度环境和正式环境来隔离发布的影响,通过设置灰度规则来控制灰度环境适用对象。目前我们可以提供WEB和服务层的灰度发布。
具体的灰度发布流程如下:

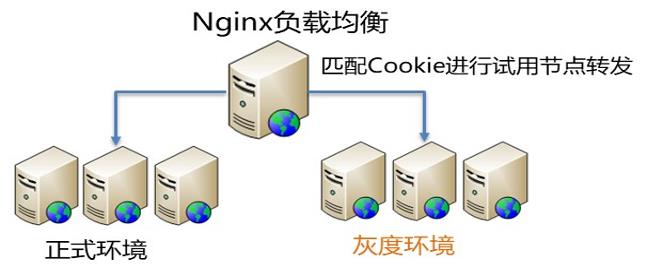
灰度规则设置:在灰度管理中进行设置,具体灰度规则可以按操作员或者区域等属性。灰度规则推送到负载器。
业务请求:判断请求信息中是否带灰度规则(就是灰度规则可能来源于上层服务),若有则路由对应的灰度环境。
灰度规则解析:若请求中没有灰度规则,则提取Cookie中的信息匹配灰度规则,匹配到路由到对应的灰度环境,否则路由到正式环境。
浩鲸DevOps2.0时代
1.0时代,浩鲸的DevOps侧重于沉淀基础的工具,落脚点在工具化和可视化。到了2.0时代,浩鲸DevOps平台除了面向虚机、物理机管理,还新增容器的管理。除了新增的容器管理平台,在运维方面还新增一套基于日志分析的应用性能管理工具,提供了基于故障场景的自愈工具、基于故障因子的故障诊断工具。
经过沉淀,浩鲸DevOps2.0功能架构如下:
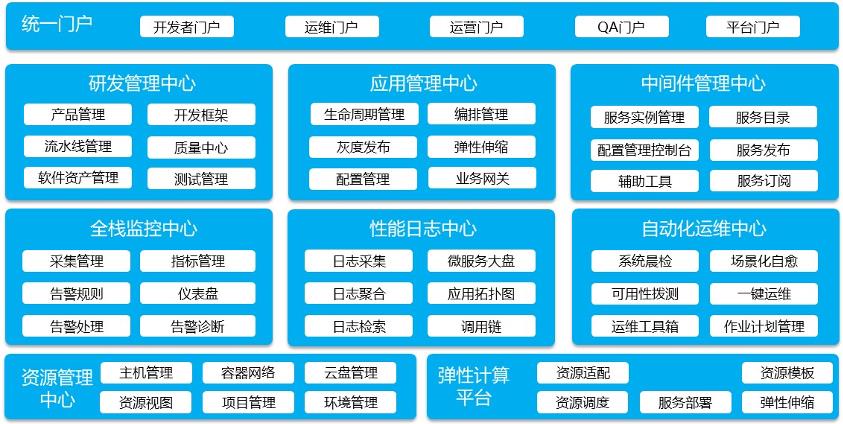
形成了覆盖研发管理、发布管理和运维管理的完整DevOps平台。
研发管理平台提供研发管理的工具,提供开发框架、持续构建和测试管理。目前构建管理覆盖了主流的工具,包括代码质量分析、代码单元测试、自动化测试平台等工具集。
应用管理中心和中间件中心提供发布管理的工具,主要提供业务和技术组件的发布工具和配置管理。
全栈监控中心、性能日志中心和自动化运维中心提供运维管理的主要工具,主要是通过收集日志、性能数据、告警数据等方面的数据,再通过算法分析出变更质量和系统运行健康度。此外,全栈监控和性能日志还提供一些业务问题分析和故障诊断的工具,自动化运维中心则输出场景化自愈能力。
下面我们主要分享下我们在故障自愈和故障诊断方面的能力。
不同的故障会有不同的恢复手段,同一类故障恢复方式还是一样的。浩鲸DevOps2.0已经具备了故障自愈的能力。
下面是我们故障自愈的一些场景,通过自愈能力可以保障高可用集群一直保持高可用状态。
ZMQ的broker主机宕机的自愈:针对这个场景我们主要是分析到主机宕机、broker进程挂,自愈时候是通过加入新主机,在新主机上自动部署ZMQ服务,并加入到ZMQ集群,修复broker主从高可用集群。
ZCache集群主机宕机的自愈:这个场景也是类似,自愈通过加入新主机,部署服务,在加入到ZCache集群,保障副本数和服务满足高可用。
NIGNX+Tomcat应用集群自愈:Tomcat节点故障后,通过工具新部署一个Tomcat节点,加入到应用集群,保障集群高可用。
故障诊断分析的技术难度非常高:故障分析诊断非常复杂,涉及到诸多因素,需要根据感知的数据进行分析才能知道故障原因。我们把分析故障经验沉淀,形成故障因子库,通过感知的数据进行分析,从而得到故障原因。
下面是一个故障因子树分析的示例,比如故障场景是界面点击慢,我们通过沉淀的经验构建一个故障因子树,初期因子如下图,其实这棵因子树会随实践经验逐步成长的。
构建故障因子树:结合基础设施类、中间件类等方面的经验沉淀为故障因子库,这样分析业务故障时可以复用这类因子。
故障诊断:结合经验设置权重,以及告警/指标等进行组合计算分析,可以匹配到对应的故障因子树,这样就定位出根因。
故障修复和加固:若多数故障的根因指向几个固定的因子,则说明这些因子不稳定,需要进行加固或维护。若是设备类则需要替换,若是业务系统类则说明该子系统不稳定,需要提升稳定性。
通过故障诊断工具,能够让普通人员具备多个专家的能力。
浩鲸DevOps3.0时代
目前,浩鲸的DevOps正从2.0向3.0演进,从工具化、自动化逐步向智能化转型。
外部环境一直在变,我们运维对象也会随之改变,除了工具的演进,3.0时代我们还在做更多的探索......
管理更多基础设施:后续,我们运行环境后续除了英特尔的CPU架构,还需要考虑ARM架构。
继续提升自动化能力:实际运维中,随业务的持续演进会不断出现新的故障,我们需要逐步优化和新增我们的场景化故障库,把经验变为自愈工具。
混合云能力:我们做性能测试时经常会遇到资源不足的问题,我们构建演示环境时也会遇到没有资源的问题。后续提升平台针对混合云的支撑能力,提供能力将业务自动弹上公有云。
引入更多智能化场景:引入更多AI算法引入到运维场景,2.0时代主要是提供异常检测、故障诊断等,后续我们会做更多探索,实现更多场景的智能化运维。
以上是关于鲸品堂|给DevOps一个机会,助力业务快速创新的主要内容,如果未能解决你的问题,请参考以下文章
搭乘“云原生”硬核实践之舟,移动云助力开发者畅游未来创新之旅