DevOps 做到 BATJ 级别,你需要这份完整的参考指南 Posted 2021-04-16 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DevOps 做到 BATJ 级别,你需要这份完整的参考指南相关的知识,希望对你有一定的参考价值。
作者简介
大家伙,今天主要带着大家一起通过 2020 年中国 DevOps 现状调查问卷来了解自己所在企业的 DevOps 能力,也会在解读问卷的过程中给大家分享一些实践经验与案例。
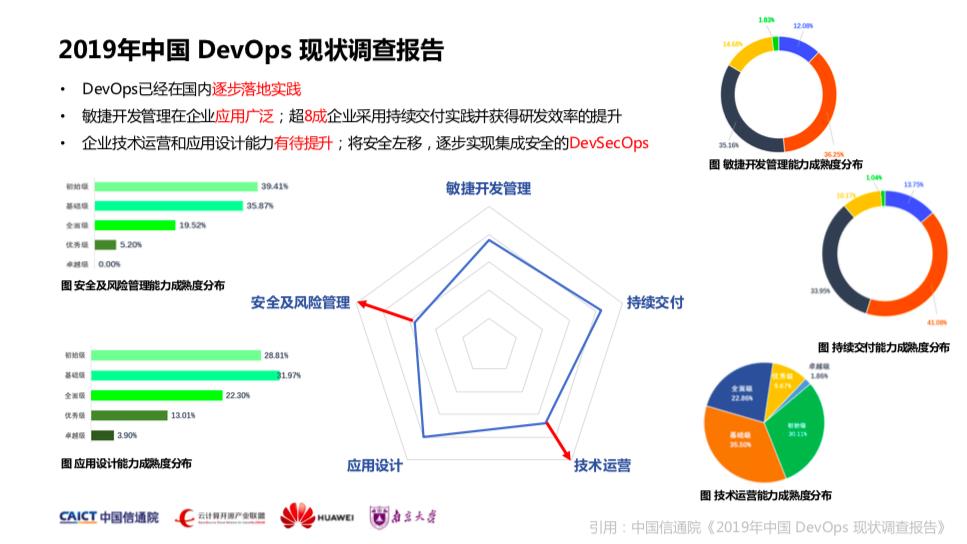
2019 年的调查报告有几个针对性的结论:
第一,DevOps 在国内已经逐渐落地实践,从成熟度的模型中来看有很多企业在 DevOps 各个领域都有很好的实践。
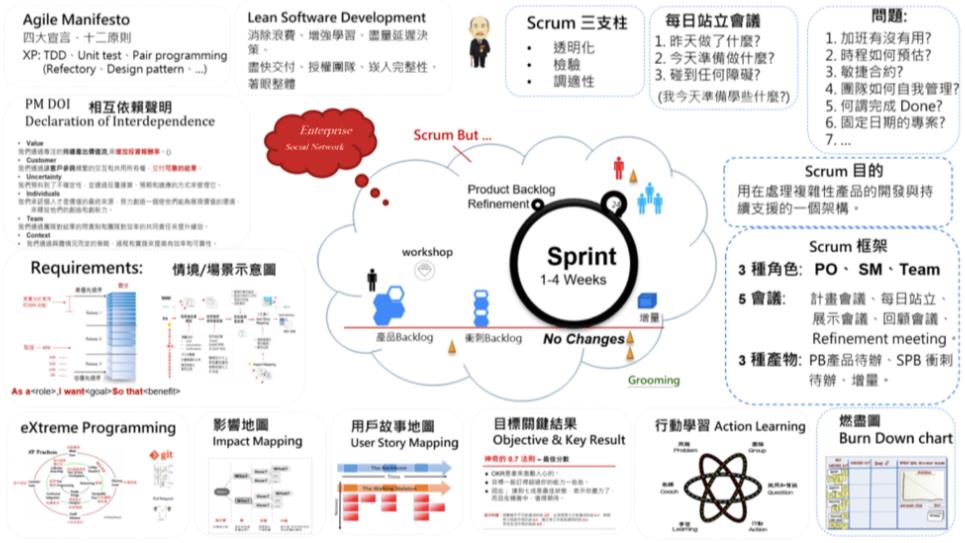
第二,敏捷开发管理在整个企业当中的广泛应用,像我之前所在公司 2010 年开始做试点,2012 年左右已经开始推大规模的组织级敏捷相关的转型,但那时候更多基于 SCRUM 的框架来推进,所以敏捷在国内的推进非常有年头了。
另外,超8成的企业采用持续交付实践,并且获得了研发效率提升,包括集成效率和频率等等。持续交付的实践主要来源于 Jez Humble 的《持续交付》,中文版由乔梁老师翻译,乔梁老师去年也出版了《持续交付2.0》,每一名工程师都应该掌握这两本书的工程实践与技术。
第三,企业的技术运营和应用设计能力是有待提升的。因为有大量的企业在运维侧的投入比较少,而且主要目标以维稳为主,所以技术运营能力偏弱。另外DevSecOps也在逐渐成为趋势和常态,大家都希望往这个方向做,但是目前能力比较薄弱。
接下来看下中间的雷达图达标了所有参与调查企业的平均能力,这是 2019 年报告的核心,这个雷达图包含了 DevOps 标准的核心能力域:敏捷开发管理、持续交付、技术运营、应用设计和安全及风险管理。
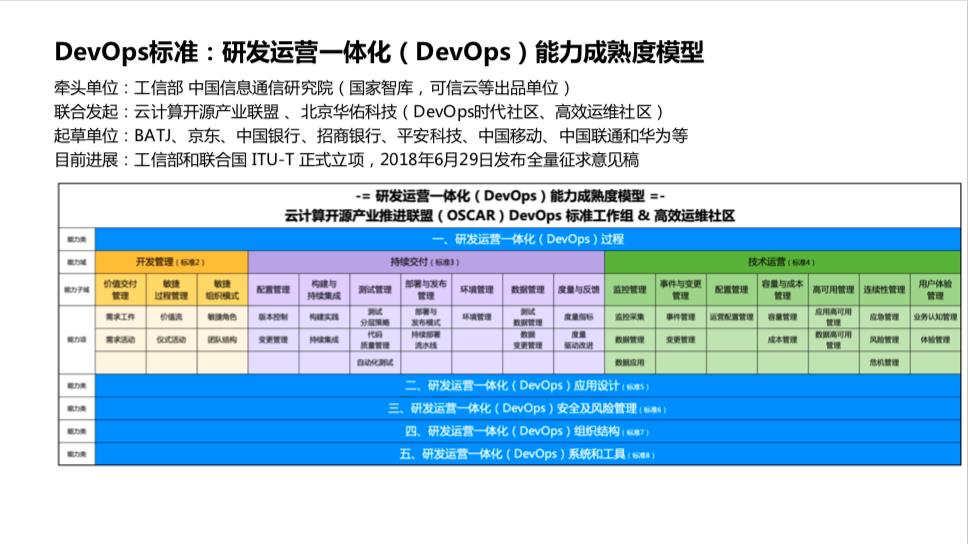
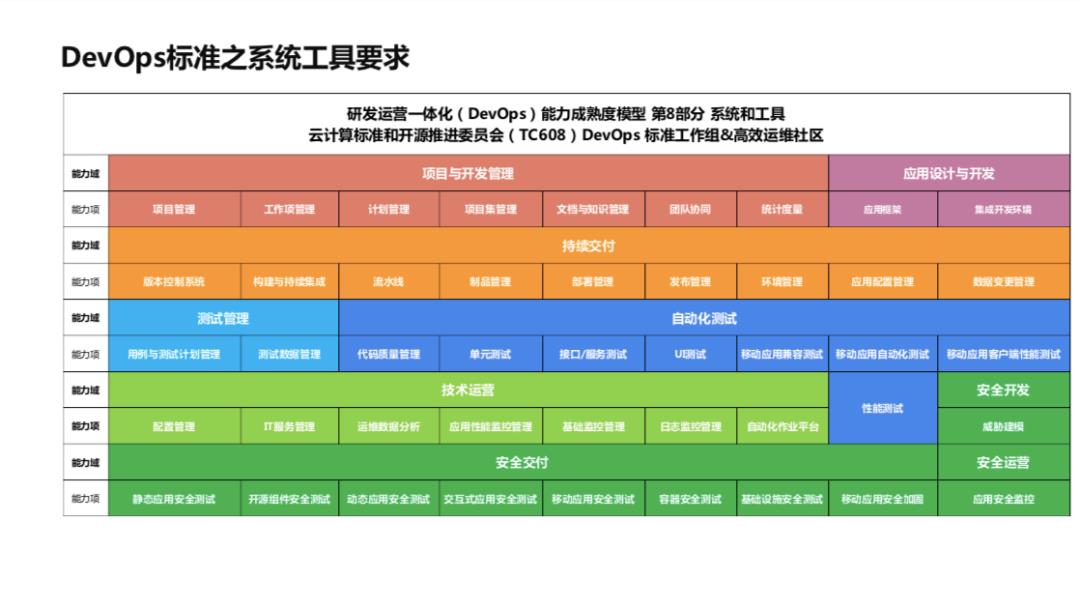
两个明显的特点就是安全及风险管理和技术运营的差距稍大一些。这里可以看到问卷背后是一个非常完整的模型,这个模型即 DevOps 标准:研发运营一体化能力成熟度模型。模型就是问卷的核心,也是基于模型来定义问卷,模型也是由工信部牵头完成,社区和 BATJ、金融、通信众多企业的参与。
2020年的到来,标准在持续迭代,问卷也进一步完善。
右边这张图是我们填写完问卷之后所获得的结果,这里会有简单的算法来通过大家的选择计算最终的级别。
我会带着大家逐步解释和填写这个问卷,同时还会穿插一些我认为比较有价值的知识点。
敏捷开发管理
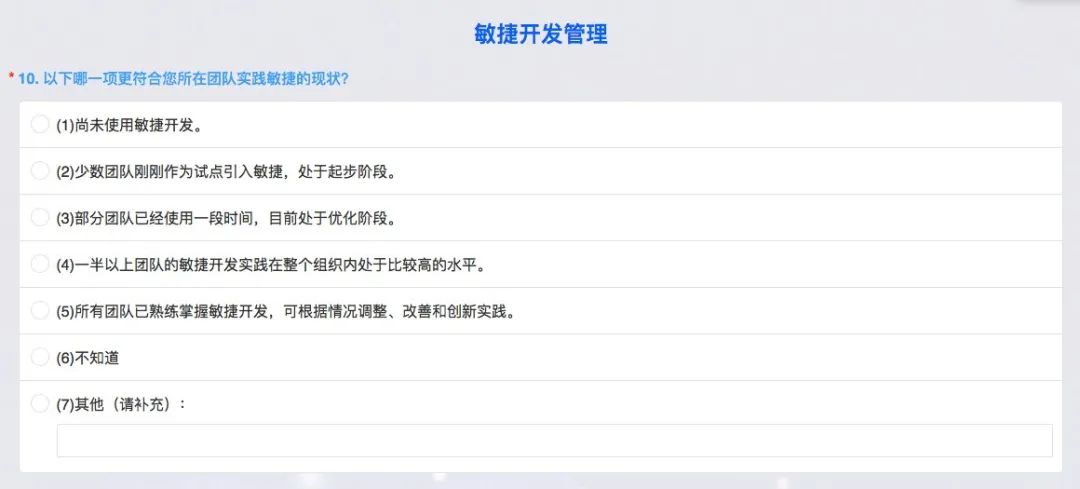
首先进入第一个部分敏捷开发管理。 第一题,以下哪一项是更符合您所在团队实践敏捷的现状?第一个选项是未使用敏捷;第二个选项是少数团队,刚开始试点是起步阶段;第三个选项是部分团队已经使用一段时间,目前处于优化阶段;第四个选项是一半以上的团队的敏捷开发实践在整个组织处于比较高的水平,五级就是非常熟练。
目前我们还是保守一些,我们正处在部分团队使用,很多团队因为业务的特点还没有做这方面的转型,大家也在不断尝试和迭代。
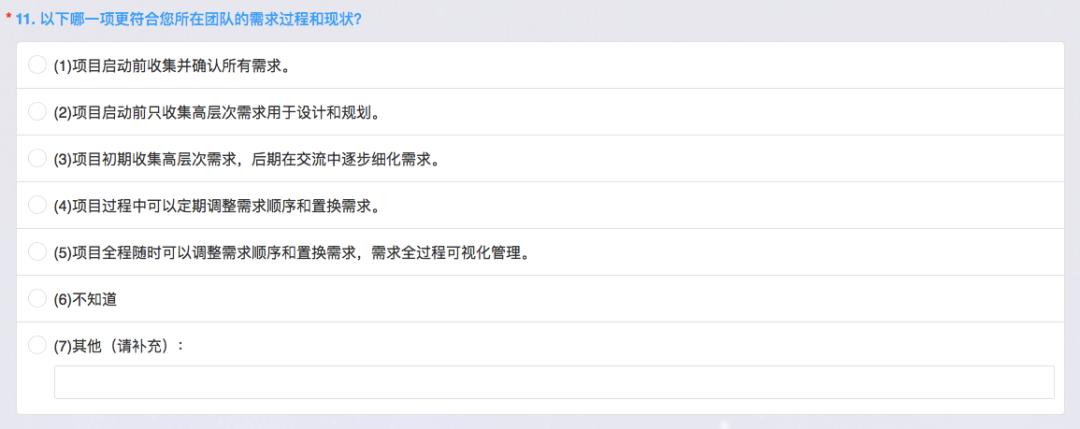
需求管理
需求管理是敏捷当中非常重要的点,需求管理。第一是项目启动前要收集并确认所有需求。让我想起以前在一个企业里面做计划安排是采用项目管理的方式,就有明确的甘特图输出,需要使用类似微软 Project Server 来定义每个人每天做什么事,输出一个最终的计划。
基于我的经验,这个计划的完成率永远是停留在99%。
第四个选项是否符合我的现状,项目过程当中调整需求的顺序。当进入到迭代过程中,并不是需求一层不变,如果确实有需要,可以把一部分需求从迭代中置换出来,置换进高进阶的需求,这样主要是为了保持迭代有一些弹性,同时保证做一些高的需求。这件事情我们可以做到,随时调整可能还没有,因为需要做一些需求优先级的确认和一些简单的变更。
下面来看团队采用的敏捷技术。这里有很多选项,我们使用了每日站会,也使用固定的Sprint 迭代,每个迭代两周时间,发布计划没有主要考虑,也没有做太多的估算,但是看板和任务板有在考虑。全功能没有使用,我们在使用用户故事,通过这种用户格式描述我们的需求。
这里稍切换一下,上面这张图来自宝岛的精益敏捷专家李智桦老师,我们一直在学习他的很多精益敏捷相关的知识,图中是一个完整的 SCRUM 过程 。
刚才非常重要的一个点就是几个实践,比如说影响地图(Impact Mapping),它是用来分析不断挖掘最真实的需求,把需求的价值分析更加清晰。 用户故事地图(User Story Mapping),有一种说法是只见树木不见森林,所以需要通过用户故事地图把整个全景图建立起来,然后在这个过程当中也是一个非常好的实践。
这里面有一个小点提一下,现在越来越多的团队在标准的 Scrum 机制做了改造,开始引入叫 Grooming 的会议,其实有点像需求澄清会,就是计划会之前对需求进行澄清,这也是比较好的实践。比如说双周迭代,我们会在迭代的末期比如周五进行需求澄清,因为开发这个时候已经完成,可能在为下一个迭代做准备。
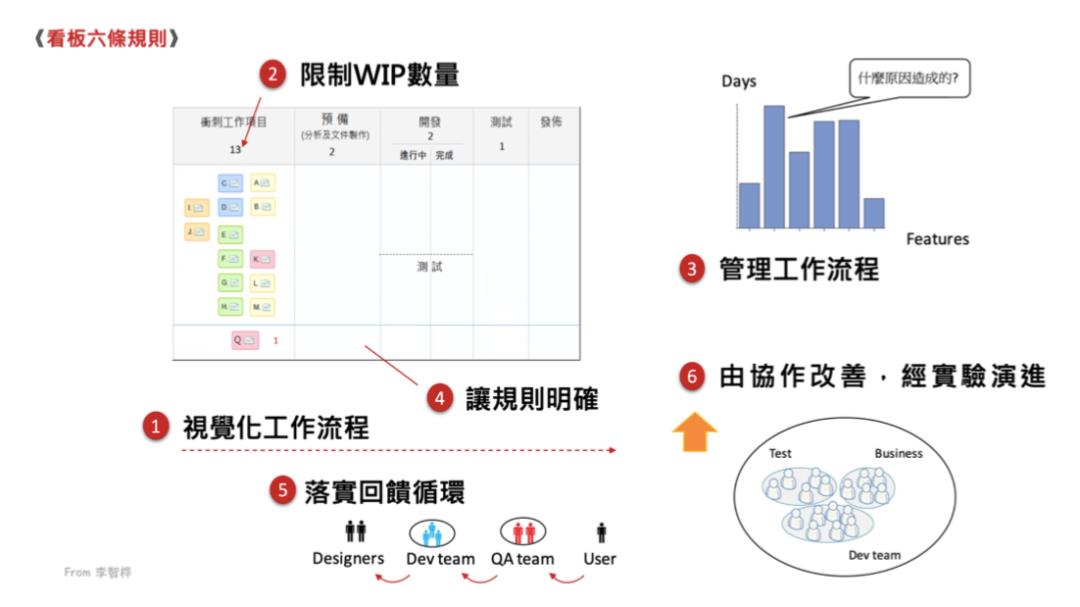
上图是看板,是比较简单的实践,但是也很难,我们能不能把WIP限制下来,能不能把规则做得清晰。每个阶段里面有个数字 2 就是 WIP,意味着我们在进行中可以完成的数量的限制,比较重要的点就是很多人做看板时,存在问题规则明确,这里有两个关键术语叫 DOR 和 DOD。DOR 即 Ready,这个定义就是什么时候可以进入到开发阶段,即我们对需求要有比较明确的验收条件,这是我们要定义的规则。
第二是什么情况下完成?比如开发自测完成、持续交付的流水线通过等,这是看板的实践,目前来说很多时候是看板和 Scrum 混用的方式。
持续交付
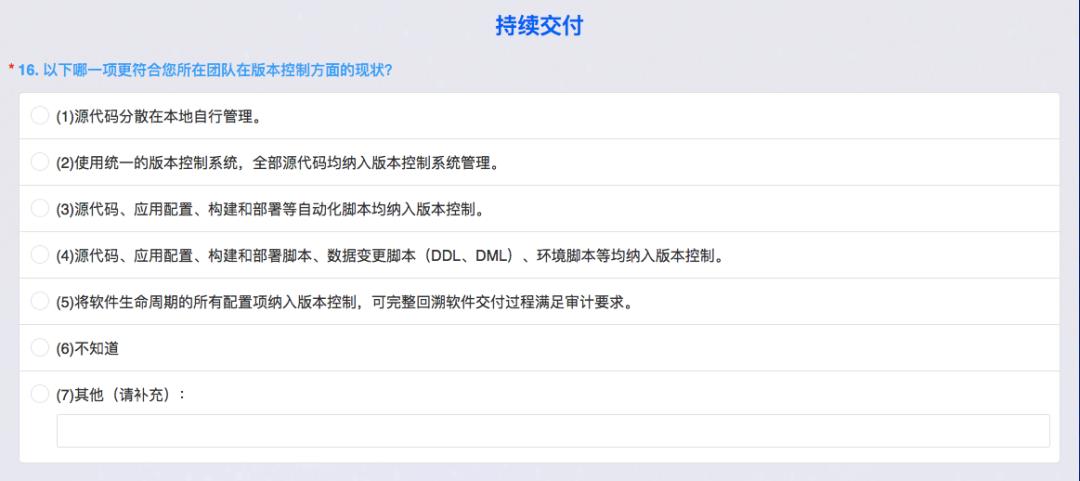
持续交付也诞生了很多优秀的实践,第一是版本控制,即源代码在什么地方管理。进入2020年了,代码在本地有点说不过去。第二个是有统一的源代码版本管理工具,源代码应用配置,比如类似的一些参数等等,还有构建、部署、自动化测试都纳入版本控制,跟我们的描述挺像。后面补充的是数据库变更脚本,也即 DDL、DML;还有环境,因为我们用K8S,Dockerfile 也存在版本控制系统当中,DDL和DML也存储进来,会有回滚脚本的方式。
制品管理
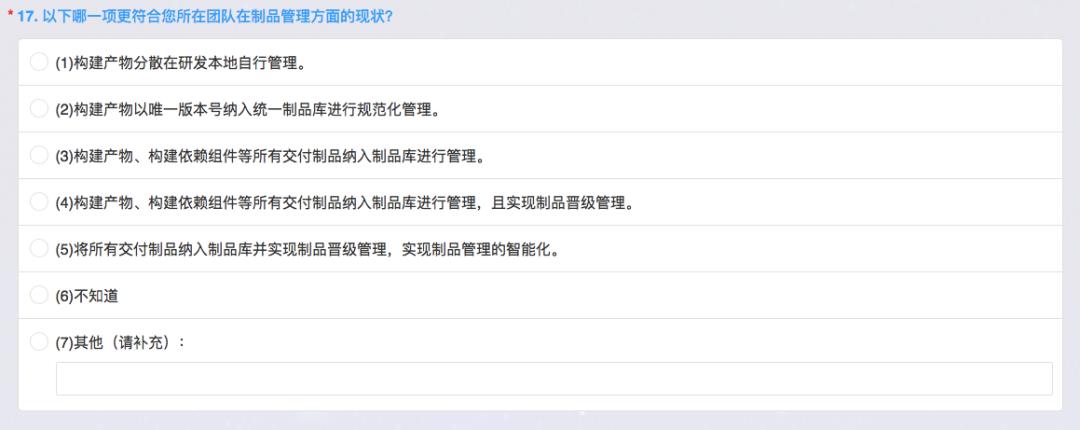
这是制品管理情况,制品主要是指依赖,比如说 JAVA 里的 Maven 依赖及打出来的包等等,如果是微服务就是加包,这里面我看了一下构建的产物,打出来的外包和依赖包都在的 Nexus 或 Artifactory 中,如果是 Docker 可能还有 Harbor 等开源工具。
但第四个选项有一个非常重要的点——实现制品晋级,是指从开发测试到预发布再到生产之间的完整的晋级过程,是需要有质量门禁的。比如从测试进到发布阶段一定需要中间测试和安全扫描通过等晋级过程。尤其是很多金融企业,研发中心与数据中心网络之间可能有隔离,这时甚至需要隔离区的网络把制品同步到生产环境,这个过程中,验证投入到生产包的完整性非常重要。
持续集成
持续集成的现状是什么样?持续集成不是说开发一个月后才集成,而是每天集成,也有统一的集成系统就是 Jenkins,还有两个同学专门维护持续集成,包括升级、维护 Jenkins 的插件和及时更新,因为 Jenkins 有漏洞。但是这个过程要注意插件版本的兼容性,因为 Jenkins 的插件是有版本的,如果升级内核的话可能会导致一些不可用。另外就是刚才说的开发的持续集成平台。
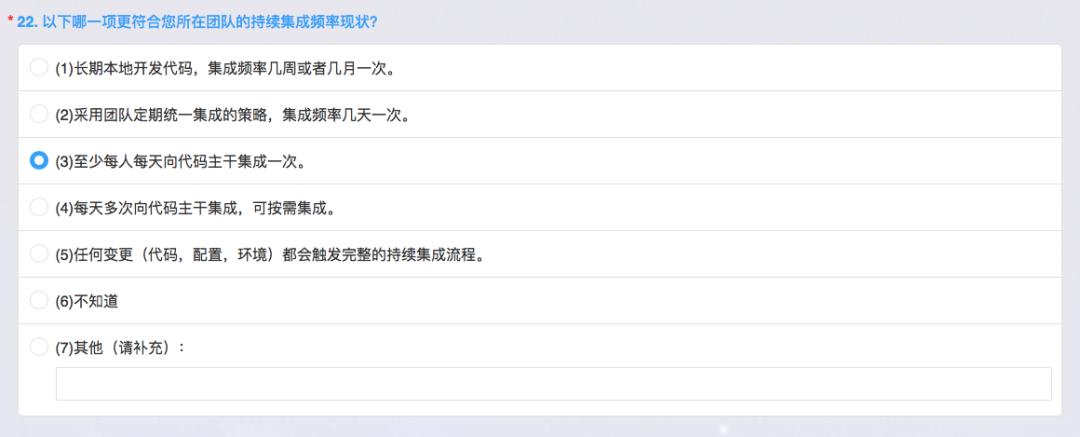
持续集成频率
因为用户故事拆分得很小,像第一个长期在本地开发,那说白了工作都在本地都不提交,第二是集成频率几天一次,比如开发一周才提交一次,这个其实周期也很长,提交的时候,虽然可以采用分模块的方式,但是不利于开发的能力复用。第三个选项,每天每人都会提交一次,其实用户故事拆分到足够在8小时内完成,所以每天都可以有提交去验证,甚至每天可以出测试包给测试人员,每天多次集成这个效率就更高。
持续集成问题修复时长
持续集成修复时长指的就是类似 Jenkins 里有一个红灯,如果出现红灯多长时间能修复?这个是团队规则的要求,持续集成的要求是越快越好,因为红灯可能影响别人的工作,意味着刚刚提交的代码有问题,如果其他人基于我的代码做修改,那说明他自己的也不通过。
我们当前统计的情况是半天到一天,我们在半天以内。举个例子,我在下午两点提交代码,下午五点之前能修复,三十分钟是比较高的要求,十分钟就非常高了,但在持续交付和持续集成领域的两个大神 Martin Fowler、Jez Humble 之前做的持续集成测试,红灯修复能够在十分钟之内完成,说明大神对这个事情的要求很高。
自动化测试
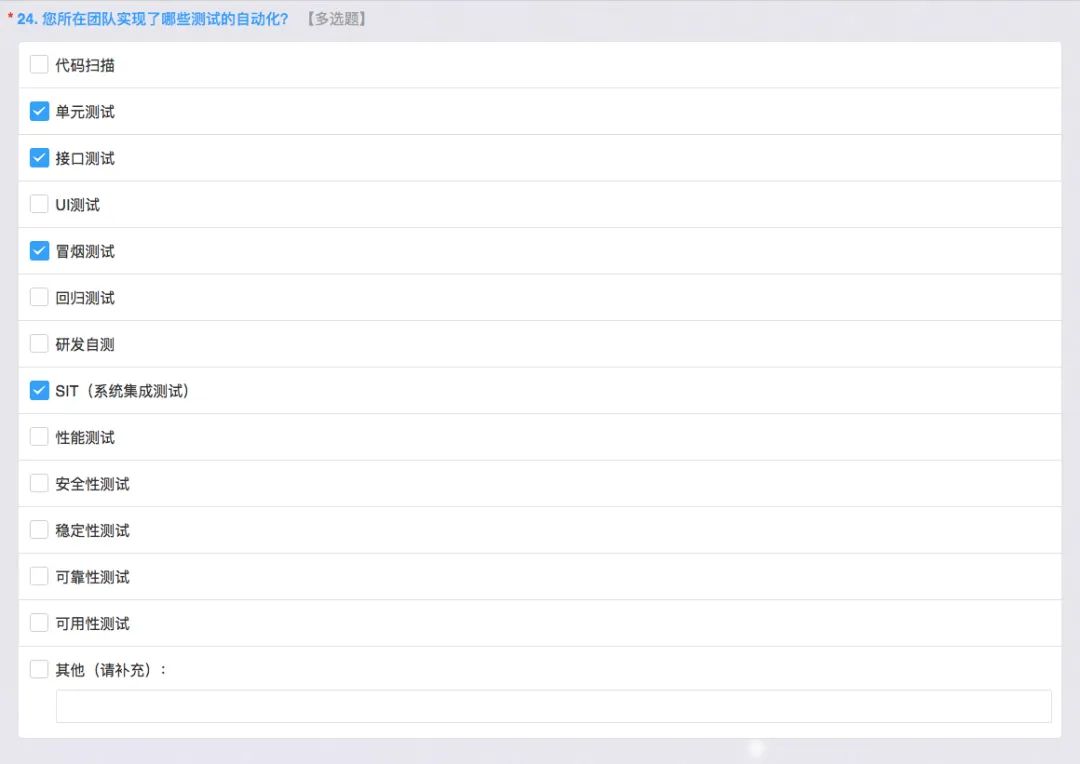
接下来是自动化测试,代码扫描这个工作很难,我们用 Sonar 这样的工具来实现自动化,单元测试肯定是用自动化来扫描,写了一些核心的测试,接口测试也是用自动化,采用 Jmeter 的方式,也有像这样的一些工具等等,还有很多商业的工具都可以做。UI我们这边没有做,UI自动化测试成本非常高,尤其是针对UI经常变化,原来我们是使用比较重型的框架,保证UI基本不变。
冒烟测试,主要是在部署以后测试之前的过程,可以通过一部分接口实现这个过程;回归也是,我们原来有一家企业回归测试需要20多人干两个月才能完成所有的回归,后来通过自动化把这些东西通过统一的接口和少量的UI用例,可以做到类似于两个人来做,两周之内可以跑完所有的用例,而且是好几轮的回归。
研发自测这个目前比较少,SIT 就是系统集成这边基本上也是通过接口的方式,但是可能更多是需要把各个性能协调起来。性能测试是用的像自动化用 Jmeter,调用测试接口用例,就可以相当于增加压力,比如说请求数、并发数就可以。
安全测试最主要可能有一些黑盒,这个领域目前比较空白。稳定性、可靠性、可用性,重点提一下可用性测试,可用性测试目前是在生产环境做一些测试,就是混沌工程方面,阿里有一个开源工具叫 Chaosblade,它会往生产环境注入一些问题,我们简单提一下。
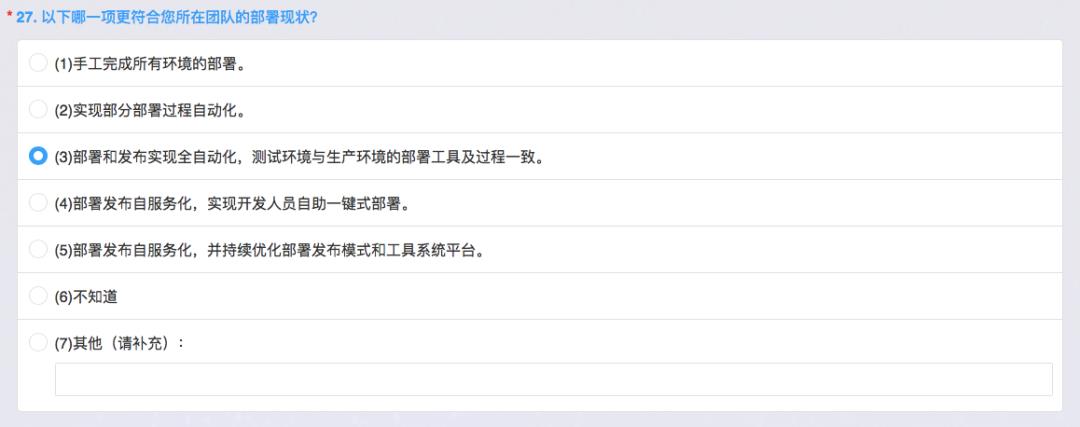
部署现状
后面是部署的现状,包括我们的部署和发布都已经实现自动化,测试环境和生产环境工具和过程是一致的,但是有很多团队没有做到,因为测试环境是测试人员自己布、人工的,如果是这种方式可能在二级。我们当前都是用K8S,所以是完全一致的。
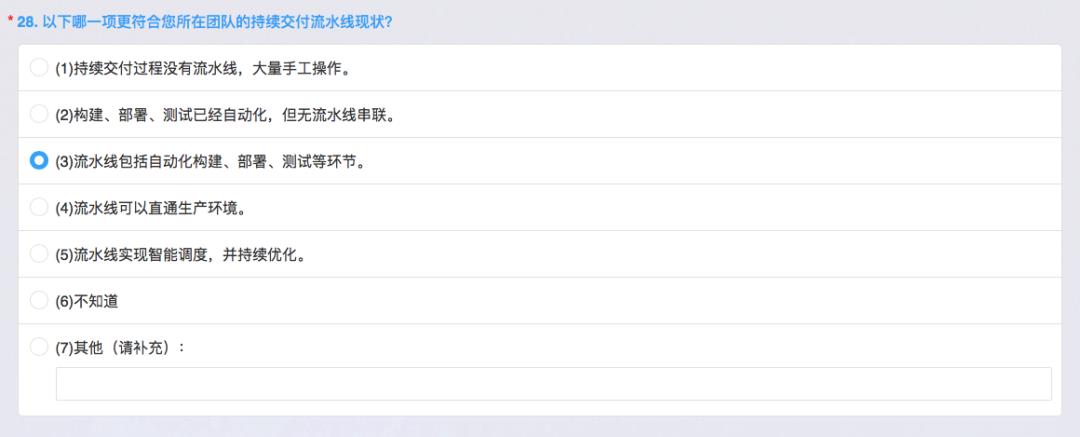
流水线
这是流水线的状况,如果没有流水线,就选第一个;第二个选项是已经自动化,有构建和部署也有测试,但是没有串起来。三级已经把构建部署等环节串起来,第四个选项是需要自动生产,这个难度很高,尤其是对金融行业的限制。
变更前置时间
这是变更前置时间,指的是从代码提交到生产当中运行需要多长时间。现在需要一天到一周,这个过程当中需要经过严格的测试,人工测试,还有一些简单的审批,所以是一天到一周才能够完成这样的过程。
大家也可以看看你们提交完代码之后多久能上,比如说是今天上午提了之后下午可以上,这个维度不是指 hotfix 的生产缺陷,指的是正常的需求,它不是走紧急流程的这种。 另外有时候我们提交完之后下个月才能发,这种可能更低了。
生产环境部署频率
生产环境多长时间部署一次,我们现在按双周迭代,至少每双周部署一次,也有可能是第一周的周五部署一次,可能就是两次等等这种情况,大家也可以看看我们的迭代频率,我理解如果迭代做得不错,每个迭代都有上线,目前来说大量的企业这一块做得不错。
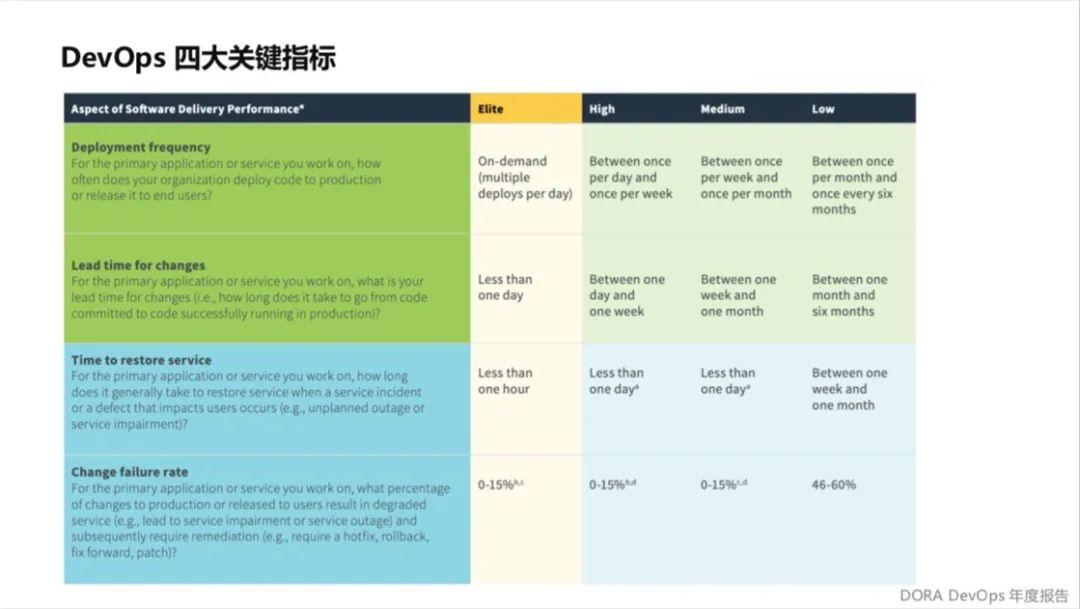
讲工具之前,先给大家讲一个技术点,这个是国外 DevOps 的报告,这个报告提到了2019 年的四个关键指标,部署频率、变更前置时间、故障的修复时长和变更失败率。
它分成精英组织、高效能、中等效能、低效能几个层级,高效能基本是一天到一周以内做一次部署,至少有一次,变更前置时间是提交完代码到运行到生产是一天到一周,基本上我们可以做到高级的维度。
我记得是2018年底2019年初的时候阿里巴巴发过一个报告,当时有提到阿里巴巴企业内部有一些做得比较好的做到“211”。
“2”是指两周,85%以上的需求可以在两周之内交付,我理解是包括需求提出,提出之后到开发到测试到上线完整过程就两周,基本上意味着两周之内就把需求上上去,“1”指的是85%以上的需求可以在一周内开发完成,所以这个开发的效率还有故事的拆分我理解都是非常厉害的。最厉害是一小时,提交代码之后可以一小时内完成发布,这意味着基本上不需要人工测试,是完备的自动化测试的体系在做。
持续交付相关工具
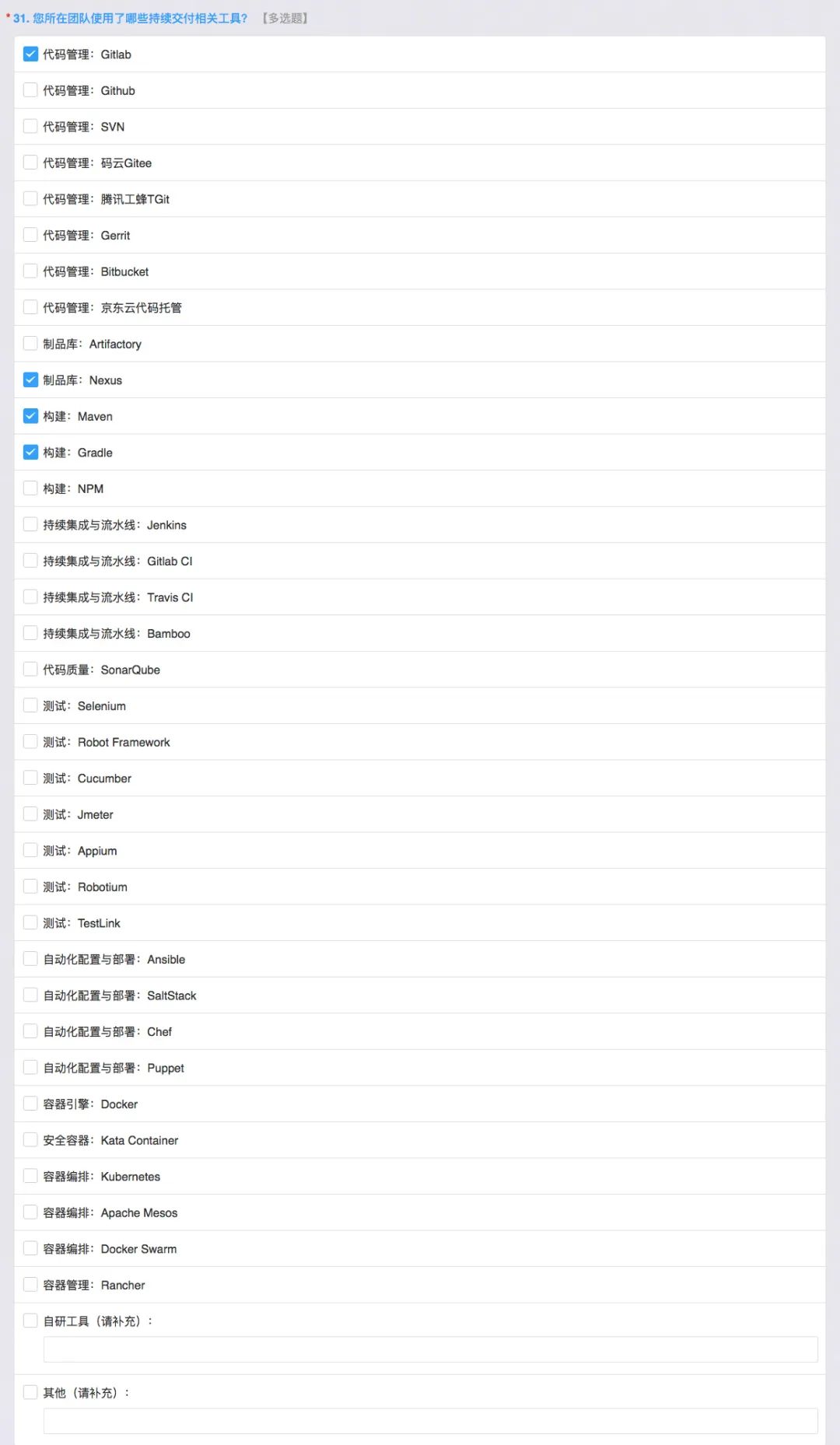
我们接下来看工具,代码管理用的是Gitlab,国内也有码云、腾讯工蜂,开源的还有Gerrit ,如果大家做安卓这套一定会经常用。另外还有一个技术点,微服务模式下有很多企业采用了,比如说 把 20 个微服务的版本统一管理,这时候 Gerrit 和一个配套的工具叫 repo 可以来实现,但是我们不是很常见这种方式,因为很多时候是每个服务自己有版本。
制品这边用的是相当于开源的 nexus,企业版也有很多人同时用 artifactory 等等。构建因为 JAVA 技术栈,Jenkins 的流水线,Gitlab 的 CI,包括像CDF的基金会有很多工具,代码质量用的是 SonarQube,测试用 Jmeter,同时有 Selenium 和 Cucumebr 等很多工具,大家都可以了解。
部署这边我们基本用原生的 K8S 就可以,还有一些配置是用 Ansible 来完成虚拟机上的配置,来保证我们环境的一致性,就是我不会手工在环境上做修改,都是通过 Ansible的 playbook 来完成的。然后 SaltStack 也是很不错的工具,而且它对 Windows 的兼容性好很多,下边还有很多其他的,如果大家有自研的等等也可以写上,这是这一块的问题。
技术运营
继续看技术运营,我可以简单给大家介绍一些内容。第一是监控,这个始终是运维的起始点,非常重要。
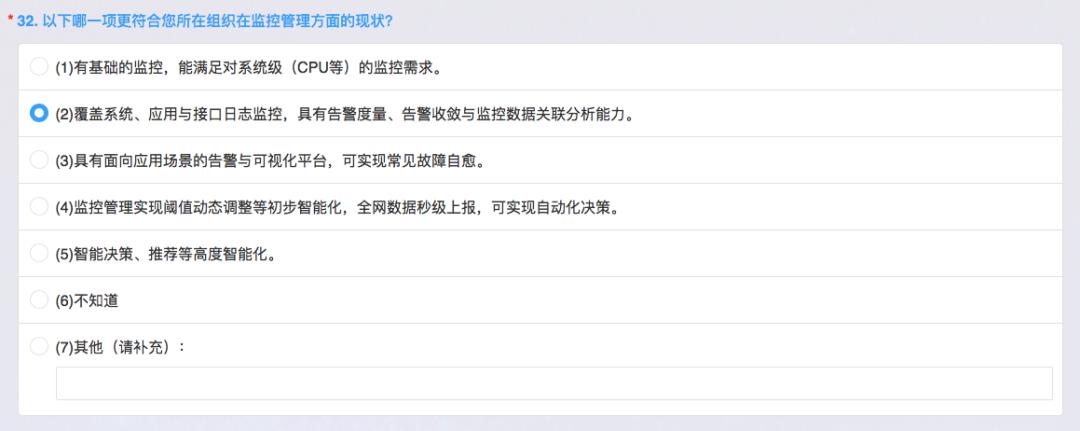
技术运营不仅仅是普通的维护好稳定性,而是要用运营的思路,目前来说基础监控,除了 Zabbix 做到 CPU、内存,还在 ELK 来监控应用、接口日志,这个维度有一个高难度就是告警收敛,告警收敛这个是非常重要的运维技能。
一开始用 Zabbix 的时候,曾经出现过一直都有报警、邮件、电话满天飞,这时是典型故障引发的连锁反应导致告警的泛滥,所以需要做告警的收敛,比如说 Oracle 数据库宕了,但前台请求也出问题,这时实际上应该通过系统收敛直接告诉我是 Oracle 宕了,而不是告诉我前台发不了还是收入端有问题等等,所以这个非常有难度。这个三级确实是让人望而却步,这个叫常见故障的自愈,这个其实是非常高的自动化作业的能力还有告警的能力才可以。
四级是更高的要求,监控我们不是靠人为设置CPU要百分之百,百分之八十就要预警,而是机器学习告诉我们,它想要什么时候预警是由机器告诉我们,而不是靠人工去决策。
事件与变更管理
下一个组织所在的事件和变更管理,第一个是基本的事件管理规范,及时处理,这个可能是比较常见的内容,可能很多我们仅仅只能做到这一块。二级这边要通过比较好的工具来去管理,而且要把流程可视化出来,比如说事件的追踪流程,还有一些变更采用自动化的方式来做,这一块我们还是有一些差距,因为在这个维度的系统不多。
三级比较高的要求就是我们要和其他流程做联动,比如说现在做变更的时候,相应监控也要做调整,比如说往服务器部署的时候,我们的监控需要先移除,部署完之后再把监控加进来,包括信息的采集,往我们的 CMDB 当中做采集等等,这些都非常地难。国内目前来说,像之前有通过技术运营评级的像北京移动还有华泰证券都在二级这个维度,都是很有难度的挑战。
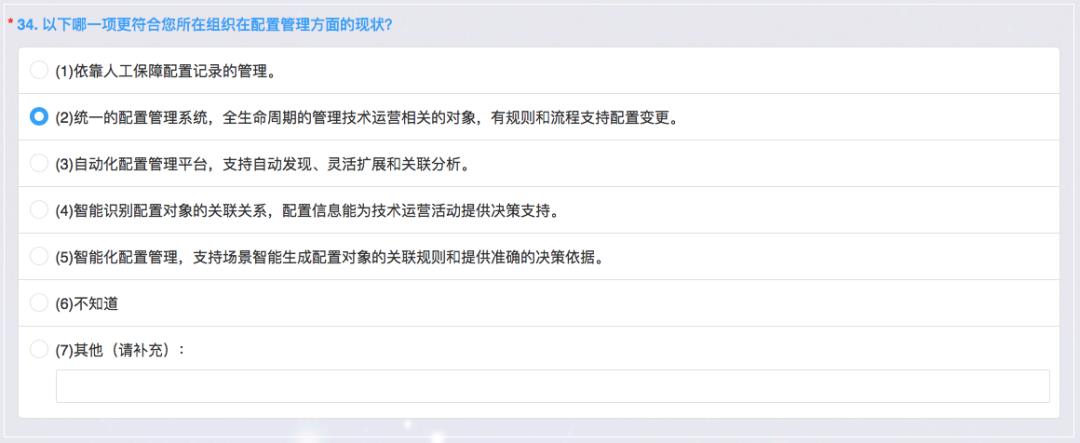
配置管理
下一个是配置管理,运维的配置管理和开发的配置管理是两件事情,这个指的是CMDB,目前来说我们已经有一个初步的 CMDB,而且是很多包括机器、资源各种都在管理,而且有流程支持的配置变更,如果要改配置都有一些流程,但是我们现在自动发现这一块做得比较弱,因为agent这边需要有比较强的能力的。
再往下就是容量和成本,目前只能做到基础预算,我们是通过制定预算的方式和估算,还做不到说全生命周期的容量和成本整体的把握,这里边也没有必要清晰的规则,可能大型的企业会往这个方向做,更别提我们基于这个生产环境的这些业务容量的规划来去灵活控制,比如说我们可以针对机器的弹性等等可以灵活采购和销毁机器,这可能是云的能力。
高可用
高可用方面,我们现在不仅仅是在硬件故障能够完成切换,我们可以有一些更高级的,应用服务调用的关系治理平台,我们可以知道两个服务之间的调用关系,另外IT系统确实中间打通了,我们能够知道说有故障,我们也在数据库之间做了分离,做了主备的同步,所以基本上能够做到这一级。但是三级的难度非常高,能够自动化的动态做扩容,这个时候分布式技术是非常重要的。
业务连续性
业务连续性。一个新词叫做 RTO,这个也是普遍、专业的定义,指的是修复的时长,其实这个维度我们能做到的是通过算法算出来3个9,因为至少半年做一次演练,同时有非常充分的应急响应预案,所以在30分钟之内我们都能修复,不一定把这个问题完整修复,可能做降级等等一些事情。第三个选项,别看加了一个0.05,其实这个是非常难的,需要我们快速响应,而且需要主动做模拟注入故障,这就是我们说在生产环境中做混沌工程非常重要的要点。
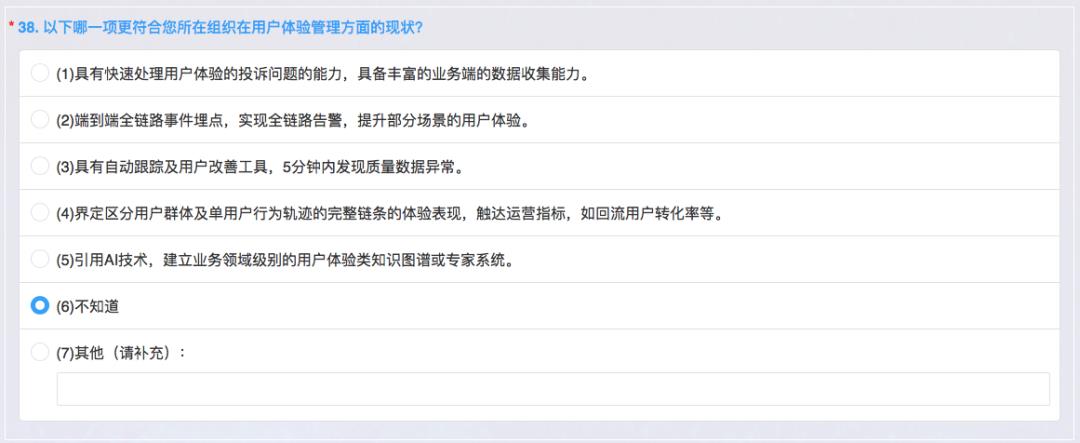
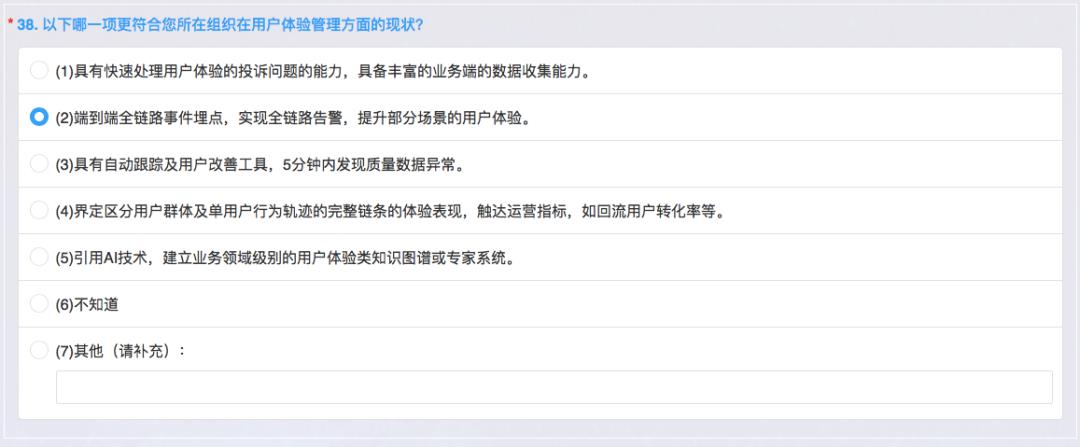
用户体验
用户体验是技术运营标准非常重要的内容,就是我们不仅仅是关注系统稳定,可用不可用,需要关心用户自己用得好不好,所以目前来说可以有一些产品里做投诉的渠道,能够通过运营做一些数据分析快速获取监控数据来去看用户体验,包括页面访问,比如做用户性能监控、页面访问的效率等等,这个全链路埋点我觉得也还可以。
如果出现问题也可以有告警,所以其实从WEB端、移动端进来,到数据库整个的全链路响应我们都能做到。但后面这个自动跟踪和用户改善这一块做得比较差一些,这个确实是非常高的要求。
应用设计
微服务框架
下一个来到应用设计,最主要第一个是看使用了什么微服务框架,我们这里面是使用了Spring Boot,所以这个是比较明确的答案,当然也可以有很多,因为微服务最大的价值是可以跨技术栈,大家如果有其他的可以写在里面。
应用架构设计
之后是团队应用架设和架构方面,目前来说因为运维服务,所以肯定不是巨石架构,另外也不是简单靠经验来去拆分这个模块,然后是由专业的架构师做设计,所以现在是按这种。四级的高要求就是架构设计要有可用性、可测试性明确的度量,目前我们比较弱。
接口管理规范
接口是非常重要的,我们有接口规范,也是强制实施,但是目前还没有做起来接口的开发库和查询平台,接口管理平台目前来说做得还不是很好。
应用可伸缩性
应用的可伸缩性,二是手工通过再部署一台机器来实现伸缩,这个目前来说基本上就是不是这种模式,因为在K8S上可以做参数调整实现应用的伸缩,提高横向扩展能力。四级确实还是做不到完全自动化。
应用故障处理
应用故障处理目前来说最主要是通过,每个系统有自己独立的,比如说可以在系统里面实现降级的能力,通过人工完成这件事情,但是确实还不能完全做到全自动的方式,而是通过人工的切换来实现,这个也是一个挺难的点,就是故障。
应用性能
应用性能刚刚说有一些简单的应用性能整体的设计,但是说非常全面的系统,包括全链路,多个模块和服务之间做到整体的性能优化还是比较难的。
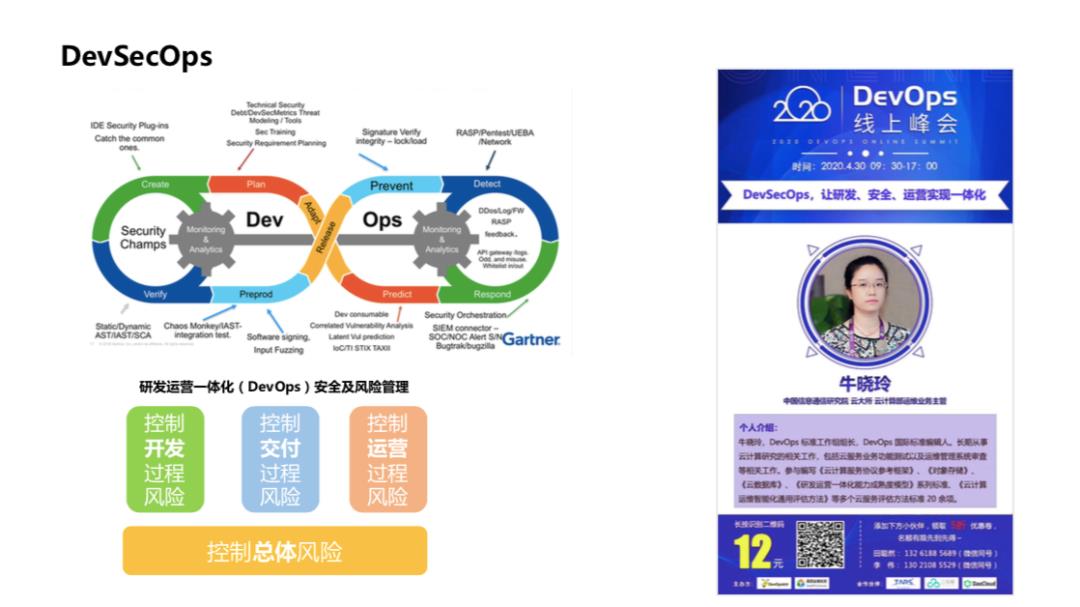
安全及风险管理
安全及风险管理,这个维度我们现在使用 DevSecOps。什么是 DevSecOps?大家可能很多人见过这张图,这个是 Gartner 对 DevSecOps 设计的一张图,细节内容很多,我们今天不用细讲,下面是由信通院牵头的 DevOps 系列标准当中的安全及风险管理模块。
这里主要从控制开发过程,开发有哪些,包括需求、设计、交付、测试、扫描、运营包括监控,技术运营,运维的监控,还有一些漏洞的扫描、收集等等,另外就是总体包括组织架构、组织结构的设计、人员的培养、工具的建设、度量等等,
这里也有个小广告,4月30号由信通院的牛晓玲老师在DevOps 线上峰会来去分享 DevSecOps 研发安全运营实现一体化,会详细讲到这个标准当中的内容,非常有价值的一些参考,也欢迎大家关注。
安全
下面是关注哪些方面的安全,首先是需求里面是否有安全需求,比如说我们是一个转帐业务,那我们里边的安全需求会有哪些,代码安全是我们关注的,设计是目前我们做得差的,比如威胁建模。第三方库的安全我们肯定会关注,比如说像去年FAST+这样的漏洞其实给我们带来很多的困扰,后面的第三方合作机构,因为我们是自研,所以没有第三方合作机构和人员,但是有的时候是调用别人的服务。
安全测试和漏洞扫描需要的,安全监控也是考虑的,大家也可以自己对安全的关注有哪些,还有云平台安全我们也会关注,自动化测试是添加哪些的,最主要是代码扫描阶段和测试阶段比较多,其他方面可能少一些。
自动化安全测试
然后就是交付过程的安全,我们最主要关注源代码,PI组件也有,也有安全扫描和测试工具,而且在流水线里面集成的安全测试,如果没有集成安全测试到流水线可能就是到二级,但是我们集成了,所以每次往生产推包之前测试过程当中我们都会有流水线,所以每个版本一定都会经过安全的测试。
运营过程当中的安全,我们是做了一些监控的,但是可能说没有把这个信息做总体的汇总,比如说有一个安全的监控管理平台和漏洞的集成管理平台,目前来说比较薄弱,更别提智能预警和自愈。
工具这个维度,这边了解得不多,大家可以关注你们在使用的,我们这边使用过 Fortify和 Checkmarx,现在用 Checkmarx,然后这里边 Clair 是容器安全比较主流的工具,还有 OWASQ ZAP 等等,这后边很多的工具我们都没有使用,Black Duck 像是开源软件的协议等等,这边有一个Snyk,这个我不知道大家了不了解,像 DevOps 之父叫 Partick,然后它是今年加入了这家公司,是推进 DevSecOps 相关的内容。
敏捷及 DevOps 转型现状
最后一个是敏捷和 DevOps 转型,其实除了能力,转型也非常重要,转型过程我们怎么判断转型是否成功?我认为客户满意度很重要,但是这个跟敏捷转型和 DevOps 转型好像没有那么相关,因为我们做 DevOps 可以正确做事,但是是不是做到正确的事情,比如说产品到底怎么样,目前还是没有这方面的考虑,所以没有选第一个。
按时交付肯定是,另外交付出去有没有足够多的业务价值,产品质量提升上来了,比如说我们的缺陷泄露率降低了,我们生产的BUG也好,漏洞也好,减少了,另外是研发效率提升了,比如说需求的交付时间、交付周期缩短了,另外是项目可见性,因为我们整个建立完整的流水线和看板,所以我们对整个项目的进展情况是清晰的。然后团队满意度也是非常重要的指标,但是也不好衡量,可以看看比如说我们团队是每天筋疲力尽,还是做起事情上非常有战斗力。转型成功的标志其实就是目前来说比较难以判断,可能通过模型是否能够给我们一个比较合理的判断。
后面是 DevOps 和敏捷转型采取哪些方式。培训是一个比较重要的内容,这个确实是比较关键的点,高层重视非常重要,基层员工引入这个我们没有,是通过自上而下推进,而且成立了转型小组。
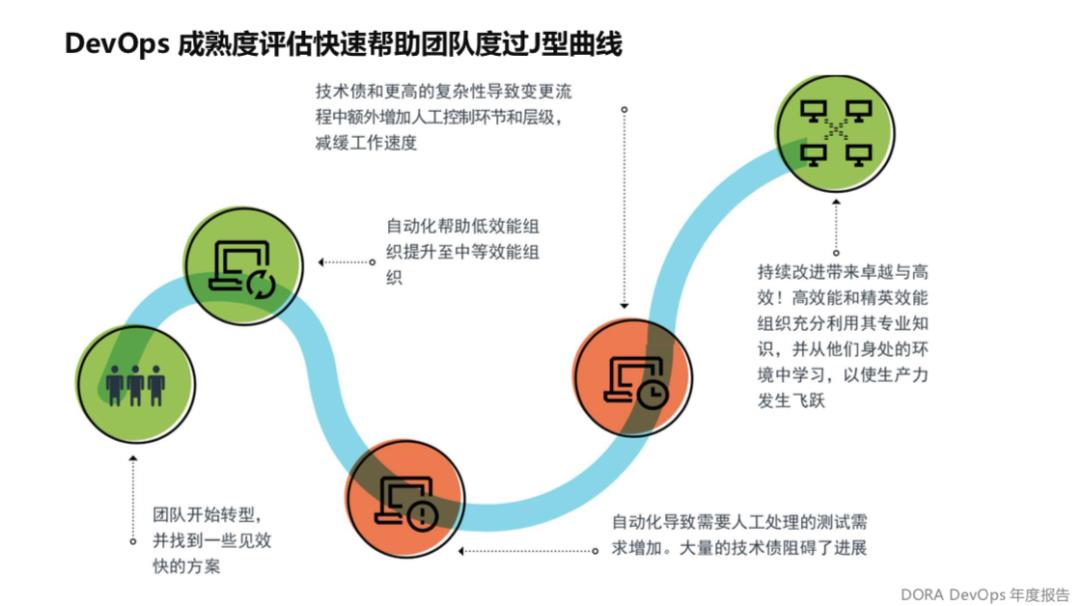
这个点可能大家觉得很有意思,为什么引入 DevOps 标准加速转型,也算是一个小广告,大家可以关心这个事,是我目前总结出来非常重要的点,也是报告提到的有一个J型曲线,其实有很多企业转型的时候没有迈过J型曲线,因为一开始我们做快速转型,比如说上了CI/CD,然后把代码扫描加进来了,这个瞬间感觉很多数据出来了,有一些成效,自动化确实帮助我们提升了一些能力。
但接下来会面临改进的深水区,比如自动化导致需要人工处理的测试的需求增加,自动化测试的成功率特别低,经常需要人工干预,另外有很多技术栈,老板不给我们时间我们没有办法改进这些技术栈,每天业务压力也很大,所以有大量的企业在这里过不去。
但是我们为什么认为 DevOps 成熟度评估可以帮助这件事?就是在信通院的评估里面,企业高层领导会很重视,因为这个东西可以整体提升企业的能力,所以团队会得到一定的授权和外部的支持,来优化技术栈和降低系统的复杂度,提升自动化程度来迈过J型曲线,这是非常重要的点,所以也希望大家能够更多引入 DevOps 标准评估来加速转型过程。
度量指标现在是定义了各个部分的独立指标,不能内部,还没有建立基于成熟度的方式,什么叫基于成熟度?类似于对整个团队从开发、测试、运维各方面都有指标输出,像一开始看到能力成熟度模型一样,我们现在做不到这个事,度量非常困难,目前很多企业做度量都是一个难点,因为度量是跟考核挂钩,都是一个问题。
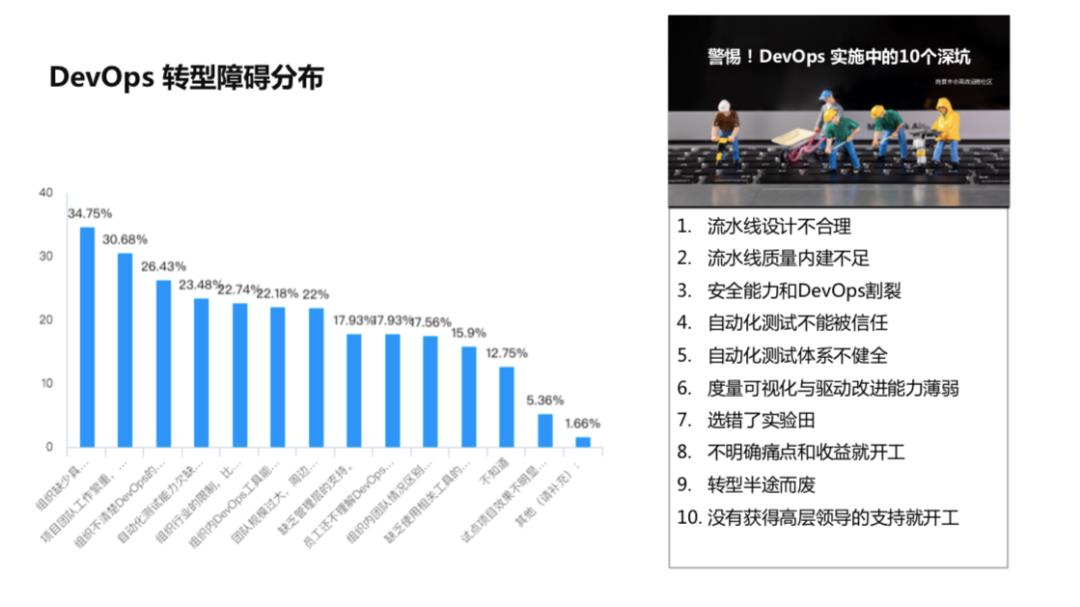
后面是一些障碍,比如说现在没有行业的障碍,但是不清楚路线图,也没有专家支持我们,领导算是支持的,工具可能还比较薄弱,项目组的工作量也很繁重,没有时间改进,团队规模现在也不算太大,相关的专业知识还可以,另外自动化测试缺得比较多,大家看到这道题,我再给大家一个简单的分享。
这个是到目前为止,由信通院提供给的数据,识别到了 DevOps 转型过程大家认为普通的难点。第一是组织内缺少具备 DevOps 经验专家,所以很多时候团队没有专业人士指导和专家支持,所以推进比较难。
第三是组织不清楚 DevOps 改进的路线图,自动化测试能力缺失也是。右边是之前社区施景丰老师给大家分享 DevOps 转型过程中的十个坑,像里面的试验田,转型半途而废,没有得到领导支持,大家如果感兴趣可以去关注施景丰老师的分享。
继续往下是工具方面,主要考虑价格、开源与否、知名度。工具的应用性非常关键,因为很多时候给开发团队用,不重视体验,其实开发同学也是用户,也需要一个很好的用户体验和很好的平台,二次开发可以定制化,公有云部署和私有化部署也是比较关键的内容,DevOps 平台目前来说,这上面是一些比较大型的平台类工具,目前我们没有专门使用工具平台,而是采用自研的,给大家写一个名字。
后面的投入其实计划引入 DevOps 的专业工具和服务,也希望能够持续提升这一块,这个是信通院这边的评估的调研。
这就是问卷的整体内容,现在我们填完点一下提交,提交成功之后就会生成这样的图,我最后的结果是全面级,敏捷还可以,技术运营能力一般,应用设计OK,这是我们得分的情况,也欢迎大家去转发这样的问卷,让他们对自己的能力有一个整体的了解,至少知道我是全面级的能力,还有薄弱的环节在什么地方。
看完本文,你是否对问卷已经有了一个全面的了解?扫描下方二维码,立即自查 DevOps 能力成熟度。
就能免费获取您企业的 DevOps 能力
错过直播了,没关系,我们为您准备了直播的回放 ⬇️
扫描上方二维码,进入直播回放 ▲
近期好文: 投稿邮箱:jiachen@greatops.net,或添加联系人微信:greatops1118.
以上是关于DevOps 做到 BATJ 级别,你需要这份完整的参考指南的主要内容,如果未能解决你的问题,请参考以下文章