代码视角深入浅出理解 DevOps | 原力计划
Posted CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了代码视角深入浅出理解 DevOps | 原力计划相关的知识,希望对你有一定的参考价值。

对于 DevOps 的理解大家众说纷纭,就连维基百科(Wikipedia)都没有给出一个统一的定义。一般的解释都是从字面上来理解,就是把开发(Development)和运维(Operations)整合到一起,来加速产品从启动到上线的过程,并使之自动化。这个是对 DevOps 的广义解释,而且大多数人都是认可的。但这个解释太宽泛了,几乎包括了 IT 的所有内容,使之没有太大意义。而 DevOps 是近几年才兴起的(2014 年才开始流行),它是对某种项目模式的描述,是有着其特定内涵的。任何项目都可以分成开发和运维两个部分,而开发的一整套流程和工具在 DevOps 之前早就有了,并没有改变。
DevOps 真正改变的是运维。因此从运维的角度去理解 DevOps,才能抓住它的本质。你可以把它理解为用开发的方式做运维(Operation as Development),这就是对它的狭义的理解。开发的方式就是写代码,换句话说 DevOps 就是通过写代码来做运维。
运维里一个非常流行的概念叫“Iac(InfrastructureAsCode)” 基础设施即代码,也就是把运行环境的创建用代码的形式来描述出来,通过运行代码来创建环境。它是运维领域的一场革命,开创了现代运维技术,它也是 DevOps 的基石。但基础设施创建只是运维的一部分,如果我们把这场革命继续延伸到运维的各个领域,让代码覆盖整个运维,那时就是代码即运维(Operation as Code),这才是 DevOps 的精髓。
那么从一个应用程序项目的角度看,什么是 DevOps 呢?它就是把应用程序的代码和运维的代码都放到一个源程序库中,并对它进行版本管理,这样你就拥有了关于这个项目的所有信息,随时可以部署这个程序(包括程序本身和它的运行环境),而且可以保证每次创建出来的程序的运行结果是一样的(因为它的运行环境也是一样的)。

运维即代码(Operation as Code)
下面我们就把运维所做的事情一件一件拆分开,看看他们是怎么用代码来实现的。
运维的工作通常包括下面几个方面:
基础设施:即程序运行环境的创建和维护。
持续部署:部署应用程序,并使整个过程自动化。
服务的健壮性:是指当服务的的运行环境出现了问题,例如网络故障或服务过载或某些微服务宕机的情况下,程序仍能够提供部分或大部分服务。
运行监测:它既包含对程序的监测也包含对运行环境的监测。

基础设施即代码(Infrastructure as Code)
我们通过一个 Go(别的语言也大同小异)微服务程序做例子来展示如何用代码来创建基础设施。程序本身的功能非常简单,只是用 SQL 语句访问数据库中的数据,并写入日志。你可以简单地把它分成两层,后端数据访问层和数据库层。程序的部署环境是基于 k8s 的容器环境。在 k8s 中它被分成两个服务。一个是后端程序服务,另一个是数据库(用 mysql)服务。后端程序要调用数据库服务,然后会把一些数据写入日志。
在这种新的模式下,运行环境的代码和应用程序的代码是存在一个源码库中的,这样当你下载了源码库之后,你不但拥有了程序的所有源码,而且也拥有了运行环境的源码。这样当要创建新的运行环境时,只要运行一遍代码就能创建出整套的运行环境,而且每次创建出来的环境都是一致的。
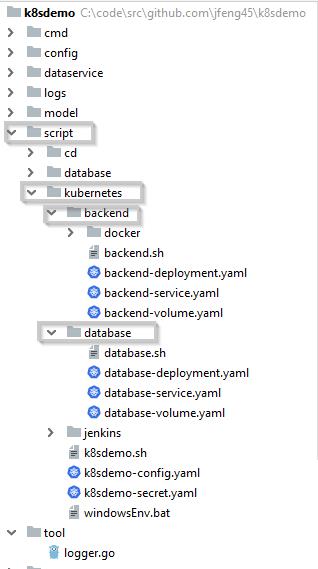
上面就是这个 Go 程序的目录结构,它里面有一个目录“script”是专门存放与运行环境相关的文件的,里面的“kuburnetes”子目录就是整个运行环境的代码。除了“script”之外的其它目录存有应用程序的代码。这样,与这个应用程序有关的信息都以代码的方式保存在了一个源代码库。有了它之后,你可以随时部署出一个相同的程序的运行环境,而且保证是一模一样的。
“kubernetes”目录下有两个子目录“backend”和“database”分别存放后端程序和数据库的配置文件。它们内部的结构是类似的,都有三个“yaml”文件:
backend-deployment.yaml:部署配置文件
backend-service.yaml:服务配置文件
backend-volume.yaml:持久卷配置文件
另外还有一个“.sh”文件是它的运行命令,当你运行这个 Shell 文件时,它就调用上面三个 k8s 配置文件来创建运行环境。
kubernetes 目录的最外层有两个“yaml”文件“k8sdemo-config.yaml”和"k8sdemo-secret.yaml",它们是用来创建 k8s 运行环境参数的,因为它们是被不同服务共享的,因此放在最外层。另外还有一个"k8sdemo.sh"文件是 k8s 命令文件,用来创建 k8s 对象。
这种源程序结构的一个好处就是使应用程序和它的运行环境能够更好地集成。举个例子,当你要修改服务的端口时,以前,你需要在运行环境和源码里分别修改,但它是分别由开发和运维完成的,这很容易造成修改的不同步。当你把它们放在同一个源码库中,只需要修改一个地方,这样就保证了应用程序和运行环境的一致性。
下面就是后端服务的 k8s 配置代码:
apiVersion: v1
kind: Service
metadata:
name: k8sdemo-backend-service
labels:
app: k8sdemo-backend
spec:
type: NodePort
selector:
app: k8sdemo-backend
ports:
- protocol : TCP
nodePort: 32080
port: 80
targetPort: 8080由于篇幅的关系,这里就不详细解释程序了,有兴趣的请参见如何把应用程序迁移到 k8s[1]。
基础设施可以分成两个层面,一个就是上面讲到的 k8s 层面,也就是容器层面,这个是跟应用程序紧密相关的。还有一个层面就是容器下面的支持层,也就是虚机层面,当然还包括网络,负载均衡等设备或软件。当你在阿里云或华为云上创建 k8s 之前,先要把这些构建好才行。它的部署也可以用代码来完成。Terraform 就是一款非常流行的用来完成创建的工具,它是被 ThoughtWorks 推荐的(详见 ThoughtWorks TECHNOLOGY RADAR VOL.20[2]),它支持用代码来创建虚机。
代码如下:
resource "aws_instance" "example" {
count = 10
ami = "ami-v1"
instance_type = "t2.micro"
}但在这一层面,基础设施的工作与应用程序的关联并没有那么紧密,因此这部分的代码没有放在应用程序里,你可以单独创建一个基础设施的源码项目,用来存放这部分代码。

持续部署(Continuous Deployment)
部署应用程序是运维的一项重要工作。随着商业竞争的加剧,要求更快的程序更新,从原来的的几周部署一次,到后来的一天部署十几次甚至几十次。这样手工部署就完全不能满足需要,于是就要把整个流程自动化,这就是持续部署。
管线(Pipeline)是一个很重要的概念,它用来描述持续部署的整个步骤和流程。Jenkins 是一款非常流行的持续集成和部署工具,它提出了“管线即代码”(“Pipeline as code”,详见 Pipeline[3])。就是把持续部署的管线也作为程序源码的一部分,和应用程序一起管理起来,让它有着和应用程序一样的版本和复审流程。
下面我们就通过一个具体例子来说明他是怎样实现的。这个例子用的是和上面一样的程序。先来看一下程序的目录结构。
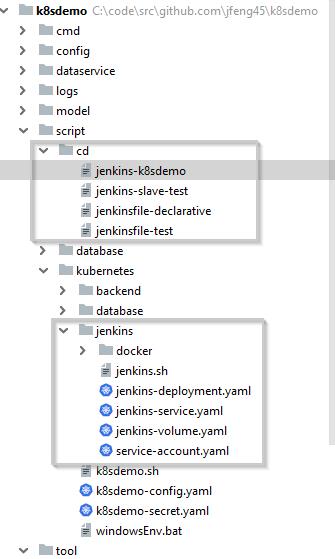
与持续部署相关的文件都在“script”目录下,他被分成两部分,一个是“cd”子目录,它存有 Jenkins 的管线,另一个是“Kubernetes”下的“jenkins”子目录,它存有 Jenkinsde 的 k8s 配置文件。你如果仔细看一下的话会发现它里面的文件和前面讲到的后端程序和数据库的 k8s 配置文件很相似,有了它,你就可以在 k8s 里创建出 Jenkins 的运行环境。
这里我把 Jenkins 的 k8s 配置文件也放在应用程序里了,但实际上它是应该放在前面提到的基础设施项目源码里。因为 Jenkins 是被应用程序共享的,而不是属于单独的一个应用。这里为了说明方便放在一起了,真正用的时候要把它抽取出来。
下面就是管线的代码:
def POD_LABEL = "k8sdemopod-${UUID.randomUUID().toString()}"
podTemplate(label: POD_LABEL, cloud: 'kubernetes', containers: [
containerTemplate(name: 'modified-jenkins', image: 'jfeng45/modified-jenkins:1.0', ttyEnabled: true, command: 'cat')
],
volumes: [
hostPathVolume(mountPath: '/var/run/docker.sock', hostPath: '/var/run/docker.sock')
]) {
node(POD_LABEL) {
def kubBackendDirectory = "/script/kubernetes/backend"
stage('Checkout') {
container('modified-jenkins') {
sh 'echo get source from github'
git 'https://github.com/jfeng45/k8sdemo'
}
}
stage('Build image') {
def imageName = "jfeng45/jenkins-k8sdemo:${env.BUILD_NUMBER}"
def dockerDirectory = "${kubBackendDirectory}/docker/Dockerfile-k8sdemo-backend"
container('modified-jenkins') {
withCredentials([[$class: 'UsernamePasswordMultiBinding',
credentialsId: 'dockerhub',
usernameVariable: 'DOCKER_HUB_USER',
passwordVariable: 'DOCKER_HUB_PASSWORD']]) {
sh """
docker login -u ${DOCKER_HUB_USER} -p ${DOCKER_HUB_PASSWORD}
docker build -f ${WORKSPACE}${dockerDirectory} -t ${imageName} .
docker push ${imageName}
"""
}
}
}
stage('Deploy') {
container('modified-jenkins') {
sh "kubectl apply -f ${WORKSPACE}${kubBackendDirectory}/backend-deployment.yaml"
sh "kubectl apply -f ${WORKSPACE}${kubBackendDirectory}/backend-service.yaml"
}
}
}
}由于篇幅的关系,这里不详细解释。如果有兴趣并想了解如何运行 Jenkins 来完成持续部署,请参阅在容器上构建持续部署及最佳实践初探[4]。
这里我用的是 Jenkins 软件,它另外还有一个子项目叫 Jenkins-x,是专门为 k8s 环境量身打造的,它的主要功能是能够帮助你自动生成管线代码(你需要回答他的一些问题)。如果你不想自己写代码,那么你可以试一下它,详情请见 Jenkins-X[5]。

服务的韧性(Service Resilience as Code)
又叫服务的健壮性,这部分不像前面两个部分有着公认的名字,英文叫“Service Resilience”,翻译成中文就五花八门了,我觉得叫服务的韧性比较合适。
“Service Resilience”是指当服务的的运行环境出现了问题,例如网络故障或服务过载或某些微服务宕机的情况下,程序仍能够提供部分或大部分服务,这时我们就说服务的韧性很强。它是衡量服务质量的一个重要指标。
这部分的功能包括下面几个部分:
服务超时 (Timeout)
服务重试 (Retry)
服务限流(Rate Limiting)
熔断器 (Circuit Breaker)
故障注入(Fault Injection)
舱壁隔离技术(Bulkhead)
这部分与前面两个部分略有不同,前面两个部分都是典型的运维任务,而这部分以前是应用程序的一部分,只是这些年才慢慢开始转移到运维的。
最开始的时候,这些功能都是和程序的业务逻辑混在一起,对业务逻辑的侵入很大,后来,大家开始把这部分逻辑抽取出来,划分成单独的一部分。下面通过一个具体的例子(Go 微服务程序)来讲解:
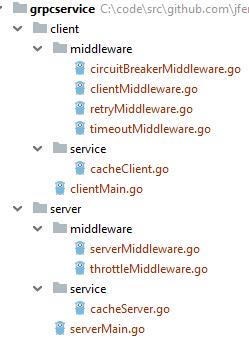
上图是程序的目录结构,它分为客户端(client)和服务端(server),它们的内部结构是类似的。“middleware”包是实现服务韧性功能的包。“service”包是业务逻辑包,在服务端就是微服务的实现函数,在客户端就是调用服务端的函数。在客户端(client)下的“middleware”包中包含四个文件并实现了三个功能:服务超时,服务重试和熔断器。“clientMiddleware.go"是总入口。在服务端(server)下的“middleware”包中包含了两个文件并实现了一个功能,服务限流。“serverMiddleware.go"是总入口。
注意,这里的服务韧性的功能是完全从业务逻辑中抽出来了,对业务逻辑没有任何侵入,它是在一个单独的包(middleware)里实现的。这里用的是修饰模式。有关程序实现的详情,请参阅 Go 微服务容错与韧性(Service Resilience)[6]。
上面讲的是用程序来实现这些功能,但从本质上来讲这些功能不应该属于应用程序,而是应该由基础设施来完成。现在公认的看法是,服务网格(Service Mesh)是完成这些功能的最佳方案。使用服务网格的方式和 k8s 类似,也是创建配置文件,然后通过运行配置文件来建立服务网格的运行环境。我们这里用 Istio 来举例说明,Istio 是一款非常流行的服务网格软件。
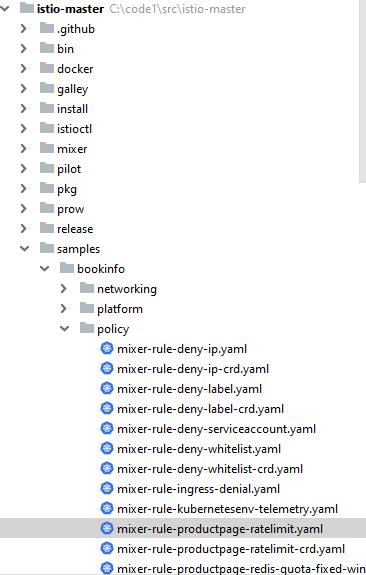
上图就是下载的 Istio 软件的目录,“bookinfo”是它的一个示例程序,在这个例子里,它展示了多种使用 Istio 的方式,其中就有如何实现服务韧性的方法。详情请参见 istio[7]。

运行监测(Monitoring or Observability)
运行监测是运维的一项重要内容,它通常包含如下几个方面的内容:
日志(logging): 记录的是程序运行过程中的信息;
跟踪(tracing): 记录的是与一条请求相关的信息,特别是请求的与时间有关的信息;
指标(metrics): 与上面的离散的信息不同,这里记录的是可累加的信息,一般是按照时间轴进行累加。
我们经常称之为观测的三个支柱(Three Pillars of Observabilty),有一篇很不错的讲解它们之间关系的文章,详情请见”Metrics, tracing 和 logging 的关系“。
这部分的内容可能会有些争议。因为前几个部分都是清清楚楚的运维工作,即使服务韧性,虽然以前是开发的工作,但现在也已经一直公认是运维的事,而且它们的代码都能很干净地摘出来。但运行监测不一样,虽然主要工作还是由运维来完成,但它的代码与业务逻辑代码混在一起,很难摘得清楚。
日志:
这部分的代码都是在应用程序里,但日志的采集,汇总,分析和展示都是由运维来完成。它的代表就是著名的 ELK 系列。采用 DevOps 之后,这里面的变化不大,顶多就是采集代理(Agent)更好地和服务网格或 k8s 进行集成,使之变得更为容易。
分布式跟踪:
这部分有点像服务韧性,开始的时候是由程序完成,慢慢地把它变成单独的部分与应用程序隔离开,最终大部分的工作交由服务网格来完成。但它又与服务韧性不太相同。服务韧性可以和应用程序做一个非常干净的切割,而分布式跟踪取决于跟踪的颗粒度。如果仅是服务之间的跟踪,就一点问题都没有,完全可以由服务网格来完成。但如果是服务内部的跟踪,服务网格就无能为力了,还是要由程序代码来完成,就像日志一样。但我觉得服务之间的跟踪是投入产出比最高的,大多数情况下有它就足够了,不必需要服务内部的跟踪。
详细情况请参见 Go 微服务全链路跟踪详解[9]。
Metrics:
这部分观测的是累加信息。大多数情况下,只要安装好工具,就能采集数据进行分析。最流行的工具是 Prometheus. 你不需要写代码来获取数据,不过你如果想要快速地找到需要的信息,k8s 的配置还是要和 Prometheus 的设置相匹配,因此你需要做一些详细的设计。详细情况请参见 Prometheus and Kubernetes: Monitoring Your Applications[10]。
当然你如果有一些更细致的监测需求,Prometheus 不能直接满足。这时需要在应用程序里插入一些 Prometheus 的监测代码来满足你的需要。

其他工作
是不是还有其他运维工作被漏掉了?
持续集成(Continious Integration)
很多人都把持续集成(CI)算作 DevOps 的重要组成部分,那是因为他用的是广义的定义。按照狭义的理解,DevOps 只包括运维的内容。持续集成(CI)与持续部署(CD)有着明显的不同,持续集成是开发的工作,而持续部署是运维的工作,下图展示了它们的差异。
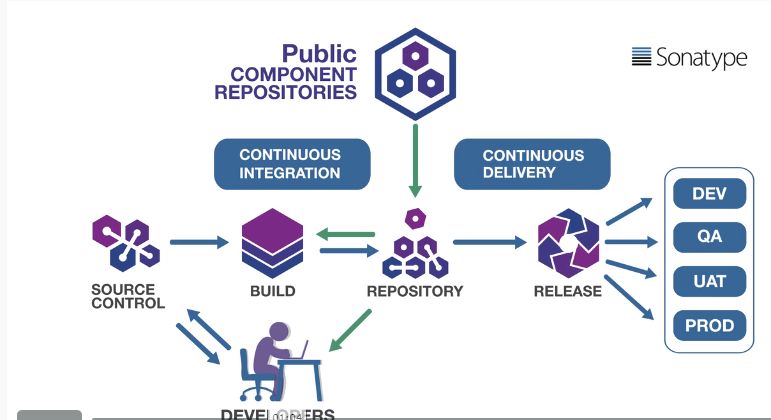
如图所示,整个流程是这样的:
程序员从源码库(Source Control)中下载源代码,编写程序,完成后提交代码到源码库,持续集成(Continuous Integration)工具从源码库中下载源代码,编译源代码,然后提交到运行库(Repository),然后持续交付(Continuous Delivery)工具从运行库(Repository)中下载代码,生成发布版本,并发布到不同的运行环境(例如 DEV、QA、UAT、 PROD)。
图中,左边的部分是持续集成,它主要跟开发和程序员有关;右边的部分是持续部署,它主要跟测试和运维有关。持续交付(Continuous Delivery)又叫持续部署(Continuous Deployment),它们如果细分的话还是有一点区别的,但我们这里不分得那么细,统称为持续部署。
我并没有把持续集成放到 DevOps 里面,因为本文用的是狭义的解释,也就是只包含运维的部分。
结论
本文从代码的视角诠释了对 DevOps 的理解,DevOps 的精髓就是用写代码的方式来做运维,并对运维的各个部分给出了具体的实例,希望能对想采用 DevOps 的朋友有所帮助。DevOps 对开发和运维的改变都是巨大的,尤其是对运维。
在不久的将来,就没有开发和运维之分了,只有一个工作,就是写代码,当然也许会细分成开发码农和运维码农。运维的工作都是通过写代码来完成。应用程序里不但包括业务逻辑的代码,也包括运维的代码,它们会被同时存储在一个源码库中。
完整源码的 GitHub 链接:
k8sdemo:https://github.com/jfeng45/k8sdemo
grpcservice:https://github.com/jfeng45/grpcservice
https://blog.csdn.net/weixin_38748858/article/details/103068797
CSDN 经作者授权发布。
索引:
[1] https://blog.csdn.net/weixin_38748858/article/details/102758381
[2] https://assets.thoughtworks.com/assets/technology-radar-vol-20-en.pdf
[3] https://jenkins.io/doc/book/pipeline/
[4] https://blog.csdn.net/weixin_38748858/article/details/102967540
[5] https://jenkins-x.io/
[6] https://blog.csdn.net/weixin_38748858/article/details/100781369
[7] https://github.com/istio/istio
[8] https://wu-sheng.github.io/me/articles/metrics-tracing-and-logging.html
[9] https://blog.csdn.net/weixin_38748858/article/details/100586019
[10] https://www.weave.works/blog/prometheus-and-kubernetes-monitoring-your-applications/
以上是关于代码视角深入浅出理解 DevOps | 原力计划的主要内容,如果未能解决你的问题,请参考以下文章