黑客级Kubernetes网络指南
Posted 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了黑客级Kubernetes网络指南相关的知识,希望对你有一定的参考价值。
我们借助于Docker在Iguazio构建的是原生云平台。使用到微服务、etcd、home-grown等Docker集群管理工具。 目前我们正在逐渐迁移到使用Kubernetes作为容器的编排引擎,因为这些已经变得越来越成熟,我们就可以利用其更先进的功能专注于提供独特的服务。
与其他很多原生云应用不同,我们更专注实时性。为了提高应用的性能,我们使用底层直接访问网络、存储、CPU和内存资源。对于容器和Kubernetes来说,这一点非常重要,而且需要使用一些独特并不常见的黑科技手段突破。
这篇文章是这个系列的第一弹,我主要分享下如何使用一些黑客的技巧学习Kubernetes和容器网络接口的内部构件,以及如何操作它们。后续的博文将会覆盖高性能存储、进程间通信(IPC)在容器中的使用技巧等。

容器使用的是Linux 中叫做Cgroups和Namespace的分区的功能来实现的。容器进程映射到网络、存储和其他的命名空间。每一个命名空间只能看到操作系统授权的那一部分,通过这种方式做到容器之间的隔离。
在网络方面,每一个命名空间都有自己的网络堆栈,包括网络接口、路由表、Socket 和 IPTABLE规则等。一个接口只能属于某一个网络的命名空间。使用多容器就意味者需要多接口。另外一个选择是生成伪接口,并将它们软连接到真实的接口(我们还可以将容器映射到主机网络的命名空间,如守护进程的使用)。
下面是创建并连接伪接口的几种选择:
虚拟桥:在容器的一侧创建虚拟接口对儿,另一方面再根命名空间中创建虚拟接口对儿,并使用Linux桥接器或者OpenvSwith(OVS)来实现容器和外部接口的连接。与直接方法相比,桥的引入会有一定的额外开销。
硬件交换:当前大多数NIC都已经支持单节点 I/O虚拟化(SR-IOV),这也是创建虚拟设备的一种方式。每个虚拟的设备都将自己显示为单独的PCI设备。它可以拥有自己的VLAN和硬件强制的QoS关联。SR-IOV提供裸机性能,但通常再公共云中不可用。
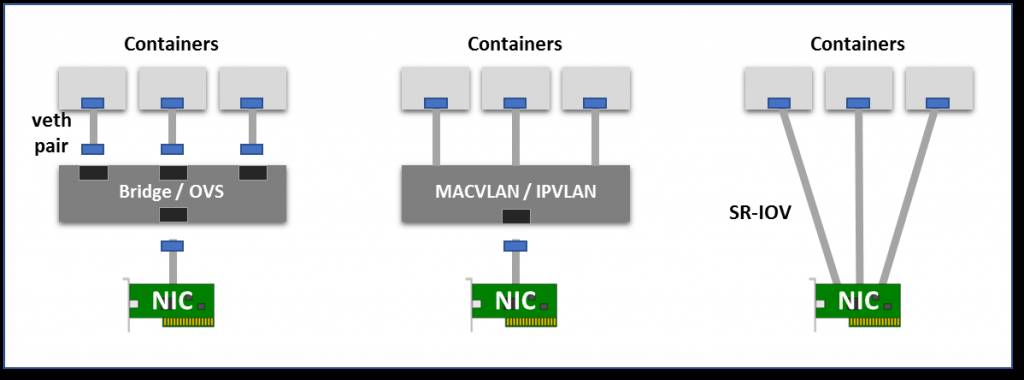
虚拟网络模式:虚拟桥、多路复用和 SR-IOV。
在很多场景下,用户希望可以创建跨越多个L2/3网段的逻辑网络子网。这需要覆盖封装协议(最常见的VXLAN,它将网路进一步包装成UDP的数据包)。VXLAN可能会引入更多的网络开销,而且由于控制中缺乏标准化,来自不同供应商的多个VXLAN网络通常不能互相操作。
Kubernetes还广泛使用IPTABLES和NAT来拦截流量,并将其路由到相应的物理目标。像Flannel,Calico和Weave使用Veth与桥接/路由器和覆盖或者路由/NAT的操作作为容器网络的解决方案。
有关各种Linux网络选项,请参与这个很好的实践教程和使用指南(http://suo.im/JGwKn)。
除了预期的数据包操作额外开销外,虚拟网络增加了隐藏的成本,可能会对CPU和内存并行行造成负面的影响,例如:
NIC根据报文的消息头将流量引入到内核中。如果报文头发现变化,流量将引入错误的内核,从而降低内存和CPU的效率。
NIC构建数据包并在硬件上校验和卸载,从而节省大量的CPU和内存周期。如果重新包装数据是软件内置功能,或者我们在最顶层覆盖(Cloud/laaS).结果都会导致性能的下降。新的NIC可以在硬件中构建VXLAN数据包,但是封装的解决方案中必须使用它。
一些应用程序(如Iguazio的)使用了先进的NIC功能,如RDMA,DPDK快速网络处理库或加密来卸载消息传递,对CPU的并行性进行更严格的控制,减少中断或消除内存副本。这只能在使用直接网络接口或SR-IOV虚拟接口时使用。
没有简单的方法可以看到网络的命名空间,因为Kubernetes和Docker并没有注册它们(“ip netns”将不会与Kubernetes和Docker一起使用)。但是我们还是可以用一些黑科技从主机上查看、调试、管理和配置POD网络。
网络命名空间在/proc/<PID>/ns/net 可以查看,所以我们需要从我们的POD中找到进程ID(PID)。首先,通过以下命令可以找到容器ID,注意只取前12个数字。
kubectl get po <POD-NAME> -o jsonpath='{.status.containerStatuses[0].containerID}' | cut -c 10-21
再次,我们使用Docker命令找到进程PID:
kubectl get po <POD-NAME> -o jsonpath='{.status.containerStatuses[0].containerID}' | cut -c 10-21
一旦获取PID,我们可以通过POD来监控和配置网络。在POD的命名空间中,使用nsenter工具来运行任意的命令,例如:
nsenter -t ${PID} -n ip addr
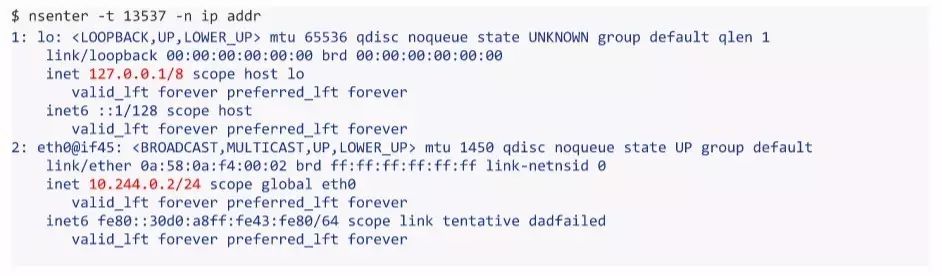
如果我们对每个POD的单个接口不满意,还可以从主机命名空间中获取或创建接口,并将它们分配给POD:
ip link set netns ${PID} <IFNAME>
如果想还原,我们设置host即可:
nsenter -t ${PID} -n ip link set <IFNAME> netns 1
Kubernetes使用CN1插件来组织网络。每次初始化或者删除一个POD时,将使用默认配置调用默认的CN1插件。该CN1插件创建一个伪接口,将其附加到相关的底层网络,设置IP和路由将其映射到POD命名空间。
不幸的是Kubernetes仍然只支持每个POD只有一个CN1接口,具有一个群集级层次的配置。这就非常有限了,因为我们可能想要配置每个POD的多个网络接口,潜在地使用具有不同策略(子网,安全性,Qos)的不同覆盖解决方案。
让我们看下我们是怎么绕过这个限制的。

Kubelet使用包含命令参数(CNI_ARGS,CNI_COMMAND,CNI_IFNAME,CNI_NETNS,CNI_CONTAINERID,CNI_PATH)的环境变量调用CNI插件,并通过stdin读写传输json.conf文件。 插件用json输出文本进行响应,描述结果和状态。 在这里查看更详细的解释和例子(http://suo.im/4Gaml7)。 如果您知道Go编程语言,开发自己的CNI插件是比较简单的,因为该框架可以做很多的魔法,您可以使用或扩展其中一个现有的插件(http://suo.im/3K9RYG)。
Kubelet将作为CNI_ARGS变量的一部分传递POD名称和命名空间(例如“K8S_POD_NAMESPACE = default; K8S_POD_NAME = mytests-1227152546-vq7kw;”)。 我们可以使用它来定制每个POD或POD命名空间的网络配置(例如,将每个命名空间放在不同的子网中)。 未来的Kubernetes版本会将网络视为平等的公民,并将网络配置作为POD或命名空间规范的一部分,就像内存,CPU和存储卷一样。 目前,我们可以使用注释来存储配置或记录POD网络数据/状态。
Multus接受一个具有CNI定义数组的分层conf文件。 它将配置每个POD具有多个接口,每个定义一个,我们可以指定哪个接口是“masterplugin”被Kubernetes识别。 我们将其作为基准线与POD名称和POD注释相结合,以创建每个POD灵活且独特的网络配置。
英特尔的同一个开源git仓库中还包括另一个有趣的CNI驱动程序,用于SR-IOV和DPDK支持。
我很喜欢原生云和微服务,他们对敏捷开发和持续交付的影响是巨大的。然后,似乎容器网络项目是新兴,仅仅只是走出了第一步,这就解决了跨部门/云连接的挑战。这些项目仍然需要定制,使其适应更广泛的应用基础和更高的性能。希望它能够快速提升其他更成熟的软件定义网络解决方案(如OpenStack Neutron或VMware NSX)的功能水平。
我们如何实现所有这些不同的封装以及在控制面板上变得可协同操作,并允许在同一个虚拟网络两端是两个不同的供应商/云解决方案? 这是64,000美元的问题,我欢迎您的反馈。 这显然是一个需要更多关注和标准化的关键领域。
本次培训内容包括:Kubernetes概述、架构、日志和监控,部署、自动驾驶、服务发现、网络方案等核心机制分析,Kubernetes调度工作原理、资源管理及源码分析等,点击识别下方二维码即可查看具体培训内容。
点击阅读原文链接可直接报名。
以上是关于黑客级Kubernetes网络指南的主要内容,如果未能解决你的问题,请参考以下文章
《Kubernetes网络权威指南》读书笔记 | 前方高能:Kubernetes网络故障定位指南
Kubernetes网络自学系列 | 前方高能:Kubernetes网络故障定位指南
《Kubernetes网络权威指南》读书笔记 | 终于等到你:Kubernetes网络