细数Kubernetes Service那些事——Kubernetes服务发布以及在eBay的实践
Posted 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了细数Kubernetes Service那些事——Kubernetes服务发布以及在eBay的实践相关的知识,希望对你有一定的参考价值。
eBay自2014年末开始Kubernetes的落地工作,并在2015年扩大研发投入。目前Kubernetes已经部署在eBay的生产环境,并将作为下一代云计算平台。本文结合社区Kubernetes的设计和实现,并结合OpenStack云基础架构,深入分析Kubernetes服务部署的设计与实现。如果您在寻找服务发布的方案或者在寻找Kubernetes服务相关的模块的原理或行为,阅读本文会让你有比较明确的方向。

Kubernetes架构
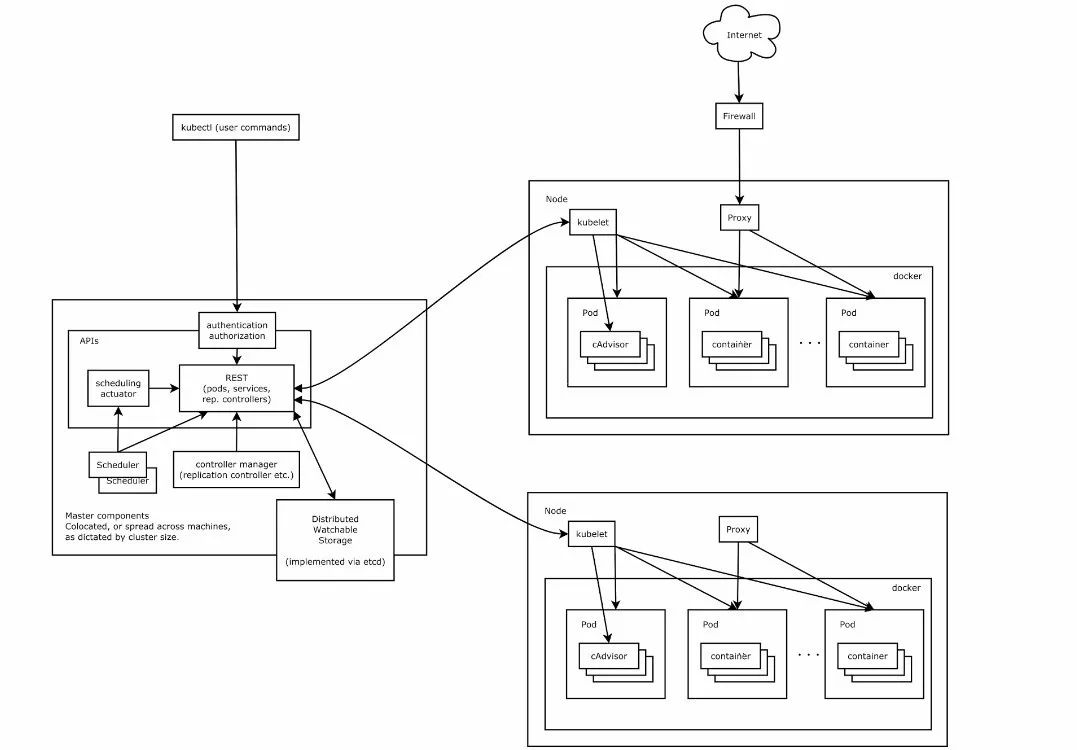
服务的发布
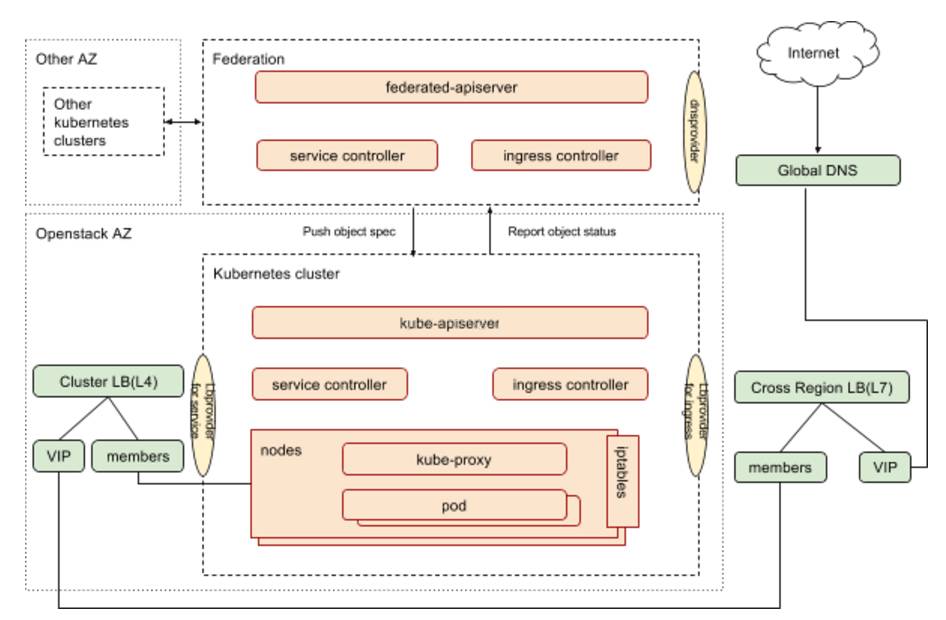
下图展示的是Kubernetes 集群包括集群联邦中服务相关的组件以及组件之间的关系。
Federated-apiserver作为集群联邦推荐的面向用户的接口,接受用户请求,并根据联邦层面的调度器和控制器,将用户请求分裂/转发至Kubernetes集群。
DNS Provider:社区实现包括 GEC Google DNS、AWS DNS,eBay采用自己的GTM client。
Load Balancer provider for service:主流云平台都有自己的Provider,eBay的Kubernetes部署在OpenStack之上,采用社区版本的OpenStack Provider。
Load Balancer provider for ingress:社区目前有GCLB和nginx两个版本的Ingress Controller,eBay与自己的内部load balancer management system(LBMS)对接,采用自己订制的基于LBMS client的Ingress Controller。
关于Kubernetes的基本概念如Pod、Service等,网上有很多相关文章,可以参考Kubernetes官网或网上的入门文章,本文不再一一赘述。本文希望针对Kubernetes服务发布,进行end to end的分析,并针对特定云环境如eBay采用的OpenStack的具体实践。
第一步:定义你的服务
eBay很多应用都采用微服务架构,这使得在大多数情况下,作为服务所有者,除了实现业务逻辑以外,还需要考虑如何把服务发布到Kubernetes集群或者集群外部,使这些服务能够被Kubernetes应用,其他Kubernetes集群的应用以及外部应用使用。
这是一个业界的通用需求,因此Kubernetes提供了灵活的服务发布方式,用户可以通过ServiceType来指定如何来发布服务。
ClusterIP:此类型是默认的,这种类型的服务只能在集群内部访问。
NodePort:此类型同时会分配ClusterIP,并进一步在集群所有节点的同一端口上曝露服务,用户可以通过任意的<NodeIP>:NodePort访问服务。
LoadBalancer:此类型同时会分配ClusterIP,分配NodePort,并且通过Cloud Provider来实现LB设备的配制,并且在LB设备中配置中,将<NodeIP>:NodePort作为pool member,LB设备依据转发规则将流量转到节点的NodePort。
内部服务
ClusterIP
如果你的Service只服务于Cluster内部,那么ServiceType定义为ClusterIP就足够了。
外部服务
NodePort
这为开发者提供了自由度,他们可以配制自己的LB设备,配制未被Kubernetes完全支持的云环境,直接开放一个或者多个节点的IP供用户访问服务。
eBay的Kubernetes集群架设在OpenStack 环境之上,采用OpenStack VM作为Kubernetes Node,这些Node在隔离的VPC,无法直接访问,因此对外不采用nodePort方式发布服务。
LoadBalancer
针对支持外部LB设备的Cloud Provider的情况,将Type字段设置为LoadBalancer会为服务通过异步调用生成负载均衡配制,负载均衡配制会体现在服务的status.loadBalancer字段。
实际上,当此类型的服务进行Load Balancer配置时,nodeip:nodeport 作为LB Pool的member,最终的traffic还是转到某node的nodePort上的。
因为eBay有OpenStack作为IaaS层架构,每个OpenStack AZ有专属的负载均衡设备,负载均衡设备与虚拟机(即Kubernetes Node)的连通性在OpenStack AZ创建的时候就已经设置好,并且OpenStack的LBaaS已经把针对LB设备的操作做了抽象,这让Kubernetes和LB设备的通信变得非常简单。eBay直接采用社区版本的OpenStack Provider作为Cloud Provider,该Provider会调用OpenStack LBaaS API来进行LB设备的配制,无需订制即可实现与LB设备的集成。
Service Controller:服务是如何被发布到集群外部的
Kubernetes controller manager的主要作用是watch kube-apiserver的相关对象,在有新对象事件如创建,更新和删除发生时,进行相应的配制,如ServiceController的主要作用是为Service配制负载均衡,ReplicaSetController主要作用是管理Replicaset中定义的Pod,保证Pod与Replicas一致。如果你对Kubernetes代码比较熟悉,你会发现ServiceController是其中职责相对清晰,代码相对简单的一个控制器。
通过解读ServiceController的源码,我们可以了解到ServiceController同时监控Service和Node两种对象的变化,针对任何新创建或者更新的服务,ServiceController调用Load Balancer Provider的接口来实现Load Balancer的配制。因为Load Balancer的member是Cluster中所有的Ready Node,所以当有任何Node的变化时,我们需要重新配制所有的LoadBalancer Pool以体现这种变化,这也就是ServiceController要同时监控Node对象的原因。
下图展示的是当ServiceController调用OpenStack LB Provider时所做的操作的时序图。
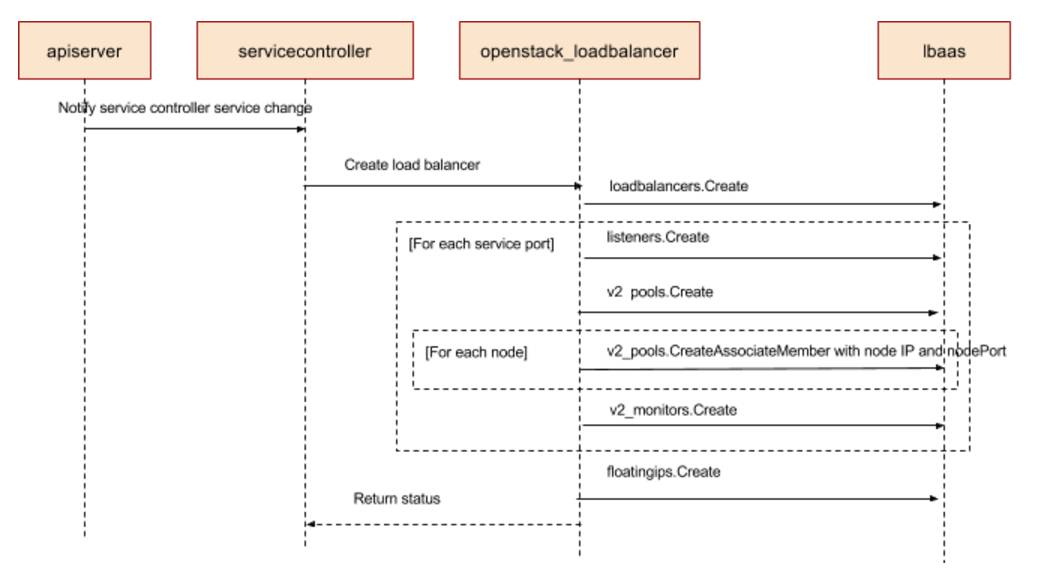
所以最终的配置结果是针对每个Service的Port,在LB设备上会创建一个Load Balancer Pool,VIP可以接受外部请求,Pool Member是节点IP加nodePort。LB设备和Node(即OpenStack VM)处于同一个Availability Zone和VPC,其连通性在Availability Zone创建时即得到保证。物理上,LB设备和虚拟机所在的物理机通过路由连接,路由规则保证LB设备对特定IP段的VM可见。
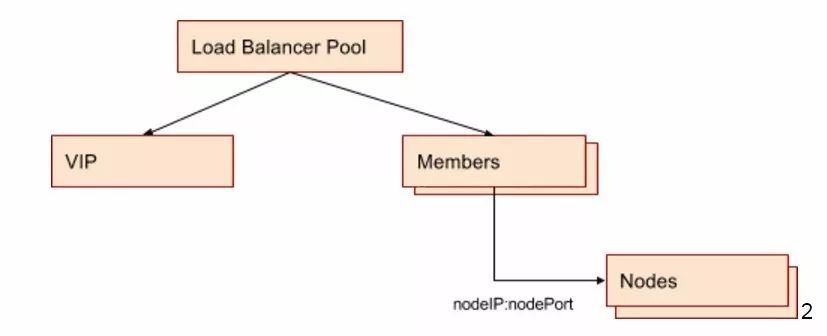
为什么用NodeIP:nodePort作为LB member,如果一个Cluster规模较大,如几千个Node,LB pool会不会很大,为什么不用Pod IP作为LB?
LB和VM之间的路由规则配制只包含VM IP段,在AZ部署的时候创建。Pod IP在通常情况下是不同的range,与LB之间无法直接相通。采用Node IP作为Pool member使得底层架构OpenStack的配制和Kubernetes的配制分离开来,不用考虑Pod的IP范围划定。
Node的变化相对Pod而言较少,这样可以减少对LB 设备的访问,LB可能会出错。
LB Service Type是基于Node Port Type的,Service同时提供两种访问方式。
集群中每个节点被轮询到的机会均等,这使得每个节点需要解析iptables的机会一致,进而使iptables解析在每台机器的资源需求一致,避免某些节点因为iptable rules解析导致压力过大的可能性。(与谷歌首席软件工程师Tim Hockin面对面讨论过此事)
我们知道,Kubernetes服务只是把应用对外提供服务的方式做了抽象,真正的应用跑在Pod的成员Container里,我们通过LB设备已经把提交至VIP的请求转到Kubernetes Nodes对应的nodePort上,那么nodePort上的请求是如何进一步转到提供后台服务的Pod的呢?Kube-proxy is the secret sauce,我们来看看kube-proxy都做了什么。
目前kube-proxy支持两种模式,userspace和iptables,iptables模式因为不需要userspace和kernel space的切换,在数据转发上有更高的效率。所以从1.2版本开始,iptables是默认模式,只有当kernel版本不支持iptables时,userspace模式才需要被启用。
Filter
在该表中,一个基本原则是只过滤数据包而不修改他们。filter table的优势是小而快,可以hook到input,output和forward。这意味着针对任何给定的数据包,只有可能有一个地方可以过滤它。
NAT
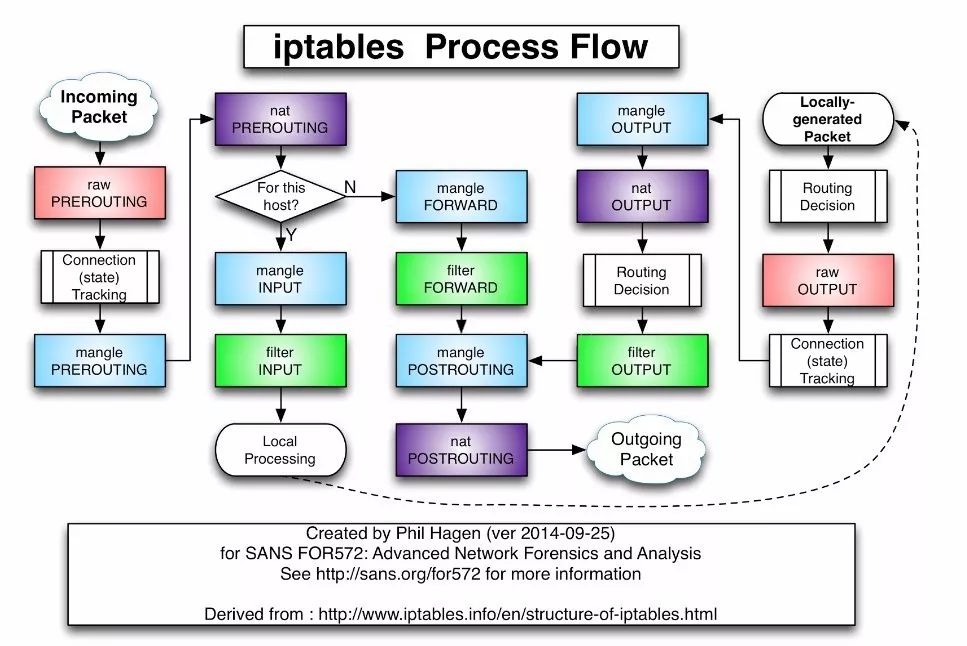
基于iptables的kube-proxy的实现代码在pkg/proxy/iptables/proxier.go,其主要职责包括两大块,一块是侦听Service更新事件,并更新Service相关的iptables规则,一块是侦听Endpoint更新事件,更新Endpoint相关的iptables规则,将包请求转入Endpoint对应的Pod,如果某个Service尚没有Pod创建,那么针对此Service的请求将会被drop掉。
kube-proxy对iptables的链进行了扩充,自定义了KUBE-SERVICES,KUBE-NODEPORTS,KUBE-POSTROUTING,KUBE-MARK-MASQ和KUBE-MARK-DROP五个链,并主要通过为KUBE-SERVICES chain增加rule来配制Routing Traffic规则。
我们可以通过对照源码和iptables规则表,来分析针对下面的Service信息,Kubernetes做了怎么样的iptables配制。
kubectl get svc es1 -o yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: 2016-08-26T05:03:38Z
labels:
component: elasticsearch
name: es1
namespace: default
resourceVersion: "7514"
selfLink: /api/v1/namespaces/default/services/es1
uid: 72f28428-6b4a-11e6-887a-42010af00002
spec:
clusterIP: 10.0.147.93
ports:
- name: http
nodePort: 32135
port: 9200
protocol: TCP
targetPort: 9200
selector:
component: elasticsearch
sessionAffinity: None
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 104.197.138.206
kubectl get endpoints es1
NAME ENDPOINTS AGE
es1 10.180.2.11:9200 11d
在iptables表中,通过iptables-save可以看到在Nat表中创建好的这些链。
:KUBE-MARK-DROP - [0:0] /*对于未能匹配到跳转规则的traffic set mark 0x8000,有此标记的数据包会在filter表drop掉*/
:KUBE-MARK-MASQ - [0:0] /*对于符合条件的包 set mark 0x4000, 有此标记的数据包会在KUBE-POSTROUTING
chain中统一做MASQUERADE*/
:KUBE-NODEPORTS - [0:0] /*针对通过nodeport访问的package做的操作*/
:KUBE-POSTROUTING - [0:0]
:KUBE-SERVICES - [0:0] /*操作跳转规则的主要chain*/
为默认的PREROUTING,Output和POSTROUTING chain增加规则,跳转至Kubernetes自定义的新chain。
-A PREROUTING -m comment --comment "kubernetes service portals"
-j KUBE-SERVICES
-A OUTPUT -m comment --comment "kubernetes service portals"
-j KUBE-SERVICES
-A POSTROUTING -m comment --comment "kubernetes postrouting
rules" -j KUBE-POSTROUTING
对于KUBE-MARK-MASQ链中所有规则设置了Kubernetes独有MARK标记,在KUBE-POSTROUTING链中对NODE节点上匹配Kubernetes独有MARK标记的数据包,进行SNAT处理。
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
-A KUBE-SERVICES ! -s 10.180.0.0/14 -d 10.0.147.93/32 -p
tcp -m comment --comment "default/es1:http cluster IP" -m tcp --dport 9200 -j KUBE-MARK-MASQ /*非Pod内部,针对cluster IP的请求,做snat操作*/
-A KUBE-SERVICES -d 10.0.147.93/32 -p tcp -m comment --comment
"default/es1:http cluster IP" -m tcp --dport 9200 -j KUBE-SVC-LAS23QA33HXV7KBL /*针对cluster IP的请求*/
-A KUBE-SERVICES -d 104.197.138.206/32 -p tcp -m comment
--comment "default/es1:http loadbalancer IP" -m tcp --dport 9200 -j KUBE-FW-LAS23QA33HXV7KBL /*针对LB IP的请求,直接交由iptables转发,防止来自cluster内部的请求给LB设备造成压力*/
-A KUBE-FW-LAS23QA33HXV7KBL -m comment --comment "default/es1:http
loadbalancer IP" -j KUBE-MARK-MASQ
-A KUBE-FW-LAS23QA33HXV7KBL -m comment --comment "default/es1:http
loadbalancer IP" -j KUBE-SVC-LAS23QA33HXV7KBL
-A KUBE-FW-LAS23QA33HXV7KBL -m comment --comment "default/es1:http
loadbalancer IP" -j KUBE-MARK-DROP
调用openLocalPort侦听Service nodePort,增加KUBE-NODEPORTS chain,并添加跳转规则将此端口收到的Packets转到KUBE-SVC-LAS23QA33HXV7KBL链。
-A KUBE-SERVICES -m comment --comment "kubernetes service
nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS /*来自集群外部,通过NodePort或者LoadBalancer访问的请求*/
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/es1:http"
-m tcp --dport 32135 -j KUBE-MARK-MASQ
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/es1:http"
-m tcp --dport 32135 -j KUBE-SVC-LAS23QA33HXV7KBL
Endpoint Chain,当接收到的ServiceInfo中包含Endpoint信息时,为Endpoint创建跳转规则。
-j KUBE-SEP-G4AX7RHRQVIX7P25
-A KUBE-SEP-G4AX7RHRQVIX7P25 -s 10.180.2.11/32 -m comment
--comment "default/es1:http" -j KUBE-MARK-MASQ
-A KUBE-SEP-G4AX7RHRQVIX7P25 -p tcp -m comment --comment
"default/es1:http" -m tcp -j DNAT --to-destination 10.180.2.11:9200
-A KUBE-SERVICES -m comment --comment "kubernetes service
nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/es1:http"
-m tcp --dport 32135 -j KUBE-MARK-MASQ
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/es1:http"
-m tcp --dport 32135 -j KUBE-SVC-LAS23QA33HXV7KBL
如果一个Service对应的Pod有多个Replicas,在iptables中会有多条记录,并通过 -m statistic --mode random --probability来控制比率。
-A KUBE-SVC-7BB4GED2QYDGC4GN -m comment --comment "kube-system/elasticsearch-logging:"
-m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-I7ND2XAHQESZGFZQ
-A KUBE-SVC-7BB4GED2QYDGC4GN -m comment --comment "kube-system/elasticsearch-logging:"
-j KUBE-SEP-OECUK2RLRF65RRGG
Iptables chain支持嵌套并因为依据不同的匹配条件可支持多种分支,比较难用标准的流程图来体现调用关系,为进一步归纳iptables的跳转流程,上面的PREROUTING chain的最终跳转规则,抽象为下图,仅供参考。
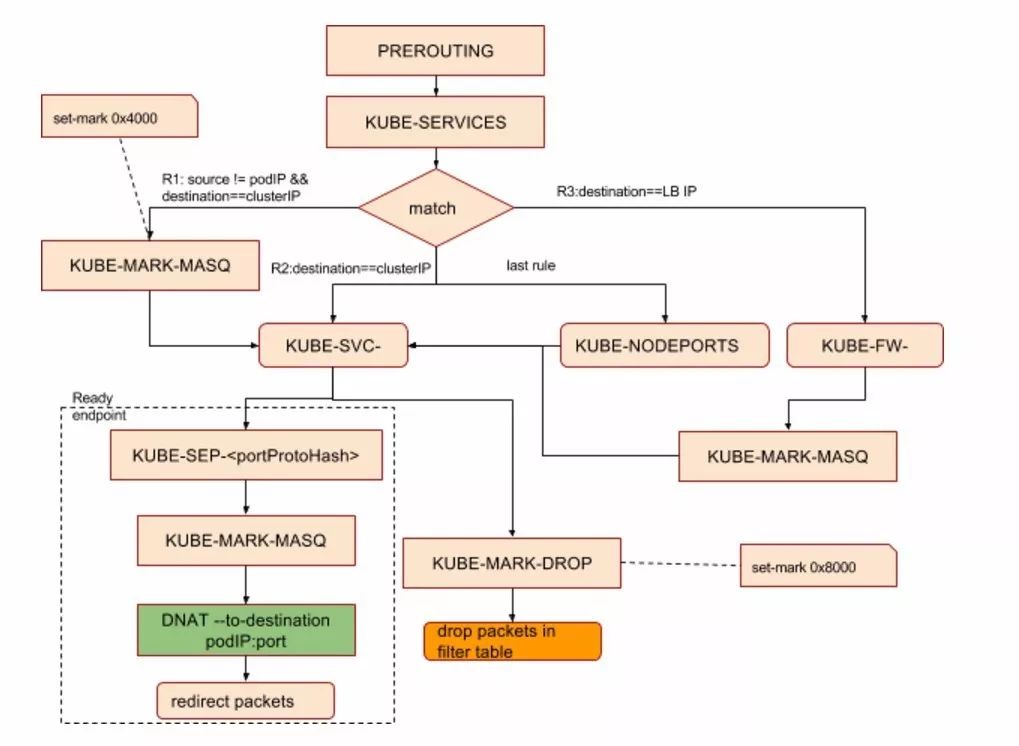
通过IP tables,Kubernetes实现了数据的高效转发,通过与集群LB设备的整合,实现了服务对外的发布,一切看起来已经working perfectly,实则不然。
全局IP不够用怎么办
Dynamic DNS
L7 Rules
针对服务发布,一种常见的场景是,用户分配几个专用的全局IP,将这些全局IP作为服务访问的入口,这些IP会预先在DNS Server中创建好DNS record。针对不同的服务,通过L7转发规则,进行hostname/path到具体服务的跳转。
TLS termination
因安全需求,面向用户的服务,只支持安全访问协议,如https。主流的LB设备都支持TLS termination,即面向用户的服务是https的,https connection在LB设备结束,LB设备到提供服务的应用中间的连接是非secure,因为这一段的连接往往在防火墙内部,属于可信网络。这种模式既提供了安全保证,又把安全配制从应用中分离出来,简化应用开发。
Ingress
针对上述的问题,Kubernetes从1.2 release开始提供Ingress来支持七层路由。对于大多数环境来讲,服务和Pod通常只有在Cluster网络可以路由的IP,对于这样的环境,来自internet的请求要么被drop要么被转发到别处(在eBay我们的Service IP 是Global Routable的)。
internet
|
------------
[ Services ]
Ingress定义了一系列使得inbound连接到达集群服务的规则,在Kubernetes中所处的地位如下。
|
[ Ingress ]
--|-----|--
[ Services ]
Ingress可以为服务配制外部可达的URL,负载均衡Traffic,SSL,提供基于名字的虚拟hosting。Ingress可以指定包含TLS私钥和证书的secret来传递TLS连接所需的证书信息。secret信息可以通过如下步骤创建:
生成证书
$ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout
/tmp/tls.key -out /tmp/tls.crt -subj "/CN=echoheaders/O=echoheaders"
创建证书对应的tls key和crt
$ echo "
apiVersion: v1
kind: Secret
metadata:
name: tls
data:
tls.crt: `base64 -w 0 /tmp/tls.crt`
tls.key: `base64 -w 0 /tmp/tls.key`
" | kubectl create -f
通过在Ingress定义中指定tls.secretName可以非常方便的指定证书,相应的,Ingress Controller需要实现证书上传和配制的逻辑。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: no-rules-map
spec:
tls:
- secretName: testsecret
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
backend:
serviceName: s1
servicePort: 80
Ingress Controller
用户通过向API Server提交请求创建Ingress对象,而我们需要对应的Ingress Controller来操作Ingress对象,实现Load Balancer的配制。因为不同的用户环境,采用的Load Balancer不尽相同,社区的Ingress Controller采用add-on的形式实现,目前有基于Nginx和GCLB(Google Cloud Load Balancer)的Ingress Controller的开源实现。
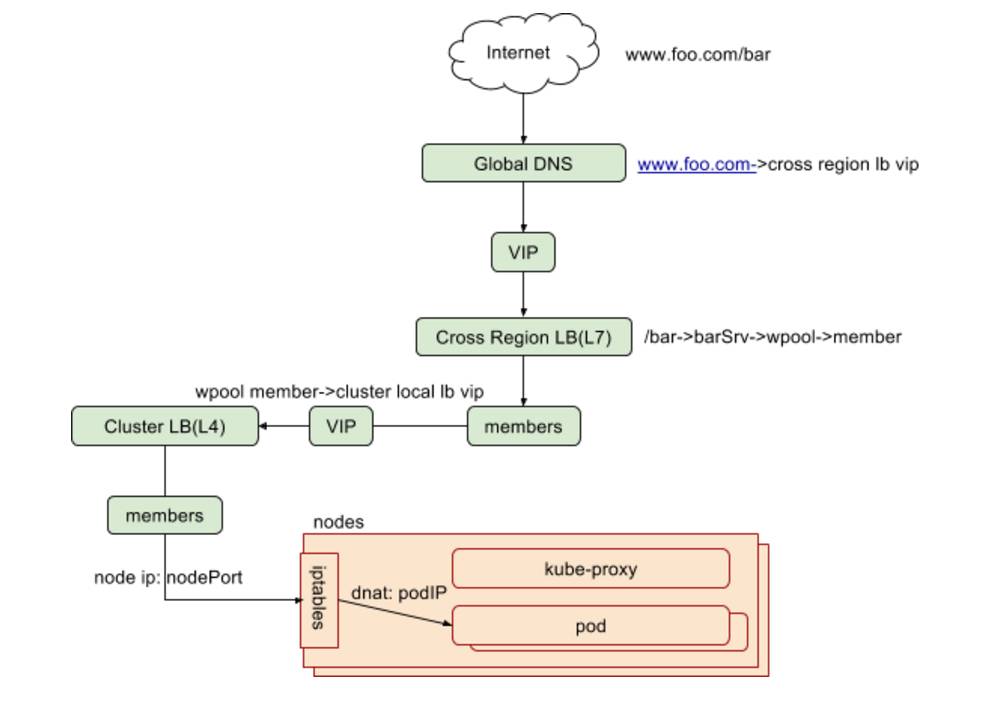
eBay作为E-Commercial公司,网络环境与其它互联网公司类似。区别于传统的flat模式,因为Traffic Management的需要,我们采用两层LB设备的拓扑结构,每个集群有cluster local load balancer,在此之上有跨集群的cross region load balancer。其中cluster local LB负责的是Region内部的负载均衡,cross region LB负责的是跨Region的负载均衡,为避免单点故障和满足流量管理的需求,针对同一应用,所有的cluster local LB pool的VIP都作为cross region LB pool的memeber,形成如下图的拓扑结构。
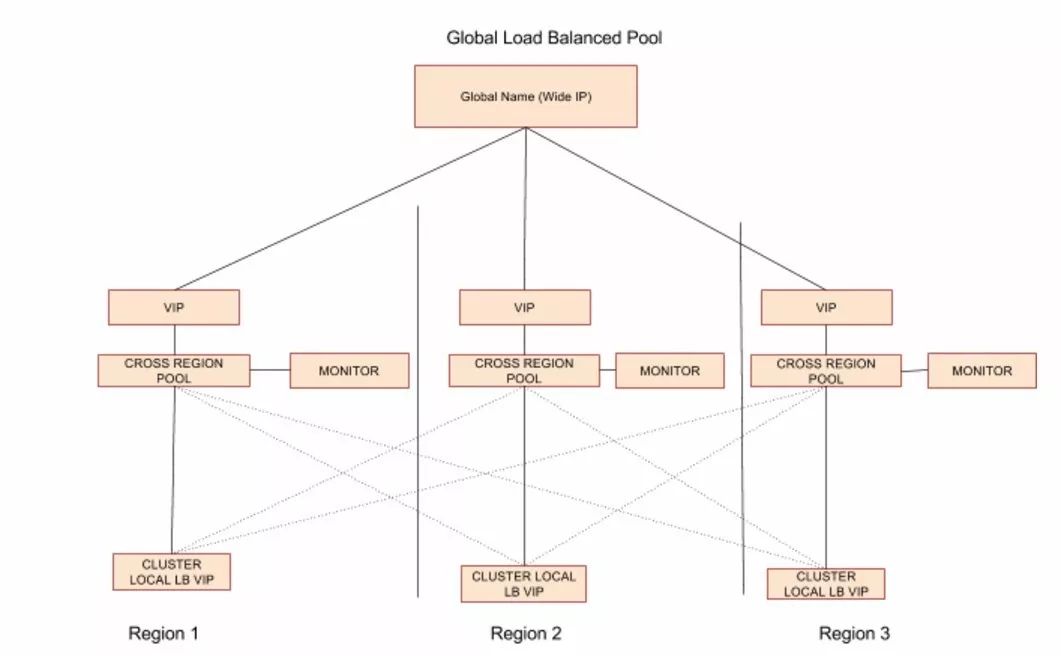
基于此拓扑,我们采用自己实现的Ingress Controller来监控Ingress对象,针对任何Ingress的创建和更新,查找对应的cluster local LB VIP,并且将这些VIP作为memeber,创建Cross Region的LB设备的配制。同时,我们在评估可以应用在生产环境的software load balancer。
我们分析了Kubernetes针对流量转发的原理,介绍了将Kubernetes服务对外发布的方式以及eBay的实践,那么部署生产系统的服务还欠缺什么呢?跨Availability Zone的高可用。
虽然uKbernetes借助ReplicaSet(或ReplicationController)天然支持Pod级别的高可用,但我们不能假定数据中心永远不会出问题,数据中心也可能遭遇区域断电,地震等大规模灾难。
自1.2版本开始,Kubernetes开始引入Federation提供跨Cluster的高可用,通过将不同AZ,不同Region的Kubernetes集群组成同一个联邦,我们可以实现使Kubernetes满足生产系统的要求。
Cluster Controller
集群要加入联邦,首先要通过Federation API server创建Cluster对象,Cluster Controller负责针对集群做healthcheck。
Federated Replicaset Controller
Replicaset是ReplicationController的替代版本(在Kubernetes中二者是等价的,但在Federation control plane,ReplicationController因为未来会被deprecated而未获支持)。Federated Replicaset Controller负责将用户定义的ReplicaSet,依据特定的调度算法,转发至目标集群。当用户定义了ReplicaSet,包括Replica、Pod、Container等信息,可以通过annotation指定目标该ReplicaSet在每个目标Cluster要部署的Replica数量。如果未指定目标集群,那么该ReplicaSet会被平均分配到每个Kubernetes中。
下面是一个指定特定Cluster中Replica数量的例子:
"federation.kubernetes.io/replica-set-preferences":
`{"rebalance": true,
"clusters": {
"k8s-1": {"minReplicas": 10, "maxReplicas": 20, "weight":
2},
"*": {"weight": 1}
}}
ReplicaSet Controller同时会监控每个集群中ReplicaSet的状态,确保所有集群中的Replicas总和与用户期望吻合,如果承担scale和failover等职责。
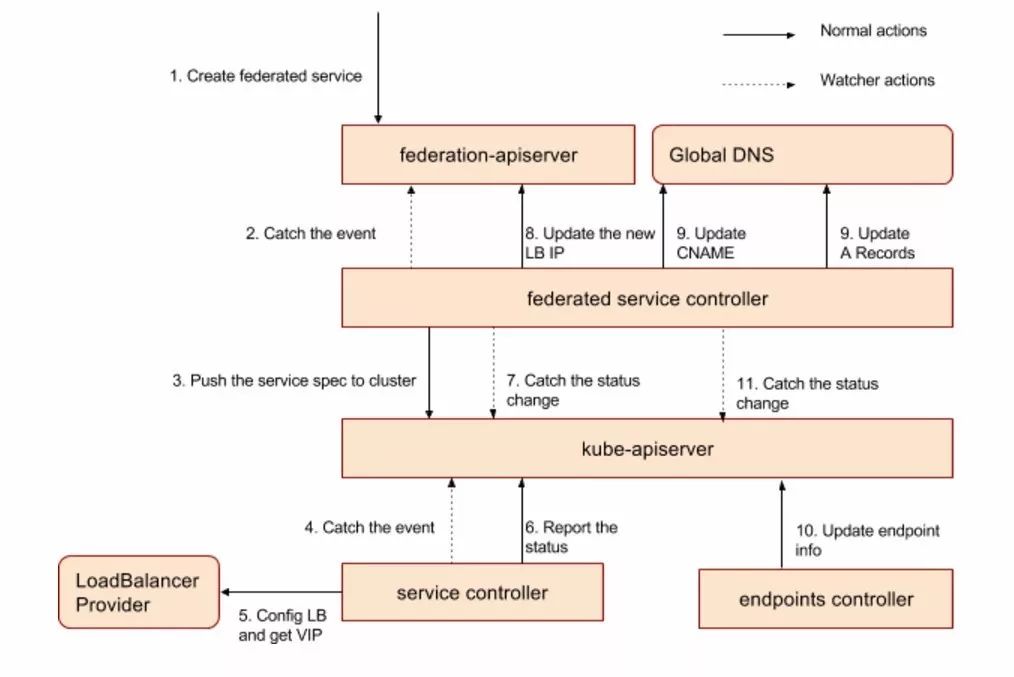
Federated Service Controller
Federated Service Controller负责将用户定义的service spec转发到所有状态正常的集群中(ReplicaSet Controller是依据调度算法调度,Service和Ingress不涉及调度)。
集群的服务控制器接收到服务创建或更新事件后,如果该服务类型为Load Balancer,则调用load balancer provider为该服务分配load balancer IP,并将状态汇报给集群联邦。
1. 监控所有集群的Service状态,如果Load Balancer IP发生变化,则更新Federation API Server。
2. 调用DNS Provider接口,将Zone Level、Region Level和Global Level的cname写入 Global DNS Server。
DNS name的pattern如下,其中federationname和dnsZoneName是在federation的配制文件中指定的联邦名字和域名(如:ebay.com),zoneName和regionName是从每个cluster master node的label中获取的Zone和Region信息。
Zone level: servicename.namespace.federationname.svc.zoneName.regionName.dnsZoneName
Region level:servicename.namespace.federationname.svc.regionName.dnsZoneName
Global level:servicename.namespace.federationname.svc.dnsZoneName
下图展示了集群拓扑下,服务创建的流程。
Federated Ingress Controller
Federated Ingress Controller的职责与工作原理非常相近,它监控Ingress的创建,更新或删除实践,将请求转发至每个集群Ingress Controller,并通过监控集群来维护Ingress的状态。
集群内部服务发现
SkyDNS作为Kubernetes的addon,保证集群内部的服务发现。在1.2以及之前的版本,SkyDNS由kube2sky,skydns和etcd组成。1.3针对dns addon做了较大改动,SkyDNS被KubeDNS取代,职责是监控集群中Service和Endpoint的变化,并维护基于内存查找的数据结构。etcd被移除,另外引入了Dnsmasq来提高效率。
Skydns作为built的addon,会在Cluster创建时启动。
在cluster bootstrap时指定dns server ip。
ENABLE_CLUSTER_DNS="${KUBE_ENABLE_CLUSTER_DNS:-true}"
DNS_SERVER_IP="${KUBE_DNS_SERVER_IP:-10.0.0.10}"
DNS_DOMAIN="${KUBE_DNS_DOMAIN:-cluster.local}"
DNS_REPLICAS=1
目前针对Kubernetes外部访问,Kubernetes没有天然集成DNS,但因为Kubernetes本身开放灵活的查找服务的Rest API,CLI和UI,用户可以查询服务并根据loadbalancer IP:port或node IP:nodePort的方式访问。
如果定义了L7 Rule,则可以方便的通过预定义的URI访问服务。
Kubernetes是一个高速发展的开源项目,此文适用的版本是1.4。还有更多跟服务相关的设计和开发正在进行中。一个典型的例子是Service Catalog的PR正在探讨将类似Cloud Foundry中的Service Broker在Kubernetes实现更便捷的全局服务注册和发现。
参考资料
Kubernetes doc:http://kubernetes.io/docs/
Kubernetes source code:https://github.com/kubernetes/kubernetes/
Iptables flow chart:http://stuffphilwrites.com/2014/09/iptables-processing-flowchart/
以上是关于细数Kubernetes Service那些事——Kubernetes服务发布以及在eBay的实践的主要内容,如果未能解决你的问题,请参考以下文章