高可用日志探险——基于 Kubernetes 中的 ELK
Posted 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高可用日志探险——基于 Kubernetes 中的 ELK相关的知识,希望对你有一定的参考价值。
在 Parsec,我们是一个负责整个堆栈问题的小团队。我们四个人主要负责基于 Mac、Windows、Linux 以及树莓派广域网 PC 游戏的低延迟,并为即将到来的平台发布提供支持。尽可能通过优化硬件,让您获得低延迟。我们服务的游戏玩家从澳大利亚遍布到北美,他们希望瘦客户端可以梦想成真,而 AWS 主办、Kubernetes 支持的基础设施就有这种魔力。
早期,为了解决出现的问题,我们需要一个可扩展但易于管理的日志解决方案,以便我们可以花费精力来构建用户所需的所有功能,而不是被恼人的日志系统调整萦身。
在过去的几个月中,我们已经尝试并调整了我们的解决方案,并达到了一个我认为可以运行良好的状态。因此,我想展示我们所做的一些工作,突出我们所学到的东西,并希望帮助其他人愉快地开启创业梦想。
这篇文章将是一个简短系列中的第一篇,详细介绍了我们堆栈的各个方面,以及我们遇到困难时思维是如何转变的。
对于日志的初始化设置,我们制定了双重目标。将所有的日志放到一个系统中,使其可靠,而不用花费太多时间管理。我过去曾经使用过Elasticsearch,令人印象深刻。所以我受欲望驱使,看是否可以把它作为一个“一站式”的衡量标准和日志拖尾(tailing)。我们也不知道日志可能要作何用途,但我们需要将日志安全地存储起来,以便我们需要的时候可以获取到。
Elasticsearch

事实上,Elasticsearch 不仅仅是一个组件,而且值得用整篇幅来写它,但是已经有一些比我更加了解 Elasticsearch 的人写过很多文章来介绍,所以这里我就不再赘述。我们决定在由 Pires 构建的 container 上自行托管我们的集群库,你可以在 https://github.com/pires/kubernetes-elasticsearch-cluster 以及 https://github.com/pires/kubernetes-elk-cluster 了解到更多信息。
因为我们不需要支持旧的日志系统,遵循“更新更好”的原则,所以文中使用的是最新版本的 Elastic 套件,即 5.X。
我们从 ES 身上学到的最重要的一点是,它很脆弱,特别是当你像我们一样在 Kubernets 上运行它时。你可以将其设置如你所想的那样健壮,但以我估计,这样做不值得。ES 是一个非常复杂的软件,它可能会因为各种原因而挂掉,所以与其担心持续的正常运行和恢复,最好还是在 ES 之前有一个持久层,在 ES 挂掉的时候可以重新向 ES 打 log。第一次安装 ES 时,我们以为可以管理它,并且不用太担心备份。但当 ES 挂掉时就,我们被打脸了,日志无处可寻。我们从内存压力,磁盘使用量到难以定位的索引损坏等方面出现了一些问题,并且索引已经不止一次地被破坏了。我们从日志丢失的事实中汲取了教训,所以现在我们合理的看待 ES - “内存”索引可以很容易地消失,但也可以从持久的“磁盘”备份很容易地恢复。自己动手,并提前备份。
特别是在 kubernetes 上运行 ES,这里是对我帮助比较大的一些捷径:
使用 _eth0_ 作为网络主机,如这里所述。
增加运行 ES 的节点的磁盘大小。默认的 20G 会很快用完,特别是当 Kubernetes 尝试恢复失败的节点并复制磁盘上的索引时。
如果追求更好的性能,请首先增加 es 数据 节点的内存分配,因为这个节点完成了大部分工作。我们的 master 节点分配了 256M,目前没有任何问题。
确保运行 curator 来清理旧的索引,只保留合理的查询数量(且需要适配你的群集)。
我不确定管理自己的 Elasticsearch 是正确的解决之道,还是使用 AWS 托管 ES 更加划算。我发现纠结这件事给自己上了一堂有价值的课,但同时感到心碎,也浪费了时间。如果你真想搭建自己的 ES,我建议让 AWS 为你处理。我们可能会在不久的将来尝试迁移到 AWS,所以请密切关注以后的博客。
我们决定坚持使用一个可视化解决方案,因为在确切地知道哪些问题值得解决之前,我们不想太快地提升装备。面向用户的功能成就了今天的 Parsec,最终我们只需要足够的指标来帮助我们明确要做什么。
Kibana 看起来很棒,大大降低了和 ES 笨重的 API 进行交互的难度。你可以点击按钮搜索并显示日志语句。别搞错了,搜索是 ES 做的,而且做得不错。你可以使用布尔逻辑或匹配特定字段,轻易搜索到子串匹配。由于所有东西都被索引了,所以通常搜索速度非常快。当你第一次通过成千上万的分散的日志语句,在几秒钟内找到只有六个相关的消息时,Arthur C. Clarke 的话涌入脑海,“任何足够先进的技术与魔术别无二致”。
但是,在 Kibana 的世界里,并不全是优点,一些缺点也值得一提。
在学习曲线方面,Kibana 就像一个平缓的草坡,顶上是一个纯粹的砖墙。大多数事情都是简单直观的,生成的图表看起来很漂亮,表现也很出色。不过,你有时会尝试做一些相当简单的工作(“如何过滤掉10以下的值”),你会发现他们好看的文档会失真,Google 查询结果可能会出现无关的、来自旧版本文档(我感觉4.x版本更受欢迎)。当你找到答案时,它经常会向你解释如何在 Elasticsearch 中直接进行某些操作,这和回答“做不到”的效果一样。如果你对搜索是认真的,系统的学习 Elasticsearch 是极好的,但如果你像我一样,对日志只是射后不理(fire-and-forget),就不要花时间学习它了。
但是,无论如何,一旦你习惯了 Kibana 的怪癖,它完全可以作为实时指标的基础,你只需要对自己的日志和记录进行一些限制。下面是我发现有价值但很难发现的事情:
注意日志记录的内容(II)
Kibana 可以绘制日志记录的所有内容,但是你需要使用发送的日志来规划应用程序所要显示的内容。我的建议是记录比你认为所需更多的字段,将每个日志语句作为一个潜在的指标,但不要随意发送所有的对象。所以,如果你还没统计事件的数量,可以仿照本例[标准Python日志记录]:
logger.info(“I did something”, extra={“something_count” : 1})
logger.info(“I did a test”, extra={“test_worked” : 1 if worked else 0})
这种做法很好,因为直接使用 Kibana 可以很容易地统计,求和和绘制图表。但是,像下面这样做:
try:
…
except Exception as e:
logger.info(“there was an error!”, extra={“exception” : e})
resp = json.loads(requests.post(“http://some-api.com”, json={“oh”: “my!”}))
logger.info(“response”, extra={response: resp})
就是在找事儿,在本例中,如果 API 响应中的类型或字段发生改变,ES 可能会间歇性地拒绝“响应”消息,并且异常对象可能会被你没注意到一些字段填充。以我的经验来看,最好是明确记录你感兴趣的字段,例如行号和位置、响应状态代码和你关心的字段,从而保持索引的清洁。
还值得注意的是,Kibana 不能(据我所知)在同一个图上绘制两个不同的搜索查询。所以,如果你认为两件事情可能相关,并且想要在一张图表中使用,最好将它们记录在一起。
logger.info(“number of active users”,
extra={“num_active”: num_active})
logger.info(“total users”,
extra={“num_users”: num_users})
logger.debug(“there are {} active users”.format(num_active))
logger.info(“active users metric”,
extra={“num_active”: num_active, “num_users”: num_users})
这里的假设是 debug 日志用于展示感兴趣的东西,但与任何图形无关,只有 info 日志会被发送到 ES。现在,您可以通过“活跃用户指标”进行搜索,并使用过滤器绘制这些元素(下面会提到更多)。
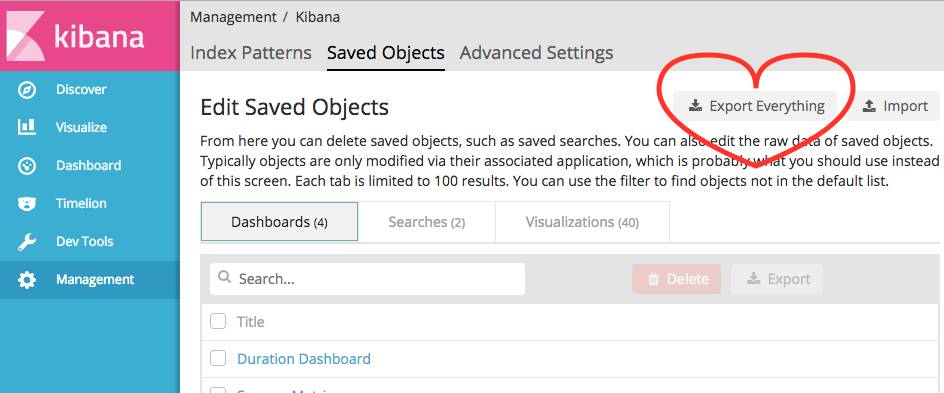
因为我经常备份, 我一直想为自己编写一个自动备份代理,但写成之前,需要手动备份。我的建议是:经常使用,不要在意昂贵的仪表板和可视化的损失。
一个有趣的事实:你会注意到,当导入数据时,如果可视化需要的字段丢失,导入将会中断!这是一个烦人的bug,除非你遵循我的建议,在持久化和数据恢复上做些工作,所以请留意这个问题。
脚本化字段
上面提到过脚本字段是如何扩展仪表盘。这些字段不是 Kibana 输出的一部分,如果每个查询都运行,似乎会产生一些负担,所以我们不会过度使用它们。如果你发现自己改变了很多字段,你应该去改变日志记录的内容。
double val = doc['connection_duration'].value;
return val / (60.0 * 60.0);
Elastic 是在文档的几个部分宣称可能会提供这些“无痛”脚本,我相信效果会很棒。但是,直到它变得更加健壮,我建议保持简单,并在少数可选择的地方使用它。
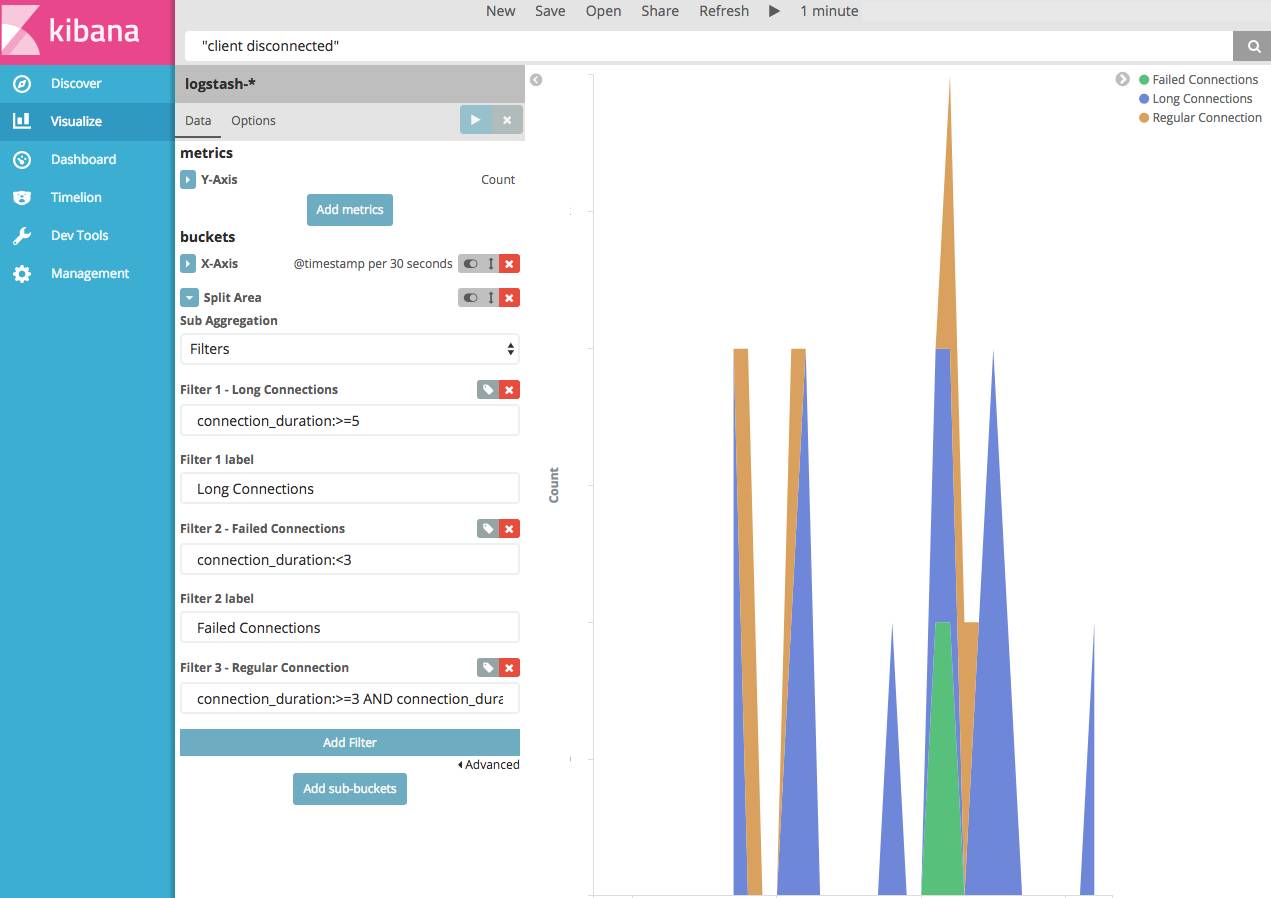
图表中的过滤器
我发现过滤器非常有用,令人惊讶的是文档中并没有很好的描述。所以想要在这里记录一下。
说到魔术,S3 则是另一个令人兴奋的软件或者说基础设施,对于我们的案例来说,这是托管我们原始日志的最好解决方案。S3 被广泛使用,上一次宕机时,整个互联网基本上都瘫痪了,所以当这种情况出现时,你通常会遇到比日志更严重的问题。
Logstash 将所有这些组件都集成在一起。简而言之,我们使用 Logstash,是因为我们必须要用 - 根据我的估计,当谈到日志过滤,聚合等问题是,Logstash 并不是最佳之选,但它使用广泛以及容易配置,所以它是最佳之选。
对于我们来说,我们采用集中式的日志 API,所有 logger 都可以连接。logstash 的 http 插件前面运行 nginx,后者又转发到 ES 和 S3。
输入
input {
http {
port => 8080
}
}
你不必在 logstash 之前使用 nginx,因为我发现期间需要考虑的东西太多。如果你想支持SSL,使用 nginx 是必须的。
过滤器
以下是过滤器部分:
filter {
….
}
丢弃事件
if [headers][request_path] == “/liveness” {
drop {}
}
Drop 可以方便地进行健康检查,活力探测等。这些调用仍然会返回 “ok”,就好像它们遍历了整个管道,其实是被立即丢弃。保持容器的活力探测是一个好主意,而且很容易设置。只需确保你将活力探测设置在正确的容器上。最初,我们在 nginx 容器上设置了活动探测器,所以当 Logstash 关闭并且探测失败时,需要重新启动 Logstash 时Kubernetes 尝试重新会启动 nginx 不会产生影响。
节流
throttle {
after_count => 2
period => 10
max_age => 20
key => “user_id”
add_tag => “throttle_warn”
}
throttle {
after_count => 3
period => 10
max_age => 20
key => “user_id”
add_tag => “throttled”
}
if “throttled” in [tags] {
drop{}
}
if “throttle_warn” in [tags] {
mutate {
replace => {“message” => “throttling events for user:%{user_id}” }
}
}
如果你在某些情况下有很多的日志,就可以耍一个一本正经的小把戏。如果你在发送端没有解决这个问题,实际上可以指示 logger 有条件地将其删除。上面的示例仅用于举例,因为它是非常严格的 - 发送警告消息后,在间隔10秒内它会发现两个消息有相同的 “user_id” 字段,并丢弃所有后续有此 ID 的消息,直到这种情况不再发生。
强类型
mutate {
convert => {
“user_id” => “integer”
}
}
与其说是在 ES schema 中处理类型,不如像文章末尾那样进行强制类型转换,让我们自己变得舒服。
增加环境变量
mutate {
add_field => {“[@metadata][docker_compose]” => “${DEBUG}” }
}
检查布尔逻辑时,Logstash 无法从 env 变量中读取,所以 if/else 处理起来可能比较困难。幸运的是,有一个简单的办法,通过添加实际上不会添加到事件中的 @metadata 标签,然后在过滤器中查询这些标签(见下文)。
输出
output {
elasticsearch { hosts => [“${ES_HOST}:9200”] }
if [@metadata][docker_compose] != “true” {
s3 {
bucket => “your-logs”
prefix => “logstash/”
codec => “json”
encoding => “gzip”
access_key_id => “${AWS_ACCESS_KEY_ID}”
secret_access_key => “${AWS_SECRET_ACCESS_KEY}”
region => “us-east-1”
}
}
}
向 ES 发送消息与设置 HTTP 输入几乎一样简单!我不敢想象 JRuby 的代码竟然必须在引擎盖(hood)之下?
值得注意的是,当我们在本地开发时,使用 env 变量来关闭 S3 输出(如你所猜测的,我们使用 docker-compose 提供正确的 env 环境变量并充当我们“本地” 的 Kubernets)。
input {
http {
port => 8080
}
}
filter {
if [headers][request_path] == "/liveness" {
drop {}
}
throttle {
after_count => 2
period => 10
max_age => 20
key => "user_id"
add_tag => "throttle_warn"
}
throttle {
after_count => 3
period => 10
max_age => 20
key => "user_id"
add_tag => "throttled"
}
if "throttled" in [tags] {
drop{}
}
if "throttle_warn" in [tags] {
mutate {
replace => {"message" => "throttling events for user:%{user_id}" }
}
}
mutate {
convert => {
"user_id" => "integer"
}
}
mutate {
add_field => {"[@metadata][docker_compose]" => "${DEBUG}" }
}
}
output {
elasticsearch { hosts => ["${ES_HOST}:9200"] }
stdout { }
if [@metadata][docker_compose] != "true" {
s3 {
bucket => "your-logs"
prefix => "logstash/"
codec => "json"
encoding => "gzip"
access_key_id => "${AWS_ACCESS_KEY_ID}"
secret_access_key => "${AWS_SECRET_ACCESS_KEY}"
region => "us-east-1"
}
}
总而言之,我们的初始日志安装是相当简单的。Logstash 和 Nginx 在kubernetes 中的一组 pod 中运行,并且附加了所有的 logger,并通过 JSON 写入日志。我们将日志进行少许改动,然后直接发送到 Elasticsearch 和 S3,并使用 Kibana 来实时可视化数据。
在下一部分中,我将进一步详细介绍如何实现高(更高)可用性。当 Logstash HTTP 端点(不可避免地)挂掉时,我们怎么做?从集群启动时,如何恢复 ES?
点击阅读原文链接即可报名。
以上是关于高可用日志探险——基于 Kubernetes 中的 ELK的主要内容,如果未能解决你的问题,请参考以下文章
集群高可用部署支持VIP,集群扩容过程中支持实时查看日志和错误重试,KubeOperator开源容器平台v3.10.0发布
基于 Rainbond 部署 DolphinScheduler 高可用集群