拥抱技术大势:机器学习微服务,容器,Kubernetes,云到边缘计算
Posted 21CTO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了拥抱技术大势:机器学习微服务,容器,Kubernetes,云到边缘计算相关的知识,希望对你有一定的参考价值。
21世纪技术官导读:除了漫天的区块链,不免心生浮燥,开发者还是要学些更技术的技术,我们来看标题中所列的技术,以及它们如何组合起来,发挥更巨大之价值。
概述
如今,开发者,数据科学家与运营部门正在通力协作,通过新技术和体系结构构建智能应用,用它们实现高灵活性,快速交付和高可维护性。
本文将向大家介绍一些热门技术,如机器学习,容器,Kubernetes,事件流(Kafka API),DataOps和云计算等内容。
AI,机器学习,深度学习
预测性机器学习使用算法来查找数据中的相关模式,然后使用识别这些模式的模型来预测新数据。
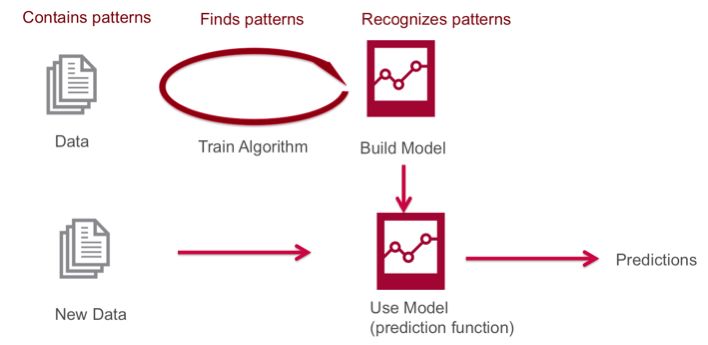
机器学习为什么如此火热?
数据分析技术在过去十年里发生了巨大变化,商用服务器,流式分析和改进的机器学习技术使分布式计算功能更加强大,成本更低,使人们能够存储和分析更多不同类型的数据。
根据Gartner调查显示,在接下来的几年中,几乎所有的应用程序,网站,服务都将包含某种程度的AI或机器学习。
微服务
微服务架构是一种开发应用软件的方法,为围绕特定业务功能构建的一套小型独立可部署的服务。
传统上,要将单个应用将其所有功能集成到一个进程中,需要复制或扩展整个应用程序,这具有局限性和不可测的复杂性。
而通过微服务,功能被放入单独的服务中,允许这些服务在服务器之间分发与复制。
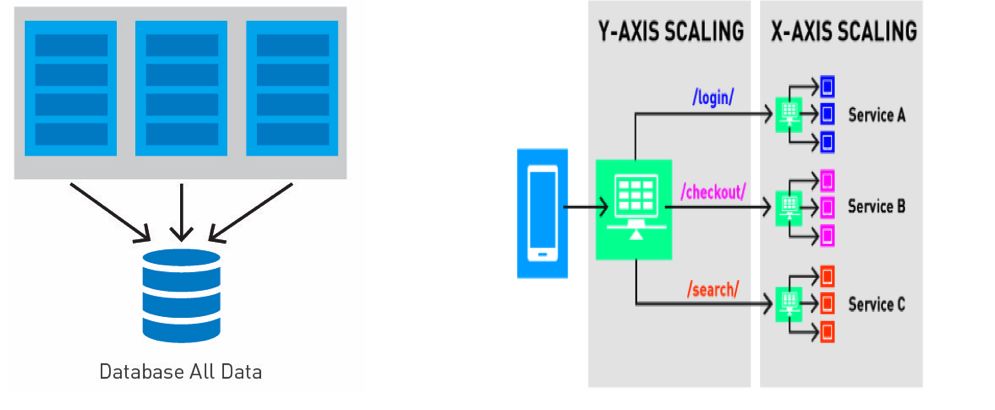
微服务方法非常适合典型的大数据架构部署。
通过在多个商用硬件服务器上部署服务,开发者可以获得高度模块化,并行性和经济且高效的扩展架构。
微服务模块化有助于独立更新/部署,避免单点故障,以防止大规模停机。
事件驱动的微服务
与微服务相结合的常见架构模式是使用仅追加的发布-订阅事件流,例如MapR事件流(其提供Kafka API)。
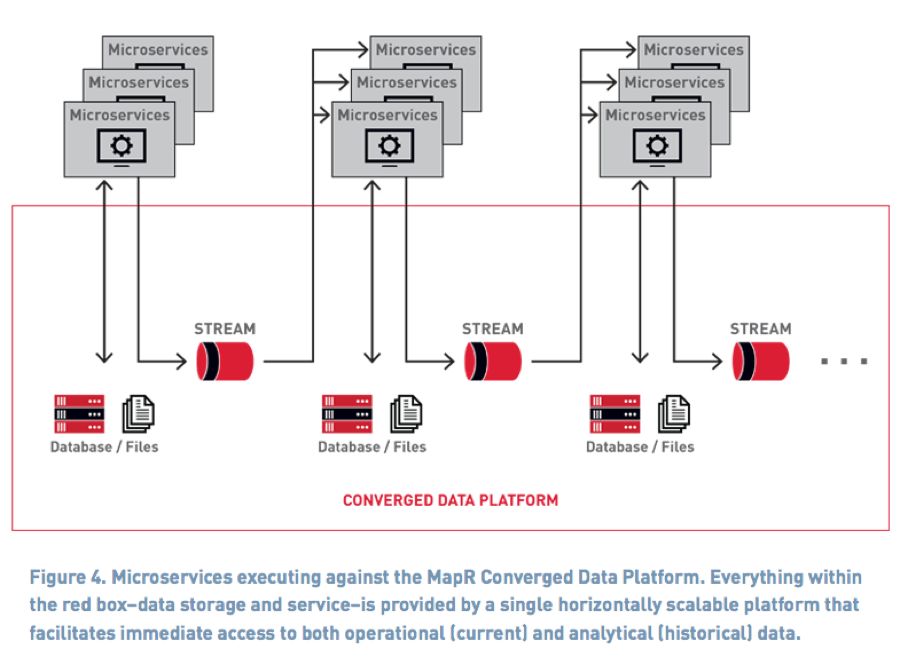
MapR-ES提供高性能消息传递,可扩展到极高的吞吐量级别,在适度的硬件上每秒可轻松传递数百万条消息。为发布/订阅Kafka API分开通信通道,生产者不知道谁订阅,消费者不知道谁发布; 在不中断现有业务流程的情况下轻松添加新订阅或新发布者。
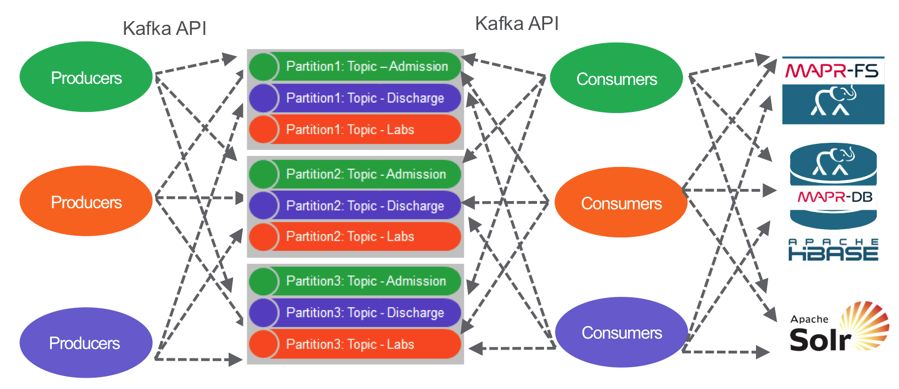
将这些消息难功能与微服务的简单概念结合使用,可极大地提高构建、部署和维护复杂数据管道的灵活性。而Stream是通过将多个微服务简单地链接在一起构建而成的,每个微服务都会监听某些数据的到达,执行其指定的任务,并可选择将自己的消息发布到某个主题中。
例如,电子商务网站的商品评分功能如下所示:
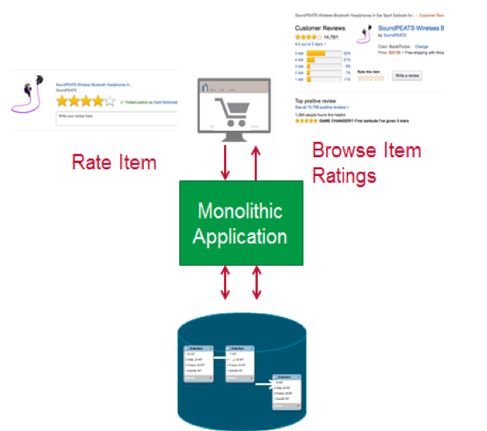
我们可以分解成以下微服务:
1)一个服务发布一个“给商品评分”事件到一个主题;
2)服务从流中读取数据,并在NoSQL文档数据库存储中评分的视图。
3)浏览项目评分服务从NoSQL文档数据存储中读取。

通过事件驱动的微服务,可以通过部署新服务轻松添加新功能。
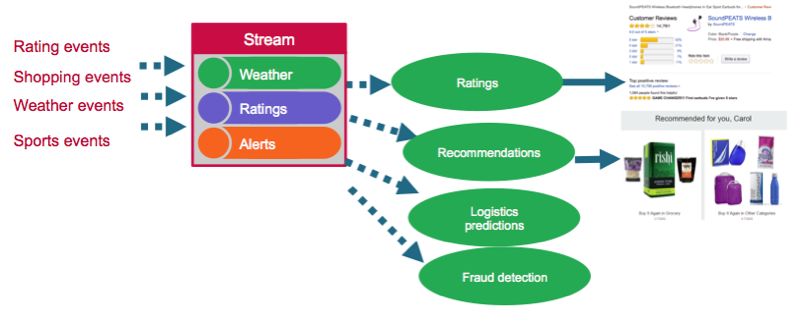
部署新服务
软件开发团队可以更快地部署新服务或服务升级,风险性更低,因为生产环境的版本并不需要脱机。 这两种版本的服务会并行运行一段时间,随着新数据的到来会产生多个版本的输出。两种输出流都可以随时监控; 旧版本在停止使用时即随时可以退役。
事件流和机器学习
将事件流与机器学习相结合,可以通过以下方式灵活处理机器学习的后续问题:
1)使输入和输出数据可供单个消费者使用
2)管理和评估多个模型并轻松部署新模型
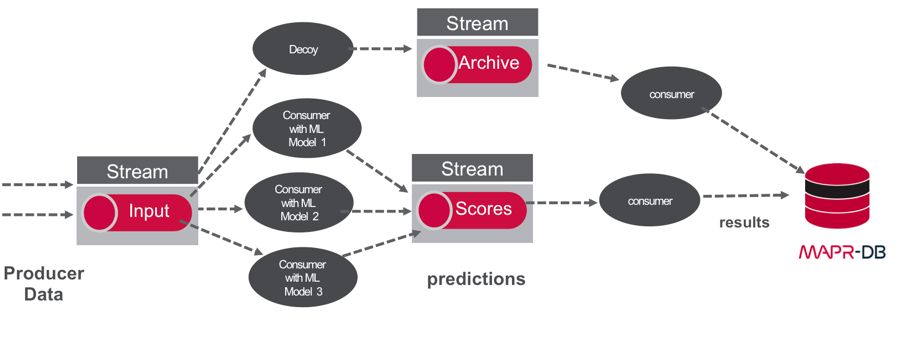
这些应用的体系架构在后面文章中有更详细的讨论。
容器
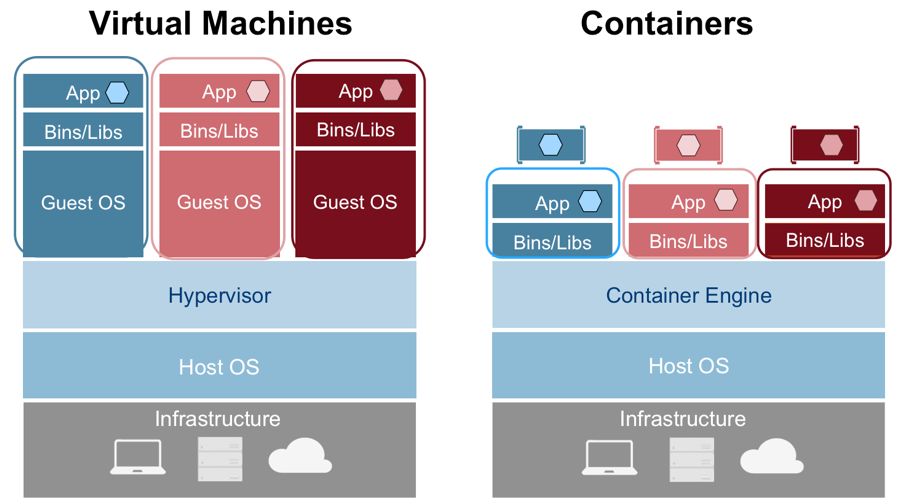
容器镜像会打包整个运行时环境:应用程序,以及执行应用程序所需的所有依赖项,库和其他二进制文件以及配置文件。
与虚拟机相比,容器具有相似的资源与隔离优势,而是更轻量级,因为容器的虚拟化是操作系统而不是硬件。容器更便携,更高效,占用更少的空间,使用更少的系统资源,在几秒钟内就能完成。
DevOps与容器
与如火为茶的敏捷开发运动如何打破业务需求,开发和测试之间的平滑结合一样,DevOps通过流程协作打破开发者与运维之间的孤岛。
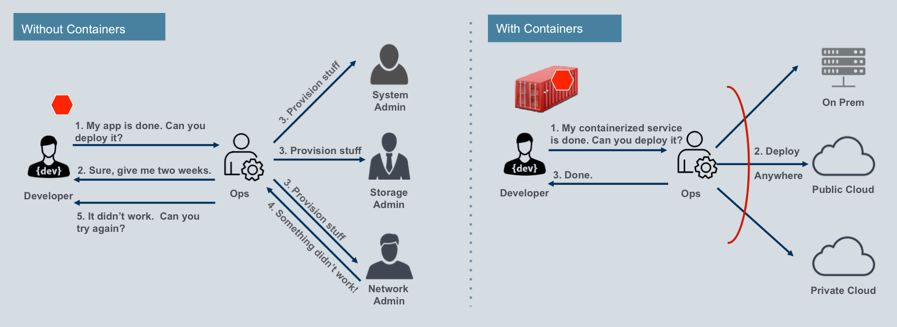
容器为开发人员提供了更高效率,而不用等待调配和操作机器,DevOps团队可以快速地将应用打包到容器中,包括不同平台,包括笔记本,私人IDC,公有云或混合云环境。
容器和云
美国国家标准与技术研究院将云计算定义为对一系列计算资源的访问,这些资源可以通过4种部署模式进行快速配置和提供,分别是私有云,社区云,公有云和混合云。
通过容器,开发人员可以不用付出太大精力将微服务直接部署到生产环境中,这种跨不同平台部署的能力已经在如今混合型IT环境中变得尤其重要,其中基础架构是现有传统IT系统,内部和外部私有云以及公有云的组合架构。
容器和云的部署
Kubernetes目前已经向容器主流迈出了一大步。 Kubernetes的自动化可以进行“容器的编排调度” - 部署,扩展和管理容器化的应用程序。
Kubernetes引入了一个称为“pod”的高级抽象层,它允许多个容器在主机上运行并共享资源,而不会存在冲突与风险。可以使用pod来定义共享服务,如目录或存储,并将其展示给容器中的全部容器。
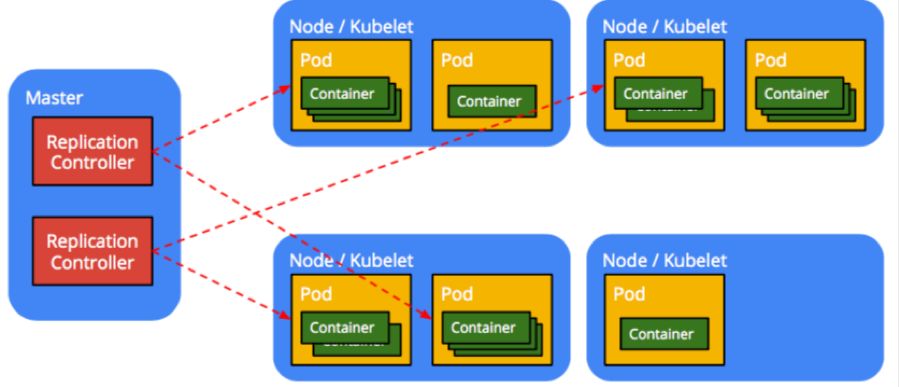
Kubernetes简化了机器与服务的管理,这能让一个运维管理员就可以管理数千个同时运行的容器。
Kubernetes允许在现场部署到公有云或私有云之间进行协调,以实现混合部署。内部部署计算也正在迅速转向容器化调度编排。
DataOps
就像前面大部分的人已经接受了DevOps概念一样,DevOps使用的新技术和流程将开发者和运维以更强的凝聚力和互利的方式结合在一起。
如今,数据世界正在向DataOps发展。
DataOps是大型开发团队将数据科学家,开发都和其它以数据为中心为角色的团队所使用的新兴实践,这些角色可以训练机器学习模型,并将其部署到生产环境中。
应用DataOps方法的目标是创建敏捷的自助式工作流,在尊重数据治理策略的同时,促进协作并提高创造力。
DataOps实践支持跨职能协作和快速实现价值,它的特点是过程以及使用如MapR等支持型平台技术。
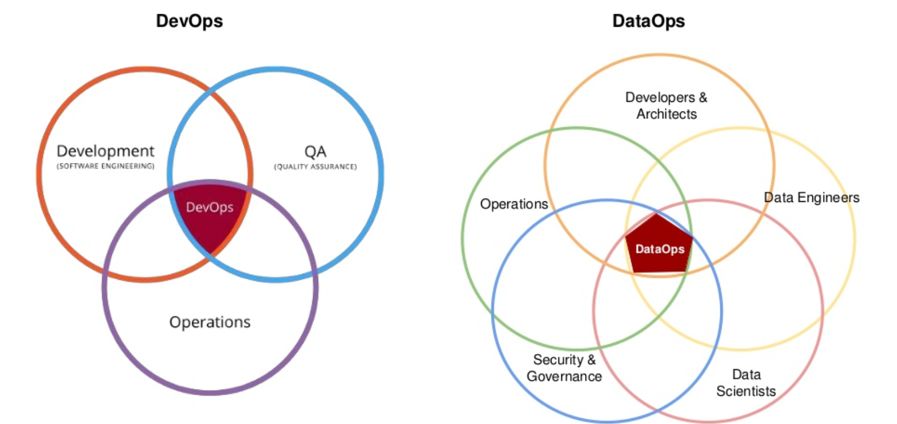
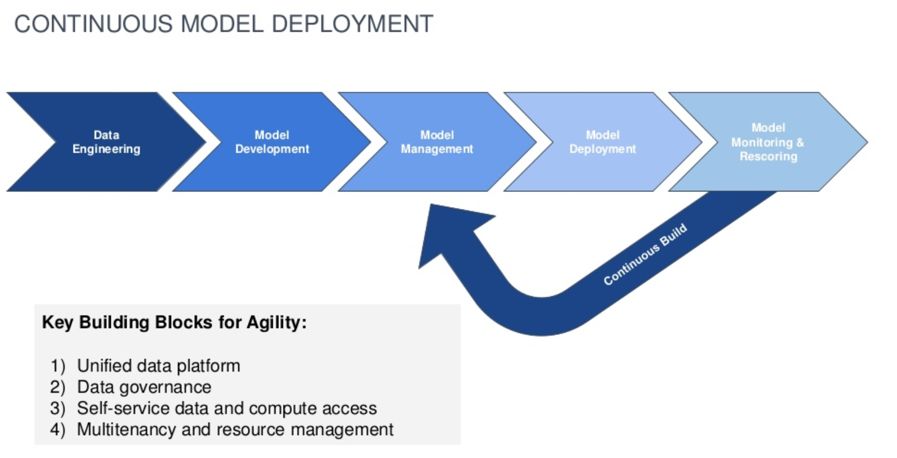
我们将微服务,容器和事件流与DataOps相结合,可以管理和评估多个机器学习模型,并轻松部署新模型,进而更高效和灵活。
物联网,边缘计算,机器学习与云
据CIO杂志称,物联网(iOT)将在2018年全面爆发,很多公司会将物联网技术融入其产品和流程中。
包括从汽车制造商到石油和天然气公司,全球各地的企业都试图从预测设备故障,避免事故,改进诊断等方面获得真正的商业价值。从而使边缘计算(Edge Computing)的需求越来越大,这使得分析和机器学习模型越来越靠近物联网数据源。
边缘计算的优异之处在于能够启用实时分析,利用本地计算来运行,并提供机器学习模型。在物联网领域,快速地分析异常检测,欺诈检测,飞机监控,石油钻机监控,制造监控,效用监控,需要快速响应警报的健康传感器监控等重要设备。
我们不妨大胆想象一下,如果在墨西哥湾深水地平线爆炸之前使用机器学习检测到BP阀门压力异常,则可能避免美国历史上最大的环境灾难,还有很多实例。
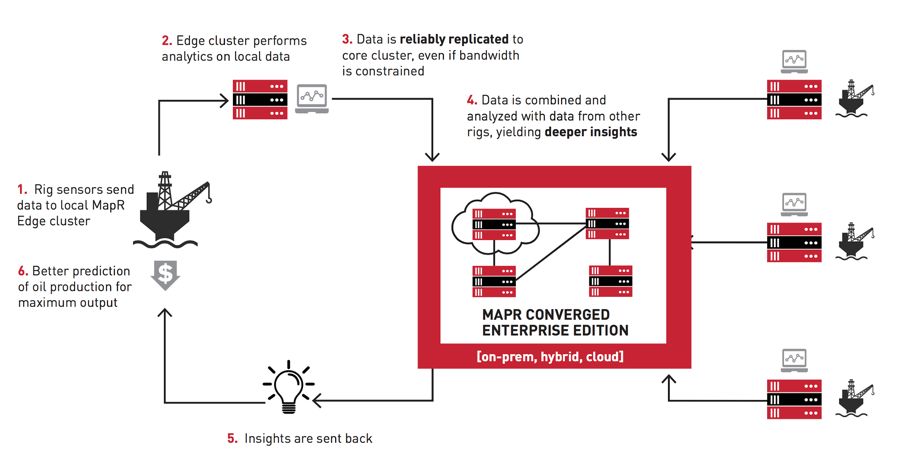
Cloud to the Edge也被称为Fog,它是Gartner预测在2018年的顶尖技术趋势之一,云服务导向模型与边缘计算相结合,用于跨越云和边缘之间的连续统一体的分布式处理。
MapR的Ted Dunning预测会看到全量数据结构延伸到设备侧的边缘数据,在某些情况下,我们将看到结构的线程直接进入设备本身。
小结
目前,几种不同技术的融合极大地改变了应用程序的构建方式。将机器学习、事件驱动的微服务、容器、DataOps和云、边缘计算相结合,将会加速开发下一代智能应用程序,这些应用利用现代计算基础架构的优势,以现代计算基础架构为动力。
MapR融合数据平台,一个号称比Hadoop快三倍的产品,将全球的事件流,实时数据库功能和企业可扩展存储与一系列数据处理和、、分析引擎集成在一起,为新一代数据处理和智能应用提供强大支撑。
一起拥抱大势。
编译:21世纪技术官
以上是关于拥抱技术大势:机器学习微服务,容器,Kubernetes,云到边缘计算的主要内容,如果未能解决你的问题,请参考以下文章