阿里云Kubernetes日志是怎么管理的?
Posted DevOps技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云Kubernetes日志是怎么管理的?相关的知识,希望对你有一定的参考价值。

陈全照/阿里云资深开发工程师
目前就职于阿里云容器服务团队,主要负责容器服务发现与负载均衡、日志采集及镜像构建服务等相关研发工作,多年来一直从事 IAAS、PAAS 计算平台的研发,主要关注虚拟化、NFV、容器等技术。
容器时代越来越多的传统应用将会逐渐容器化,而日志又是应用的一个关键环节。那么在应用容器化过程中,如何方便快捷地自动发现和采集应用日志?如何与日志存储系统协同来高效存储和搜索应用日志?
本次分享主要介绍容器原生日志输出到容器日志的自动发现与采集,以及高性能容器日志采集部署架构及性能测试。
大家好,我是来自阿里云容器服务团队的陈全照,花名云澔。在团队现在主要负责容器服务发现与负载均衡、日志采集以及镜像构建服务相关的一些研发工作。今天主要跟大家分享一下阿里云容器服务在日志实践方面的一些工作。

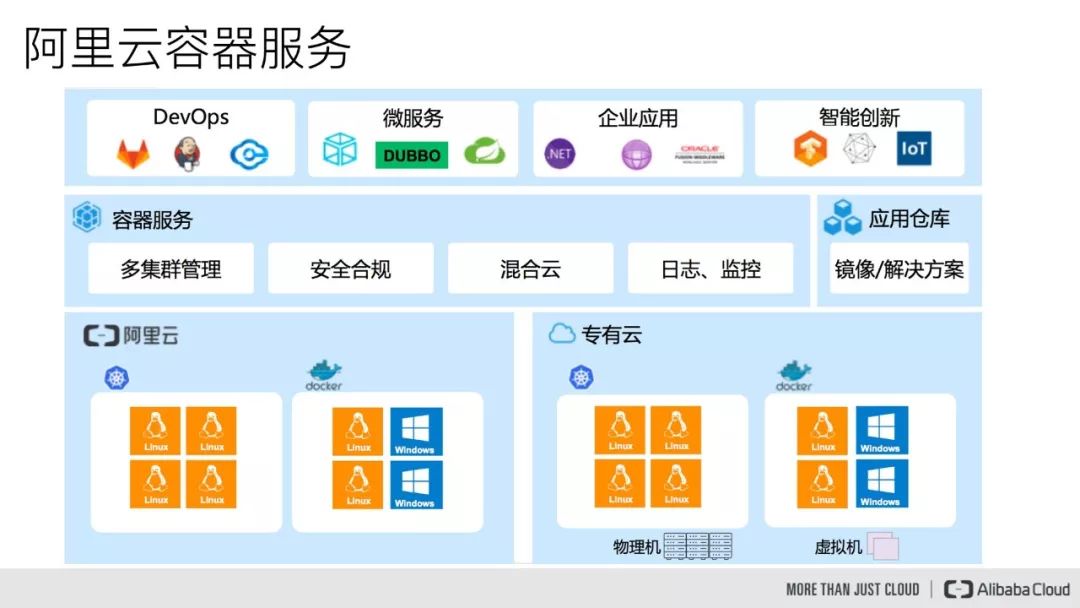
阿里云容器服务
下面先简单介绍一下阿里云容器服务。阿里云容器服务提供了高性能、可伸缩的容器应用管理平台,支持 Swarm 和 Kubernetes 进行应用容器化的生命周期管理,同时整合了阿里云的虚拟化、网络、存储、安全的能力,打造了一个最佳的云端容器运行环境。
阿里云容器服务不仅提供了多集群管理、安全合规、混合云以及日志监控的能力,同时还提供了源代码仓库管理和镜像构建相关的解决方案,打通了用户从源代码编译,到镜像构建,到应用容器集群部署的整个流程。
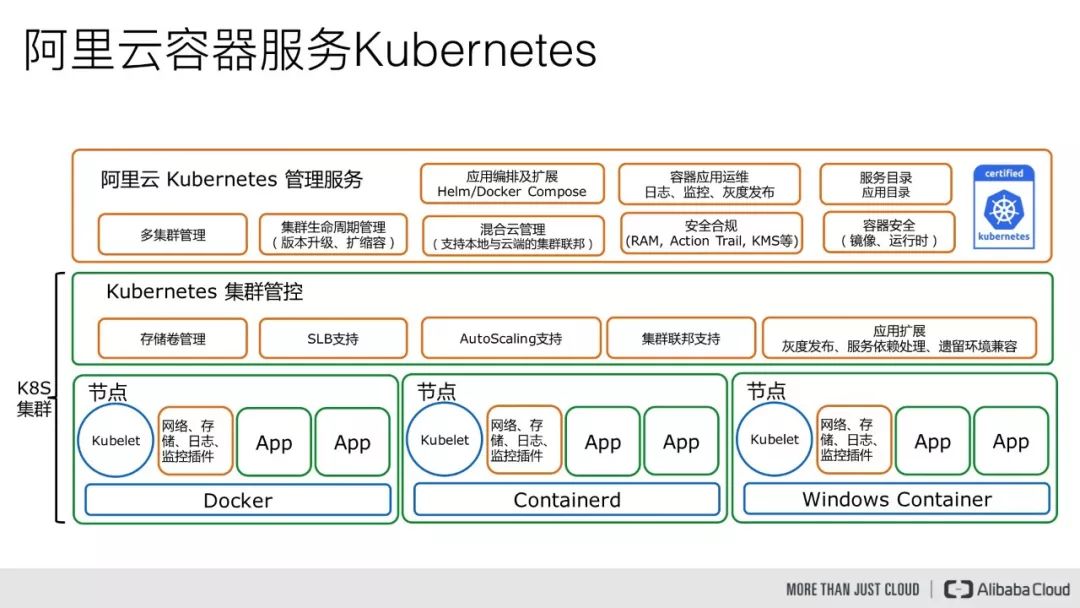
阿里云的 Kubernetes 服务,是在 2017 年 5 月正式对外开放的,我们在完全兼容原生 Kubernetes 的基础上,提供了很多的扩展性功能,同时深度整合了阿里云的公有云资源,提供了一个安全可靠的 Kubernetes 集群管理服务。

下面简单看一下,我们在原生 Kubernetes 基础上做的一些扩展性方面的工作。首先从管理服务层面来看,我们整合了 Helm 和应用目录的能力,然后支持本地和云端的集群联邦,并且对接了阿里云的 RAM、KMS 等授权系统,另外在集群管控层面,我们对接了阿里云的 NAS、OSS、EBS 存储,完全兼容 CSI 标准,同时对接了阿里云的 SLB 来对外提供服务,以及支持弹性伸缩的能力。
我们在支持灰度发布的同时也开发了新的蓝绿发布的特性,然后在网络层面,我们整合了阿里云的高性能 VPC 网络,同时支持流控和网络策略,以及对接了阿里云的云监控,不仅可以监控宿主机资源的使用情况,同时可以监控容器的负载情况,进而对接报警系统。
日志采集难点
今天主要跟大家分享一下我们在日志方面的一些实践工作。首先看一下容器日志采集的一些难点,这里主要从两个方面来讲,第一个是容器本身的特性,第二个是现有采集工具的一些缺陷。

容器本身的特性导致采集目标多,容器一般将日志写在标准输出,但是也有一些特殊的场景就是应用直接将日志写在容器内部,这样的话,对于容器的标准输出日志来说,Docker Engine 本身就提供了一个很好的日志采集能力,但是对于容器内部的文件日志采集,现在并没有一个很好的工具能够去动态发现采集。
容器的弹性伸缩性,因为我们知道 Kubernetes 本身是一个分布式集群,那么我们事先就无法像传统虚拟机环境下那样,事先配置好日志的采集路径等一些信息,因此这对于容器的日志采集来说也将面临一个很大的挑战。
另外一个就是现有采集工具的一些缺陷:
第一,是缺乏动态配置的能力。目前的采集工具都需要我们事先手动配置好日志采集方式和路径等信息,由于它无法能够自动感知到容器的生命周期变化或者动态漂移,所以它无法动态地去配置。
第二,是日志采集重复或丢失的问题。因为现在的一些采集工具基本上是通过 tail 的方式来进行日志采集的,那么这里就可能存在两个方面的问题:一个是可能导致日志丢失,比如采集工具在重启的过程中,而应用依然在写日志,那么就有可能导致这个窗口期的日志丢失;而对于这种情况一般保守的做法就是,默认往前多采集 1M 日志或 2M 的日志,那么这就又会可能引起日志采集重复的问题。
第三,是未明确标记日志源。因为一个应用可能有很多个容器,输出的应用日志也是一样的,那么当我们将所有应用日志收集到统一日志存储后端时,在搜索日志的时候,我们就无法明确这条日志具体是哪一个节点上的哪一个应用容器产生的。
破解利器:Log-Pilot
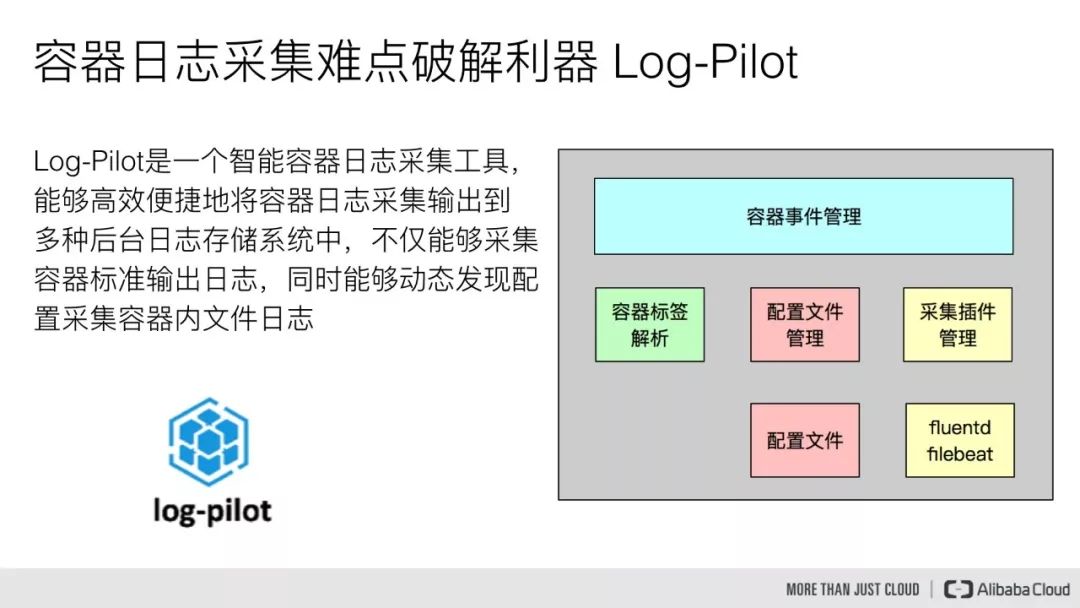
针对这些问题,我们提供了一个智能容器采集工具 Log-Pilot,它不仅能够高效便捷地将容器日志采集输出到多种存储日志后端,同时还能够动态地发现和采集容器内部的日志文件。
Log-Pilot 本身分为三部分,其中一部分就是容器事件管理,它能够动态地监听容器的事件变化,然后依据容器的标签来进行解析,生成日志采集配置文件,然后交由采集插件来进行日志采集。
下面简单看一下,针对前面容器日志采集的难点,Log-Pilot 是如何去解决的。
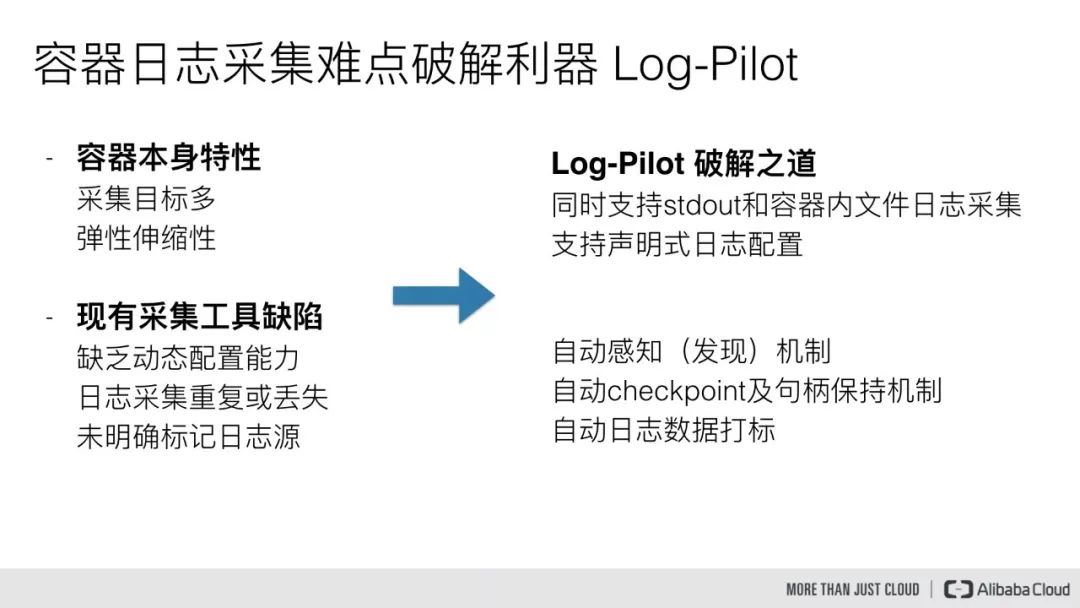
首先对于采集目标多的问题,Log-Pilot 本身同时支持标准输出和容器内部文件日志采集。对于容器的动态伸缩性,Log-Pilot 支持声明式的日志配置方式。对于缺乏动态配置的能力,Log-Pilot 具有自动感知和发现的特性。对于日志采集重复和丢失的情况,Log-Pilot 内部有 Checkpoint 和句柄保持的机制。以及最后未明确标记日志源的问题,Log-Pilot 支持日志自动数据打标。
下面看一下 Log-Pilot 的声明式日志配置,Log-Pilot 可以依据容器的 Label 或者 ENV 来动态地生成日志采集配置文件。这里有两个变量:
$name 是我们自定义的一个字符串,它在不同的场景下指代不同的含义,比如当我们将日志采集到 ElasticSearch 的时候,这个 $name 表示的是 Index,当我们将日志采集到 Kafka 的时候,这个 $name 表示的是 topic,当我们将日志采集到阿里云的 SLS 的时候,这里的 $name 表示的是 LogstoreName。
另一个是 $path,它本身支持两种,一种是约定关键字 stdout,表示的是采集容器的标准输出日志,第二种是容器内部的具体文件日志路径,可以支持通配符的方式,比如说我们要采集 tomcat 容器日志,那么我们通过配置标签 aliyun.logs.catalina=stdout 来采集 tomcat 标准输出日志,通过配置标签 aliyun.logs.access=/usr/local/tomcat/logs/*.log 来采集 tomcat 容器内部文件日志,当然如果你不想使用 aliyun 这个关键字,Log-Pilot 也提供了环境变量 PILOT_LOG_PREFIX 可以指定自己的声明式日志配置前缀,比如 PILOT_LOG_PREFIX: aliyun,custom。

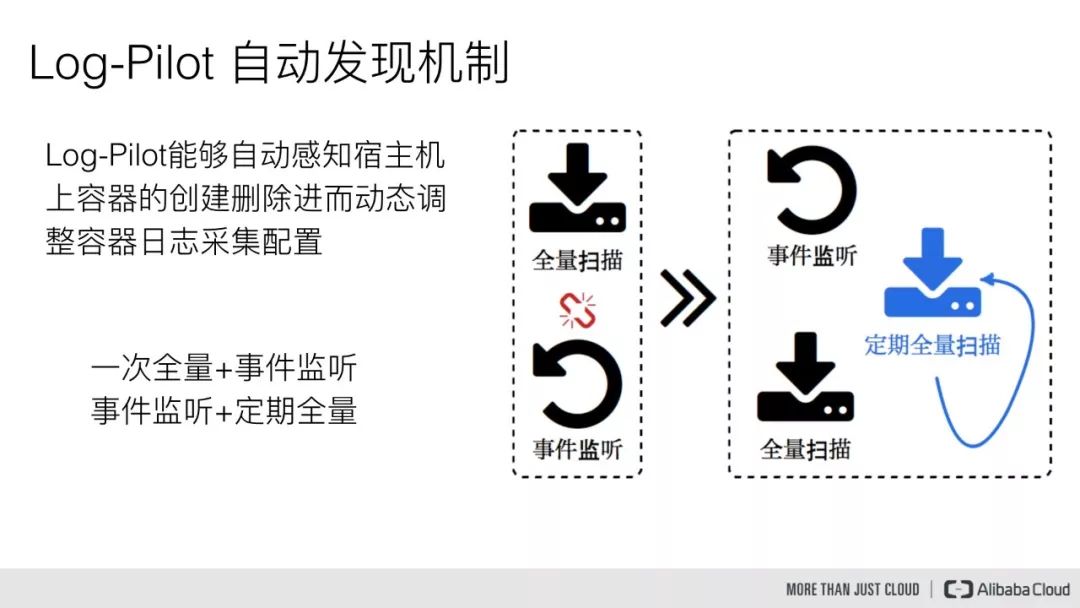
下面看一下 Log-Pilot 的自动发现机制,Log-Pilot 能够自动感知宿主机上容器的创建删除事件,进而动态配置容器日志采集配置文件。
一般情况下我们是通过全量扫描加事件监听的方式,比如采集工具进程在起来的时候,会先去全量扫描一遍宿主机上的所有容器列表,然后依据容器的声明式配置来进行日志采集配置文件的动态生成,然后再注册事件监听。
那么这样可能会导致一个问题,在全量扫描配置的过程中并且在注册事件监听之前,这个窗口期的容器事件就有可能会丢失,所以这里我们采用的是先注册事件监听,然后再全量扫描,这样就可以很好地规避容器事件丢失的问题。
同时再配合定期全量扫描的机制,这样可以完全保证不会因为容器事件的丢失,而导致一个容器虽然设置了声明式日志配置,但却日志没有被采集的情况发生。
下面我们看一下 Log-Pilot 的内部 CheckPoint 及句柄保持的机制:
CheckPoint 机制
Log-Pilot 内部会实时跟踪日志采集偏移量,然后维持日志文件信息与偏移量的映射关系,最后定期地持久化到磁盘中。这样的话,采用偏移量的方式我们可以避免日志采集丢失和重复的问题,同时即使当采集工具宕掉再起来,它可以通过加载持久化在磁盘上的元数据信息,然后从指定的日志偏移位置上继续采集日志。
句柄保持的机制
另一个是句柄保持的机制,Log-Pilot 在监测到配置的日志路径目录下有新的日志文件产生时会主动地打开其句柄,并维持打开状态。这样是为了防止因日志采集工具比较慢或者应用日志输出速率特别大,比如说当前已经生成五个日志文件但只采集到第三个,后面两个还没有开始采集,一旦这个容器退出就可能导致后面两个文件的日志丢失了。
所以 Log-Pilot 在监测到有新的日志产生的时候,会立即将其文件句柄打开,这样的话即使这个日志文件删除,它在磁盘中的数据并没有被擦除,只有当该日志文件采集完成后,我们才会主动去释放这个文件句柄,这样就可以保证日志文件里面的日志不会丢失。

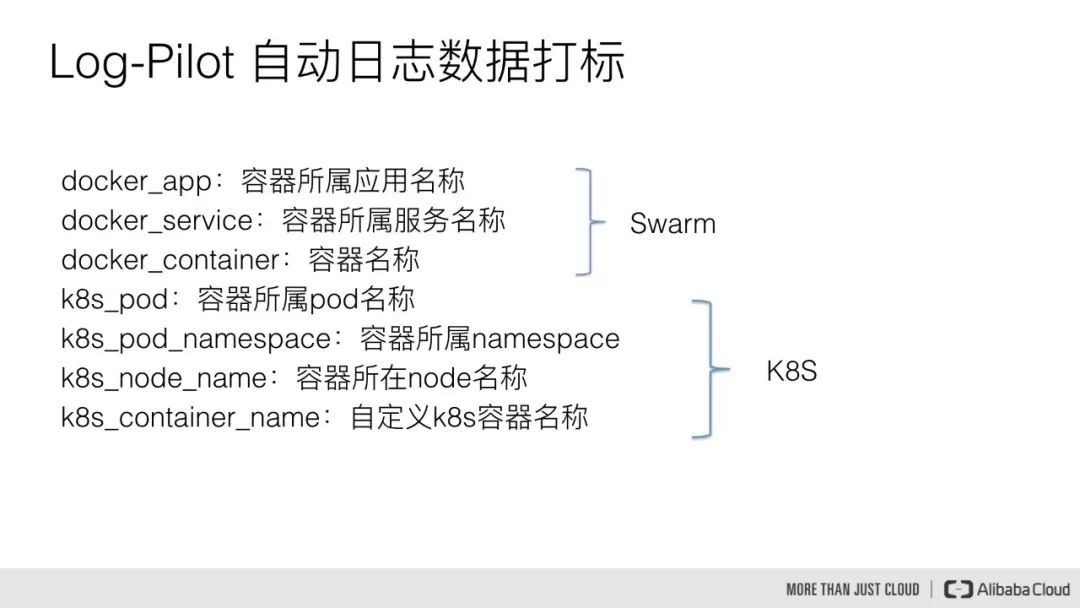
下面简单说一下自动日志数据打标,Log-Pilot 在采集容器日志的时候,同时也会收集容器的元数据信息,包括容器的名称,容器所属的服务名称以及容器所属的应用名称。
同时在 Kubernetes 里面也会采集容器所属的 Pod 信息,包括 Pod 的名称,Pod 所属的 namespace 以及 Pod 所在的节点信息。这样我们排查问题时,就可以很方便地知道这个日志数据是来源于哪个节点上的哪个应用容器。
Log-Pilot 高级特性
另外,Log-Pilot 除了提供前面的几个特性外,还支持一些其他的高级特性,比如低资源消耗,支持自定义 tag,支持多种日志解析格式,支持自定义日志输出 target 以及支持 fluentd 和 filebeat 等插件,最后支持对接到多种日志存储后端。

首先对于低资源消耗这一块,我们先简单说一下容器日志采集一般采用的两种部署模式:
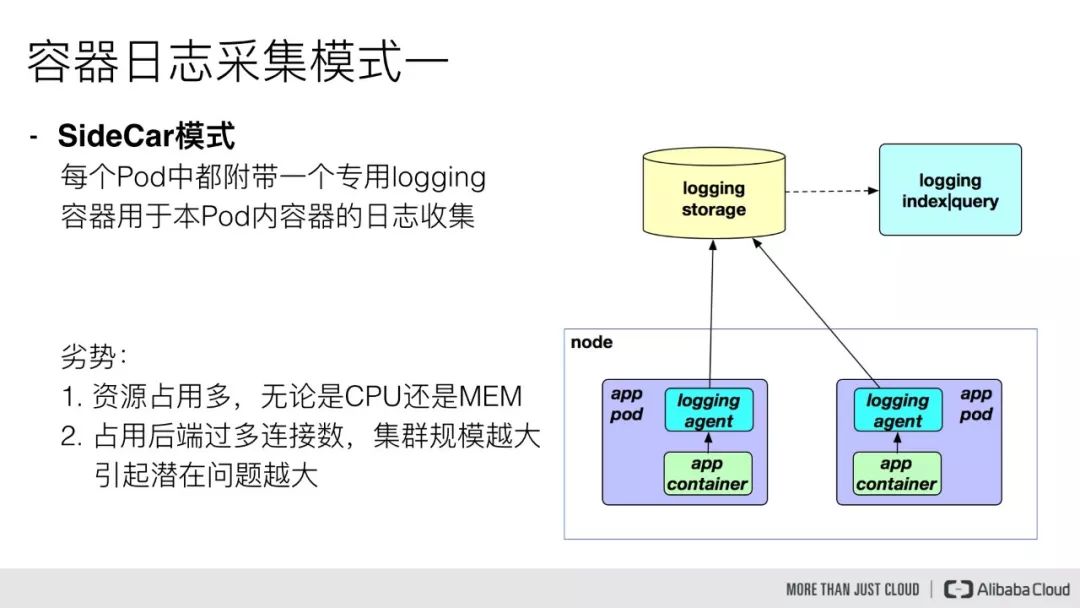
第一种模式是 sidecar 模式,这种需要我们在每个 Pod 中都附带一个 logging 容器来进行本 Pod 内部容器的日志采集,一般采用共享卷的方式,但是对于这一种模式来说,很明显的一个问题就是占用的资源比较多,尤其是在集群规模比较大的情况下,或者说单个节点上容器特别多的情况下,它会占用过多的系统资源,同时也对日志存储后端占用过多的连接数。当我们的集群规模越大,这种部署模式引发的潜在问题就越大。
另一种模式是 Node 模式,这种模式是我们在每个 Node 节点上仅需布署一个 logging 容器来进行本 Node 所有容器的日志采集。这样跟前面的模式相比最明显的优势就是占用资源比较少,同样在集群规模比较大的情况下表现出的优势越明显,同时这也是社区推荐的一种模式。
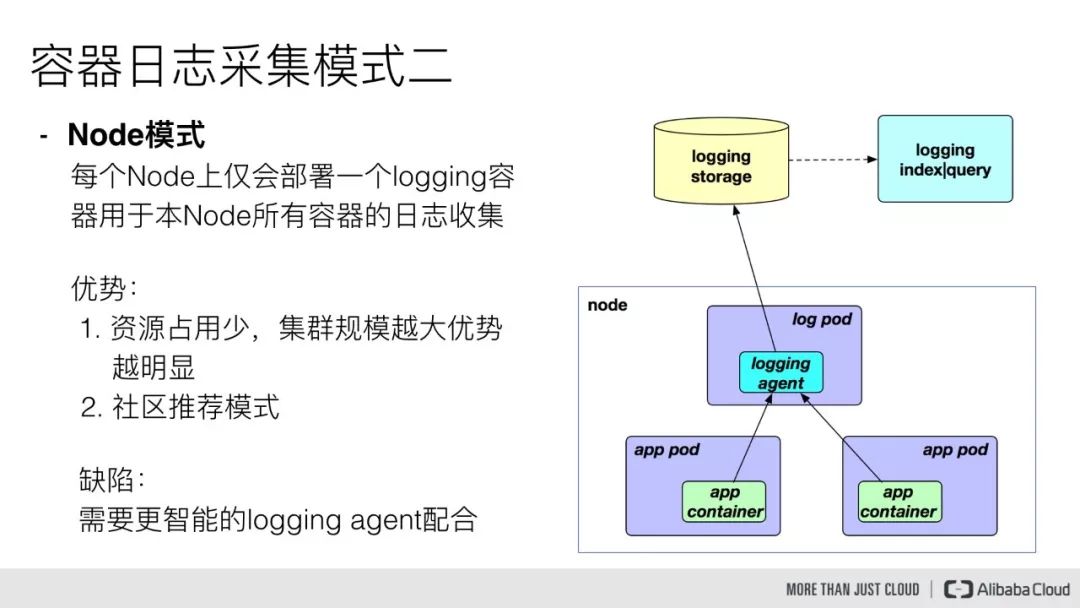
但对于这种模式来说我们需要一个更加智能的日志采集工具来配合,那么这里用 Log-Pilot 工具就是一个很好的选择。因此我们在布署 Log-Pilot 采集工具的时候采用的就是 Node 模式。
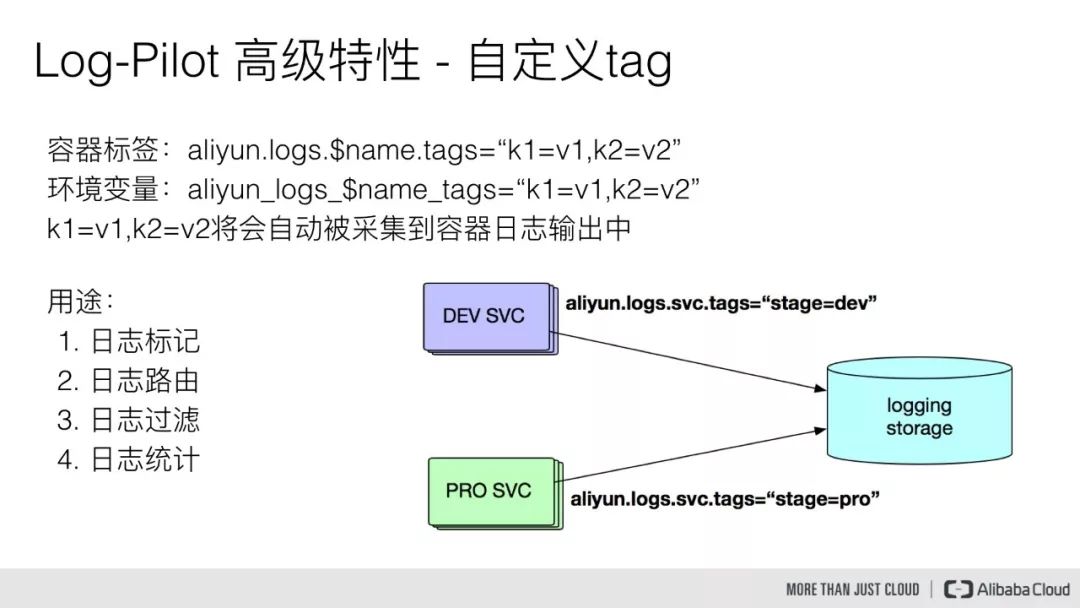
另外 Log-Pilot 也支持自定义 tag,我们可以在容器的标签或者环境变量里配置 aliyun.logs.$name.tags=K1=V1,那么在采集日志的时候也会将 K1=V1 采集到容器的日志输出中。
比如说我们有一种场景,有一个开发环境和测试环境,应用日志都会被采集到统一的一个日志存储后端,假设是一个 ElasticSearch 集群,但是我们在 ElasticSearch 中查询日志的时候又想区分出来,具体某条日志记录到底来源于生产环境,还是测试环境。
那么我们就可以通过给测试环境的容器打上 stage=dev 的 tag,给生产环境的容器打上 stage=pro 的 tag,Log-Pilot 在采集容器日志的时候,同时会将这些 tag 随容器日志一同采集到日志存储后端中,那么当我们在查询日志的时候,就可以通过 stage=dev 或者 stage=pro 能明确地区分出某条日志是来源于生产环境的应用容器所产生,还是测试环境应用容器所产生的。同时通过自定义 tag 的方式我们还可以进行日志统计、日志路由和日志过滤。
另外 Log-Pilot 也支持多种日志解析格式,通过 aliyun.logs.$name.format=<format>标签就可以告诉 Log-Pilot 在采集日志的时候,同时以什么样的格式来解析日志记录。目前主要支持六种:
第一种是 none,这也是默认格式,指不对日志记录做任何解析,整行采集出来直接输出到日志存储后端。
第二钟就是常用的 json 格式,配置成 json 格式之后,Log-Pilot 在采集日志的时候同时会将每一行日志以 json 的方式进行解析,解析出多个 KV 对,然后输出到日志存储后端。
另外几种是 csv,nginx,apache2
最后我们还支持 regexp,用户可以通过 format 标签来自定义正则表达式,告诉 Log-Pilot 在解析日志记录的时候以什么样的拆分格式来进行解析拆分。

下面看一下自定义输出 target,这里我们同样假设一种场景,就是同样有一个生产环境和一个测试环境,应用日志都需要被采集到同一套 Kafka 中,然后由不同的 consumer 去消费。
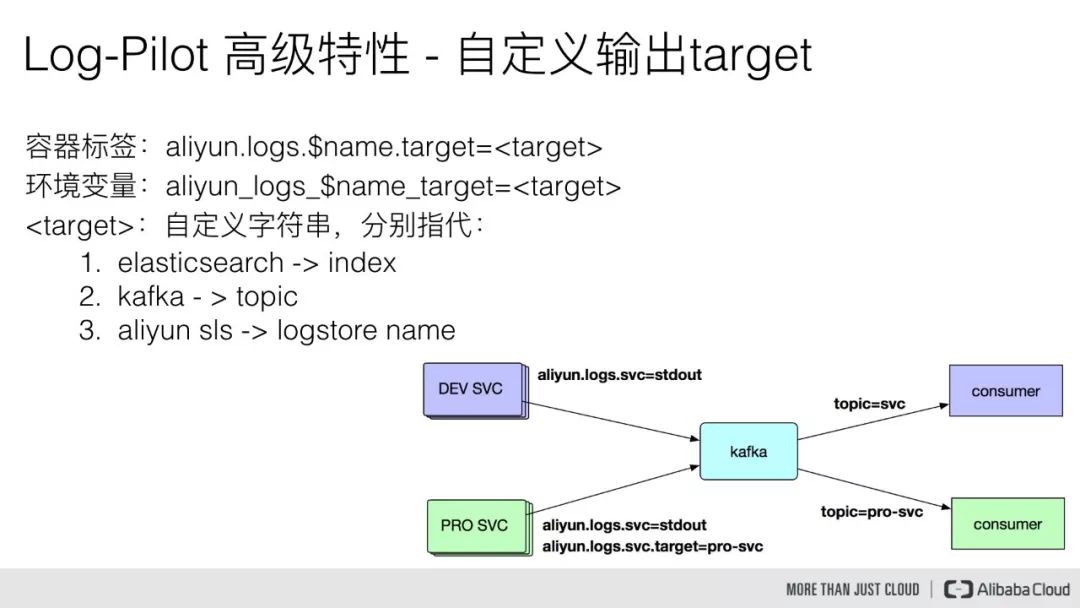
但是我们同样希望区分出来,某条日志数据是由生产环境的应用容器产生的,还是测试环境的应用容器产生的,但我们在测试环境中的应用容器已经配置了 aliyun.logs.svc=stdout 标签,那么当这些应用容器的标准输出日志被采集到 kafka 中,它最终会被路由到 topic=svc 的消息队列中,那么订阅了 topic=svc 的 consumer 就能够接收测试环境的应用容器产生的日志。
但当我们将该应用发布到生产环境时,希望它产生的日志只能交由生产环境的 consumer 来接收处理,那么我们就可以通过 target 的方式,给生产环境的应用容器额外定义一个 target=pro-svc,那么生产环境的应用日志在被采集到 Kafka 中时,最终会被路由到 topic 为 pro-svc 的消息队列中,那么订阅了 topic =pro-svc 的 consumer 就可以正常地接收到来自于生产环境的容器产生的日志。
因此这里的 target 本身也有三种含义:
当我们将日志对接到 ElasticeSearch 的时候,这个 target 字符串就是 Index;
当我们对接到 Kafka 的时候,它指代的就是 topic;
当我们将日志对接到 Aliyun SLS 的时候,它代表的就是 Logstore Name。
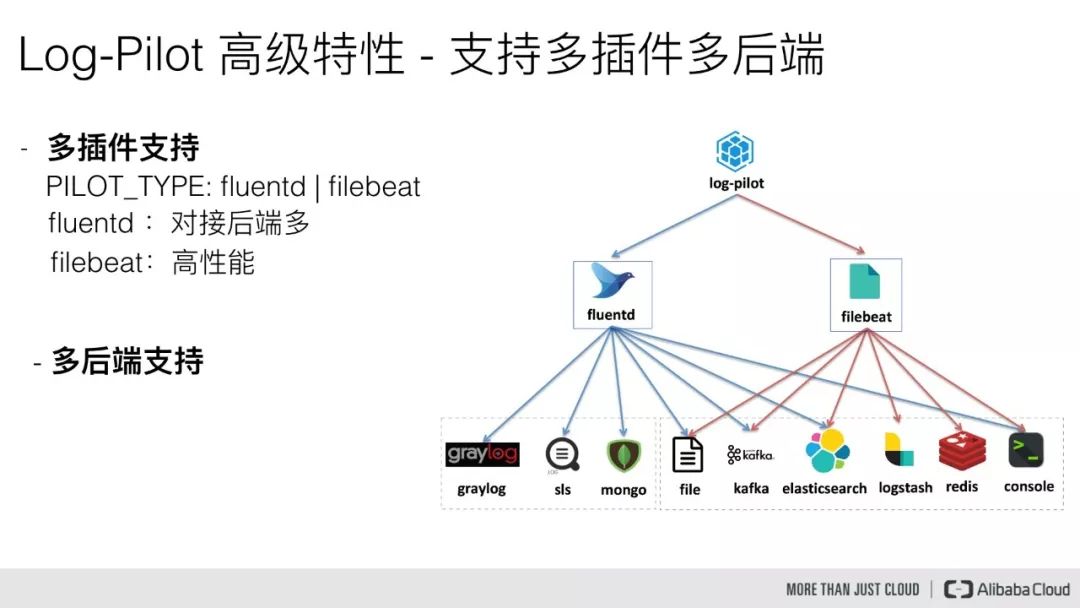
目前 Log-Pilot 支持两种插件,第一种是 fluentd,第二种是 filebeat,同时支持对接多种存储后端,目前 fluentd 和 filebeat 都支持 elasticsearch、kafka、file、console 作为日志存储后端,而 fluentd 还支持 graylog、sls 以及 mongodb 作为存储后端。
支持两种插件的原因
那么为什么我们同时要支持这两种插件呢?主要是因为它们各自有各自的优势,对于 fluentd 来说,它支持的存储后端特别多,而对于 filebeat 来,它的性能特别高。
因此一般我们在对接常见的一些日志存储系统时,我们可以优先考虑 filebeat 插件,但是对一些特殊的场景,比如某些日志存储后端是 filebeat 是不支持的,那我们可以采用 fluentd 的方式来对接。
两种场景下的性能测试
下面简单介绍一下我们之前对于 fluentd 和 filebeat 这两种插件做的一个性能压测。这里主要测试了两种场景:
测试场景 1:是我们事先准备好一个很大的日志文件,然后分别启用 filebeat 和 fluentd 插件来进行日志采集性能对比测试,我们看一下左边图,横坐标表示每行日志的长度,而纵坐标表示每秒日志采集行数。
从左边图可以看出是 fluentd 的采集速率基本上是在 7500-8000 行每秒的采集速率,而 filebeat 的采集速率是在 85000 行每秒的采集速率。而此时我们看一下采集工具的 CPU 使用率,fluentd 插件 CPU 打到百分之百,因为 fluentd 默认使用的是单核,filebeat 插件打到百分之三百多,因为使用的是多协程。
测试场景 2:是我们边产生日志边采集的方式,左边图横坐标是每秒钟写的日志行数,纵坐标是每秒钟采集的日志行数,从这里可以看出 fluentd 在将近 8000 行每秒的采集速率的时候,CPU 基本上打到百分之百,而 filebeat 保持线性增长状态,因此一般在 CPU 足够的情况下,可以达到 10 万行每秒的采集速率。
目前 Log-Pilot 在 Github 上已经开源,欢迎大家一起来完善和增强,我的分享今天到此结束。感谢大家。
以上是关于阿里云Kubernetes日志是怎么管理的?的主要内容,如果未能解决你的问题,请参考以下文章