干货|你想要的百分点大规模Kubernetes集群的应用实践来了
Posted 百分点
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货|你想要的百分点大规模Kubernetes集群的应用实践来了相关的知识,希望对你有一定的参考价值。
编者按
去年8月底,百分点与云知声联合发布了Google开源的集群管理系统Kubernetes的“发行版”——Sextant。在百分点大规模Kubernetes集群经过四五个月的应用实践后,到目前为止,集群上已经承载了百分点推荐系统的大部分业务组件和部分的运维组件。那么,在使用过程中会遇到哪些问题?如何解决?本篇将详尽总结百分点在实践中的经验教训,期望能够更多地回馈社区。
从0到
1
先来讲讲百分点自己的故事:
在传统的集群管理方法下,百分点服务器利用率长期处于20%以下。通常为了完成某个业务目标,团队会申请各自的服务器,然后工程师使用跳板机登陆到这些服务器上完成程序的部署。
这样的弊端是:首先,这些服务器上的空闲资源并不会贡献出来为其他团队所使用;其次,这些服务器在解决业务高峰问题之后,负载下降,而这时团队并不希望服务器被回收,因为不知道如何备份服务器之上的数据。
这样,集群服务器利用率逐步降低,整体集群的维护和管理也变得异常困难,在百分点AI技术运用增多的趋势下,常遇到计算资源不足而导致业务进展缓慢的情况。

如何解决呢?
我们做了很多尝试,最终决定选择CoreOS、Kubernetes(以下简称K8s)、Ceph相结合的技术方案。
对于Kubernetes在生产环境中的应用,百分点是比较早的一批实践者,从开始关注Kubernetes1.0,到将1.2版本实际部署到我们的生产环境中,围绕Kubernetes做了很多周边工作,使Kubernetes能够更好地服务于业务场景。
限于篇幅原因,这里不展开介绍Kubernetes的基本原理和概念了,感兴趣的读者可以在我们的githubsextant项目中,找到相当丰富的文档。
为了达成这样的目标,我们要求开发者使用Docker将自己的应用程序完成封装,逐步将手动的集群部署,切换到使用K8S的集群容器编排之上。如下图所示,需要在团队项目的gitlab repo中增加相应的Dockerfile和编排文件内容,CI环境会自动将应用完成编译->单元测试->docker镜像打包->镜像提交的工作。封装在容器中的应用使用Ceph存储数据,并通过ingress LoadBalancer对外部提供服务。
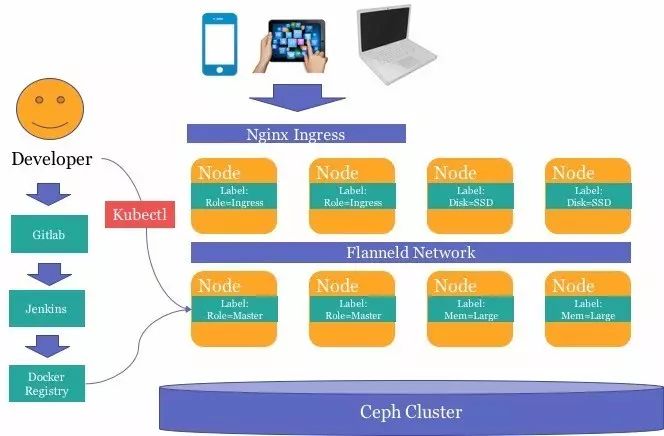
对于Kubernetes在生产环境上的部署,我们希望最大限度的简化K8S集群维护人员的工作。比如扩容一台机器、下架维修一台机器等,只需要维护人员直接完成开机/关机的操作即可。由于K8S的调度编排,可以屏蔽这类操作对应用的影响。
首先要解决的问题,就是如何能够高效的、自动化的进行组件的部署以减少手动部署可能带来的问题。
百分点、云知声在百度科学家王益带领下,合作开发了基于PXE自动化安装CoreOS+Kubernetes集群的开源Sextant项目,只需要简单的三个步骤即可完成集群的安装:规划集群->启动bootstrapper->节点开机自动安装。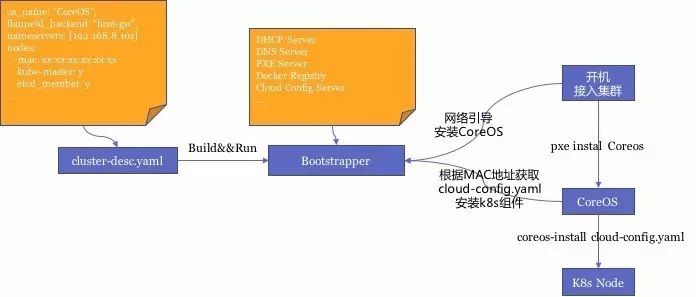
- PXE采用PXE的技术,从网络安装CoreOS的操作系统,完成节点操作系统的初始化。
- 操作顺序:
- Step 0集群规划
规划集群,将集群信息描述为cluster-desc.yaml配置文件,例如操作系统的类型、etcd节点的数量、flanneld协议类型,哪些节点作为master等等。
- Step 1编译、运行bootstrapper
通过上一步骤的cluster-desc.yaml文件,编译bootstrapper的docker image并启动,bootstrapper会提供PXE、DHCP、DNS以及Docker Registry等服务。
- Step 2安装kubernetes节点
将服务器接入集群,开机并从网络引导安装,即可自动完成CoreOS以及K8s组件的安装过程。
下一步就是应用迁移,在收获中也充满了痛。
收获和
痛
至此,我们自认为可以开始像习大大元旦助词说的那样“撸起袖子”,进行逐步的迁移工作了。但经过简单的性能测试后,结果并不理想。运行在K8S之上的服务响应延迟,导致出现至少20%的性能损耗。在踩坑之后,我们对K8S的网络有了更加深入的理解。
一、打造kubernetes高性能网络
但是实际上每个container里约定俗成地只运行一个服务进程,所以还是三层概念:
节点(node)
Pod
Container
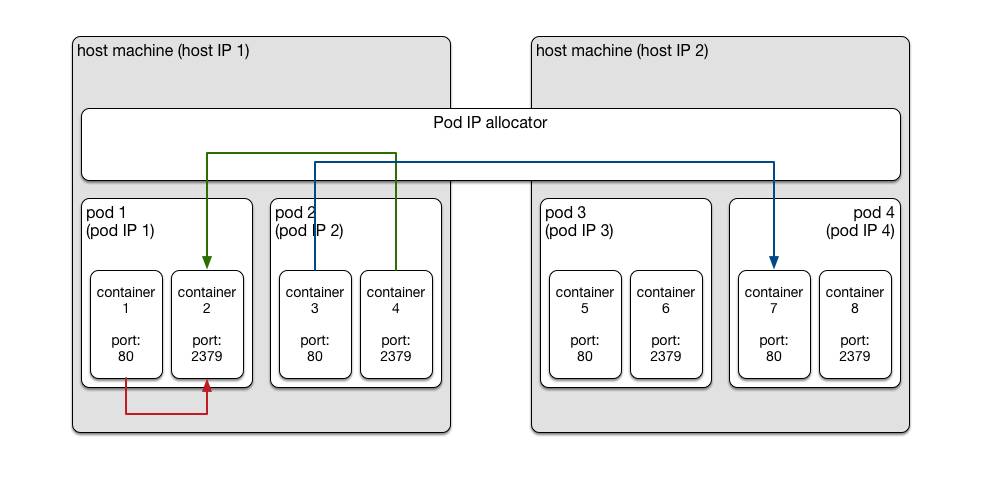
Kubernetes实现这种网络结构有多种方法,如overlay networking、BGP和其他SDN技术,常见的实现包括:Flannel、 Calico、 L2 networking、OpenVSwitch等,我们对常用并活跃的项目进行了针对性评测,结论如下:
可以看到,在L2模式下,针对高性能web应用场景可以达到最佳性能。当然如果有专用的SDN交换机设备,也可以大大提高SDN的网络性能。但综合成本、方案复杂程度、方案后续可扩展性考虑,最终选择flannel host-gw模式。这个模式,要求所有host保持稳定的2层网络连接,然后通过Linux路由表,将Docker bridge的包完成3层转发。
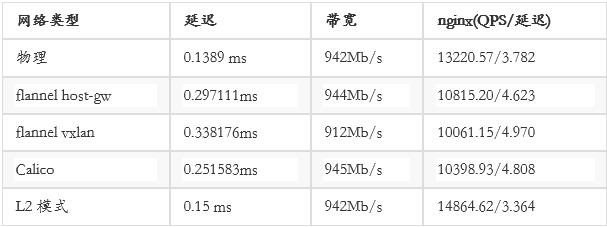
另外一点,在评测过程中发现,linux加在netfilter和iptables相关内核模块之后,平均网络延迟会下降10%左右。但就目前状态来说,使用iptables NAT作为Kubernetes的service负载均衡仍然是性能最高、最简单的方式。后续如果可以使用更优秀的方法提供service负载均衡,可以去掉iptables以降低容器之间的网络延迟。
在这种网络部署下,使用普通的千兆网卡和千兆交换机,即可以较低成本来搭建大规模的集群,并获得相对可观的性能。在针对网络延迟有更高要求的服务,比如Redis等,则考虑直接物理部署作为折中方案。
从上面的介绍可以看出,Kubernetes service主要仍是针对数据中心内部互相访问,若要方便地提供HTTP web服务的创建,则需要引入Ingress的概念。
众所周知的是,Kubernetes中的Service可以将一组pod提供的服务暴露出来供外部使用,并默认使用iptables的方式提供负载均衡的能力。Service通过使用iptables,在每个主机上根据Kubernetes service定义,自动同步NAT表,将请求均衡的转发到后端pod上,并在pod故障时自动更新NAT表。相对于使用userspace方式直接转发流量有更高的效率。常用的Service有ClusterIP、Loadbalancer以及NodePort方式。
- NodePort是为了Kubernetes集群外部的应用方便访问kubernetes的服务而提供的一种方案,它会在每个机器上。
- 由于NAT性能的问题,NodePort会带来一定的性能损失,在一些场景下,我们也会选用Loadbalancer作为k8s集群外部应用访问K8s集群内部应用的统一入口。百分点采用的Loadbalancer负载均衡器是基于haproxy,通过watcher Kubernetes-apiserver中service以及endpoint信息,动态修改haproxy转发规则来实现的。
从上面的介绍可以看出,Kubernetes service仍是主要针对数据中心内部互相访问,若要方便地提供HTTP web服务的创建,则需要引入Ingress的概念。
1. Ingress
2. Ingress HA
Ingress的机器是整个集群的入口,如果其中一台机器出现故障,带来的影响将会是致命的。我们也曾考虑过使用F5等技术做前端的高可用,但最后基于成本和可维护性考虑,最终使用Keepalived+vip的方案。
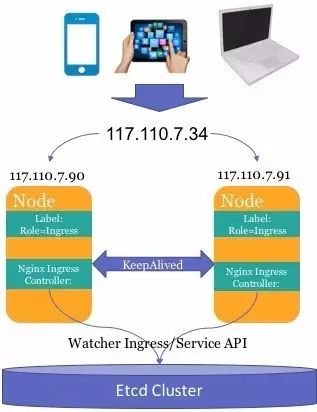
3. Ingress优化
- 性能优化
由于nginxIngress Controller要监听物理机上的80端口,我们最初的做法是给他配置了hosrtport,但当大量业务上线时,我们发现QPS超过500/s就会出现无法转发数据包的情况。经过排查发现,系统软中断占用的CPU特别高,hostport会使用iptables进行数据包的转发,后来将Ingress Controller修改为hostnetwork模式,直接使用Docker的host模式,性能得到提升,QPS可以达到5k以上。
- Nginx配置优化
Nginx IngressController大致的工作流程是先通过监听Service、Ingress等资源的变化然后根据Service、Ingress的信息以及nginx.temple文件,将每个service对应的endpoint填入模板中生成最终的Nginx配置。但是很多情况下模板中默认的配置参数并不满足我们的需求,这时需要通过kubernetes中ConfigMap机制基于Nginx Ingress Controller使用我们定制化的模板。
- 日志回滚
默认情况下Docker会将日志记录在系统的/var/lib/docker/container/xxxx下面的文件里,但是前端日志量是非常大的,很容易就会将系统盘写满,通过配置ConfigMap的方式,可以将日志目录改到主机上,通过配置logrotate服务可以实现日志的定时回滚、压缩等操作。
- 服务应急
当线上服务出现不可用的情况时,我们会准备一套应急的服务作为备用,一但服务出现问题,我们可以将流量切换到应急的服务上去。在k8s上,这一系列操作变得更加简单,这需再准备一套ingress规则,将生产环境的Servuce改为应急的Service,切换的时候通过kubectl replace -f xxx.yaml 将相应的Ingress替换,即可实现服务的无感知切换。
ubernetes集群服务
作为一个集群化的操作系统,基础服务必不可少,开发者通常需要经常查看服务的日志,查看监控数据,查看运行状态等。我们为Kubernetes集群配置了很多基础类服务,使集群使用起来更加高效。
1. 日志管理
当我们的应用运行在集群操作系统上时,如何高效地查看、分析服务日志是一个必须要解决的问题。百分点采用了Fluented+Elasticsearch+Kibana的方案,整个套件也都是运行在Kubernetes集群上的。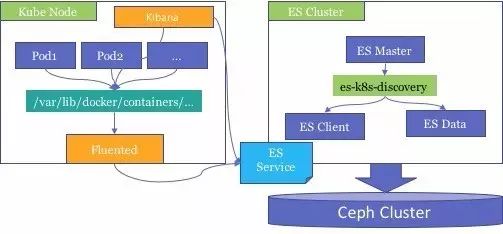
- Fluentd
Fluented是使用Kubernetes中Daemonset的机制,使得fluented启动在每一个节点上,并自动采集Docker Container的日志到ES集群中。
- Elasticsearch
- Kibana
Kibana中能够根据用户自定义筛选、聚合,方便用户查询使用。
2 . 系统监控
通过heapster+collectd+influxdb+grafana解决多源数据采集、监控数据存储、查询展现的问题。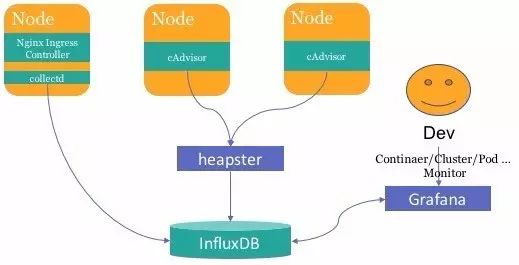
- heapster负责从cAdvisor中采集宿主机以及container中的监控数据并写入influxdb中。
- collectd负责采集类似nginx组件的监控数据写入influxdb中。
- influxdb负责按时间序列存储监控数据,并且支持类SQL的语法来访问数据 。
- grafana提供了WebUI,通过用户自定义的查询规则,生成SQL语句来查询influxdb中的数据,并最终以图表的形式展现给用户。
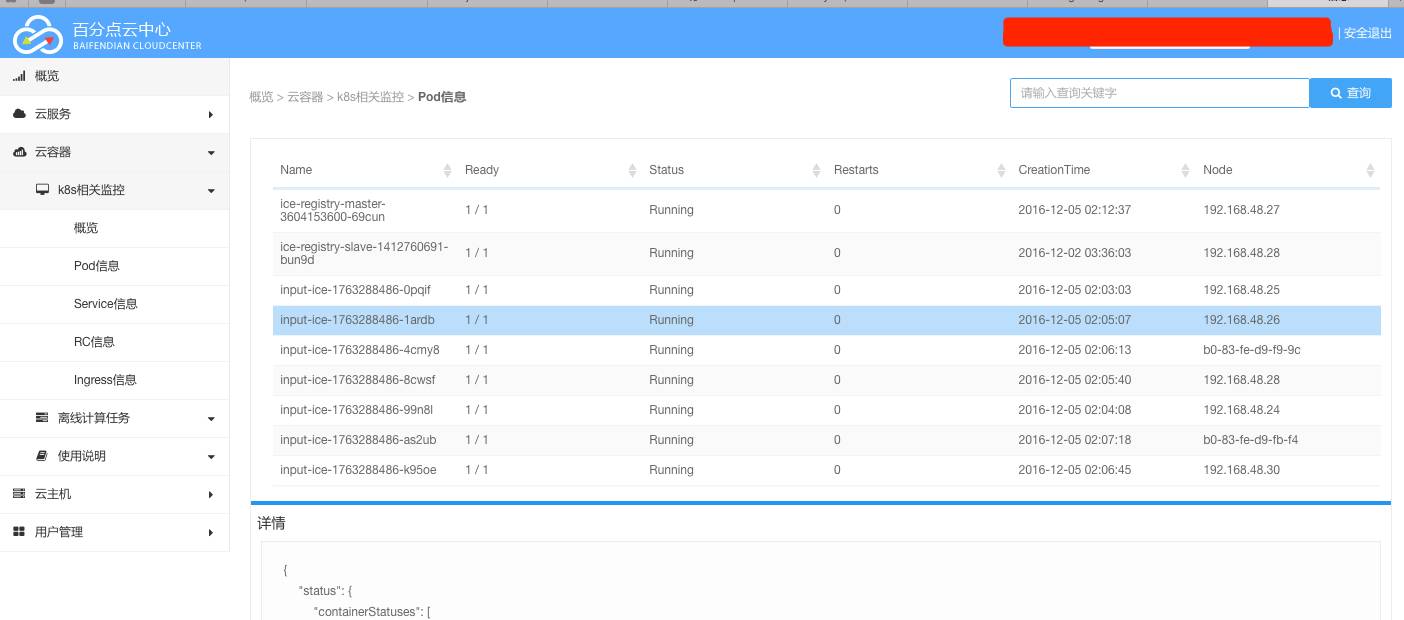
3. 统一Dashboard
为了简化kubernetes集群的使用,百分点的技术团队开发了系统,使用户使用起来更加的方便,并且此项目也在Github上进行了开源。
4. 持续化集成
Docker是我们落地Devops理念的核心技术,从开发人员写下第一行代码开始,我们构建了这样一条持续集成的流水线。
我们选择了Gitlab作为代码仓库,当开发人员向Gitlab提交代码,Jenkins会监听每个tag,每次push事件,有选择的自动构建为docker image,并推向Docker Registry,存储在我们的Docker仓库中。随后,Jenkins会将新版本的镜像推到集成测试的Kubernetes集群中,完成一次构建、测试、预上线的流程。待测试通过后,再发布到生产环境。
5. 持续化部署
在逐步将线上应用迁移到kubernetes集群过程中,当然也遇到不少问题,每个应用在提交之后需要经过多次修改和更新才可以正式上线,为了方便更新、并尽量减少人为操作的失误,我们使用“编排文件版本管理+kubernetes deployment”完成持续化部署。
- 什么是Deployment?
Deployment描述了待部署Pod的状态,只需要定义我们期望的一组Pod的状态,kube-controller会帮助我们在集群上维持这一状态,并且可以很方便地在上面做roll-out和roll-back。
- 如何更新Deployment?
直接使用kubectl editdeployment/{your deployment}即可对相应deployment进行修改。并且可以指定最大不可用的Pod个数来控制滚动更新的进度。每次执行edit命令之后,就会触发deployment的rolling update,应用会在后台完成逐个平滑升级。
- 持续部署
在每个应用的代码仓库中,会增加一个.kube的目录,下面存放本应用的yaml编排文件,每次部署升级都直接使用对应版本的编排文件即可完成部署。
四、打造统一持久化存储平台
Kubernetes在运行时是基于容器技术的,这就意味着容器的停止会销毁容器中的数据。若应用要使用持久化的存储,如果直接挂在容器所在主机的磁盘目录,这个编排系统会显得十分混乱。虽然Kubernetes提供了诸如hostPath机制,除非应用和主机具有非常明确的绑定关系,否则不推荐使用。这样,我们需要一个通过网络可访问的存储池,作为统一的集群存储平台。选型的问题这里不详细展开,我们最中使用ceph作为Kubernetes的后端存储。
在部署时,考虑到kubernetes编排的网络请求可能和ceph的数据存储请求抢占网卡带宽而导致整体集群瘫痪,预先将kubernetes访问ceph集群的网络使用单独的两个网口做bond0之后连接ceph集群的交换机。同时为了防止多个容器突发性的高IOPS对ceph集群的访问,我们正在开发storage-iops的qos限制功能。
虽然ceph提供了3种存储访问的方式,我们还是选用了相对稳定的rbd,没有使用ceph filesystem模式。在rbd模式下,首先要保证内核已经加在了rbd.ko内核模块,和ceph-common包。这一步,我们在前面提到的sextant自动安装系统中已经完成打包。
接下来在使用rbd作为pod存储时可以参考示例:
{ "apiVersion": "v1beta3", "id": "rbdpd2", "kind": "Pod", "metadata": { "name": "rbd2" }, "spec": { "containers": [ { "name": "rbd-rw", "image": "kubernetes/pause", "volumeMounts": [ { "mountPath": "/mnt/rbd", "name": "rbdpd" } ] } ], "volumes": [ { "name": "rbdpd", "rbd": { "monitors": [ "192.168.0.1:6789" ], "pool": "rbd", "image": "foo", "user": "admin", "secretRef": { "name": "ceph-secret" }, "fsType": "ext4", "readOnly": true } } ] } }
|
目前,我们已经使用kubernetes+ceph rbd部署使用了mysql、MongoDB、Redis、InfluxDB、ElasticSearch等服务和应用。
百分点
实
践总结
到目前为止,百分点的Kubernetes集群上承载了推荐系统的大部分业务组件和部分的运维组件。Kubernetes相对来说还比较新,集群上也需要更多的工具才能让用户应用起来更加的方便。非常感谢Kubernetes社区、王益以及云知声公司的技术团队,百分点会持续专注在Kubernetes的建设,期望能够更多地回馈社区。
相关文章链接:
以上是关于干货|你想要的百分点大规模Kubernetes集群的应用实践来了的主要内容,如果未能解决你的问题,请参考以下文章
#yyds干货盘点# 如何保障你的 Kubernetes 集群资源不会被打爆(18)
#yyds干货盘点# Kubernetes 集群权限管理那些事儿(17)
有容云干货-容器系列Kubernetes调度核心解密:从Google Borg说起
#yyds干货盘点# Kubernetes 怎样控制业务的资源水位?(16)