如何解决 Kubernetes 的多租户难题
Posted K8sMeetup
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何解决 Kubernetes 的多租户难题相关的知识,希望对你有一定的参考价值。
| 为 | 容 | 器 | 技 | 术 | 而 | 生 |
翻译:夏天
技术校对:星空下的文仔
Kubernetes 是一种新内核(kernel)。与典型的操作系统内核相对应,我们可以将其称为“集群内核”。对于尝试部署应用程序的用户来说,Kubernetes 非常棒。当然,我们依然面临着以前在操作系统内核方面就曾面临的许多挑战。其中之一就是权限隔离。在 Kubernetes 中,我们称之为多租户(multi-tenancy),或者一个集群中的多租户隔离。
社区的多租户工作组中关于多租户模式问题的讨论可谓经久不衰。 (如果你想查看这些 Google 文档,你需要成为 kubernetes-wg-multitenancy Google 群组的成员。) 针对不同的模式问题,大家也给出了一些相应的建议。
Kubernetes 目前的租户模式假定集群是安全边界。你可以在 Kubernetes 之上构建 SaaS,但需要携带自己的可信 API,而不是使用 Kubernetes API。如果你想要安全地构建集群,那么即使是在 SaaS 上你也需要考虑很多因素。
这篇文章我们关注的是“多租户难题”(hard multi-tenancy)。租户间互不信任,彼此认为对方是恶意的。多租户的难点在于同一集群中的多租户不能访问其他租户的任何内容。要解决这一难题,我们们首先就要让安全边界成为 Kubernetes namespace 对象。
多租户模式难题尚未解决,但目前有一些建设性的建议。所有系统都有缺陷,没有什么是完美的。像 Kubernetes 这样复杂而庞大的系统确实很容易受到攻击。只要利用 Kubernetes 的一个漏洞得到管理员的全部权限,那就全面崩溃了。系统安全和租户间隔离不能被保证。接下来,我将在文章中介绍为什么拥有多个安全层如此重要。
逻辑漏洞风险最高的攻击面是 Kubernetes API,因此租户之间必须进行隔离。远程代码执行风险最高的攻击面是在容器中运行的服务,所以也必须进行多租户隔离。
如果你看一看开源 repo 和 Kubernetes 的发展速度,就会发现 Kubernetes 与已占据了 Windows,Mac OS X,Linux 和 FreeBSD 的宏内核有很多相似之处。幸运的是,目前已经有很多可以在宏内核(monolithic kernels)中实现权限隔离的方案了。
在文中,我还提出了一个解决方案是内核嵌套(Nested Kernel):Intra-Kernel 隔离,即通过在宏内核中嵌入一个小内核来解决宏内核中权限隔离的问题。
我们需要多个安全层
我们今天熟知的“沙箱”(sandboxes)被定义为具有多个安全层。例如,我为 contained.af playground 制作的沙箱具有由 seccomp,apparmor,kernel namespaces,cgroups,capabilities 和非特权 Linux 用户定义的安全层,所有这些层不必重叠。如果用户要使用 apparmor 或 seccomp bypass,并尝试在容器内部调用 mount ,则 Linux 的 CAP_SYS_ADMIN 功能会阻止 mount 执行。
如果系统中存在一个漏洞,这些安全层可以确保它不至于影响整个系统。在解决 Kubernetes 中多租难题时也需要这个思路。这就可以解释为什么现有的所有建议都不够完善。因为我们至少需要两个安全层,而这些建议通常都只有一个。
要将 Intra-Kernel 隔离应用于 Kubernetes,我们需要两个安全层。接下来我们进行更深入地探讨。
通过 Namespace 隔离
现有的多租户难题解决方案是把 Namespace 作为 Kubernetes 上多租户的安全边界。“Namespace”是由 Kubernetes 定义的。这些建议都有缺陷:如果你只利用 Kubernetes 的一部分,那么你就可以拥有横向扩展 Namespace 的权限,因此可以横向扩展租户。
通过 Intra-Kernel 隔离,Namespace 仍然是安全边界。但是,并非所有人都共享主要的 Kubernetes 系统服务,每个 Namespace 都拥有自己的“嵌套” Kubernetes 系统服务。这意味着 api-server,kube-proxy 等都将单独运行在该 Namespace 的一个 pod 中。部署到该 Namespace 的租户将无法访问实际的 root 级别 Kubernetes 系统服务,而只能访问其 Namespace 中运行的那些服务。Kubernetes 中的一个漏洞不会让整个系统崩溃,只会影响 Namespace。
另一个安全边界是容器隔离本身。这些 pod 可能会被像例如 PodSecurityPolicy 和NetworkPolicy 这样的现有资源进一步锁定。随着生态系统不断地增长、创新,你甚至可以在容器之间运行虚拟机(katacontainers)进行硬件隔离,从而为集群中的服务提供最高级别保护。
对于那些熟悉 Linux Namespace 的人来说,你可以把它看作是一个克隆的 Kubernetes。他们的设计大致相似。
例如在 Linux 上克隆新的 Namespace 像这样:

所以当你在 Intra-Kernel 隔离创建一个新的 Kubernetes Namespace 时,大致如下:

在 Linux 中,Namespace 控制进程是可见的。这适用于那些在 Kubernetes 中指定 Namespace 的用户。由于每个 Namespace 都有自己的系统服务,因此所有的服务用户都是可以看到的。
与上面的伪代码不同,Kubernetes Namespace 将自动获取每个系统服务的新组件。这更符合 Solaris Zones 或 FreeBSD Jails 的设计。
在我的博客文章《 Setting the Record Straight: Containers vs. Zones vs. Jails vs. VMs》中,我介绍了各种隔离技术之间的差异。在这个设计中,我们更接近于 Zones 或 Jails 的方法。容器配备了所有部件。Kubernetes 中的 Namespace 应该自动建立一个完全隔离的世界,就像 Zones 或 Jails 那样,用户不必担心它们配置是否正确。
Linux 中 Namespace 的另一个问题是, Namespace 不是万能的。这种设计可以确保 Kubernetes 的各个部分都是针对每个租户进行隔离的。
通过资源控制隔离
上述设计仍然有一些尚未解决的问题。接下来我们来看看 Linux 中的另一个控制机制:Cgroups。Cgroups 控制流程是可行的,他们是资源控制的主人。
这个概念也适用于 Kubernetes Namespace。Cgroups 不像内存消耗和 CPU 那样控制资源, 而是应用于节点(node)。一个 Namespace 内的租户只能访问指定的某些节点。所有的 Namespace 服务也将在机器级别被隔离。不同租户的服务不会在同一台机器上运行。在未来这可能是一个设置,但默认情况下节点是不共享的。
该模型允许在我们的嵌套 API 服务器在各个节点上指定使用一组 kubelet。
在这一点上,我们将租户可以看到的东西(Kubernetes Namespace)和他们可以使用的东西(指定给 Namespace 的节点)进行隔离。
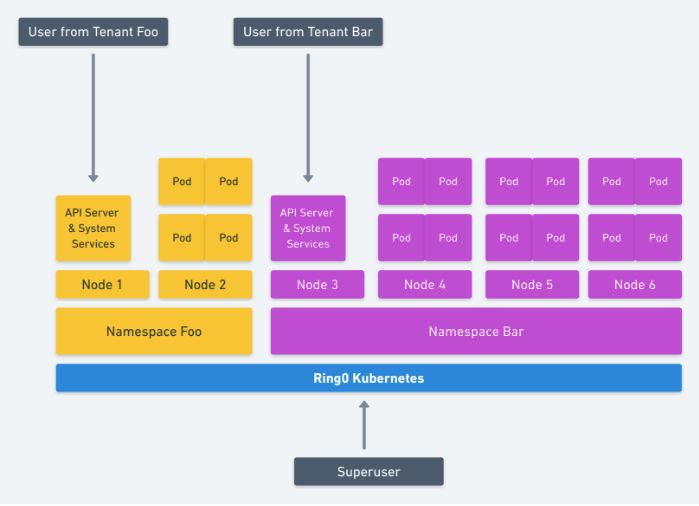
或者,如果 Namespace 的系统服务与嵌套的虚拟容器(katacontainers)隔离,并且你考虑了此设计文档(https://docs.google.com/document/d/1PjlsBmZw6Jb3XZeVyZ0781m6PV7-nSUvQrwObkvz7jg/edit)中列出的所有其他变量。那么,那些服务就可以共享节点。与上面的方法相比,这种方法在资源利用率方面表现更好。如下所示:
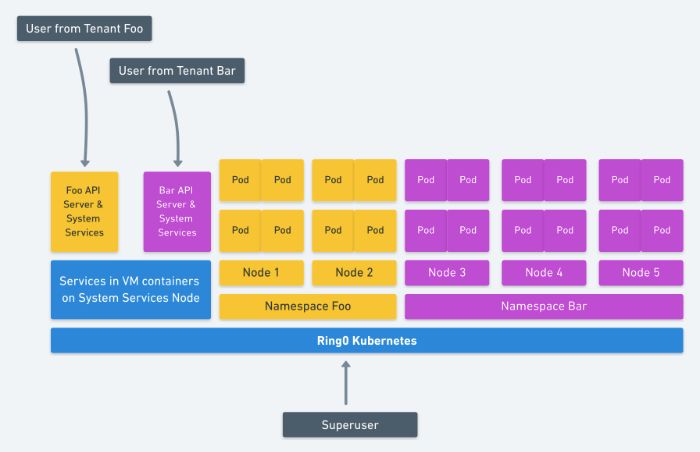
如果更进一步,像这个文档(https://docs.google.com/document/d/1PjlsBmZw6Jb3XZeVyZ0781m6PV7-nSUvQrwObkvz7jg/edit)所说,隔离整个系统,将容器放进完全沙盒或者 VM 容器里面,那么所有服务都可以共享节点,这将进一步提高资源利用率。
跨越多个 Namespace 的租户
工作组曾经几次提出租户可能需要跨越多个 Namespace 的问题。虽然我不觉得这应该是一个默认设置,但我看不到它有什么问题。
我们再来看看 Namespace 在 Linux 中的工作方式以及我们是如何将它们用于容器中。每个 Namespace 都是一个文件描述符。你可以通过为想要共享的 Namespace 指定文件描述符,然后调用系统的 setns 函数的方式来在容器之间共享 Namespace。
在 Kubernetes 中,我们可以实施相同的方案。一个 superuser 可以指定一个 Namespace,让有权访问该 Namespace 的租户可以实现共享。
总的来说,这个方案使用了内核隔离技术的以往的专业知识,并从过去的内核隔离技术中汲取了经验教训。
随着 Kubernetes 生态系统的不断扩大的,在租户之间建立多个安全层是非常重要的。诸如故障安全默认设置,完全控制,最低权限和最少通用机制等安全技术非常流行,但很难应用于宏内核。Kubernetes 默认共享一切,并且各不相同,它的驱动程序和插件,就像操作系统内核一样。将相同的内核隔离技术应用于 Kubernetes 将是更好的权限隔离解决方案。
这为我们带来了什么?
我们已经用完全隔离这种我们非常擅长的方式解决了我们的威胁模型。逻辑漏洞风险最高的攻击面即 Kubernetes API 具有完全的逻辑分离,因为每个租户都有自己的逻辑漏洞。远程代码执行风险最高的攻击面(容器本身)与其他租户完全虚拟化分离。这种隔离要么通过指定的节点本身隔离到租户,要么通过运行使用硬件隔离的容器来隔离。其他租户唯一可行的途径是在某些服务中获得远程代码执行,然后突破容器(和/或 VM)的限制。
通过节点资源控制进行的 Intra-Kernel 隔离(如第一个图所示)与由一个 superuser 操作的两个完全分离的集群是相同的。由于节点是为每个租户指定的,因此大家的资源利用率都不会太高。
具有最高资源控制收益的模型可以安全地设置你的集群,以将嵌套虚拟机用作容器,或者将容器本身完全沙箱化,以使边界是容器而不是节点。这减轻了运营商运行多个集群的痛苦,并且可以更有效地使用资源,同时还可以维持多层安全。
上面这些解决方案都不是一成不变的。这只是我解决这个问题的浅见。如果您对 Kubernetes 或其他方面的多租户问题感兴趣,请加入工作组。我期待在那里与您进行更多讨论。谢谢!
原文链接:https://medium.freecodecamp.org/how-to-know-if-kubernetes-is-right-for-your-saas-315dfffe0a25
推荐阅读:
END
以上是关于如何解决 Kubernetes 的多租户难题的主要内容,如果未能解决你的问题,请参考以下文章
如何解决使用mybatis-plus提供的多租户插件出现Column ‘tenant_id‘ specified twice问题