容器容器云与Kubernetes技术漫谈
Posted K8S中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了容器容器云与Kubernetes技术漫谈相关的知识,希望对你有一定的参考价值。
我们为什么使用容器?
我们为什么使用虚拟机(云主机)? 为什么使用物理机? 这一系列的问题并没有一个统一的标准答案。因为以上几类技术栈都有自身最适用的场景,在最佳实践之下,它们分别都是不可替代的。 原本没有虚拟机,所有类型的业务应用都直接跑在物理主机上面,计算资源和存储资源都难于增减,要么就是一直不够用,要么就一直是把过剩的资源浪费掉,所以后来我们看到大家越来越多得使用虚拟机(或云主机),物理机的使用场景被极大地压缩到了像数据库系统这样的特殊类型应用上面。
原本也没有容器,我们把大部分的业务应用跑在虚拟机(或云主机)上面,把少部分特殊类型的应用仍然跑在物理主机上面。但现在所有的虚拟机技术方案,都无法回避两个主要的问题,一个问题是虚拟化Hypervisor管理软件本身的资源消耗与磁盘IO性能降低,另一个是虚拟机仍然还是一个独立的操作系统,对很多类型的业务应用来说都显得太重了,导致我们在处理虚拟机的扩缩容与配置管理工作时效率低下。所以,我们后来发现了容器的好处,所有业务应用可以直接运行在物理主机的操作系统之上,可以直接读写磁盘,应用之间通过计算、存储和网络资源的命名空间进行隔离,为每个应用形成一个逻辑上独立的“容器操作系统”。除此之外,容器技术还有以下优点:简化部署、多环境支持、快速启动、服务编排、易于迁移。
容器技术的一些缺点:仍然不能做到彻底的安全隔离,技术栈复杂度飚升,尤其是在应用了容器集群技术之后。所以如果只是小规模的使用,做实验或测试是可以的,上生产环境需要三思而后行。
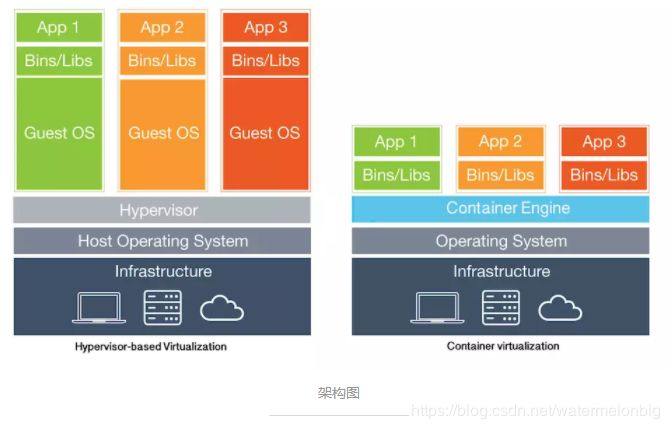
容器与容器集群技术的演进
容器技术的演进路线
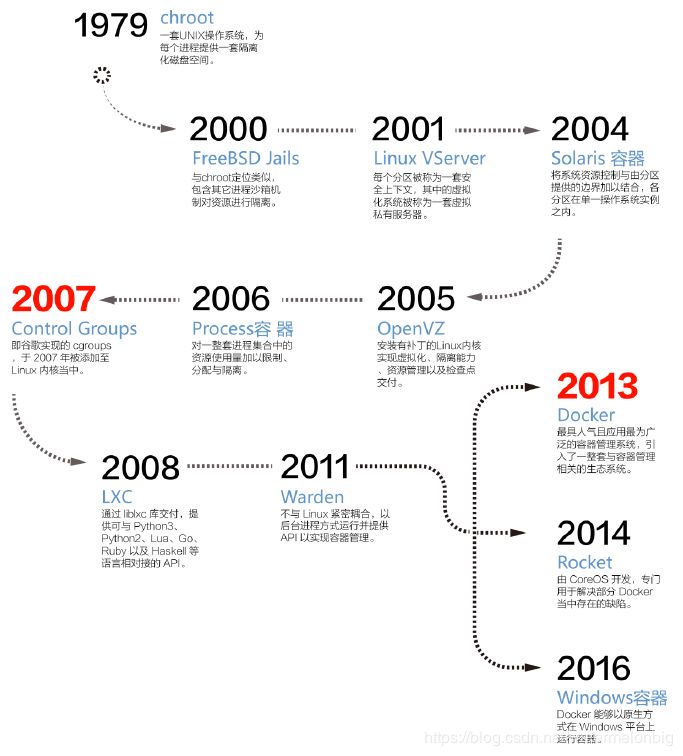
注:上图取自《容器技术及其应用白皮书[v1.0]》
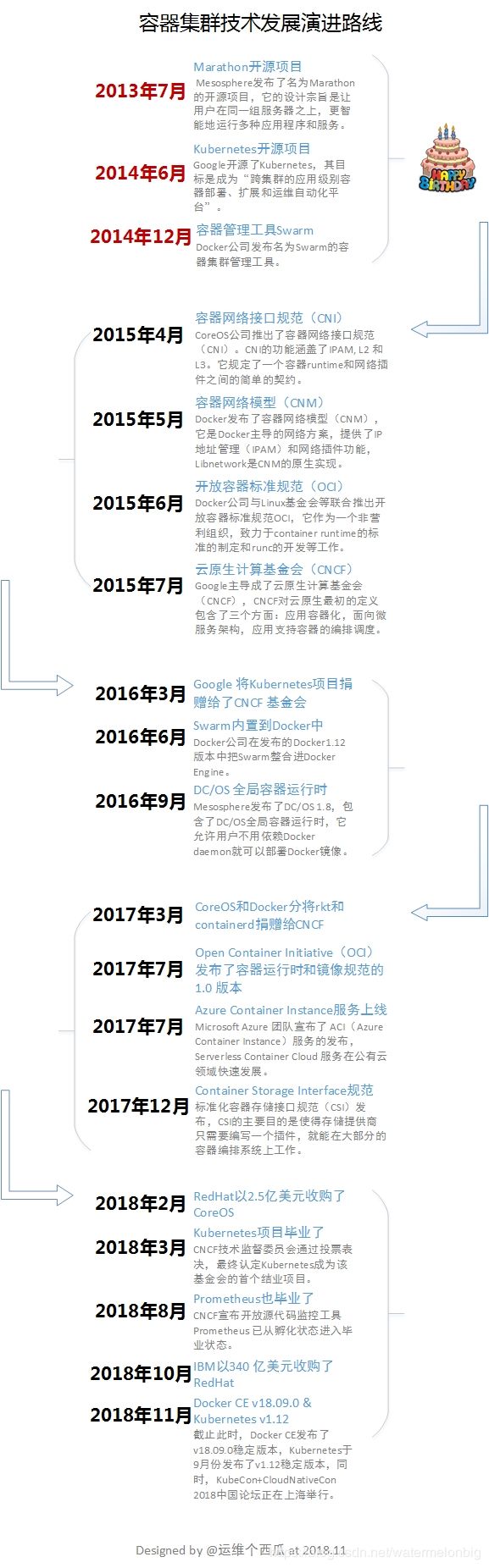
容器集群技术的演进
上图描述了容器技术的演进,此后的近三年来的容器技术演进发展为主要是以容器集群技术为中心,如下所示。
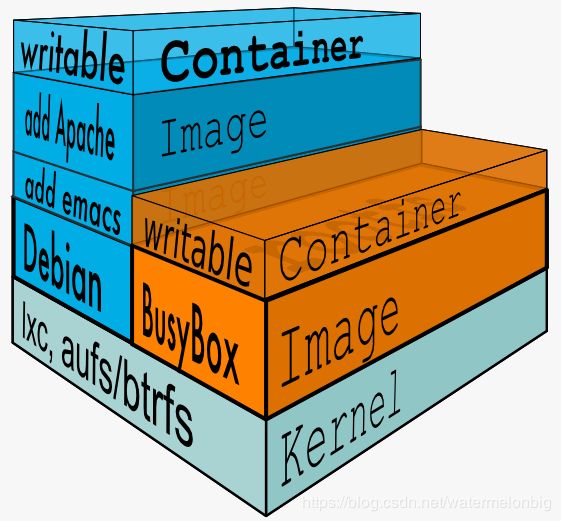
器的运行原理与基本组件
Docker容器主要基于以下三个关键技术实现的: – Namespaces – Cgroups技术 – Image镜像
容器引擎 容器引擎(Engine)或者容器运行时(Runtime)是容器系统的核心,也是很多人使用“容器”这个词语的指代对象。容器引擎能够创建和运行容器,而容器的定义一般是以文本方式保存的,比如 Dockerfile。
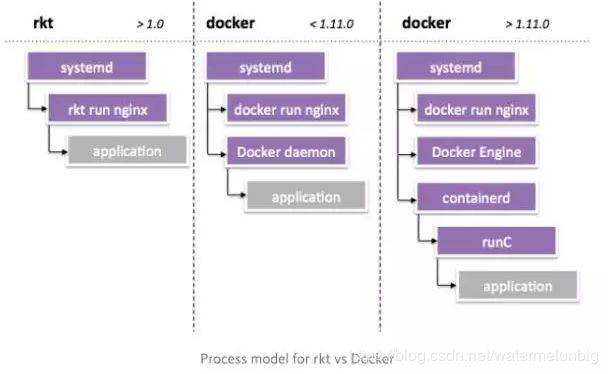
Docker Engine :目前最流行的容器引擎,也是业界的事实标准。
Rkt:CoreOS 团队推出的容器引擎,有着更加简单的架构,一直作为 Docker 的直接竞争对手存在,是 kubernetes 调度系统支持的容器引擎之一。
containerd:这个新的Daemon是对Docker内部组件的一个重构以便支持OCI规范,containerd 主要职责是镜像管理(镜像、元信息等)、容器执行(调用最终运行时组件执行),向上为 Docker Daemon 提供了 gRPC 接口,向下通过 containerd-shim 结合 runC,使得引擎可以独立升级。
docker-shim:shim 通过调用 containerd 启动 docker 容器,所以每启动一个容器都会起一个新的docker-shim进程。docker-shim是通过指定的三个参数:容器id,boundle目录和运行时(默认为runC)来调用runC的api创建一个容器。
runC :是 Docker 按照开放容器格式标准(OCF, Open Container Format)制定的一种具体实现,实现了容器启停、资源隔离等功能,所以是可以不用通过 docker 引擎直接使用runC运行一个容器的。也支持通过改变参数配置,选择使用其他的容器运行时实现。RunC可以说是各大CaaS厂商间合纵连横、相互妥协的结果,
注:RunC在各个CaaS厂商的推动下在生产环境得到广泛的应用。Kubernetes目前基本只支持RunC容器,对于Docker超出其容器抽象层之外的功能,一概不支持。同样,Mesos也通过其Unified Containerizer只支持RunC容器,目前还支持Docker,但是未来的规划是只支持Unified Containerizer。CF也通过Garden只支持RunC,不支持Docker超出RunC之前的功能。
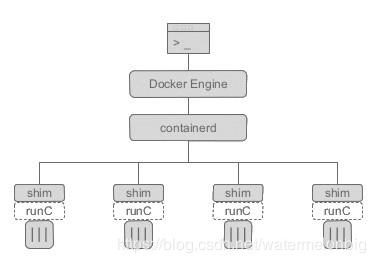
为什么在容器的启动或运行过程中需要一个 docker-containerd-shim 进程呢? 其目的有如下几点: – 它允许容器运行时(即 runC)在启动容器之后退出,简单说就是不必为每个容器一直运行一个容器运行时(runC) – 即使在 containerd 和 dockerd 都挂掉的情况下,容器的标准 IO 和其它的文件描述符也都是可用的 – 向 containerd 报告容器的退出状态
rkt与containerd的区别是什么? 一个主要的不同之处是,rkt作为一个无守护进程的工具(daemonless tool),可以用来在生产环境中,集成和执行那些特别的有关键用途的容器。举个例子,CoreOS Container Linux使用rkt来以一个容器镜像的方式执行Kubernetes的agent,即kublet。更多的例子包括在Kubernetes生态环境中,使用rkt来用一种容器化的方式挂载volume。这也意味着rkt能被集成进并和Linux的init系统一起使用,因为rkt自己并不是一个init系统。kubernets支持容器进行部署,其所支持的容器不只是仅仅局限于docker,CoreOS的rkt也是容器玩家之一,虽然跟docker比起来还是明显处于绝对下风,但有竞争总要好过没有。
容器编排和管理系统
容器是很轻量化的技术,相对于物理机和虚机而言,这意味着在等量资源的基础上能创建出更多的容器实例出来。一旦面对着分布在多台主机上且拥有数百套容器的大规模应用程序时,传统的或单机的容器管理解决方案就会变得力不从心。另一方面,由于为微服务提供了越来越完善的原生支持,在一个容器集群中的容器粒度越来越小、数量越来越多。在这种情况下,容器或微服务都需要接受管理并有序接入外部环境,从而实现调度、负载均衡以及分配等任务。 简单而高效地管理快速增涨的容器实例,自然成了一个容器编排系统的主要任务。
容器集群管理工具能在一组服务器上管理多容器组合成的应用,每个应用集群在容器编排工具看来是一个部署或管理实体,容器集群管理工具全方位为应用集群实现自动化,包括应用实例部署、应用更新、健康检查、弹性伸缩、自动容错等等。 容器编排和管理系统的分层结构图
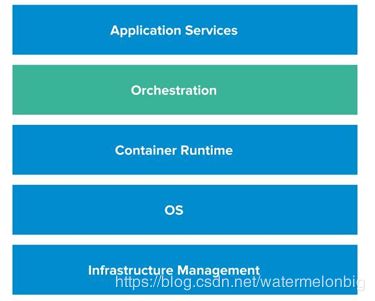
容器编排和管理系统界的主要选手 – Kubernetes:Google 开源的容器管理系统,起源于内部历史悠久的 Borg 系统。因为其丰富的功能被多家公司使用,其发展路线注重规范的标准化和厂商“中立”,支持底层不同的容器运行时和引擎(比如 Rkt),逐渐解除对 Docker 的依赖。Kubernetes的核心是如何解决自动部署,扩展和管理容器化(containerized)应用程序。目前该项目在github上Star数量为43k。 – Docker Swarm: 在 Docker 1.2 版本后将 Swarm 集成在了 Docker 引擎中。用户能够轻松快速搭建出来 docker 容器集群,几乎完全兼容 docker API 的特性。目前该项目在github上Star数量为5.3k。 – Mesosphere Marathon:Apache Mesos 的调度框架目标是成为数据中心的操作系统,完全接管数据中心的管理工作。Mesos理念是数据中心操作系统(DCOS),为了解决IaaS层的网络、计算和存储问题,所以Mesos的核心是解决物理资源层的问题。Marathon是为Mesosphere DC/OS和Apache Mesos设计的容器编排平台。目前该项目在github上Star数量为3.7k。
注:国内外有很多公司在从事基于上面三个基础技术平台的创新创业,为企业提供增值服务,其中做得不错的如Rancher,其产品可以同时兼容 kubernetes、mesos 和 swarm 集群系统,此外还有很多商用解决方案,如OpenShift。
中国市场的表现 在中国市场,2017 年 6 月 Kubernetes 中国社区 K8SMeetup 曾组织了国内首个针对中国容器开发者和企业用户的调研。近 100 个受访用户和企业中给我们带来了关于 Kubernetes 在中国落地状况的一手调查资料显示: – 在容器编排工具中,Kubernetes占据了70%市场份额,此外是Mesos约11%,Swarm不足7%; – 在中国受访企业用户中,Kubernetes 平台上运行的应用类型非常广泛,几乎包括了除hadoop大数据技术栈以外的各种类型应用; – 中国受访企业运行 Kubernetes 的底层环境分布显示,29%的客户使用裸机直接运行容器集群,而在包括OpenStack、VMWare、阿里云和腾讯云在内的泛云平台上运行容器集群服务的客户占到了60%;
关于CNCF基金会
主要的容器技术厂商(包括 Docker、CoreOS、Google、Mesosphere、RedHat 等)成立了 Cloud Native Computing Foundation (CNCF) 。 CNCF对云原生的定义是: – 云原生技术帮助公司和机构在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。 – 这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术可以使开发者轻松地对系统进行频繁并可预测的重大变更。 – 云原生计算基金会(CNCF)致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术。我们通过将最前沿的模式普惠,让这些创新为大众所用。
下图是截止2018.11的CNCF部分云原生项目列表:
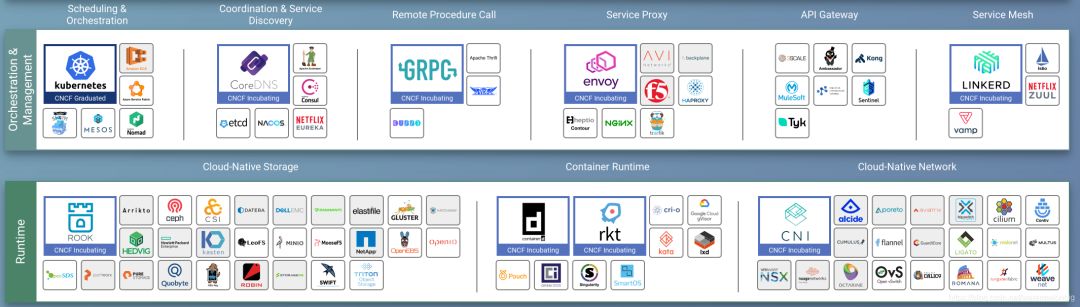
云原生以容器为核心技术,分为运行时(Runtime)和 Orchestration 两层,Runtime 负责容器的计算、存储、网络;Orchestration 负责容器集群的调度、服务发现和资源管理。
注:上图只截取了原图的核心组件部分,完整图表详见https://landscape.cncf.io/images/landscape.png
Kubernetes的核心组件
Kubernetes的核心组件示意图
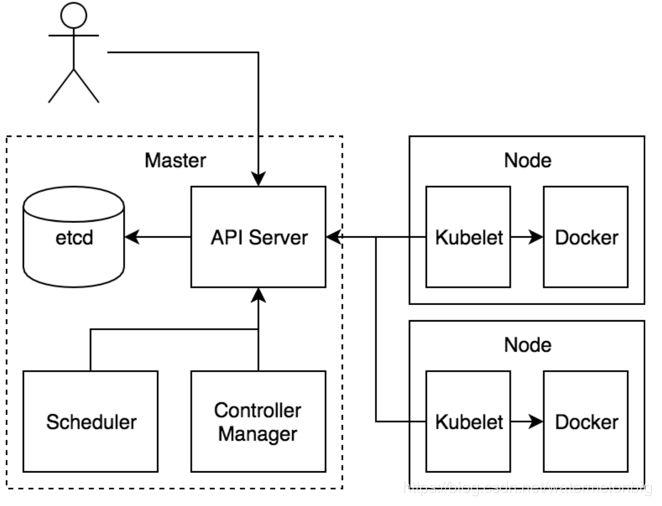
etcd是Kubernetes的存储状态的分布式数据库,采用raft协议作为一致性算法(raft协议原理可参见一个动画演示http://thesecretlivesofdata.com/raft/)。
API Server组件主要提供认证与授权、运行一组准入控制器以及管理API版本等功能,通过REST API向外提供服务,允许各类组件创建、读取、写入、更新和监视资源(Pod, Deployment, Service等)。
Scheduler组件,根据集群资源和状态选择合适的节点用于创建Pod。
Controller Manager组件,实现ReplicaSet的行为。
Kubelet组件,负责监视绑定到其所在节点的一组Pod,并且能实时返回这些Pod的运行状态。
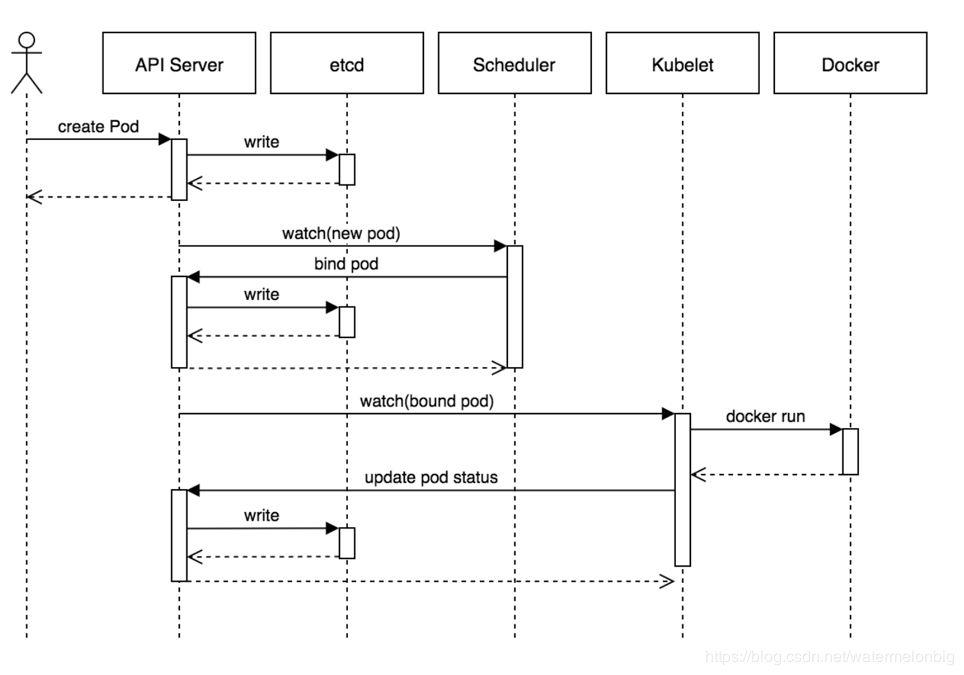
创建Pod的整个流程时序图
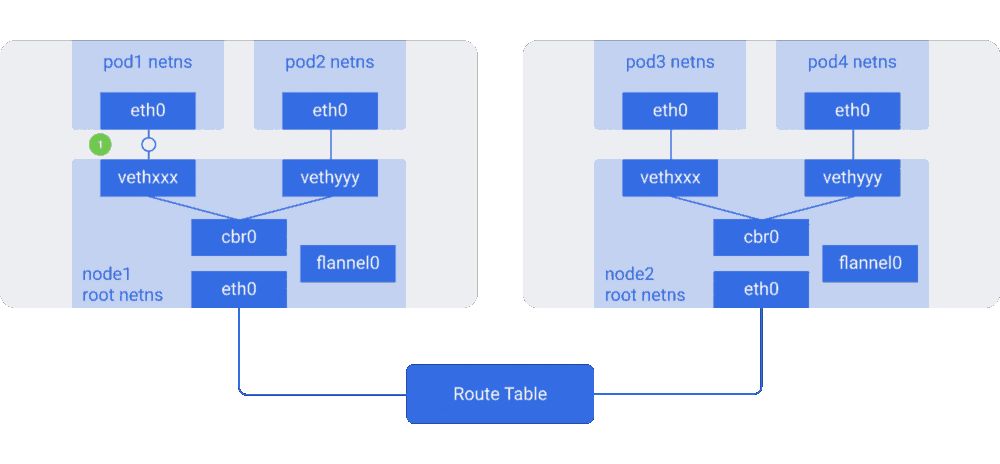
容器网络
容器的大规模使用,也对网络提供了更高的要求。网络的不灵活也是很多企业的短板,目前也有很多公司和项目在尝试解决这些问题,希望提出容器时代的网络方案。 Docker采用插件化的网络模式,默认提供bridge、host、none、overlay、macvlan和Network plugins这几种网络模式,运行容器时可以通过–network参数设置具体使用那一种模式。
– bridge:这是Docker默认的网络驱动,此模式会为每一个容器分配Network Namespace和设置IP等,并将容器连接到一个虚拟网桥上。如果未指定网络驱动,这默认使用此驱动。 – host:此网络驱动直接使用宿主机的网络。
– none:此驱动不构造网络环境。采用了none 网络驱动,那么就只能使用loopback网络设备,容器只能使用127.0.0.1的本机网络。
– overlay:此网络驱动可以使多个Docker daemons连接在一起,并能够使用swarm服务之间进行通讯。也可以使用overlay网络进行swarm服务和容器之间、容器之间进行通讯,
– Network plugins:可以安装和使用第三方的网络插件。可以在Docker Store或第三方供应商处获取这些插件。
在默认情况,Docker使用bridge网络模式。
容器网络模型(CNM)
容器网络接口(CNI)
CNI诞生于2015年4月,由CoreOS公司推出,CNI是容器中的网络系统插件,它使得类似Kubernetes之类的管理平台更容易的支持IPAM、SDN或者其它网络方案。CNI实现的基本思想为:Contianer runtime在创建容器时,先创建好network namespace,这在实际操作过程中,首先创建出来的容器是Pause容器。之后调用CNI插件为这个netns配置网络,最后在启动容器内的进程。
CNI Plugin负责为容器配置网络,包括两个基本接口: – 配置网络:AddNetwork(net NetworkConfig, rt RuntimeConf) (types.Result, error) – 清理网络:DelNetwork(net NetworkConfig, rt RuntimeConf) error
每个CNI插件只需实现两种基本操作:创建网络的ADD操作,和删除网络的DEL操作(以及一个可选的VERSION查看版本操作)。所以CNI的实现确实非常简单,把复杂的逻辑交给具体的Network Plugin实现。
Kubernetes CNI 插件

Calico:一个纯三层的网络解决方案,使用 BGP 协议进行路由,可以集成到 openstack 和 docker。Calico节点组网可以直接利用数据中心的网络结构(无论是L2或者L3),不需要额外的NAT,隧道或者Overlay Network,网络通信性能好。Calico基于iptables还提供了丰富而灵活的网络Policy,保证通过各个节点上的ACLs来提供Workload的多租户隔离、安全组以及其他可达性限制等功能。如果企业生产环境可以开启BGP协议,可以考虑calico bgp方案。不过在现实中的网络并不总是支持BGP路由的,因此Calico也设计了一种IPIP模式,使用Overlay的方式来传输数据。
Weave Net:weaveworks 给出的网络的方案,使用 vxlan 技术通过Overlay网络实现的, 支持网络的隔离和安全,安装和使用都比较简单。
Contiv: 思科开源,兼容CNI模型以及CNM模型,支持 VXLAN 和 VLAN 方案,配置较复杂。支持Tenant,支持租户隔离,支持多种网络模式(L2、L3、overlay、cisco sdn solution)。Contiv带来的方便是用户可以根据容器实例IP直接进行访问。
Canal:基于 Flannel 和 Calico 提供 Kubernetes Pod 之间网络防火墙的项目。
Cilium:利用 Linux 原生技术提供的网络方案,支持 L7 和 L3、L4 层的访问策略。
Romana:Panic Networks 推出的网络开源方案,基于 L3 实现的网络连通,因此没有 Overlay 网络带来的性能损耗,但是只能通过 IP 网段规划来实现租户划分。
从理论上说,这些CNI工具的网络速度应该可以分为3个速度等级。 最快的是Romana、Gateway模式的Flannel、BGP模式的Calico。 次一级的是IPIP模式的Calico、Swarm的Overlay网络、VxLan模式的Flannel、Fastpath模式的Weave。 * 最慢的是UDP模式的Flannel、Sleeve模式的Weave。
Flannel
UDP封包使用了Flannel自定义的一种包头协议,数据是在Linux的用户态进行封包和解包的,因此当数据进入主机后,需要经历两次内核态到用户态的转换。网络通信效率低且存在不可靠的因素。
VxLAN封包采用的是内置在Linux内核里的标准协议,因此虽然它的封包结构比UDP模式复杂,但由于所有数据装、解包过程均在内核中完成,实际的传输速度要比UDP模式快许多。Vxlan方案在做大规模应用时复杂度会提升,故障定位分析复杂。
Flannel的Gateway模式与Calico速度相当,甚至理论上还要快一点。Flannel的Host-Gateway模式,在这种模式下,Flannel通过在各个节点上的Agent进程,将容器网络的路由信息刷到主机的路由表上,这样一来所有的主机就都有整个容器网络的路由数据了。Host-Gateway的方式没有引入像Overlay中的额外装包解包操作,完全是普通的网络路由机制,它的效率与虚拟机直接的通信相差无几。Host-Gateway的模式就只能用于二层直接可达的网络,由于广播风暴的问题,这种网络通常是比较小规模的。路由网络对现有网络设备影响比较大,路由器的路由表有空间限制,一般是两三万条,而容器的大部分应用场景是运行微服务,数量集很大。
Flannel网络通信原理示意图
各CNI网络插件的功能对比:
容器存储
因为容器存活时间很短的特点,容器的状态(存储的数据)必须独立于容器的生命周期,也因为此,容器的存储变得非常重要。 – Ceph:分布式存储系统,同时支持块存储、文件存储和对象存储,发展时间很久,稳定性也得到了验证。之前在 OpenStack 社区被广泛使用,目前在容器社区也是很好的选项。 – GlusterFS:RedHat 旗下的产品,部署简单,扩展性强。 – 商业存储:DELL EMC,NetApp等 – CSI(Container Storage Interface):定义云应用调度平台和各种存储服务接口的项目,核心的目标就是存储 provider 只需要编写一个 driver,就能集成到任何的容器平台上。 – Rook:基于 Ceph 作为后台存储技术,深度集成到 Kubernetes 容器平台的容器项目,因为选择了 Ceph 和 Kubernetes 这两个都很热门的技术,并且提供自动部署、管理、扩展、升级、迁移、灾备和监控等功能
Kubernetes支持的存储类型
awsElasticBlockStore
azureDisk
azureFile
cephfs
configMap
csi
downwardAPI
emptyDir
fc (fibre channel)
flocker
gcePersistentDisk
gitRepo (deprecated)
glusterfs
hostPath
iscsi
local
nfs
persistentVolumeClaim
projected
portworxVolume
quobyte
rbd
scaleIO
secret
storageos
vsphereVolume
Kubernetes以in-tree plugin的形式来对接不同的存储系统,满足用户可以根据自己业务的需要使用这些插件给容器提供存储服务。同时兼容用户使用FlexVolume和CSI定制化插件。
一般来说,Kubernetes中Pod通过如下三种方式来访问存储资源: – 直接访问 – 静态provision – 动态provision(使用StorageClass动态创建PV)
服务发现
容器和微服务的结合创造了另外的热潮,也让服务发现成功了热门名词。可以轻松扩展微服务的同时,也要有工具来实现服务之间相互发现的需求。 DNS 服务器监视着创建新 Service 的 Kubernetes API,从而为每一个 Service 创建一组 DNS 记录。 如果整个集群的 DNS 一直被启用,那么所有的 Pod应该能够自动对 Service 进行名称解析。在技术实现上是通过kubernetes api监视Service资源的变化,并根据Service的信息生成DNS记录写入到etcd中。dns为集群中的Pod提供DNS查询服务,而DNS记录则从etcd中读取。 – kube-dns:kube-dns是Kubernetes中的一个内置插件,目前作为一个独立的开源项目维护。Kubernetes DNS pod 中包括 3 个容器:kube-dns,sidecar,dnsmasq – CoreDNS:CoreDNS是一套灵活且可扩展的权威DNS服务器,作为CNCF中的托管的一个项目,自k8s 1.11 版本起被正式作为集群DNS附加选项,且在用户使用kubeadm时默认生效。提供更好的可靠性、灵活性和安全性,可以选择使用CoreDNS替换Kubernetes插件kube-dns。
状态数据存储
目前主要有三种工具,大部分的容器管理系统也都是同时可以支持这三种工具。 – etcd:CoreOS 开源的分布式 key-value 存储,通过 HTTP/HTTPS 协议提供服务。etcd 只是一个 key-value 存储,默认不支持服务发现,需要三方工具来集成。kubernetes 默认使用 etcd 作为存储。 – ZooKeeper:Hadoop 的一个子项目,本来是作为 Hadoop 集群管理的数据存储,目前也被应用到容器领域,开发语言是 Java。 – Consul:HashiCorp 开发的分布式服务发现和配置管理工具
这些工具的主要作用就是保证这个集群的动态信息能统一保存,并保证一致性,这样每个节点和容器就能正确地获取到集群当前的信息。
健康检查
Kubernetes提供两种类型的健康检查,支持进行三种类型的探测:HTTP、Command和TCP。 – Readiness探针旨在让Kubernetes知道您的应用何时准备好其流量服务。 Kubernetes确保Readiness探针检测通过,然后允许服务将流量发送到Pod。 如果Readiness探针开始失败,Kubernetes将停止向该容器发送流量,直到它通过。 – Liveness探针让Kubernetes知道你的应用程序是活着还是死了。 如果你的应用程序还活着,那么Kubernetes就不管它了。 如果你的应用程序已经死了,Kubernetes将删除Pod并启动一个新的替换它。
容器监控
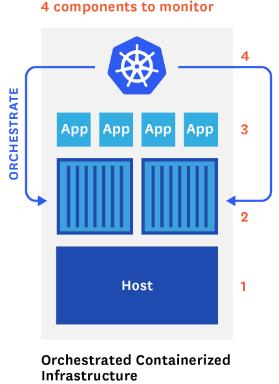
我们习惯于在两个层次监控:应用以及运行它们的主机。现在由于容器处在中间层,以及 Kubernetes 本身也需要监控,因此有 4 个不同的组件需要监控并且搜集度量信息。
1)cAdvisor + InfluxDB + Grafana:一个简单的跨多主机的监控系统Cadvisor:将数据,写入InfluxDBInfluxDB :时序数据库,提供数据的存储,存储在指定的目录下Grafana :提供了WEB控制台,自定义查询指标,从InfluxDB查询数据,并展示。
2)Heapster + InfluxDB + Grafana:Heapster是一个收集者,将每个Node上的cAdvisor的数据进行汇总,然后导到InfluxDB,支持从Cluster、Node、Pod的各个层面提供详细的资源使用情况。Heapster:在Kubernetes集群中获取Metrics和事件数据,写入InfluxDB,Heapster收集的数据比cAdvisor多,而且存储在InfluxDB的也少。InfluxDB:时序数据库,提供数据的存储,存储在指定的目录下。Grafana:提供了WEB控制台,自定义查询指标,从InfluxDB查询数据,并展示。
3)Prometheus+Grafana:Prometheus是个集DB、Graph、Statistics、Alert 于一体的监控工具。提供多维数据模型(时序列数据由metric名和一组key/value组成)和在多维度上灵活的查询语言(PromQl),提供了很高的写入和查询性能。对内存占用量大,不依赖分布式存储,单主节点工作,所以不具有高可用性,支持pull/push两种时序数据采集方式。
考虑到Prometheus在扩展性和高可用方面的缺点,在超大规模应用时可以考察下thanos这样的面向解决Prometheus的长时间数据存储与服务高可用解决方案的开源项目:https://github.com/improbable-eng/thanos
容器集群的四个监控层次
镜像 registry
镜像 registry 是存储镜像的地方,可以方便地在团队、公司或者世界各地分享容器镜像,也是运行容器最基本的基础设施。 – Docker Registry:Docker 公司提供的开源镜像服务器,也是目前最流行的自建 registry 的方案 – Harbor:企业级的镜像 registry,提供了权限控制和图形界面
每种对应技术几乎都有自己的基础镜像,例如: – https://hub.docker.com/_/java/ (该镜像仍存在,但已经很长时间未更新) – https://hub.docker.com/_/python/ – https://hub.docker.com/_/nginx/ – https://hub.docker.com/_/alpine/ 一个常用的基础镜像Alpine Linux(体积小于5MB)
参考资料
中国开源云联盟容器工作组-容器技术及其应用白皮书v1.0 从风口浪尖到十字路口,写在 Kubernetes 两周年之际 白话Kubernetes网络 http://dockone.io/article/2616Kubernetes 主机和容器的监控方案 http://dockone.io/article/2602CNCF 云原生容器生态系统概要 http://dockone.io/article/3006Kubernetes 存储系统介绍及机制实现 http://dockone.io/article/3063Kubernetes 内部组件工作原理介绍 http://dockone.io/article/5108Docker、Containerd、RunC…:你应该知道的所有 https://www.infoq.cn/article/2017%2F02%2FDocker-Containerd-RunC 从 docker 到 runC https://www.cnblogs.com/sparkdev/p/9129334.html
文章由高庆投稿,百悟科技 高级运维工程师
推荐阅读
以上是关于容器容器云与Kubernetes技术漫谈的主要内容,如果未能解决你的问题,请参考以下文章