知乎基于Kubernetes的kafka平台的设计和实现
Posted 高可用架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知乎基于Kubernetes的kafka平台的设计和实现相关的知识,希望对你有一定的参考价值。
我是知乎技术中台工程师,负责知乎存储相关的组件。我的分享主要基于三个,第一,简单介绍一下Kafka在知乎的应用,第二,为什么做基于Kubernetes的Kafka平台。第三,我们如何去实现基于Kubernetes的kafka平台。
Kafka在知乎的应用
Kafka是一个非常优秀的消息或者数据流的组件,在知乎承载了日志、数据收集、消息队列等服务,包括运行的DEBUG日志关键性日志。比如我们在浏览知乎的时候,有些用户行为或者内容特征,会通过我们这个平台做数据的流失处理。
关于Kafka实现对消息服务。简单地来说,我关注的A用户,是不是应该基于关注用户行为上做很多事情,而是应该关注更多的消息队列。我们平台现在部署有超过有40个Kafka集群,这些集群都是独立的。另外集群内部有超过一千个topic,我们有接近两千的Broker数量。
平台从上线到现在已经运行接近两年,承载的数据量都是百TB级别。对于公司内部的平台来说,我们必须要保证高可用。平台架构底层是Broker管理,而上层是抽象出来的。关于平台管理,创建topic、创建分区,或做故障处理。集群对业务对来说,必须是无感状态。
为什么采用Kubernetes?
在早期的时候,知乎的Kafka只是一个单集群,在大家使用率不高,数据量增长不爆炸的时候,单集群还OK,但是有天发现有一个Broker挂了,所有业务同时爆炸,这时候才发现其实是一条路走下去是不行的。因为不管是业务也好,日志也好,发消息也罢,都会依赖我们这个单一的集群。对于Kafka来,我们开发中有一个的Top的概念,每个topic都代表了不同的业务的场景,因此我们业务场景在内部要做分级,不重要的数据及重要的数据,我们如何做拆分。另外一方面,我们的业务怎么能于Kafka做深度耦合?我们发现,我们的日志里topic有很多类型,第一种是日志,剩下的是数据和消息。为此我们需要把Kafka集群在内部要做成多集群的方式,从而根据我们top做出划分。

比如一个A业务,每天有上百几十T的数据,是不是可以申请一个新的Broker,新的集群,别的数据并不会和新的数据搀和到一起,那这样就会遇到一个问题,服务器资源怎么去使用?如何去分配?早期部署的时候肯定单机部署,暂定我用一台服务器,一台服务器暂定4T容量,这样部署一个消息任务是不是有点浪费?如何提升资源利用率,如歌从单机上部署更多的Broker,如何将影响降到最低?在实践过程中,磁盘其实是Kafka一个绕不开的问题。
另一个问题是磁盘持久化的问题,在磁盘写入量剧增的情况下,我们如何去处理磁盘也是一个非常大的难题。既然Broker可以做到不影响,那么我们在物理层面是否可以将磁盘分开?接下来就是服务器部署问题了,我们采用了腾讯云的黑石服务器,提供12个单磁盘接口,对管理这块是我们非常好的!
底层服务器搞定了,接下来是上层服务,这块该怎么做呢?知乎前期是自研了一个Kafka管理平台,但是非常难用,新同事来了都需要从代码方面开始了解,所以我们决定使用Kubernetes。
Kafka on Kubernetes
首先解决问题设计Kafka容器,无非就是四个问题——内存,CPU,网络和存储。另外一个问题是我们怎么实现具体调度Kafka容器。

CPU是比较难以预估的,因为根据资讯类型不同,对于内存和CPU消耗是不同的,Kafka本身是不依赖于CPU。但是在实际使用中还是有些问题的,比如Kafka不适合做批量,假如延迟很高,如何保证每一条消息都确切的投放过去,难道是把Brokers收得很小?这时候会造成一个什么问题?CPU会高,但是很这种问题我们可以通过调高CPU来解决。如果不出现这种大流量的话,一般内存是不会超过八个G的。
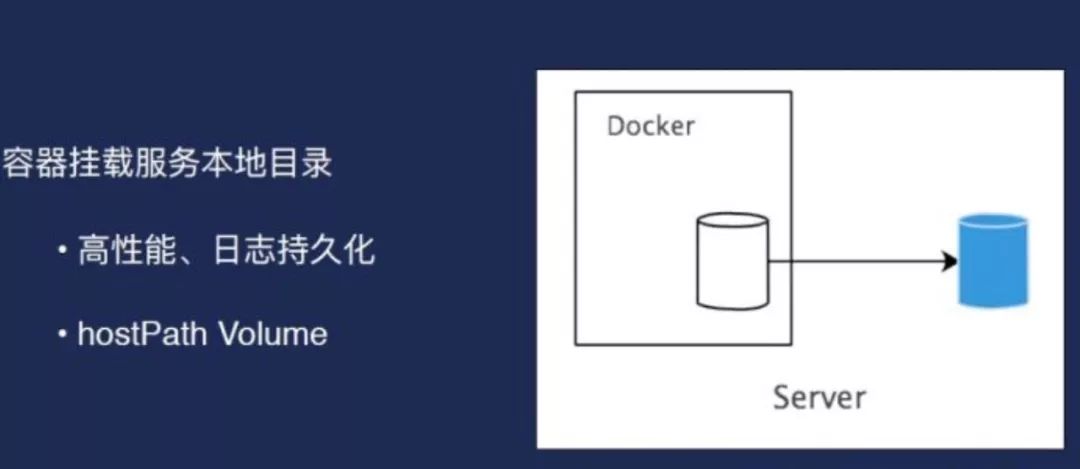
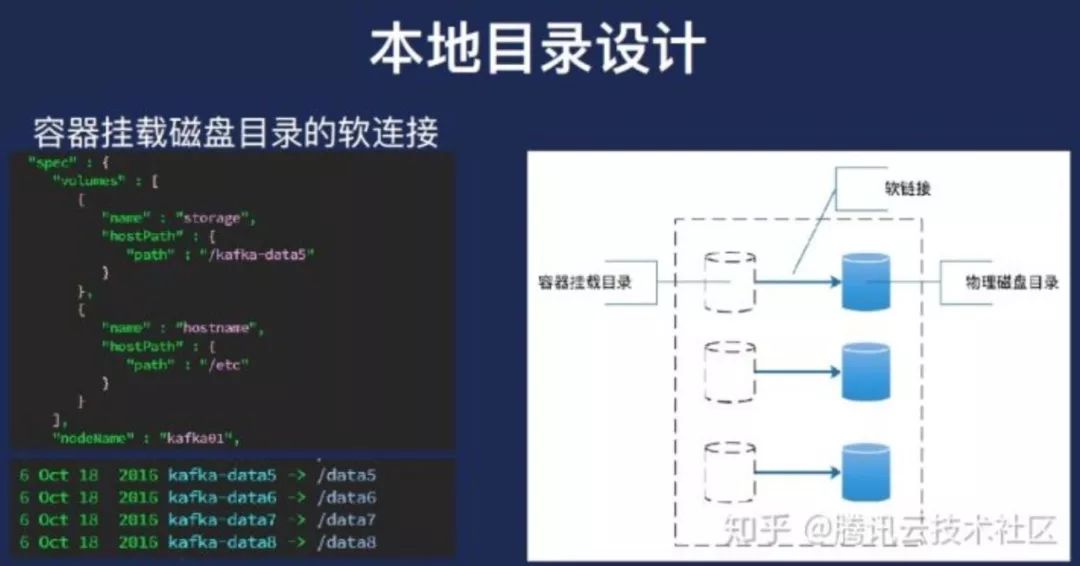
另外网络方面就是我们对外服务,采用的是一种独立的内网ip方式,比如我每一个Broker都有一个独立的ip,实际上因为我们的单机上会部署很多容器,所以每个都有IP,并且将这个ip注册在内网DNS上面,这样照好处是对于使用者来说,不需要知道具体容器的ip。这个是网络又有一个很好的方式——可以做单机的多ip网络设计,至少可以满足我们的需求,这是容器方面的设计。默认支持的磁盘的挂载方式是HostParh Volume,这种方式是最优的,因为Kafka在本地磁盘性能最好的,而且能够充分利用到本地的这种高效的文件缓存,我们本身的磁盘性能也是非常棒的,至少我可以满足我的需求。
因此我们就应该是本地的目录一个cosplay,也就到K2起来之后是给他的,请求的配置挂载到服务器的磁盘,黑色框是我们的一个容器,开发目录指向的蓝色框是服务器上的一个磁盘或者服务器上的目录。虽然我们的集群看来就是这个样子的,每一个方块代表网上有很多的部署的Broker。业务上面可以反过来看,每个蓝色的地方代表Broker。
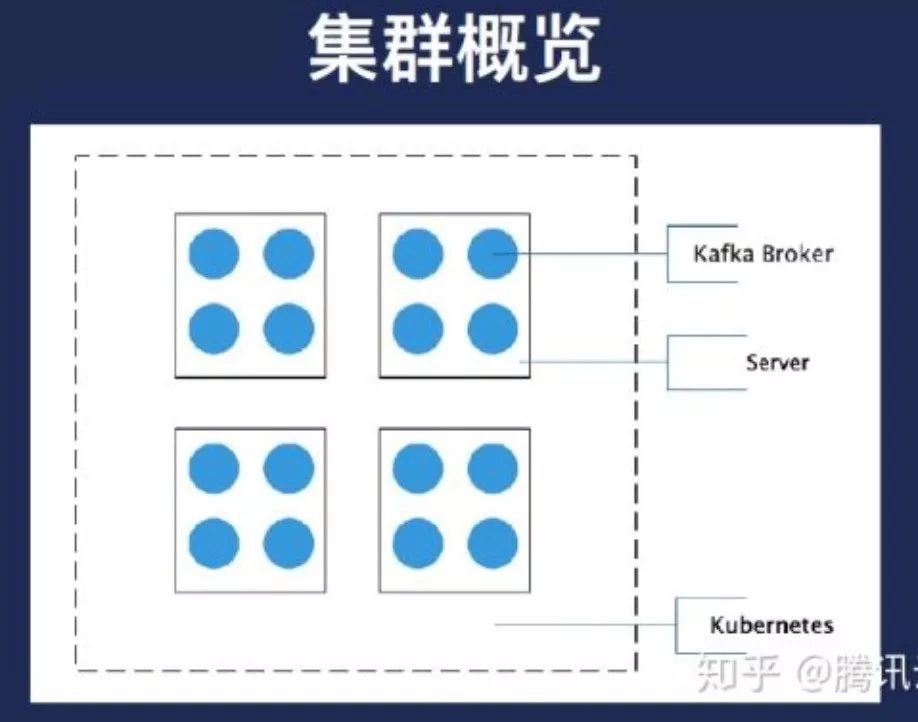
第一,CPU和内存并不是问题,网络其实已过测试过的,服务器网络是二世纪的20G带宽,每个盘我们经过测试,是有一点几个G性能,即便把每个盘所有人都跑满,其实这是灾难情况,他只有不会超过20个G,因此我们不在考虑范围之内,我们考虑的是磁盘的高可用目标,让单个集群的Broker在节点要尽量做到分散。
第二是节点上的存储使用尽量均匀。
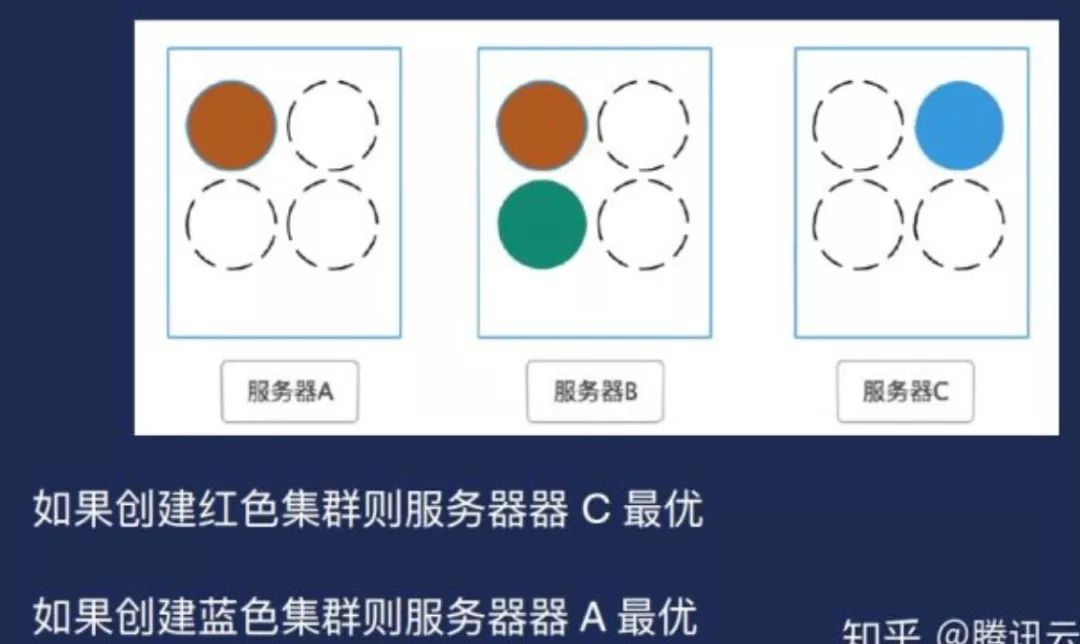
算法是根据服务器磁盘状态计算分数,分数高者被调度。另外就是磁盘的使用情况,如果有更多的可用盘,我们倾向于把Broker挂在了上面。其实它用了一个简单的方式,假设创建一个红色集群,实际上A和C都可以,但C是最优的,因为C上面的Broker数比较少。如果要创建一个蓝色集群,那显然是A是最优的。另外,在实际使用情况下要更复杂,因为得考虑到分片的高可用。按照算法去实现会遇到了一个实际性的问题——用HostPat是有很大局限性,一致性不好,比如需要去管理要调度的节点,因为如果用class的话需要去注册一个本身选择的word,或者其实我是不知道被调到哪个节点上。另外主机上要去挂载的目录其实是没有人管理的。这是我们遇到的问题,当时我们希望是既要利用到HostPath,只有挂在本地的磁盘这种特性来提高我们的性能管理。
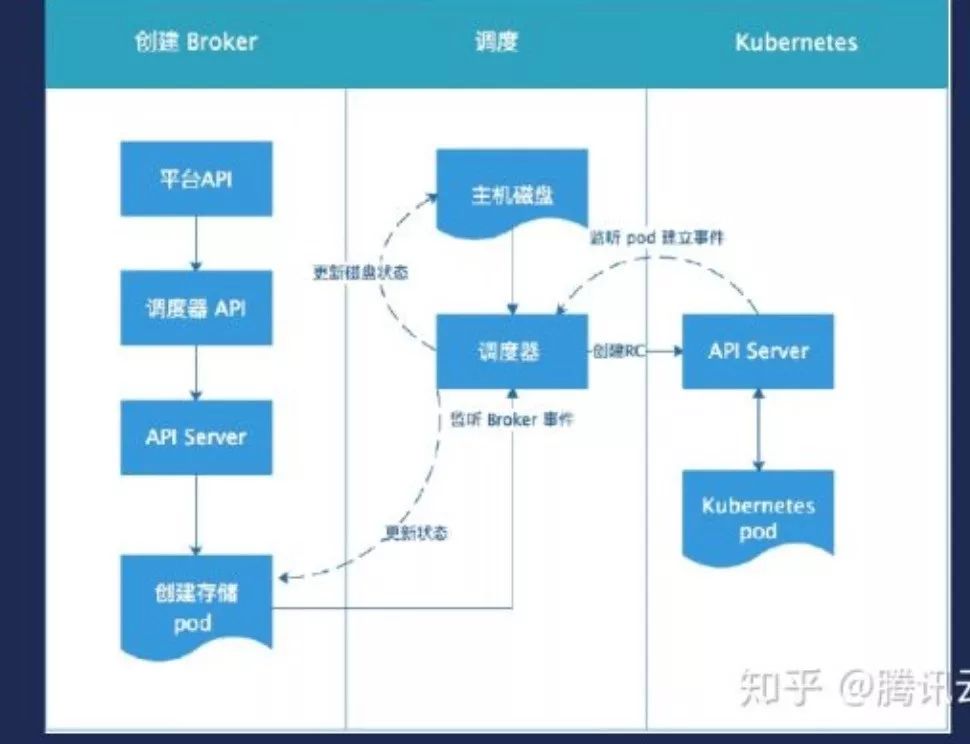
而且我要能够选出合理节点,并且能够管理到这个存储。因此我们在当时对Kubernetes做改造,实现磁盘和调度器的算法,可以实现实时更新磁盘信息。但是实现方式是通过假设创建实例.
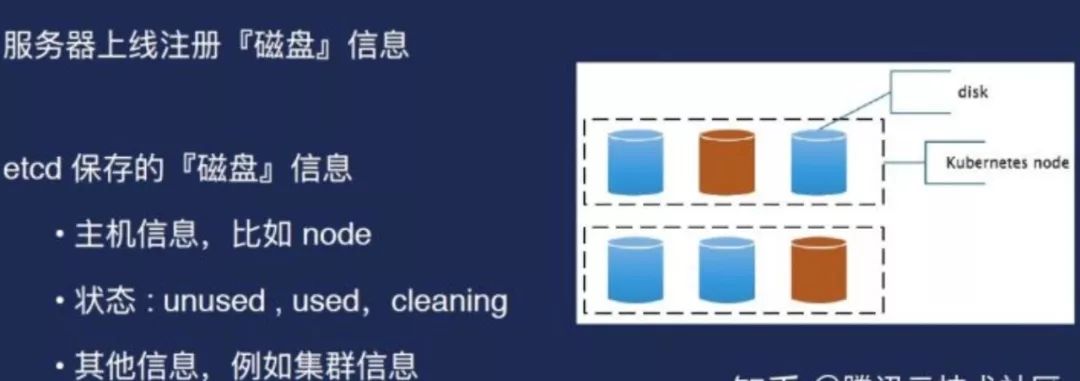
本地磁盘管理
如果Broker已经在设备上建立起来,磁盘也被用了,那如何去管理它?事实上磁盘管理只能进入第三方的Agent。

故障处理和提升资源利用时会预留空间,比如为了快速处理故障不做签署,首先就是成本太高,现在做的是快速恢复,因此我们会预留1到2个盘,即快速处理盘,因此只要把软件指向这个容器,就可以马上启用,并且不会有太大的网络开销。另外就是在主机层面,即把分片在主机层面是做分开,做到高可用。
但我们遇到一个问题——需要把客户端统一,因为技术平台化。那如何把客户端做到统一?我们的看这里,客户端可以去读Consul信息,检查topic是不是有用。还有个好处是,如果做迁移的时候,因为事情使了很多方,生产和消费方式是很多的,而且一般流程是先于生产方,消费方就过来,大家可能有业务,可能大家如果按照这种注册方式的话,其实迁移过程是可以同步的。在这个地方更改信息,整个这个生产所生产的消费,都可以感受到,就是另外就是易用性会提高。且用这种方式有好处是有一个集群比如我整个集群全部断掉了,虽然事没发生过,但是作为一个备用的方式的话,我们会有一个灾备集群把所有的客户端都可以直接迁移过去。
了解更多详情,请戳下面的链接:
[1] 知乎基于Kubernetes的Kafka平台的设计和实现.pdf http://link.zhihu.com/?target=https%3A//ask.qcloudimg.com/draft/1184429/vz545uds4s.pdf
相关阅读
高可用架构
改变互联网的构建方式
以上是关于知乎基于Kubernetes的kafka平台的设计和实现的主要内容,如果未能解决你的问题,请参考以下文章