达达基于Kubernetes混部的日志系统演变
Posted 达达京东到家技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了达达基于Kubernetes混部的日志系统演变相关的知识,希望对你有一定的参考价值。
作者简介:彭星星,达达云平台SRE工程师,负责达达OpenResty与日志系统开发。
本文主要分享达达是如何通过Kubernetes混部构建一个日峰值处理超过130亿条日志,单日存储超过14TB,总存储量300TB的日志系统。

1
背景
在2016年达达与京东到家合并后线上业务迅速发展。面对海量日志增长和日志查询需求,基于ELK架构的日志系统已经不能满足达达的线上场景,迫切需要一个高效自动化的日志系统。本文主要分享达达是如何通过Kubernetes混部构建一个日峰值处理超过130亿条日志,单日存储超过14TB,总存储量300TB的日志系统。
2
历史包袱
达达最早也是使用ELK构建第一版日志系统,当时被研发吐槽最多的是『 kibana怎么查不到我想要的数据』『日志延时怎么这么久』。经过仔细梳理分析后,我们发现当时的日志系统主要存在以下三个问题:
日志采集无法自动化
日志无格式化解析
Elasticsearch 存储混乱
日志采集无法自动化
每当新增一个日志接入需求,研发要和运维反复沟通,再由运维修改Flume采集配置。每次变更都需要繁琐的手工操作,且执行过程中很容出现问题。
此外在服务扩容经常时会遗落添加Flume采集配置,导致部分日志采集丢失,直接影响业务数据统计准确性。所以,自动化的采集日志是实现高效日志系统的基础。
日志无格式化解析
当时采用的是如下图展示的经典ELK日志系统架构 Flume采集 --> Kafka集群 --> Logstash解析 --> ElasticSearch存储 --> Kibana查询展示。
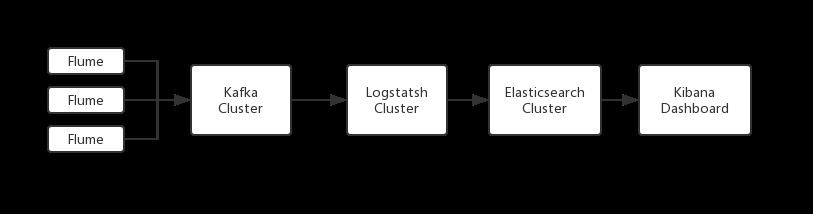
利用 Logstash 的 grok 插件解析所有类型日志,这样的日志解析方式在面对一定数量级的日志时效率非常低。当时Logstash已经成为达达日志系统的瓶颈,如何高效解析日志是实现高效日志系统的核心。
Elasticsearch 存储混乱
Elasticsearch 集群采用的粗放式的管理,在Kibana配置了将近600多个查询索引,每个索引的用途没有人说得清楚,另外模板都是由 Elasticsearch 自动生成,存储嵌套JSON的日志经常会出现大量的类型冲突异常,导致数据无法存储;进而导致研发无法方便的使用Kibana查询日志内容。因此,精细化管理 Elasticsearch 集群是实现高效日志系统的关键。
3
系统演进
如何解决上面提到的三个问题呢?我们的思路是:相同类型的日志尽可能使用一个解析规则、以天为单位使用一个 Elasticsearch 索引存储,最终通过不同的Tag来区分不用应用日志,假如日志量非常大或者业务方明确提出单独存储需求,再拆分成不同的 kafka topic以及 Elasticsearch 存储索引。
日志采集自动化
自动化的前提是标准化。首先在公司内推行日志标准化,确保所有服务的日志的命名以及内容格式统一。比如针对Java服务,所有相同类型的日志文件名都有固定的路径和命名格式:
/path/to/project/$(appName)_info.log
/path/to/project/$(appNmae)_error.log
/path/to/project/$(appName)_access.log
/path/to/project/topic_$(nameOfTopic).log
我们使用Filebeat替换了配置繁琐且资源占用多的Flume,针对达达的应用场景做了二次开发。比如根据文件名添相应的Tag信息,对于不同的采集需求发送到不同 kafka topic。所有这一切都是自动化,只要按照日志标准化的约定打印日志,可以做到无人值守的自动采集。
Filebeat相对Flume具有采集效率高、资源占用低、稳定性高同时配置管理非常灵活的优点,利用Filebea实现了绝大部分的日志自动化采集场景,彻底解放了在日志采集上的人力投入。
日志格式化解析
在原有架构中,Logstash集群已无法满足所有日志Kafka Topic的消费解析和管理。需要引入新的技术栈才能解决遇到大规模日志流计算解析,经过调研分析,我们最终决定采用Java技术栈的Strom来开发日志解析模块。
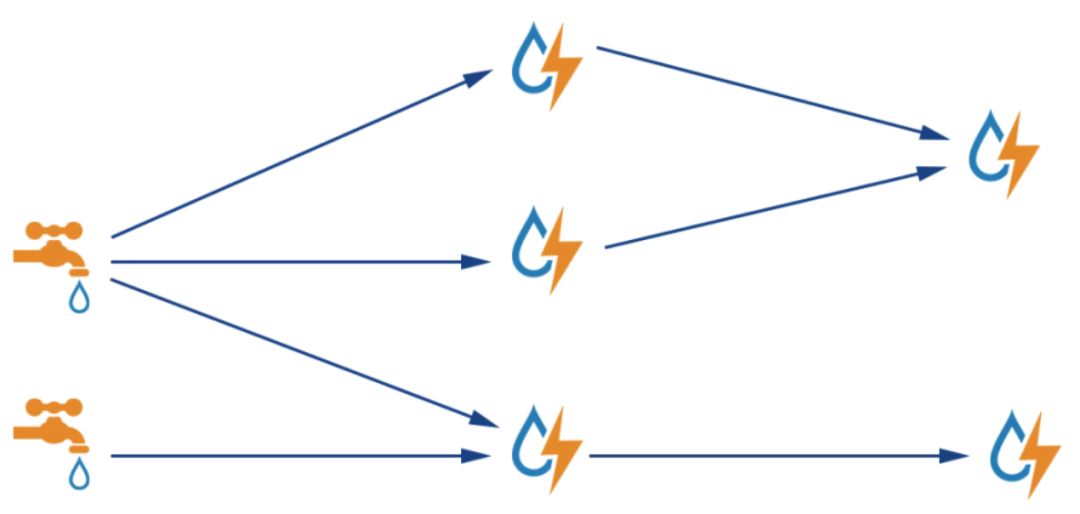
在Storm的topology中有两种组件:spout和bolt。spout代表输入的数据源,Storm从这个spout中不断地读取数据,然后发送到下游的bolt中进行处理。bolt收到消息之后,对消息做处理,处理完以后可以直接结束,或者将处理后的消息继续发送到下游的bolt,形成一个处理流水线。下图就是一个非常典型的Storm结构图,图中的水龙头就被称作spout,闪电被称作bolt。
日志解析的核心是 logParserBolt,它的主要功能是针对不同的日志信息采用不同的解析逻辑。简单来说 Filebeat采集的日志被 kafkaSpout 包装成 Map<source, logText> 对象,经过 logParserBolt 处理后转变成另外一个 Map<esIndex, logJson>对象。其中logJson就是原始日志内容 logText 经过解析规则处理之后的格式化信息,esIndex就是最终日志存储的索引名称。
比如一个名叫bill的服务,至少会存在以下3个日志:
bill_info.log
bill_error.log
bill_access.log
经过Filebeat采集后,info和error日志被带上了source: appLog的tag,而access日志被带上了source: access的tag。
这样info日志和error日志会被同一个parser函数处理,最终存入applog的索引,而access日志被另外一个parser函数处理,最终存入accesslog索引。
最初针对每个日志kafka topic都单独创建一个Storm toplogy,包含了独立的 kafkaSpout、日志解析logParserBolt、日志存储 sendESBolt 的逻辑。然而上线之后发现Storm浪费服务器资源的现象。
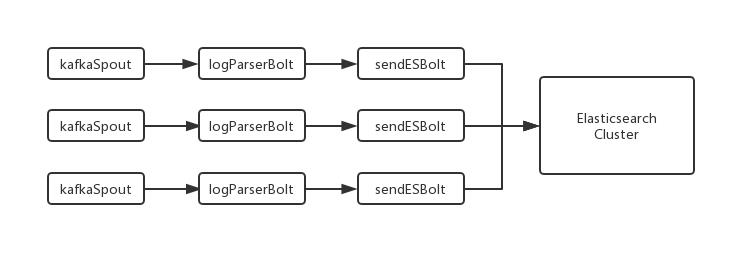
有些日志量很少,一天不过几万条记录,却独占一个Storm toplogy资源大部分时间基本空置,有些日志量却非常大,一个toplogy资源可能还不足够。
为尽可能提高资源利用率,我们根据日志的属性划分成不同的topology, 由 kafkaSpout 同时消费多个 kafka topic,在logParserBolt中维护一个Map<source, logParserFunc>,根据当前日志消息的source决定叠加解析方法,比如JSONParser、正则Parser。
最后所有经过解析后的日志信息统一流转给 sendESBolt 写入 Elasticsearch 集群。可以在控制平台就可以很便捷地完成所有的日志的消费配置信息修改。下图就是最终基于Storm的日志解析系统架构。
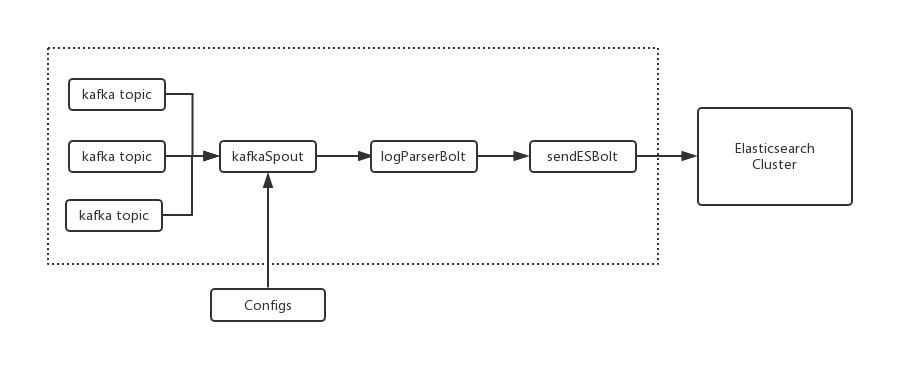
经过上述系统改造,使用Storm开发的日志解析模块,相比Logstash的方式,不但提高了日志解析效率同时降低了维护成本。
由 3台 8C16G配置的服务器构成的Storm解析集群,轻松解决之前12台8C8GLogstash的都无法完成工作。在2019年的双十一,Storm集群水平扩展到20台,完成单日130亿条日志的解析工作。
Elasticsearch索引管理
每种类型的日志在处理的过程中,都按照业务方的要求或者通过格式解析,并存储到Elasticsearch。相同类型的日志落到相同的索引中,通过不同Tag搜索查询。
目前日均新增索引120个,总日志索引量维持300个左右。确保每个日志索引都有固定的映射模板。当前日志系统在日常的问题排查中发挥了重要的作用。以下就是在我们稳定性群经常看到的日志搜索截图。
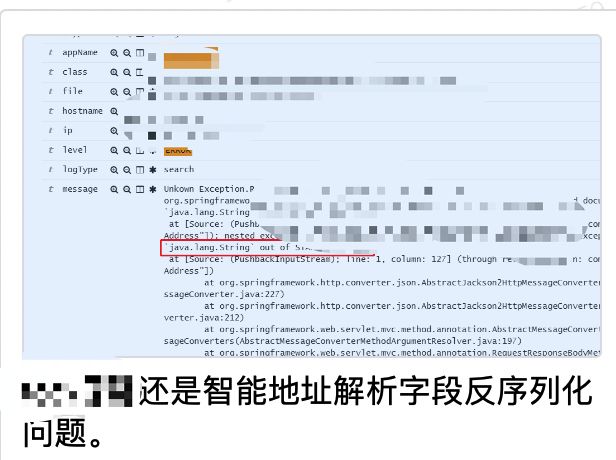
4
Elasticsearch On Kubernetes
目前达达的Elasticsearch的集群由最初的5个节点逐步演变成15个热节点和5个冷节点。目前一共有15台热节点机器(配置是32C 64G 3T SSD盘) 5台冷节点机器(配置32C 96G 48T SATA盘)组成,总集群容量300T每天新增7T存储。
热节点机器主要承担实时日志写入以及最近3天日志的日志搜索查询,对于查询频次较低的3天以前的日志则全部迁移到冷节点。
冷热节点共存的方式运行一段时间后,我们发现冷节点的CPU利用率一直非常低,只在数据迁移以及数据查询时有磁盘IO的开销,其他时间段内几乎都是处于闲置状态。
我们决定使用基于Kubernetes部署Elasticsearch冷节点,物理机部署热节点的混合部方式,以达到充分利用这些CPU利用率峰值3%左右的冷节点资源。
使用Kubernetes的Statefullset的模式部署冷节点以及Host网络模式来保证Elasticsearch集群的网络互通。为Elasticsearch冷节点固定申请了4核CPU以及56G内存的系统资源,这样剩下28核CPU资源以及40G的内存资源可以部署其他应用。
为充分利用这些计算资源,我们使用Go重构了Java技术栈的日志解析逻辑。目前已经完成所有日志解析的迁移工作,按照当前的使用资源使用量,使用5个Elasticsearch的冷节点计算资源可以替换原来的Storm集群的解析工作。
假如遇到大促等这样日质量暴涨的场景,可以使用公有云服务器扩容Kubernetes的Node资源以满足日志解析需要的计算资源。
下图就是原来的5个冷节点的在使用Kubernetes混部前后的CPU利用率对比图。上方图显示的是冷节点CPU在白天几乎处于闲置状态,只在晚上做日志迁移时才会达到3%左右,而下图是使用Kubernetes混部之后并把日志解析迁移到冷节点上的CPU利用率,白天的CPU利用率峰值可以达到40%左右,CPU利用率提高10倍以上。
5
总结与后续规划
达达日志系统的演变,解决了三个核心的问题:日志自动化采集、高效日志解析以及日志的搜索存储。
引入Filebeat和Storm,替换传统的ELK架构中的Flume和Logstash两个组件,解决了采集和解析的问题。
引入Elasticsearch的冷热节点架构构建了一个满足日志高速写入同时保证了300T的存储空间的集群,同时引入Kubernetes部署冷节点和重构的日志解析逻辑,解决了冷节点的CPU利用率低的问题。
目前达达对于应用日志的搜索查询有着完备的解决方案,但面对日益快速增长nginx日志和应用的访问日志,Elasticsearch存储和分析已经很难满足达达SRE日常以及大时间跨度的分析统计需求。
因此我们正在调研使用ClickHouse替换Elasticsearch来作为另外一种高效的日志分析引擎,尽量挖掘日志以及数据背后隐藏的价值或者问题,以促进达达系统的优化和提升。
以上是关于达达基于Kubernetes混部的日志系统演变的主要内容,如果未能解决你的问题,请参考以下文章