Cephfs 多MDS负载均衡的使用方式
Posted Ceph开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Cephfs 多MDS负载均衡的使用方式相关的知识,希望对你有一定的参考价值。
最近发现不少朋友,对cephfs的使用方式存在误区。很多朋友线上连接数十几万,IOPS压力巨大,依然在跑着单mds。直接导致单mds session耗尽,mds进程down。或者扛不住那么大的IOPS,性能很慢。要知道cephfs的性能是随着mds的数量增加线性增长的,mds越多cephfs性能越好。灵活的让多个mds分担IOPS,连接压力是最佳选择。但是多mds如果配置不好,会导致IO夯住,这就让cephfs更冷门了。我和朋友tiger认为有必要帮助下社区。下面进入正题。
多mds的坑在哪?
cephfs多mds默认是动态负载均衡的,为了负载文件系统请求到多个mds。cephfs会根据每个mds计算一个热点值,热点高的mds缓存中的目录会往热点低的mds迁移,缓存中的目录在迁移的过程中是被锁定的,应用层的IO不能访问正在迁移的目录或文件,会导致部分IO访问中断几秒。于是用户就感觉卡了。
我们怎么才能让多mds之间缓存目录不迁移,或者尽量少的数据迁移呢?有2种方案,两种方案是独立使用的。
一,使用静态负载均衡,我们把业务绑定到mds,每次来业务我们根据mds性能监控报表,把业务绑定到负载低的mds上去,也叫手动负载均衡。操作过程如下:
1. 把业务的根目录pin到mds上。
假设给用户a分配了目录/A ,用户b分配了目录/B,用户c分配了目录/C。那么我们把a用户分配到mds0,把b用户分配到mds1,把c用户分配到mds2。
setfattr -n ceph.dir.pin -v 0 /A
setfattr -n ceph.dir.pin -v 1 /B
setfattr -n ceph.dir.pin -v 2 /C
2. 设置cephfs的mds不迁移
有同学会问,你只pin了/A根目录,那/A目录的子目录/A/AA,/A/AA/AAA,不一样会迁移吗?我们只需要设置cephfs的mds不迁移,就能让子目录不迁移。
打开/etc/ceph/ceph.conf文件配置 mds_bal_min_rebalance=1000
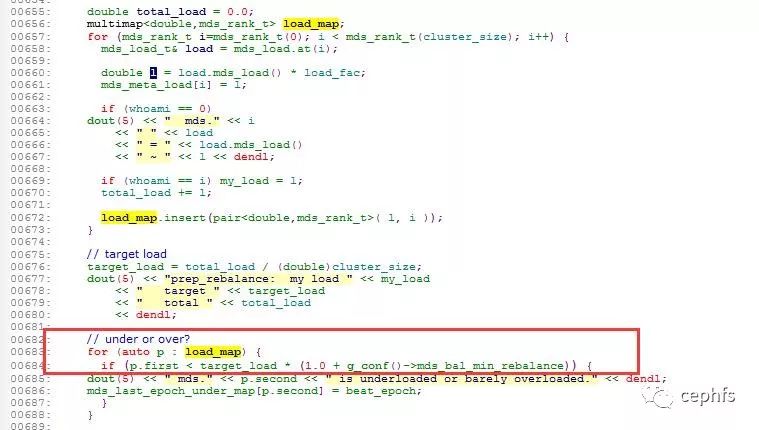
每个mds都会产生一个热点值,这个热点值除以集群的总热点,然后和mds_bal_min_rebalance比较,超过mds_bal_min_rebalance就会迁移,但mds的热点值经过计算后怎么都不会超过1000的,所以只要配置mds_bal_min_rebalance=1000,多MDS之间就不会相互迁移缓存目录(不会产生负载均衡),既然不迁移,子目录就会跟着父母走,/A/AA会跟着父目录/A绑定到mds0上,而/A/AA/AAA会跟着父目录/A/AA绑定到mds0上。所以只要绑定了业务的根目录,并且设置了mds_bal_min_rebalance=1000,用户目录就被固定到了mds上。多个用户可以绑定到同一个mds上。
注意:只要使用这种模式,一定要绑定所有业务到mds上,否则业务会被默认分配到mds0上,造成mds0超载。
二,使用动态负载均衡。
依然采用默认的动态负载均衡,但是把迁移敏感度调小,让多mds之间迁移的粒度变小,而不是一下子迁移整个大目录,导致卡了很长时间。目录迁移的速度变快了,访问目录延迟的时间可以忽略不计。
1. 使多mds之间迁移粒度变小
mds_max_export_size = 209715202. 使mds之间热度的检测频繁变迟钝(根据场景适当调整)
mds_bal_interval = 10
mds_bal_sample_interval = 3.000000
这样既可以使用动态负载,也能避免负载均衡时候数据迁移导致的IO夯死。
总结:两种方案各有优点
1,静态负载均衡用在需要性能稳定的场景。
2,动态负载均衡用在对IOPS需求巨大的场景。一个业务可以跑多个mds。
相关阅读:
Ceph中国社区
是国内唯一官方正式授权的社区,
为广大Ceph爱好者提供交流平台!
开源-创新-自强
官方网站:www.ceph.org.cn
合作邮箱:devin@ceph.org.cn
长期招募热爱翻译人员,
参与社区翻译外文资料工作。
以上是关于Cephfs 多MDS负载均衡的使用方式的主要内容,如果未能解决你的问题,请参考以下文章