高可用篇之Keepalived (HAProxy+keepalived 搭建高可用负载均衡集群)
Posted 洁癖是一只狗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高可用篇之Keepalived (HAProxy+keepalived 搭建高可用负载均衡集群)相关的知识,希望对你有一定的参考价值。
Keepalived是Linux下一个轻量级别的高可用解决方案。健康检查和失败切换是keepalived的两大核心功能。所谓的健康检查,就是采用tcp三次握手,icmp请求,http请求,udp echo请求等方式对负载均衡器后面的实际的服务器(通常是承载真实业务的服务器)进行健康状态检测;而失败切换主要是应用于配置了主备模式的负载均衡器,利用VRRP维持主备负载均衡器的心跳,当主负载均衡器出现问题时,由备负载均衡器承载对应的业务,从而在最大限度上减少流量损失,并提供服务的稳定性。
与HeartBeat相比,Keepalived主要是通过虚拟路由冗余来实现高可用功能,虽然它没有HeartBeat功能强大,但是Keepalived部署和使用非常的简单,所有配置只需要一个配置文件即可以完成。配置文件名:/etc/keepalived/keepalived.conf
二、VRRP协议与keepalived工作原理
1. VRRP协议(虚拟路由冗余协议)简介
在现实的网络环境中,主机之间的通信都是通过配置静态路由或者(默认网关)来完成的,而主机之间的路由器一旦发生故障,通信就会失效,因此这种通信模式当中,路由器就成了一个单点瓶颈,为了解决这个问题,就引入了VRRP协议。
VRRP协议是一种容错的主备模式的协议,保证当主机的下一跳路由出现故障时,由另一台路由器来代替出现故障的路由器进行工作,通过VRRP可以在网络发生故障时透明的进行设备切换而不影响主机之间的数据通信。
VRRP拓扑图:
2. Keepalived服务VRRP的工作原理
Keepalived高可用对之间是通过VRRP进行通信的,VRRP是通过竞选机制来确定主备的,主的优先级高于备,因此,工作时主会优先获得所有的资源,备节点处于等待状态,当主宕机的时候,备节点就会接管主节点的资源,然后顶替主节点对外提供服务。
在Keepalived服务对之间,只有作为主的服务器会一直发送VRRP广播包,告诉备它还活着,此时备不会抢占主,当主不可用时,即备监听不到主发送的广播包时,就会启动相关服务接管资源,保证业务的连续性。
三、HAProxy+keepalived 高可用负载均衡集群构建
目的:利用keepalived做主备,避免HAProxy单点问题,实现高可用
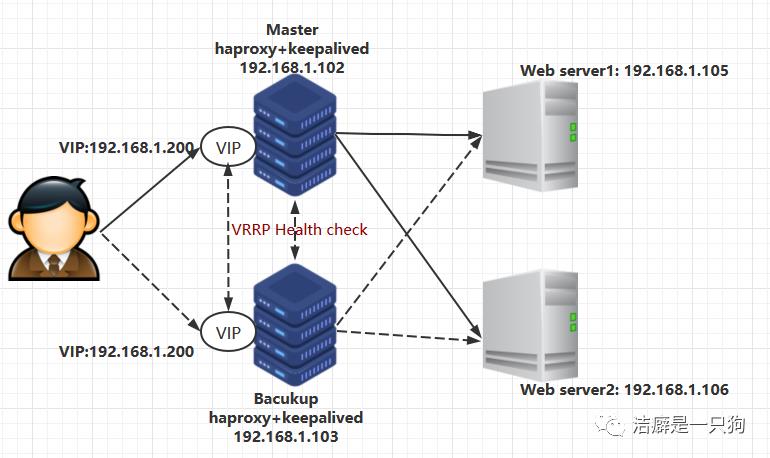
环境:要准备四台机器,IP配置如下;同时还要给主haproxy机器和备haproxy 机器配置VIP
(我们只创建的两台web 机器, 你可以根据需要创建多台web 机器, 实现动静分离;你也可以创建NFS机器做web服务器的后端存储等。)
主haproxy: 192.168.1.102 网卡接口:ens33
备haproxy: 192.168.1.103 网卡接口:ens33
Web server1: 192.168.1.105 网卡接口:ens33
Web server2: 192.168.1.106 网卡接口:ens33
VIP: 192.168.1.200 网卡接口:ens33:0
HAProxy+keepalived 高可用负载均衡集群构建拓扑图:
操作步骤:
1. 在haproxy-master 和 haproxy-slave 机器上面安装keepalived
yum -y install keepalived
2. 配置VIP
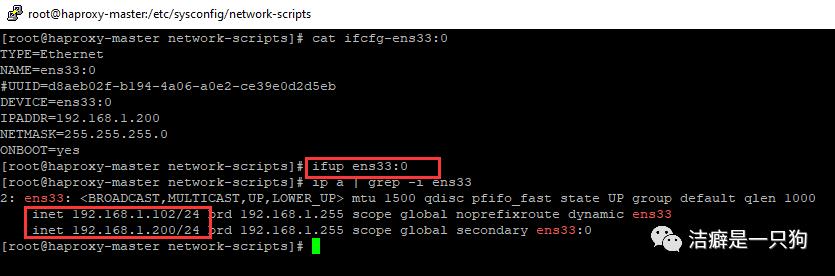
1)在haproxy-master 机器上面配置VIP:
[root@haproxy-master network-scripts]# cp ifcfg-ens33 ifcfg-ens33:0[root@haproxy-master network-scripts]# vim ifcfg-ens33:0[root@haproxy-master network-scripts]# ifup ens33:0[root@haproxy-master network-scripts]# ip a | grep -i ens332: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000inet 192.168.1.102/24 brd 192.168.1.255 scope global noprefixroute dynamic ens33inet 192.168.1.200/24 brd 192.168.1.255 scope global secondary ens33:0[root@haproxy-master network-scripts]# cat ifcfg-ens33:0TYPE=EthernetNAME=ens33:0DEVICE=ens33:0IPADDR=192.168.1.200 ##VIPNETMASK=255.255.255.0ONBOOT=yes[root@haproxy-master network-scripts]#
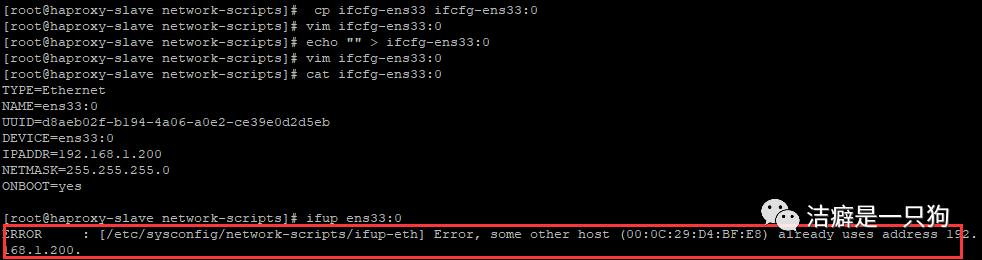
2)在haproxy-slave机器上面配置VIP:
[root@haproxy-slave network-scripts]# cp ifcfg-ens33 ifcfg-ens33:0[root@haproxy-slave network-scripts]# vim ifcfg-ens33:0[root@haproxy-slave network-scripts]# echo "" > ifcfg-ens33:0[root@haproxy-slave network-scripts]# vim ifcfg-ens33:0[root@haproxy-slave network-scripts]# cat ifcfg-ens33:0TYPE=EthernetNAME=ens33:0DEVICE=ens33:0IPADDR=192.168.1.200 ##VIPNETMASK=255.255.255.0ONBOOT=yes[root@haproxy-slave network-scripts]# ifup ens33:0ERROR : [/etc/sysconfig/network-scripts/ifup-eth] Error, some other host (00:0C:29:D4:BF:E8) already uses address 192. 168.1.200.[root@haproxy-slave network-scripts]# vim ifcfg-ens33:0[root@haproxy-slave network-scripts]# ifup ens33:0ERROR : [/etc/sysconfig/network-scripts/ifup-eth] Error, some other host (00:0C:29:D4:BF:E8) already uses address 192. 168.1.200.
此时我们需要修改如下配置:
vi /etc/sysconfig/network-scripts/ifup-eth屏蔽掉下面5行
if [ $? = 1 ]; then# ARPINGMAC=$(echo $ARPING | sed -ne 's/.*[(.*)].*/1/p')# net_log $"Error, some other host ($ARPINGMAC) already uses address ${ipaddr[$idx]}."# exit 1#fi
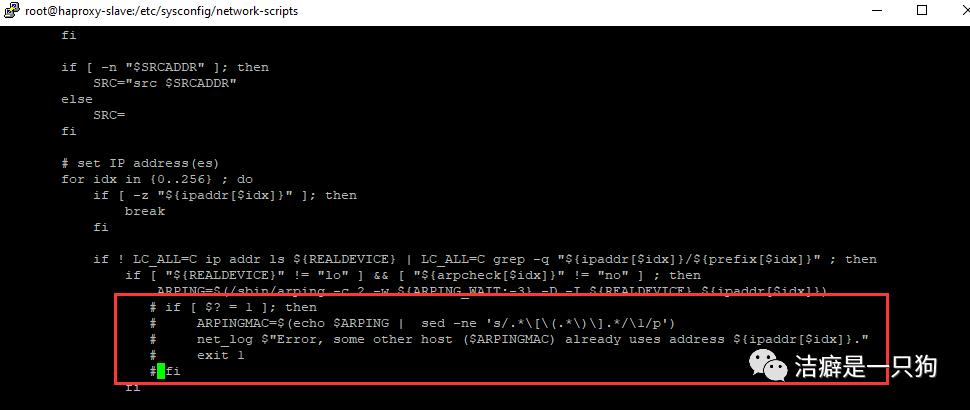
然后再去启动ens33:0就没有报错了

3. 编辑haproxy-master 和 haproxy-slave 机器上面keepalived配置文件
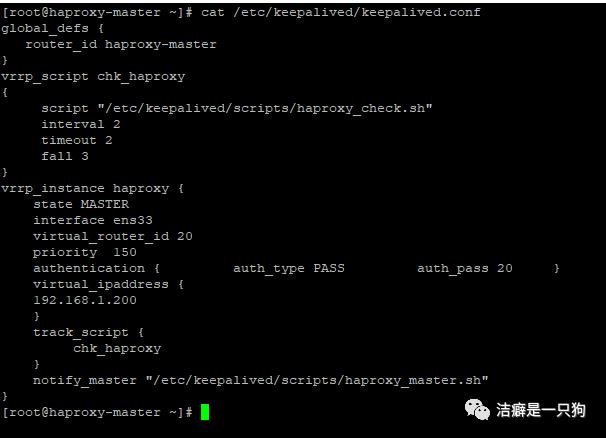
1)192.168.1.102(主)修改keepalived.conf为:
[root@haproxy-master scripts]# cat /etc/keepalived/keepalived.confglobal_defs { ##全局定义, 还可以设置发送邮件等功能router_id haproxy-master # 路由ID,标识本节点的字符串,邮件通知时会用到}# 自定义VRRP实例健康检查脚本 keepalived只能做到对自身问题和网络故障的监控,Script可以增加其他的监控来判定是否需要切换主备vrrp_script chk_haproxy{script "/etc/keepalived/scripts/haproxy_check.sh" #心跳检测脚本,检测haproxy是否启动interval 2 #检测脚本执行的间隔,单位是秒timeout 2fall 3}# VRRP实例:定义对外提供服务的VIP区域及其相关属性vrrp_instance haproxy {state MASTER #指定keepalived的角色,MASTER为主,BACKUP为备interface ens33 #节点固有IP(非VIP)的网卡,用来发VRRP包virtual_router_id 20 #虚拟路由编号,主从要一致priority 150 #优先级,数值越大,获取处理请求的优先级越高,主从之间最好差50authentication { auth_type PASS auth_pass 20 } #设置验证类型和密码,MASTER和BACKUP必须使用相同的密码才能正常通信virtual_ipaddress {192.168.1.200 #定义虚拟ip(VIP)}# 自定义健康检查脚本track_script {chk_haproxy # 配置上面自定义的vrrp脚本调用名}notify_master "/etc/keepalived/scripts/haproxy_master.sh" #记录切换为主节点的信息}[root@haproxy-master scripts]#
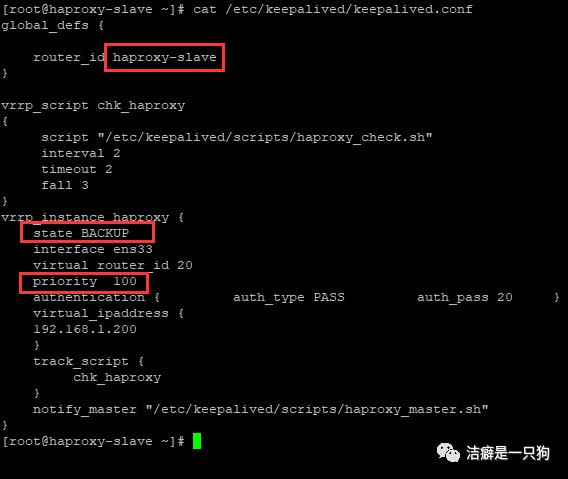
2)192.168.1.103(备)修改keepalived.conf为:
主备配置只有如下三处不同:
修改一:router_id haproxy-master 修改至 router id haproxy-slave
修改一:state MASTER 修改至 state SLAVE
修改二:priority 150 修改至 priority 100, 一般建议与主服务器差值为50.
scripts]# cat /etc/keepalived/keepalived.confglobal_defs {router_id haproxy-slave}vrrp_script chk_haproxy{script "/etc/keepalived/scripts/haproxy_check.sh"interval 2timeout 2fall 3}vrrp_instance haproxy {state BACKUPinterface ens33virtual_router_id 20priority 100authentication { auth_type PASS auth_pass 20 }virtual_ipaddress {192.168.1.200}track_script {chk_haproxy}notify_master "/etc/keepalived/scripts/haproxy_master.sh"}scripts]#
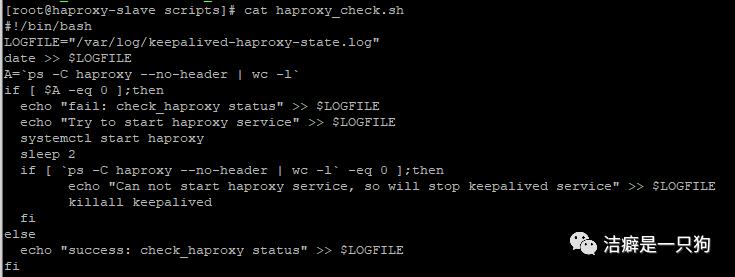
4. 设置haproxy_check.sh脚本
路径:/etc/keepalived/scripts/haproxy_check.sh
注意:脚本内容都是可以自定义的,结合需求
功能:检测haproxy服务状态,如果服务异常,尝试启动haproxy服务,并将该过程记录到log 文件;如果服务正常,也将检测结果记录到log文件。如果第一次检测haproxy服务异常,则启动一次之后再次检测状态,如果服务还是异常,则停止keepalived服务,释放本地VIP, 实现IP漂移到对端继续提供服务。
LOGFILE="/var/log/keepalived-haproxy-state.log"date >> $LOGFILEA=`ps -C haproxy --no-header | wc -l`if [ $A -eq 0 ];thenecho "fail: check_haproxy status" >> $LOGFILEecho "Try to start haproxy service" >> $LOGFILEsystemctl start haproxy #重启haproxy服务sleep 2if [ `ps -C haproxy --no-header | wc -l` -eq 0 ];then #如果启动失败,就进行VIP 转移echo "Can not start haproxy service, so will stop keepalived service" >> $LOGFILEkillall keepalivedfielseecho "success: check_haproxy status" >> $LOGFILEfi
1) 在haproxy-master机器上面创建这个脚本
2)在haproxy-slave 机器上面也创建同样的脚本
3)测试脚本可用性:
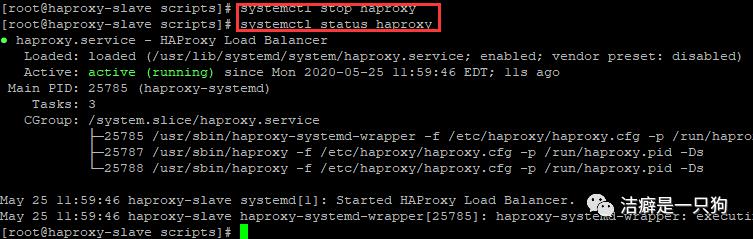
先停掉主机的haproxy 服务,然后我们再查看haproxy 状态发现haproxy服务被脚本启动了。
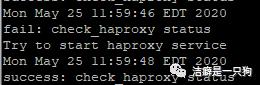
查看日志记录:看到停掉haproxy时有服务fail的日志,同时还有尝试启动haproxy服务的日志。
5. 设置haproxy_master.sh脚本,并设置两个脚本的文件权限为777
路径:/etc/keepalived/scripts/haproxy_master.sh
注意:脚本内容都是可以自定义的,结合需求
功能:记录哪个节点为master节点
1) 在haproxy-master机器上面创建这个脚本
[root@haproxy-master scripts]# cat haproxy_master.shLOGFILE="/var/log/keepalived-haproxy-state.log"echo "Being Master ..." >> $LOGFILE[root@haproxy-master scripts]#
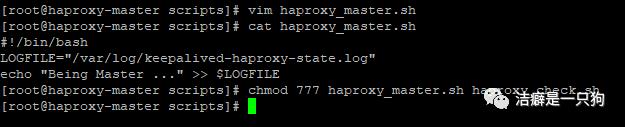
2)在haproxy-slave 机器上面也创建同样的脚本
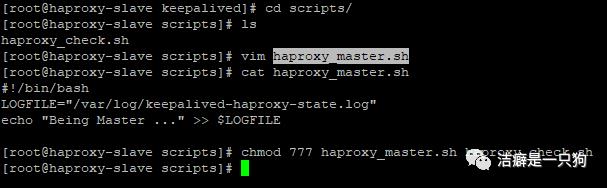
3)测试脚本可用性:
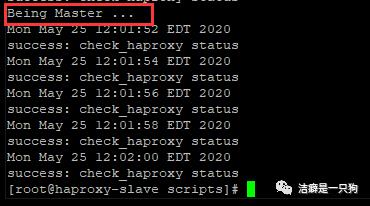
停掉主机的keepalived服务,可以在备机的日志中看到备机成为master的记录:

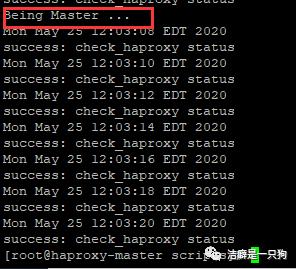
启动主机的keepalived服务,可以在主机的日志看到主机再次成为master的记录:
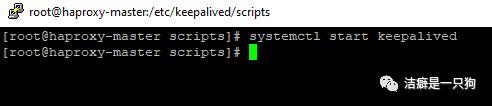
6. 启动keepalived
注意:先启主机的keepalived,再启备机的keepalived
systemctl start keepalived
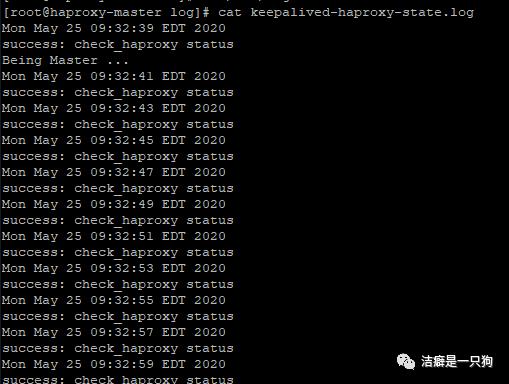
可以在日志文件"/var/log/keepalived-haproxy-state.log" 中查看到主机为当前的master:
(也可以在系统messages日志中看到该信息)
7. 测试
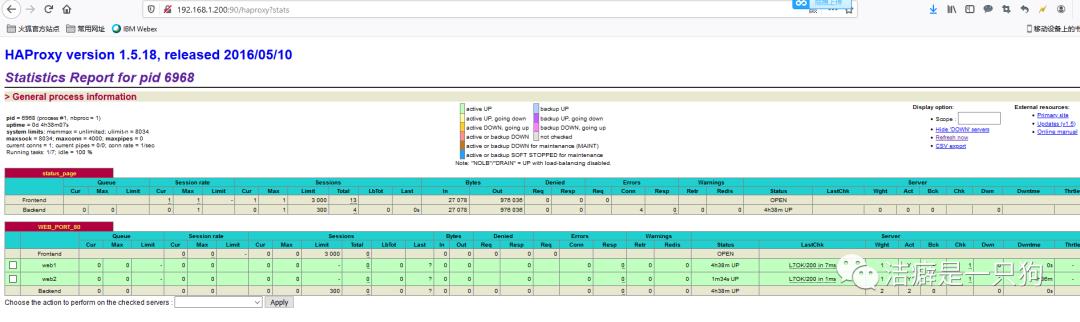
测试之前, 我们访问http://192.168.1.200:90/haproxy?stats, 可以看到haproxy 是正常提供服务的。
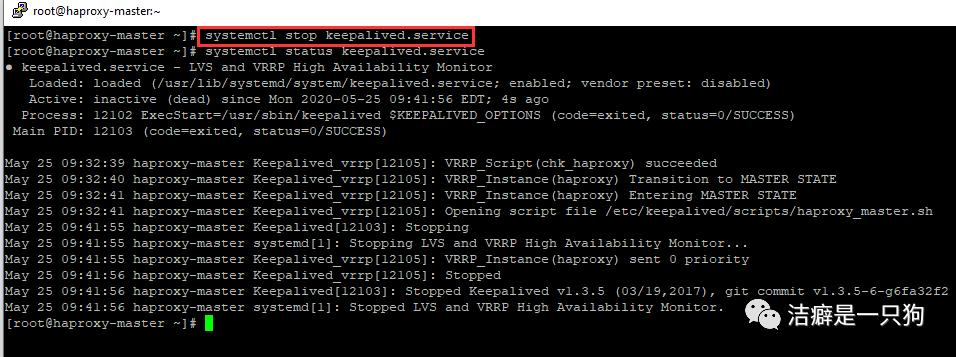
1)关闭主keepalived,VIP是否切换至备机,业务是否正常,恢复原状;(验证keepalived高可用)
关闭主keepalived: systemctl stop keepalivd
在备机上查看messages日志我们发现备机已经进入到MASTER状态:

再访问网页可以看到服务是正常的,haproxy并没有因为主keepalived的中断而中断:(其实在切换的过程中是有短暂的几秒的中断的):
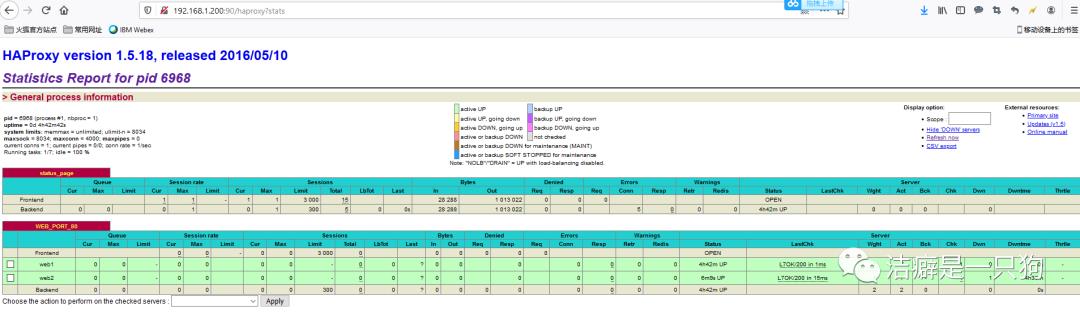

我们再次启动主机的keepalived,查看日志发现主机进入到了MASTER状态,备机进入到BACKUP状态:


2)关闭主HAproxy,VIP是否切换至备机,业务是否正常,恢复原状;(验证HAproxy高可用)
关闭主HAProxy: systemctl stop haproxy.service

在备机上查看messages日志我们发现备机已经进入到MASTER状态:

再访问网页可以看到服务是正常的,haproxy并没有因为主haproxy服务的中断而中断:(其实在切换的过程中是有短暂的几秒的中断的)
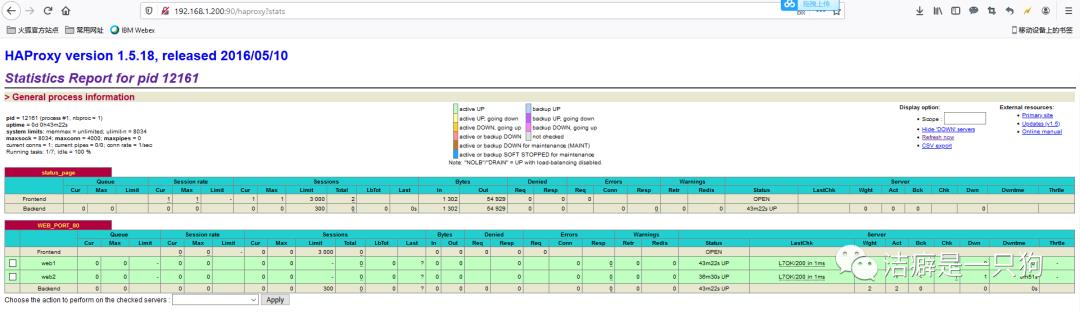
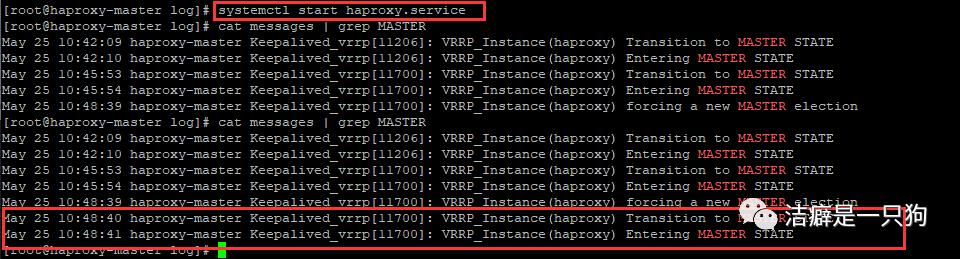
我们再次启动主机的keepalived,查看日志发现主机进入到了MASTER状态,备机进入到BACKUP状态:

3)关闭后台服务器haproxy-master,业务是否正常。(验证HAproxy状态检查)
将主机关机:
发现ping 不通了:
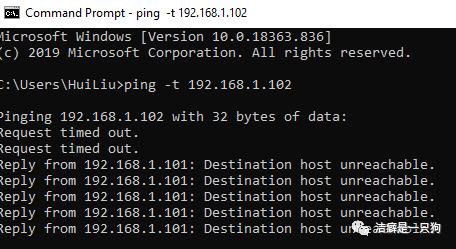
在备机上查看messages日志我们发现备机已经进入到MASTER状态:

再访问网页可以看到服务还是正常的:
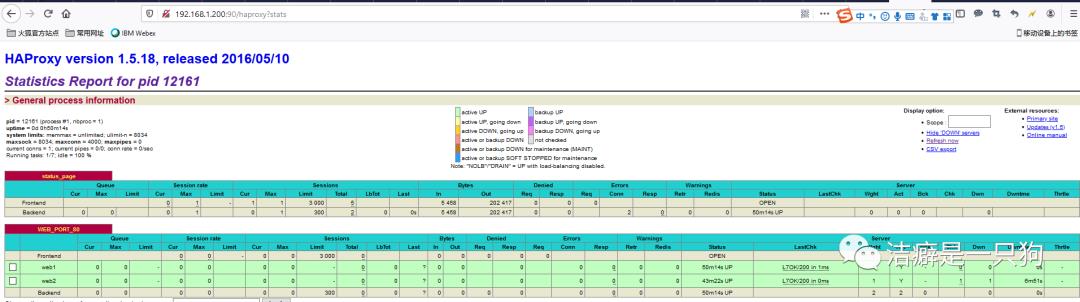

至此,我们成功验证了keepalived+haproxy的高可用性;以及haproxy的负载均衡。集群搭建成功!
今天我们就介绍到这里,之后会继续更新另外一种实现高可用的方式:Heartbeat。可以持续关注!
长按二维码
以上是关于高可用篇之Keepalived (HAProxy+keepalived 搭建高可用负载均衡集群)的主要内容,如果未能解决你的问题,请参考以下文章
keepalived + haproxy + mysql 构建高可用数据库