如何入门 Python 爬虫
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何入门 Python 爬虫相关的知识,希望对你有一定的参考价值。
个人觉得:新手学习python爬取网页先用下面4个库就够了:(第4个是实在搞不定用的,当然某些特殊情况它也可能搞不定)
1. 打开网页,下载文件:urllib
2. 解析网页:BeautifulSoup,熟悉JQuery的可以用Pyquery
3. 使用Requests来提交各种类型的请求,支持重定向,cookies等。
4. 使用Selenium,模拟浏览器提交类似用户的操作,处理js动态产生的网页
这几个库有它们各自的功能。配合起来就可以完成爬取各种网页并分析的功能。具体的用法可以查他们的官网手册(上面有链接)。
做事情是要有驱动的,如果你没什么特别想抓取的,新手学习可以从这个闯关网站开始
,目前更新到第五关,闯过前四关,你应该就掌握了这些库的基本操作。
实在闯不过去,再到这里看题解吧,第四关会用到并行编程。(串行编程完成第四关会很费时间哦),第四,五关只出了题,还没发布题解。。。
学完这些基础,再去学习scrapy这个强大的爬虫框架会更顺些。这里有它的中文介绍。
这是我在知乎的回答,直接转过来有些链接没有生效,可以到这里看原版,http://www.zhihu.com/question/20899988/answer/59131676 参考技术A
链接:https://pan.baidu.com/s/1wMgTx-M-Ea9y1IYn-UTZaA
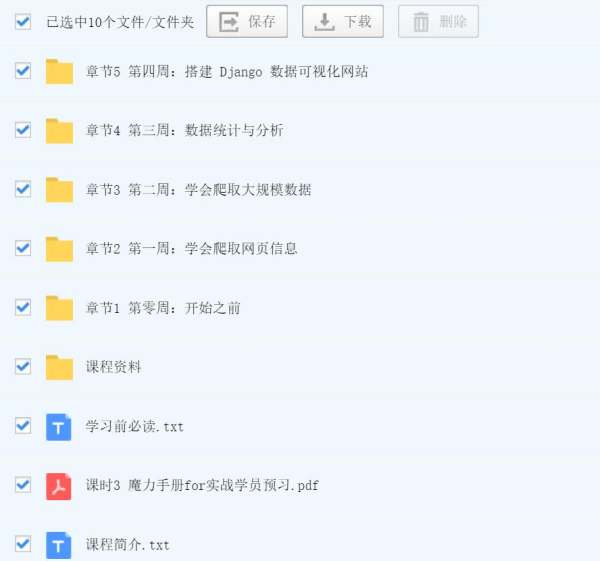
课程简介
毕业不知如何就业?工作效率低经常挨骂?很多次想学编程都没有学会?
Python 实战:四周实现爬虫系统,无需编程基础,二十八天掌握一项谋生技能。
带你学到如何从网上批量获得几十万数据,如何处理海量大数据,数据可视化及网站制作。
课程目录
开始之前,魔力手册 for 实战学员预习
第一周:学会爬取网页信息
第二周:学会爬取大规模数据
第三周:数据统计与分析
第四周:搭建 Django 数据可视化网站
......
参考技术B python最常用的是requests库,pip install requests,然后import requests,就可以requests.get(url)了,这是最基本的爬虫了,对于静态网页应该没有什么问题。如果要登录获取信息,那么就直接session = requests.Session(); session.get(url)之类。对于动态网页,比如纯js写的网页,推荐phantomjs和casperjs;虽然这两个东西和python没有关系,但是安装好phantomjs,再使用python-selenium,就可以把phantomjs当没有界面的浏览器使用,并可以得到js运行后渲染出的页面。 参考技术C python有专门的爬虫框架的
Scrapy框架
如何入门爬虫(基础篇)
一、爬虫入门
-
Python爬虫入门一之综述
-
Python爬虫入门二之爬虫基础了解
-
Python爬虫入门三之Urllib库的基本使用
-
Python爬虫入门四之Urllib库的高级用法
-
Python爬虫入门五之URLError异常处理
-
Python爬虫入门六之Cookie的使用
- Python爬虫入门七之正则表达式
二、爬虫实战
-
Python爬虫实战一之爬取糗事百科段子
-
Python爬虫实战二之爬取百度贴吧帖子
-
Python爬虫实战三之实现山东大学无线网络掉线自动重连
-
Python爬虫实战四之抓取淘宝MM照片
-
Python爬虫实战五之模拟登录淘宝并获取所有订单
-
Python爬虫实战六之抓取爱问知识人问题并保存至数据库
-
Python爬虫实战七之计算大学本学期绩点
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
三、爬虫利器
-
Python爬虫利器一之Requests库的用法
-
Python爬虫利器二之Beautiful Soup的用法
-
Python爬虫利器三之Xpath语法与lxml库的用法
-
Python爬虫利器四之PhantomJS的用法
-
Python爬虫利器五之Selenium的用法
- Python爬虫利器六之PyQuery的用法
四、爬虫进阶
-
Python爬虫进阶一之爬虫框架概述
-
Python爬虫进阶二之PySpider框架安装配置
-
Python爬虫进阶三之爬虫框架Scrapy安装配置
- Python爬虫进阶四之PySpider的用法
如何获取:
添加小编Q群:789133747,即可获取本文书籍

以上是关于如何入门 Python 爬虫的主要内容,如果未能解决你的问题,请参考以下文章