第二篇,选择排序算法:简单选择排序堆排序
Posted Xtizzzz分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第二篇,选择排序算法:简单选择排序堆排序相关的知识,希望对你有一定的参考价值。
此为第二篇,选择排序算法:简单选择排序、堆排序。
简介
选择排序的基本思想是:每一趟(如第i趟)在后面 n-i+1 ( i = 1 , 2, ...., n-1) 个待排序元素中选取关键字最小的元素,作为有序子序列的第i个元素,直到第 n-1 趟做完,待排序元素只剩下一个,就不用再选了。
基于选择的排序算法主要介绍简单选择排序和堆排序。
一.简单选择排序
简单选择排序算法的思想:假设排序表 L [1...n ],第i趟排序即从 L[i...n] 中选择关键字最小的元素与L(i) 交换,每一趟排序可以确定一个元素的最终位置,这样经过n-1趟排序就可使得整个排序表有序。
若表L={4,6,8,5,9},我们以min来选择较小元素的小标,i和j结合来遍历数组。初始的时候min和i都指向L的首元素,j指向i+1元素,然后j开始从右向左进行遍历L,若L(j)>L(min),则min=j,直至j走完整个L表;i再向右走,这样循环到i走到最后一个元素就完成了排序,过程如下图所示:
1.例程
/********************************* 选择排序 *********************************/#include <stdio.h>#include <stdlib.h>#include <string.h>void SelectSort(int *data, int length){int i, j, min, temp;for(i = 0; i < length-1; i++) //进行n-1次循环{min = i; //选择一个序号for(j = i+1; j < length; j++) //从(选择的序号+1)到最后一个序号,进行两两比较if(data[j] < data[select]) //若找到比选择序号的值小的,则更新min = j;temp = data[i]; //交换data[i] = data[min];data[min] = temp;}}int main() {int i = 0;int data[] = {23, 64, 24, 12, 9, 16, 53, 57};int temp[] = {0};int length = sizeof(data) / sizeof(int);SelectSort(data, length);for (i = 0;i < length;i ++) {printf("%4d", data[i]);}printf(" ");}
2.性能分析
2.1空间复杂度
仅使用常数个辅助单元,故空间效率为:O(1);
2.2时间复杂度
在简单选择排序过程中,元素移动的操作次数很少,不会超过 3(n-1) 次,若表已有序,最好的情况是移动0次;但元素间比较的次数与序列的初始状态无关,始终是n(n-1)/2次。
因此时间复杂度始终为:O(n2)。
2.3稳定性
在第i趟找到最小元素后,和第i个元素交换,可能会导致第i个元素与其含有相同关键字元素的相对位置发生改变。例如,表L = {2, 2, 1}, 经过一趟排序后 L={1, 2, 2} ,最终排序序列也是L={1, 2, 2},显然,2和2的相对次序己发生变化。
因此简单选择排序是一种不稳定的排序方法。
二.堆排序
堆排序是根据堆的数据结构设计的一种排序,而堆可分为大根堆(每个结点的值都大于其左孩子和右孩子结点的值)和小根堆(每个结点的值都小于其左孩子和右孩子结点的值),这两种堆都是一棵完全二叉树。若序列L={45, 78, 09, 32, 87, 65, 53, 17},则大小根堆如下图:
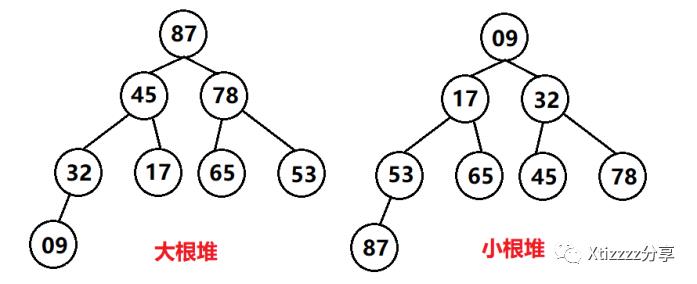
将上面的大小跟堆进行映射可得到:
大根堆序列L(1~8)={87, 45, 78, 32, 17, 65, 53, 09}
小根堆序列L(1~8)={09, 17, 32, 53, 65, 45, 78, 87}
取父结点索引:i左孩子索引:2i右孩子索引:2i+1
则以上大小根堆满足一下性质(即堆的性质):
1<= i <= n/2
L(i) >= L(2i) && L(i) >= L(2i+1)
或
L(i) =< L(2i) && L(i) =< L(2i+1)
堆排序的思路为:
1.首先将存放在L[1....n]中的n个元素建成初始堆,由于堆本身的特点(以大顶堆为例),堆顶元素就是最大值。
2.输出堆顶元素后,将堆底元素送入堆顶,此时根结点已不满足大顶堆的性质,堆被破坏,将堆顶元素向下调整使其继续保持大顶堆的性质,再输出堆顶元素。
3.如此重复,直到堆中仅剩一个元素为止。
可见堆排序主要步骤为:1.将无序序列构造成初始堆。2.输出堆顶元素后,将剩余元素调整成新的堆。
1.将无序序列构造成初始堆
n个结点的完全二叉树,最后一个结点是第 n/2 个结点的孩子。
1.1对第 n/2 个结点为根的子树筛选(对于大根堆,若根结点的关键字小于左右孩子中关键字较大者,则交换),使该子树成为堆。
1.2之后向前依次对各结点 ( n/2 - 1 ~ 1) 为根的子树进行筛选,看该结点值是否大于其左右子结点的值,若不大于,则将右子结点中的较大值与之交换,交换后可能会破坏下一级的堆,于是继续采用上述方法构造下一级的堆,直到以该结点为根的子树构成堆为止
1.3反复利用上述调整堆的方法建堆,直到根结点。
步骤如下图所示:
(a) 初始时调整L(4)子树,09 < 32,交换,交换后满足堆的定义;
(b) 向前调整L(3)子树,78 < 左右孩子的较大者87,交换,交换后满足堆的定义;
(c) 向前调整L(2)子树,17 < 左右孩子的较大者45,交换后满足堆的定义;
(d) 向前调整至根结点L(1), 53 < 左右孩子的较大者87,交换,交换后破坏了L(3)子树的堆;采用上述方法对L(3)进行调整,53 < 左右孩子的较大者78 ,交换;
(e) 至此该完全二叉树满足堆的定义。
2.输出堆顶元素后,将剩余元素调整成新的堆
输出堆顶元素后,堆的性质被破坏,需要向下进行筛选。步骤如下图所示:
将 09 右孩子的较大者 78 交换,交换后破坏了L(3)子树的堆,继续对L(3)子树向下筛选;将 09 和左右孩子的较大者 65 交换,交换后得到了新堆。
1.例程
#include <stdio.h>#include <stdlib.h>#include <string.h>void display(int array[], int size) {for (int i = 0; i < size; i++) {printf("%d ", array[i]);}printf(" ");}void swap(int array[], int x, int y) {int key = array[x];array[x] = array[y];array[y] = key;}// 从大到小排序// void Down(int array[], int i, int n) {// int child = 2 * i + 1;// int key = array[i];// while (child < n) {// if (array[child] > array[child + 1] && child + 1 < n) {// child++;// }// if (key > array[child]) {// swap(array, i, child);// i = child;// } else {// break;// }// child = child * 2 + 1;// }// }// 从小到大排序void Down(int array[], int i, int n) { // 最后结果就是大顶堆int parent = i; // 父节点下标int child = 2 * i + 1; // 子节点下标while (child < n) {if (array[child] < array[child + 1] && child + 1 < n) {//判断子节点那个大,大的与父节点比较child++;}if (array[parent] < array[child]) { // 判断父节点是否小于子节点swap(array, parent, child); // 交换父节点和子节点parent = child; // 子节点下标 赋给 父节点下标}child = child * 2 + 1; // 换行,比较下面的父节点和子节点}}void BuildHeap(int array[], int size) {for (int i = size / 2 - 1; i >= 0; i--) { // 倒数第二排开始, 创建大顶堆,必须从下往上比较Down(array, i, size); // 否则有的不符合大顶堆定义}}void HeapSort(int array[], int size) {printf("初始化数组:");BuildHeap(array, size); // 初始化堆display(array, size); // 查看初始化结果for (int i = size - 1; i > 0; i--) {swap(array, 0, i); // 交换顶点和第 i 个数据// 因为只有array[0]改变,其它都符合大顶堆的定义,所以可以从上往下重新建立Down(array, 0, i); // 重新建立大顶堆printf("排序的数组:");display(array, size);}}int main() {int i = 0;int data[] = {23, 64, 24, 12, 9, 16, 53, 57};int temp[] = {0};int length = sizeof(data) / sizeof(int);HeapSort(data, length);for (i = 0;i < length;i ++) {printf("%4d", data[i]);}printf(" ");}
2.性能分析
2.1适用性
堆排序适合关键字较多的情况(如 n>1000)。
例如,在一亿个数中选出前 100 个最大值?首先用一个大小为100 的数组,读入前 100 个数,建立小顶堆,而后依次读入余下的数,若小于堆顶则舍弃,否则用该数取代堆顶并重新调整堆,待数据读取完毕,堆中100个数即为所求。
2.2空间复杂度
仅使用常数个辅助单元,故空间效率为:O(1);
2.3时间复杂度
建堆时间为O(n),之后有 n-1 次向下调整操作,每次调整的时间复杂度为O(h)(h为堆的高度,h=log(n+1) 约为 log2n )。
因此在最好、最坏和平均情况下,堆排序的时间复杂度为O(nlog2n)。
2.4稳定性
进行筛选时,可能会把后面相同关键字的元素调整到前面。例如,表L = {1, 2, 2},构造初始推时可能将2交换到堆顶,此时L={2, 1, 2 } ,最终排序序列为L={1, 2, 2},显然,2和2的相对次序己发生变化。
因此堆排序是一种不稳定的排序方法。
下一篇,第三篇,插入排序算法:直接插入排序、希尔排序。
参考:
《王道数据结构》
CSDN博主:有人_295 的《堆排序算法--C/C++》
以上是关于第二篇,选择排序算法:简单选择排序堆排序的主要内容,如果未能解决你的问题,请参考以下文章