R语言爬虫系列4|AJAX与动态网页介绍
Posted 机器学习实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言爬虫系列4|AJAX与动态网页介绍相关的知识,希望对你有一定的参考价值。
很早之前就写过用rvest包实现对静态网页的抓取之类的文章,以至于很久之后看到那些文章的朋友还拿来套,以为换个网址也能达到同样的抓取效果。然而事与愿违,殊不知这些通常自己会“动”,明明是同一个url,前后硬是两个不同的网页内容,利用rvest的爬虫自然也就失效了。
网络技术实现从静态到动态转变的一个关键角色是汇总于AJAX这个术语下的一组技术,所谓AJAX,全称叫做异步javascript和XML(Asynchronous JavaScript and XML),它是一组技术,不同的浏览器有自己的AJAX实现组件,有了AJAX技术之后,就不需要对整个网页进行刷新了,局部更新既不占用宽带又可以提高加载速度有没有,比如说刚刚的知乎首页,想看新内容?不断把网页下拉自动加载就好。
再举个例子:比如说你们班拍毕业照,照完之后洗出来才发现哎呀少了一个人,那怎么办呢?传统的方式就是重新把大家集合起来再拍一次,那AJAX就不会这么做了,AJAX会把这位漏掉的同学P到先前的合照中去。总之,AJAX可以在不重新加载整个网页的情况下对网页的局部进行更新的某种技术。
JavaScript如何将html网页转化为DHTML?
JavaScript号称最流行的Web编程脚本语言,可惜小编并不懂这门语言,但这不妨碍咱们的网络数据抓取的需要。在爬虫专栏开始的第一篇文章的时候小编就说过,HTML、CSS和JavaScript是前端技术的三驾马车,要认识原生的JavaScript,重要的是了解其对于HTML的三种改进方法:
1. 以HTML中的<script>标签为固定位置进行代码内嵌;
2. 对<script>元素中的src属性路径引用一个存放外部的JavaScript代码文件;
3. JavaScript代码直接出现在特定HTML元素属性里,也叫事件处理器。
在当前浏览器显示中对HTML信息进行修改称之为DOM操作(文档对象模型),这些操作构成了产生产生动态浏览器行为的基本过程,JavaScript可供支持的修改操作有很多,HTML元素和属性可以添加移动删除,CSS样式也可以修改,具体JS是怎样对HTML进行修改的,小编这里就不展示了,感兴趣的同学可以自行去补JavaScript这门语言,总之大家能知道是JavaScript这个东西让我们容易抓取的静态网页变成难以抓取的动态网页的罪魁祸首之一。
XHR:DHTML中数据的获取机制是怎么样的?
如果说JavaScript是将HTML变成DHTML的话,那么XHR就是将传统的HTTP协议同步请求通信变成异步发起HTTP请求。传统上HTTP协议的同步通信通常意味着在网络服务器处理一个新的网页过程中,用户和浏览器之间的交互是无效的。而支持在浏览器与Web服务器之间进行持续的信息交换的方法就是所谓的XHR(XMLHttpRequest)。
XHR在DHTML中的数据获取机制如下:
1. 用户开始通过任何浏览器可识别的事件发起一个AJAX请求,比如说点击一个按钮,下拉一个菜单之类的,然后JavaScript会将这个把这个请求作为一个实例化的XHR对象;
2. 这个XHR对象会向服务器发起一个对特定文件的请求,请求一般从后台发出,所以不影响用户与网页的交互;
3. 请求在服务器端会被接受和处理,相应的数据就会通过XHR对象发回给浏览器客户端;
4. 数据到了客户端会被接受,该事件就会被触发然后被某个事件处理器所捕获。
在XHR的实际使用过程中,一般可以加载HTML/XML和JSON等数据类型。
对于通过AJAX改进后的DHTML而言,我们在用R进行抓取时只是去查看源代码肯定是不够的,R语言没有为我们提供必要的结构分析功能,这时候还是要借助于浏览器本身的Web开发者工具来进行分析。
目前任意一款浏览器基本上都具备这个功能,只要在你浏览的网页上右键然后点击审查元素即可出现WDT(Web Development Tools)界面,界面最上面一栏显示包括元素、控制台、来源、网络、时间线、运行概况、资源、安全和审计8个面板,对于网络数据抓取而言只需要重点关注元素和网络这两大面板即可。
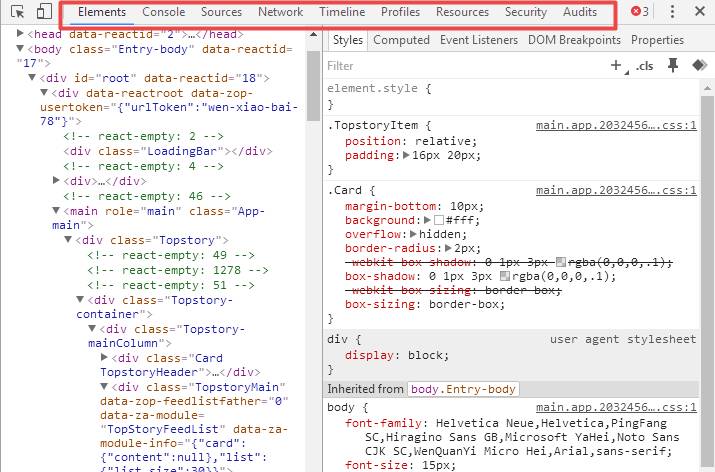
元素面板(Elements)包含了网页HTML结构信息,对于特定的HTML代码及其在网页视图中对应的图形化表现之间的联系特别有用,将鼠标悬停在某个元素节点上,对应的节点在HTML页面上蓝色高亮显示,而对于指定节点的信息提取,也可以通过邮件单击选择复制XPath表达式。
网络面板(Network)会提供实时的网络请求和下载的相关信息。点击网络面板然后F5刷新后下拉网页查看XHR请求可获取request信息:
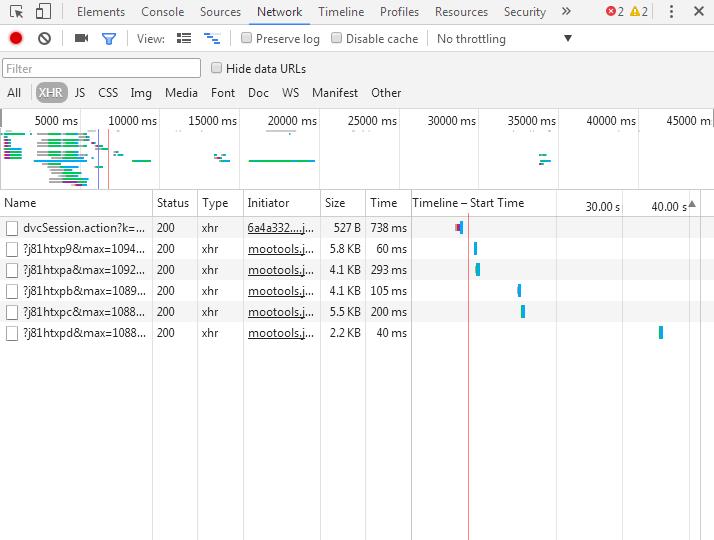
从图中可以看出一共请求到6个资源,包括文件名、状态码和类型等信息。如果我们是要获取每张图片的信息的话,通过对XHR的分析多试几次即可找到我们真实要请求的url,并掌握其构成规律:
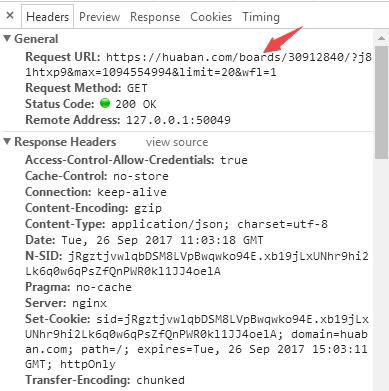
通过字符串的拼接即可构造准确的url资源请求,然后按照批量下载的方式利用RCurl包对其进行解析即可。
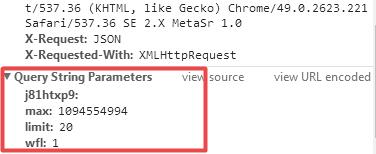
url规律构造如下:
http://huaban.com/boards/30912840/? j81htxp9& max=1094554994 &limit=20 &wfl=1
http://huaban.com/boards/30912840/?j81htxp9&&max=1094554994&limit=20&wfl=1
参考资料:
Automated Data Collection with R
R语言自动数据采集
往期精彩:
一个数据科学狂热者的学习历程

以上是关于R语言爬虫系列4|AJAX与动态网页介绍的主要内容,如果未能解决你的问题,请参考以下文章