数据爬虫:AJAX与网页动态加载 | R语千寻
Posted 狗熊会
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据爬虫:AJAX与网页动态加载 | R语千寻相关的知识,希望对你有一定的参考价值。


很多了解R语言数据抓取的读者可能已经听说过rvest包。rvest包作为一款简单易用的R爬虫包(在后文中会详细介绍),对静态网页的抓取非常适用。但对于有些会“动”的网页来说,rvest就不再有效了。
网络技术实现从静态到动态转变的一个关键角色是汇总于AJAX这个术语下的一组技术。所谓AJAX,全称为异步JavaScript和XML(Asynchronous JavaScript and XML),它是一组技术,不同的浏览器有自己的AJAX实现组件,有了AJAX技术之后,就不需要对整个网页进行刷新了,局部更新既不占用宽带又可以提高加载速度。比如说知乎首页,要看新内容,不断把网页下拉自动加载即可。
01
从HTML到DHTML
javascript号称最流行的Web编程脚本语言,我们不需要了解它的细节,因为这并不妨碍网络数据抓取的需要。前文提到过,html、CSS和JavaScript是前端技术的三驾马车,其中,JavaScript主要起到一些效果渲染的作用。要认识原生的JavaScript,重要的是了解其对于HTML的三种改进方法:
(1)以HTML中的<script>标签为固定位置进行代码内嵌;
(2)对<script>元素中的src属性路径引用一个存放外部的JavaScript代码文件;
(3)JavaScript代码直接出现在特定HTML元素属性里,也叫事件处理器。
在当前浏览器显示中对HTML信息进行修改称为DOM操作(文档对象模型),这些操作构成了产生动态浏览器行为的基本过程。JavaScript可供支持的修改操作有很多,HTML元素和属性可以添加移动删除,CSS样式也可以修改。具体JS是怎样对HTML进行修改的,这里就不展示了,感兴趣的读者可以自行学习JavaScript语言。总之,在抓取网页时,JavaScript往往使得容易抓取的静态网页变成难以抓取的动态网页。
02
网页动态加载中数据的获取机制
如果说JavaScript是将HTML变成DHTML的话,那么XHR就是将传统的HTTP协议同步请求通信变成异步发起HTTP请求。这里的异步应该如何理解呢?比如爬拉钩网的招聘信息时,输入表单后却发现它网页结构跟静态的完全不同,无法抓取。这就是采用了异步加载内容的技术,爬虫的时候需要我们找到真实的要请求的URL才能爬到它的招聘数据。传统上HTTP协议的同步通信通常意味着在网络服务器处理一个新的网页过程中,用户和浏览器之间的交互是无效的。而异步通信支持在浏览器与Web服务器之间进行持续的信息交换的方法就是所谓的XHR(XMLHttpRequest)。
XHR在DHTML中的数据获取机制如下:
(1)用户开始通过任何浏览器可识别的事件发起一个AJAX请求,比如说点击一个按钮,下拉一个菜单之类的,然后JavaScript会将这个请求作为一个实例化的XHR对象;
(2)这个XHR对象会向服务器发起一个对特定文件的请求,请求一般从后台发出,所以不影响用户与网页的交互;
(3)请求在服务器端会被接受和处理,相应的数据就会通过XHR对象发回给浏览器客户端;
(4)数据到了客户端会被接受,该事件就会被触发然后被某个事件处理器所捕获。
在XHR的实际使用过程中,一般可以加载HTML/XML和JSON等数据类型。
03
使用Web开发者工具辅助动态爬取
前面两节介绍了网页动态爬取的理论方法,但在实际应用时还需要其他的工具辅助,与网页“斗智斗勇”。对于通过AJAX改进后的DHTML而言,在用R进行抓取时只是去查看源代码肯定是不够的,R语言没有提供必要的网页结构分析功能,这时还是要借助于浏览器本身的Web开发者工具(图1)来进行分析。
目前任意一款浏览器基本上都具备这个功能,只要在浏览的网页上使用鼠标右键点击审查元素即可出现WDT(Web Development Tools)界面,界面最上面一栏显示包括元素、控制台、来源、网络、时间线、运行概况、资源、安全和审计8个面板(见图1),对于网络数据抓取而言只需要重点关注元素和网络这两大面板即可。
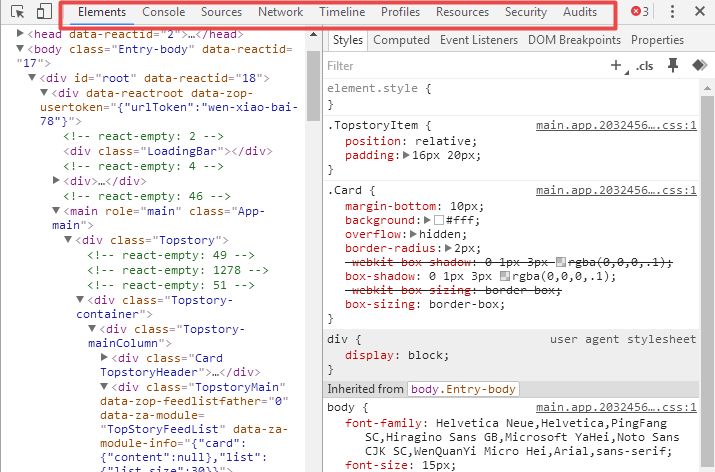
图1 Web开发者工具界面
元素面板(Elements)包含了网页HTML结构信息,对于特定的HTML代码及其在网页视图中对应的图形化表现之间的联系特别有用。在中介绍过,可以使用selectorGadget获取XPath表达式,元素面板也有相似的功能。将鼠标悬停在某个元素节点上,对应的节点在HTML页面上蓝色高亮显示,而对于指定节点的信息提取,也可以通过右键单击选择复制XPath表达式。
网络面板(Network)会提供实时的网络请求和下载的相关信息。在中,已经介绍了HTTP消息,但是在动态爬取中,获得request(请求)信息并非易事。这就要借助网络面板辅助获取了。点击网络面板然后F5刷新后下拉网页查看XHR请求,即可获取request信息(见图2)。
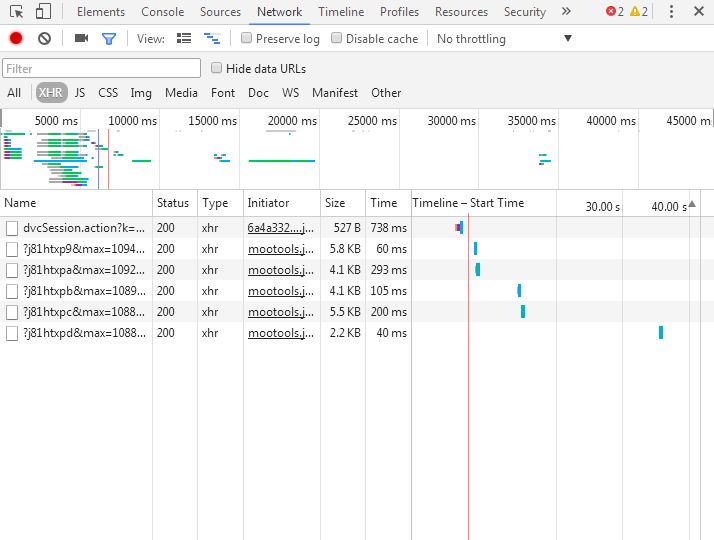
图2 XHR面板
从图2中可以看出,一共请求到6个资源,包括文件名、状态码和类型等信息。如果我们是要获取每张图片的信息的话,通过对XHR的分析多试几次即可找到真实要请求的URL,并掌握其构造信息(见图3)。
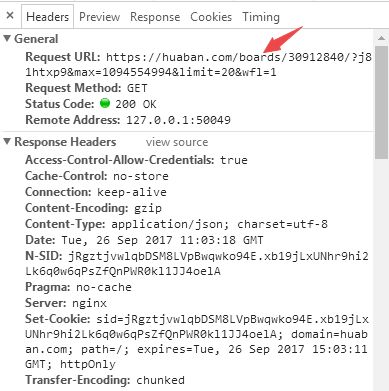
图3 真实请求URL的详细信息
通过字符串的拼接即可构造准确的URL资源请求,然后按照批量下载的方式利用RCurl包对其进行解析即可(图4)。
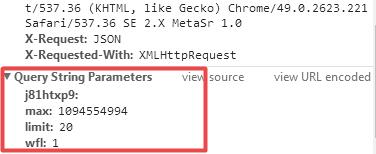
图4 URL请求参数
通过参数信息可以获得URL构造信息:
http://huaban.com/boards/30912840/?
j81htxp9&max=1094554994
&limit=20
&wfl=1
http://huaban.com/boards/30912840/?j81htxp9&&max=1094554994&limit=20& wfl=1

熊小编1分钟前
第一期:
第二期:
第三期:

识别下方二维码成为狗熊会会员!
友情提示:
个人会员不提供数据、代码,
视频only!
个人会员网址:http://teach.xiong99.com.cn
以上是关于数据爬虫:AJAX与网页动态加载 | R语千寻的主要内容,如果未能解决你的问题,请参考以下文章